The Energy Consumption of Transformer Fine-Tuning: A Roofline-Inspired Scaling Model
Pith reviewed 2026-06-26 09:01 UTC · model grok-4.3
The pith
A roofline-inspired scaling law predicts energy consumption for fine-tuning transformers across multiple GPU configurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
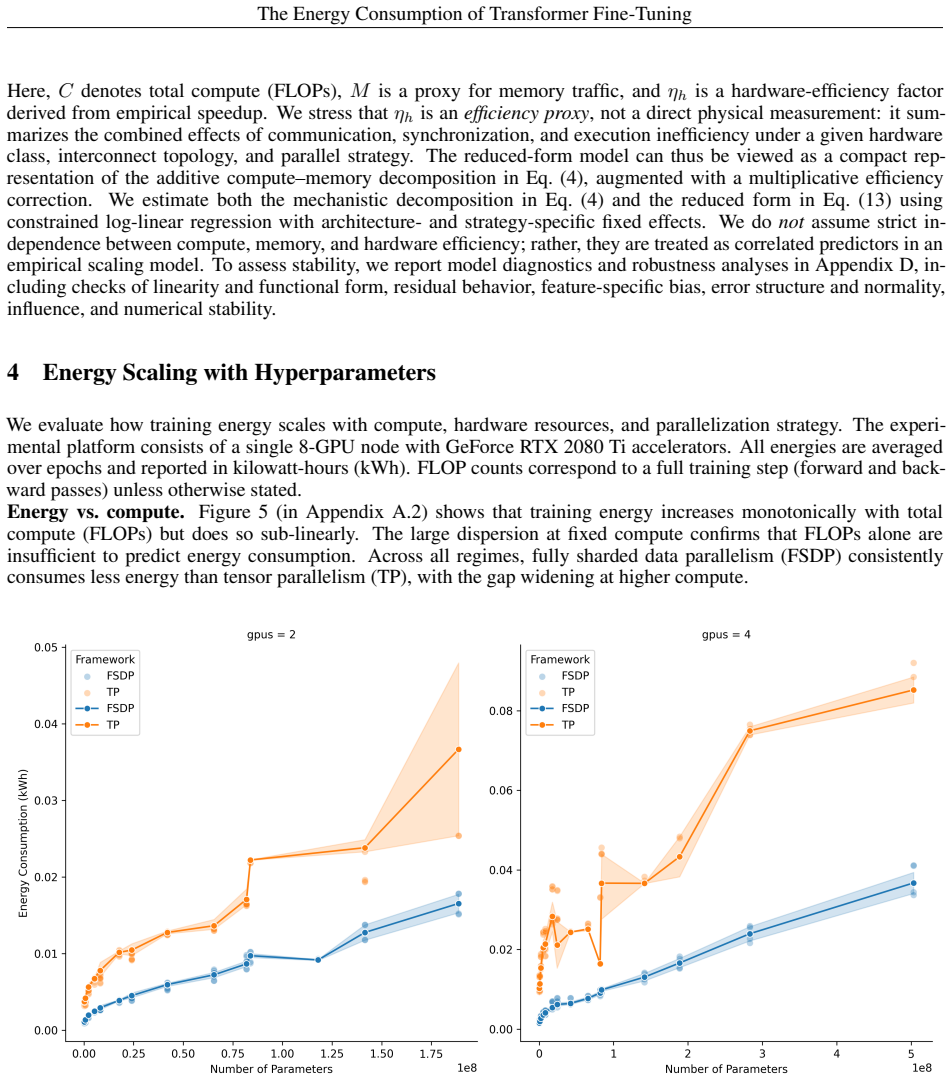
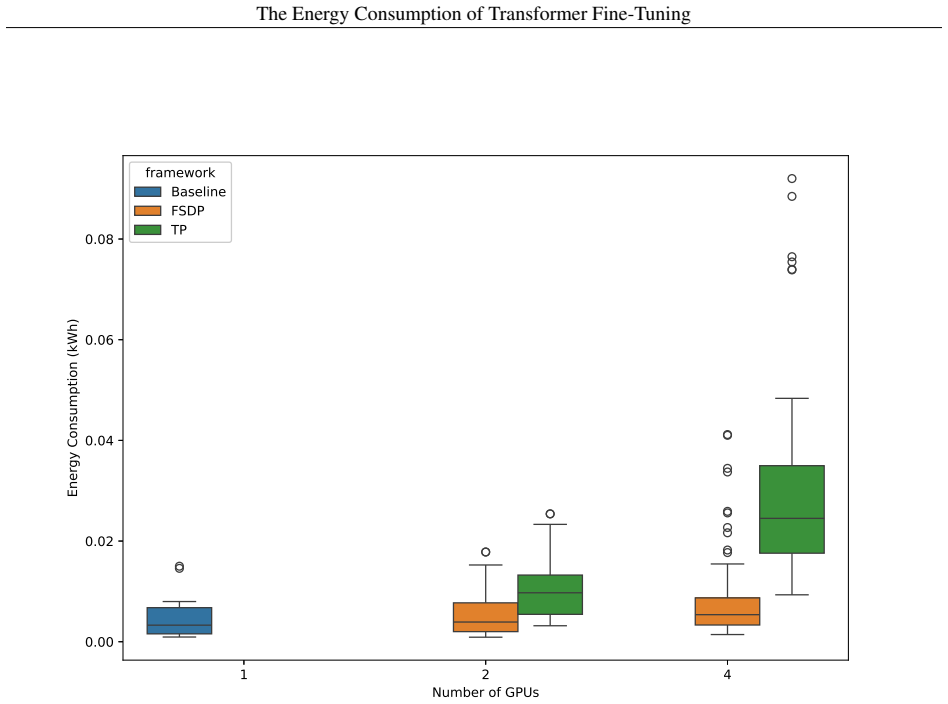
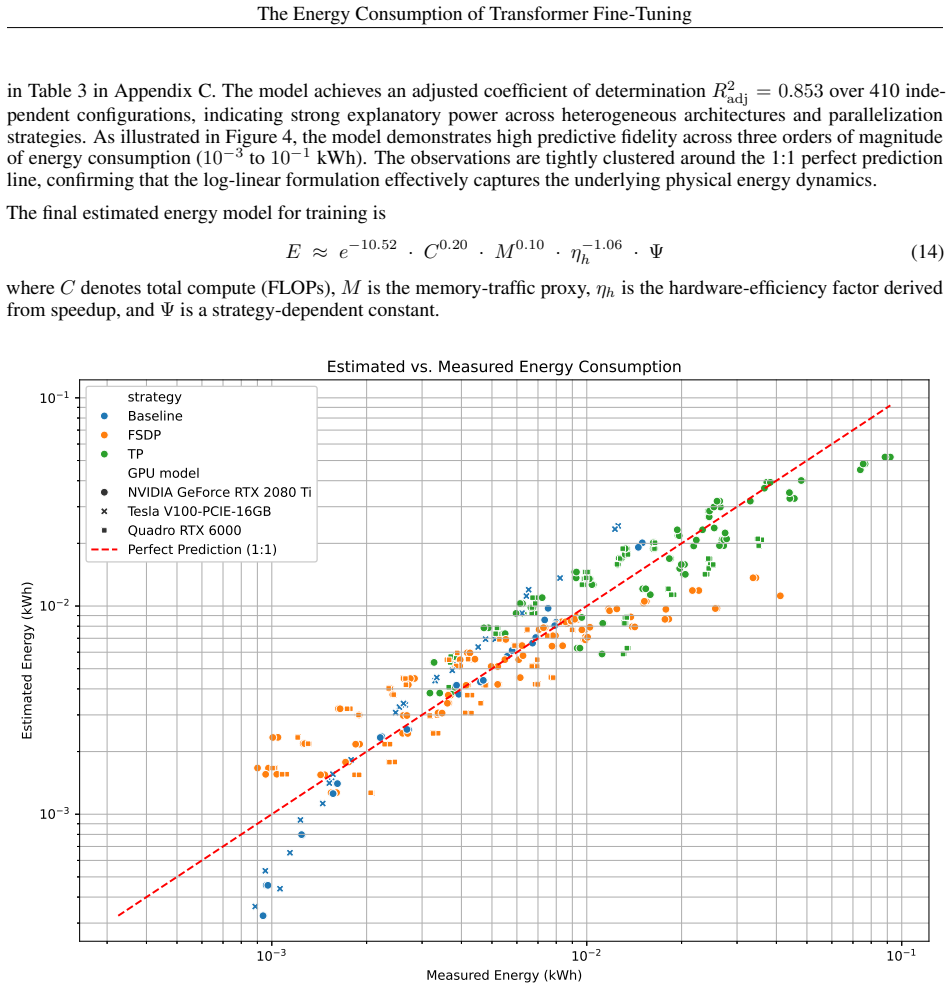
We present a framework for modeling the energy consumption of Transformer training on multiple GPUs. Using controlled architectural sweeps of BERT models, we relate measured energy to lightweight proxies for compute, memory traffic, and hardware efficiency. Inspired by roofline models, our approach incorporates a speedup-based hardware-efficiency factor that captures the effects of tensor parallelism and fully sharded data parallelism. We derive a scaling law model that accurately predicts training energy across heterogeneous configurations.
What carries the argument
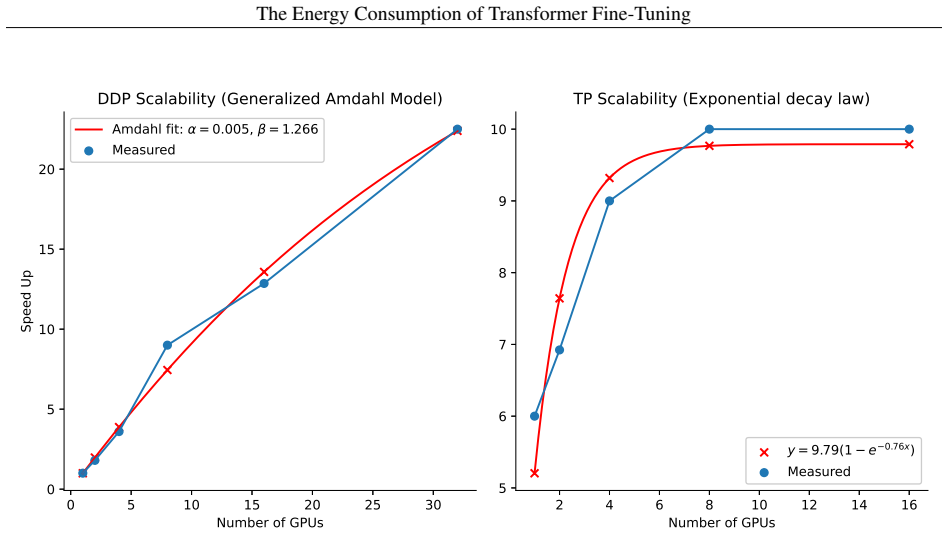
Speedup-based hardware-efficiency factor, derived from roofline-inspired measurements on BERT sweeps, that accounts for performance impact of tensor parallelism and fully sharded data parallelism when predicting energy.
Load-bearing premise
The speedup-based hardware-efficiency factor measured on controlled BERT sweeps is assumed to generalize and capture the effects of tensor parallelism and fully sharded data parallelism for arbitrary model and hardware configurations.
What would settle it
Measure energy consumption on a transformer model with a size or parallelism configuration outside the original BERT sweeps and test whether the scaling law predictions match the measured values within the claimed accuracy.
Figures
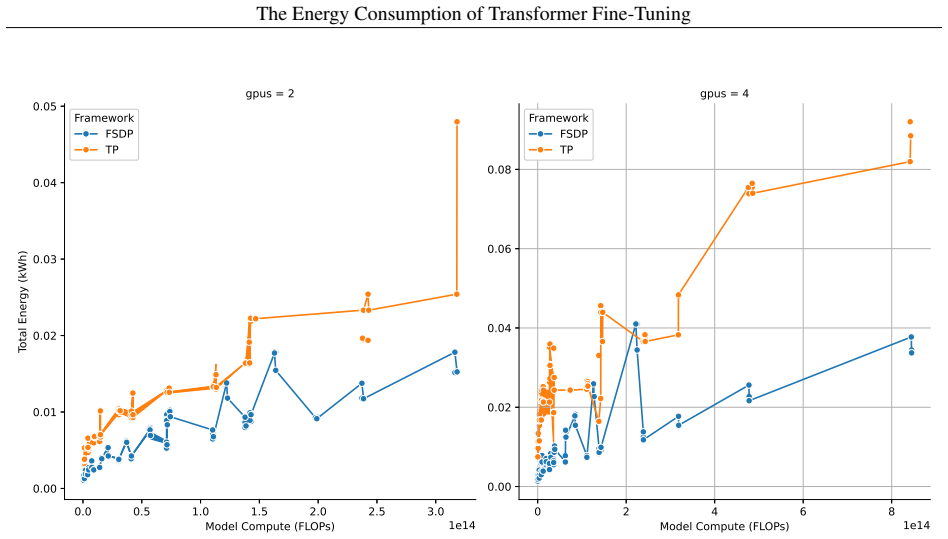
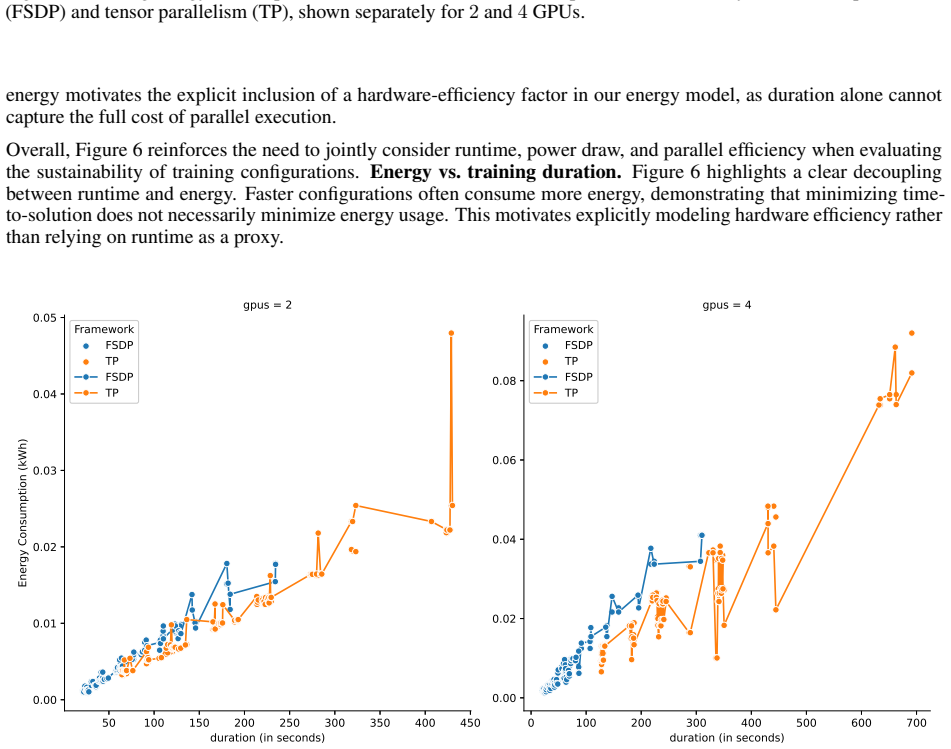
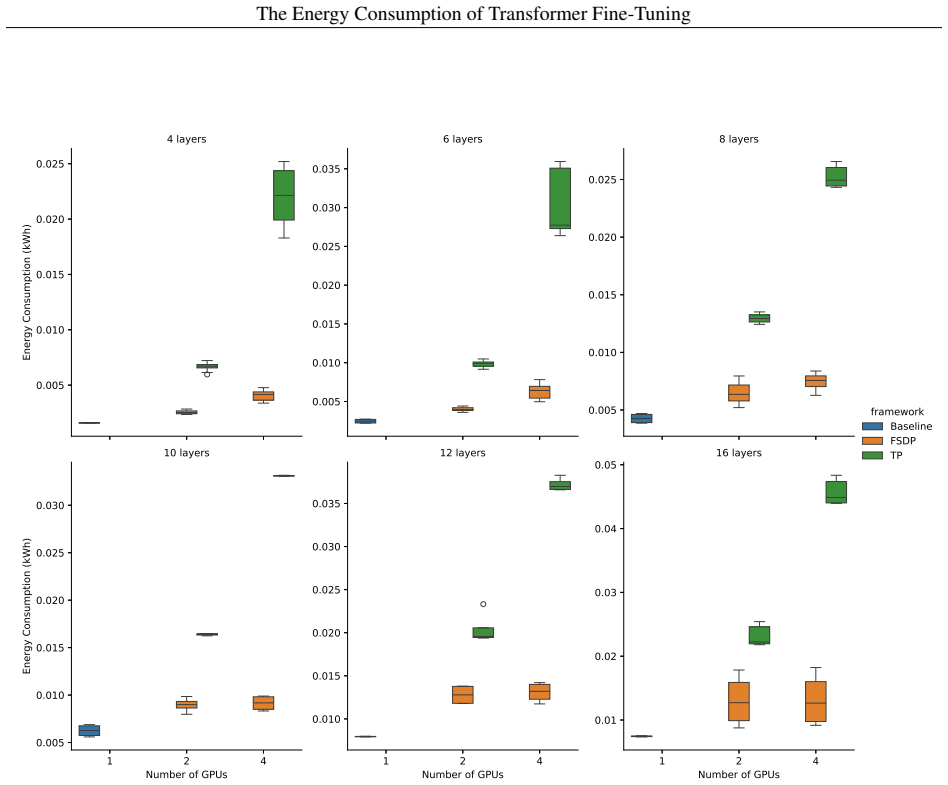
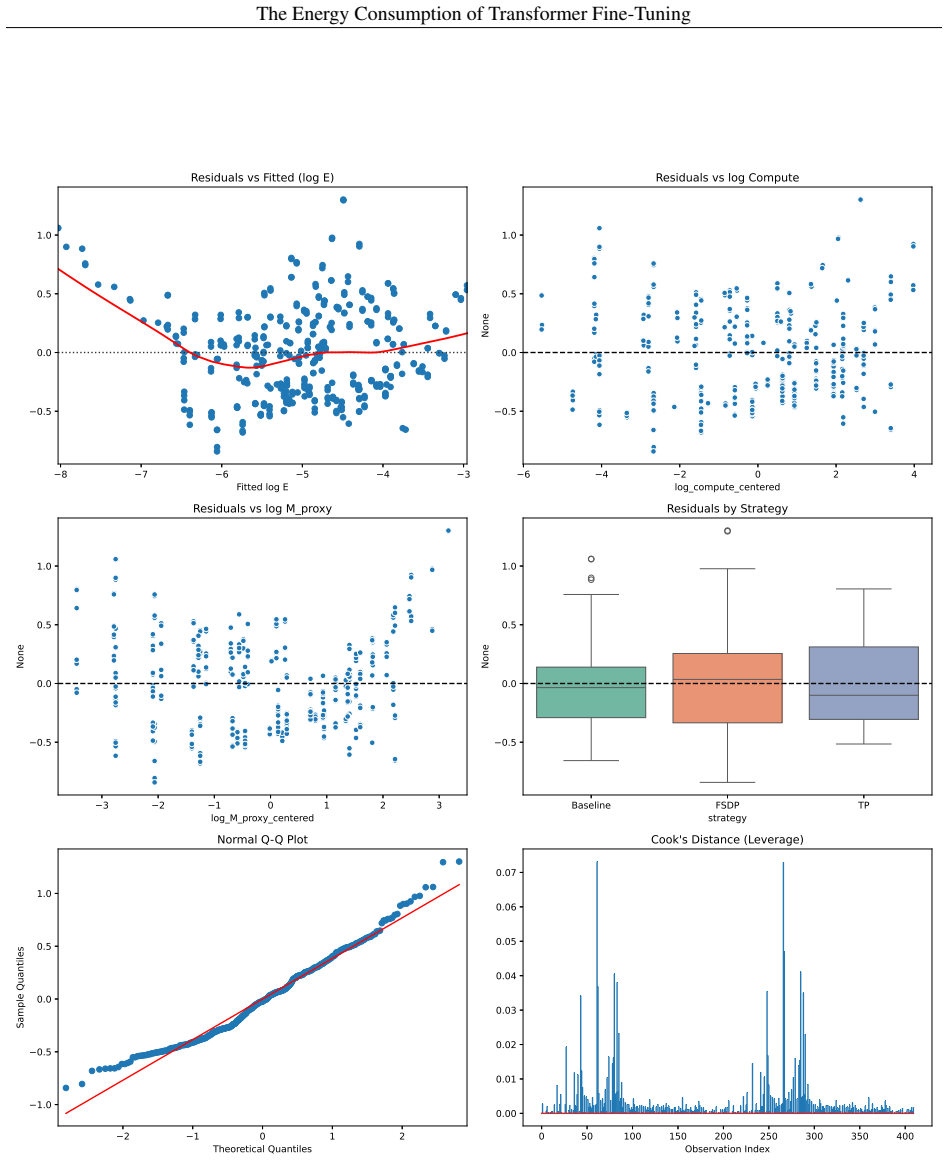
read the original abstract
Transformer-based models underpin modern natural language processing but incur rapidly growing computational and energy costs. As training scales in both model size and parallelism, accurately predicting energy consumption has become critical for sustainable and cost-aware system design. We present a framework for modeling the energy consumption of Transformer training on multiple GPUs. Using controlled architectural sweeps of BERT models, we relate measured energy to lightweight proxies for compute, memory traffic, and hardware efficiency. Inspired by roofline models, our approach incorporates a speedup-based hardware-efficiency factor that captures the effects of tensor parallelism and fully sharded data parallelism. We derive a scaling law model that accurately predicts training energy across heterogeneous configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a roofline-inspired framework for modeling the energy consumption of Transformer fine-tuning on multiple GPUs. Using controlled BERT architectural sweeps, it relates measured energy to lightweight proxies for compute and memory traffic plus a speedup-based hardware-efficiency factor intended to capture tensor parallelism and fully sharded data parallelism, deriving a scaling law claimed to accurately predict training energy across heterogeneous configurations.
Significance. If the central claim holds after proper validation, the work could supply a practical, lightweight tool for estimating energy costs during scaling of Transformer training, supporting more sustainable system design. The roofline inspiration and proxy-based approach are conceptually promising for avoiding full simulation, but the fitted efficiency factor introduces a generalization burden that must be resolved for the result to have lasting impact.
major comments (2)
- [Abstract] Abstract: the claim that the model 'accurately predicts training energy across heterogeneous configurations' is unsupported because the abstract supplies neither the explicit form of the scaling law, the definition of the hardware-efficiency factor, nor any validation metrics (prediction error, R^{2}, or held-out test configurations).
- [Abstract] Abstract: the speedup-based hardware-efficiency factor is fitted on controlled BERT sweeps and asserted to generalize to arbitrary model families, tensor-parallel degrees, and accelerator types; no cross-family or cross-hardware validation is described, which is load-bearing for the heterogeneous-configuration claim.
minor comments (1)
- The title refers to 'Fine-Tuning' while the abstract and body appear to address general training; clarify the intended scope.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to improve clarity and accuracy.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the model 'accurately predicts training energy across heterogeneous configurations' is unsupported because the abstract supplies neither the explicit form of the scaling law, the definition of the hardware-efficiency factor, nor any validation metrics (prediction error, R^{2}, or held-out test configurations).
Authors: We acknowledge that the abstract is concise and does not provide these supporting details. In the revised manuscript, we will expand the abstract to include the explicit mathematical form of the scaling law, a clear definition of the speedup-based hardware-efficiency factor, and report quantitative validation metrics including prediction error and R² on held-out configurations. This will better substantiate the claim within the abstract itself. revision: yes
-
Referee: [Abstract] Abstract: the speedup-based hardware-efficiency factor is fitted on controlled BERT sweeps and asserted to generalize to arbitrary model families, tensor-parallel degrees, and accelerator types; no cross-family or cross-hardware validation is described, which is load-bearing for the heterogeneous-configuration claim.
Authors: The paper's validation is based on BERT architectural sweeps across different model sizes and parallelism configurations (tensor parallelism and FSDP) on the evaluated GPU hardware. The term 'heterogeneous configurations' in the abstract refers to these variations within the BERT family and tested accelerators. We do not provide cross-family validation for other model architectures or different accelerator types. To address this, we will revise the abstract and discussion sections to precisely delineate the scope of the claimed generalization and note that extension to other families and hardware is an important direction for future work. This revision ensures the claims are aligned with the presented evidence. revision: yes
Circularity Check
Fitted speedup-based hardware-efficiency factor from BERT sweeps used as input to scaling-law predictions on heterogeneous configurations
specific steps
-
fitted input called prediction
[Abstract]
"Using controlled architectural sweeps of BERT models, we relate measured energy to lightweight proxies for compute, memory traffic, and hardware efficiency. Inspired by roofline models, our approach incorporates a speedup-based hardware-efficiency factor that captures the effects of tensor parallelism and fully sharded data parallelism. We derive a scaling law model that accurately predicts training energy across heterogeneous configurations."
The speedup-based hardware-efficiency factor is obtained by relating measured energy on BERT sweeps to proxies; the scaling law then uses this fitted factor to generate predictions. When the heterogeneous configurations overlap with or are statistically close to the sweep data, the 'predictions' reduce to re-application of the fitted parameter rather than an independent derivation.
full rationale
The paper fits a hardware-efficiency factor on controlled BERT architectural sweeps and incorporates it into a roofline-inspired model whose outputs are then presented as predictions for energy across heterogeneous model/parallelism/hardware setups. This matches the fitted-input-called-prediction pattern because the central scaling law depends on a data-derived proxy tuned to the same measurements used for validation, creating partial circularity even though the model may still contain independent structure from the compute and memory proxies.
Axiom & Free-Parameter Ledger
free parameters (2)
- hardware-efficiency factor
- proxy coefficients for compute and memory traffic
axioms (1)
- domain assumption Energy consumption can be expressed as a scaling law combining compute, memory traffic, and hardware efficiency proxies.
Reference graph
Works this paper leans on
-
[1]
Greenwade
George D. Greenwade. The C omprehensive T ex A rchive N etwork ( CTAN ). TUGBoat. 1993
1993
-
[2]
2025 , MONTH = Oct, DOI =
Zoubeirou a Mayaki, Mansour and Charpenay, Victor , URL =. 2025 , MONTH = Oct, DOI =
2025
-
[3]
Advances in Neural Information Processing Systems , volume=
Revisiting neural scaling laws in language and vision , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
2022 , eprint=
A Survey and Empirical Evaluation of Parallel Deep Learning Frameworks , author=. 2022 , eprint=
2022
-
[5]
Jared Kaplan and Sam McCandlish and Tom Henighan OpenAI and Tom B Brown OpenAI and Benjamin Chess OpenAI and Rewon Child OpenAI and Scott Gray OpenAI and Alec Radford OpenAI and Jeffrey Wu OpenAI and Dario Amodei OpenAI , title =
-
[6]
Rae and Oriol Vinyals and Laurent Sifre , month =
Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Eric...
-
[7]
Brain informatics , volume=
How Amdahl’s Law limits the performance of large artificial neural networks: why the functionality of full-scale brain simulation on processor-based simulators is limited , author=. Brain informatics , volume=. 2019 , publisher=
2019
-
[8]
arXiv preprint arXiv:2111.04949 , year=
A survey and empirical evaluation of parallel deep learning frameworks , author=. arXiv preprint arXiv:2111.04949 , year=
-
[9]
Deep Learning Scaling is Predictable, Empirically
Deep learning scaling is predictable, empirically , author=. arXiv preprint arXiv:1712.00409 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2405.21015 , year=
The rising costs of training frontier AI models , author=. arXiv preprint arXiv:2405.21015 , year=
-
[11]
Proceedings of the AAAI conference on artificial intelligence , volume=
Energy and policy considerations for modern deep learning research , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[12]
2024 , url=
Ahmad Faiz and Sotaro Kaneda and Ruhan Wang and Rita Chukwunyere Osi and Prateek Sharma and Fan Chen and Lei Jiang , booktitle=. 2024 , url=
2024
-
[13]
Carbon Emissions and Large Neural Network Training
Carbon emissions and large neural network training , author=. arXiv preprint arXiv:2104.10350 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , year=
Attention is all you need , author=. Advances in Neural Information Processing Systems , year=
-
[15]
and Ho, Qirong and Dai, Wei and Kim, Jin Kyu and Wei, Jinliang and Lee, Seunghak and Zheng, Xun and Xie, Pengtao and Kumar, Abhimanu and Yu, Yaoliang , journal=
Xing, Eric P. and Ho, Qirong and Dai, Wei and Kim, Jin Kyu and Wei, Jinliang and Lee, Seunghak and Zheng, Xun and Xie, Pengtao and Kumar, Abhimanu and Yu, Yaoliang , journal=. Petuum: A New Platform for Distributed Machine Learning on Big Data , year=
-
[16]
Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages=
Efficient large-scale language model training on gpu clusters using megatron-lm , author=. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages=
-
[17]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[18]
arXiv preprint arXiv:2109.10465 , year=
Scalable and efficient moe training for multitask multilingual models , author=. arXiv preprint arXiv:2109.10465 , year=
-
[19]
The Twelfth International Conference on Learning Representations , year=
Parallelizing non-linear sequential models over the sequence length , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
2016 , title =
Moser, Martin , keywords =. 2016 , title =
2016
-
[21]
arXiv preprint arXiv:2305.00798 , year=
Performance and Energy Consumption of Parallel Machine Learning Algorithms , author=. arXiv preprint arXiv:2305.00798 , year=
-
[22]
Proceedings of the 44th annual international symposium on computer architecture , pages=
In-datacenter performance analysis of a tensor processing unit , author=. Proceedings of the 44th annual international symposium on computer architecture , pages=
-
[23]
International conference on machine learning , pages=
The evolved transformer , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[24]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[26]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[27]
arXiv preprint arXiv:2001.09977 , year=
Towards a human-like open-domain chatbot , author=. arXiv preprint arXiv:2001.09977 , year=
-
[28]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[29]
Proceedings of Machine Learning and Systems , volume=
Sustainable ai: Environmental implications, challenges and opportunities , author=. Proceedings of Machine Learning and Systems , volume=
-
[30]
Journal of Machine Learning Research , volume=
Towards the systematic reporting of the energy and carbon footprints of machine learning , author=. Journal of Machine Learning Research , volume=
-
[31]
The 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Power hungry processing: Watts driving the cost of AI deployment? , author=. The 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[32]
Journal of Machine Learning Research , volume=
Estimating the carbon footprint of bloom, a 176b parameter language model , author=. Journal of Machine Learning Research , volume=
-
[33]
Mixed precision training , author=. arXiv preprint arXiv:1710.03740 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Training Deep Nets with Sublinear Memory Cost
Training deep nets with sublinear memory cost , author=. arXiv preprint arXiv:1604.06174 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[36]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Mobilenets: Efficient convolutional neural networks for mobile vision applications , author=. arXiv preprint arXiv:1704.04861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) , pages=
vDNN: Virtualized deep neural networks for scalable, memory-efficient neural network design , author=. 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) , pages=. 2016 , organization=
2016
-
[38]
arXiv preprint arXiv:2303.01980 , year=
Towards energy-efficient deep learning: An overview of energy-efficient approaches along the deep learning lifecycle , author=. arXiv preprint arXiv:2303.01980 , year=
-
[39]
2023 IEEE/ACM 2nd International Conference on AI Engineering--Software Engineering for AI (CAIN) , pages=
Uncovering energy-efficient practices in deep learning training: Preliminary steps towards green ai , author=. 2023 IEEE/ACM 2nd International Conference on AI Engineering--Software Engineering for AI (CAIN) , pages=. 2023 , organization=
2023
-
[40]
Energy-Efficient Machine Learning Acceleration: From Technologies to Circuits and Systems , year=
Ogbogu, Chukwufumnanya and Abernot, Madeleine and Delacour, Corentin and Todri-Sanial, Aida and Pasricha, Sudeep and Pande, Partha Pratim , booktitle=. Energy-Efficient Machine Learning Acceleration: From Technologies to Circuits and Systems , year=
-
[41]
Benoit Courty and Victor Schmidt and Sasha Luccioni and Goyal-Kamal and MarionCoutarel and Boris Feld and Jérémy Lecourt and LiamConnell and Amine Saboni and Inimaz and supatomic and Mathilde Léval and Luis Blanche and Alexis Cruveiller and ouminasara and Franklin Zhao and Aditya Joshi and Alexis Bogroff and Hugues de Lavoreille and Niko Laskaris and Edoa...
-
[42]
Williams, Samuel and Waterman, Andrew and Patterson, David , title =. Commun. ACM , month = apr, pages =. 2009 , issue_date =. doi:10.1145/1498765.1498785 , abstract =
-
[43]
Jacek Czaja and Michal Gallus and Joanna Wozna and Adam Grygielski and Luo Tao , title =. CoRR , volume =. 2020 , url =. 2009.11224 , timestamp =
-
[44]
Time-Based Roofline for Deep Learning Performance Analysis , year=
Wang, Yunsong and Yang, Charlene and Farrell, Steven and Zhang, Yan and Kurth, Thorsten and Williams, Samuel , booktitle=. Time-Based Roofline for Deep Learning Performance Analysis , year=
-
[45]
and Houston, Mike and Luebke, David and Green, Simon and Stone, John E
Owens, John D. and Houston, Mike and Luebke, David and Green, Simon and Stone, John E. and Phillips, James C. , journal=. GPU Computing , year=
-
[46]
Computer Graphics Forum , year=
A Survey of General‐Purpose Computation on Graphics Hardware , author=. Computer Graphics Forum , year=
-
[47]
A Roofline Model of Energy , year=
Choi, Jee Whan and Bedard, Daniel and Fowler, Robert and Vuduc, Richard , booktitle=. A Roofline Model of Energy , year=
-
[48]
2025 , eprint=
Scaling Laws for Energy Efficiency of Local LLMs , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.