Dustin: Draft-Augmented Sparse Verification for Efficient Long-Context Generation with Speculative Decoding
Pith reviewed 2026-06-26 00:10 UTC · model grok-4.3
The pith
Draft-augmented sparse verification lets speculative decoding handle 32k contexts with 9x end-to-end speedup and little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
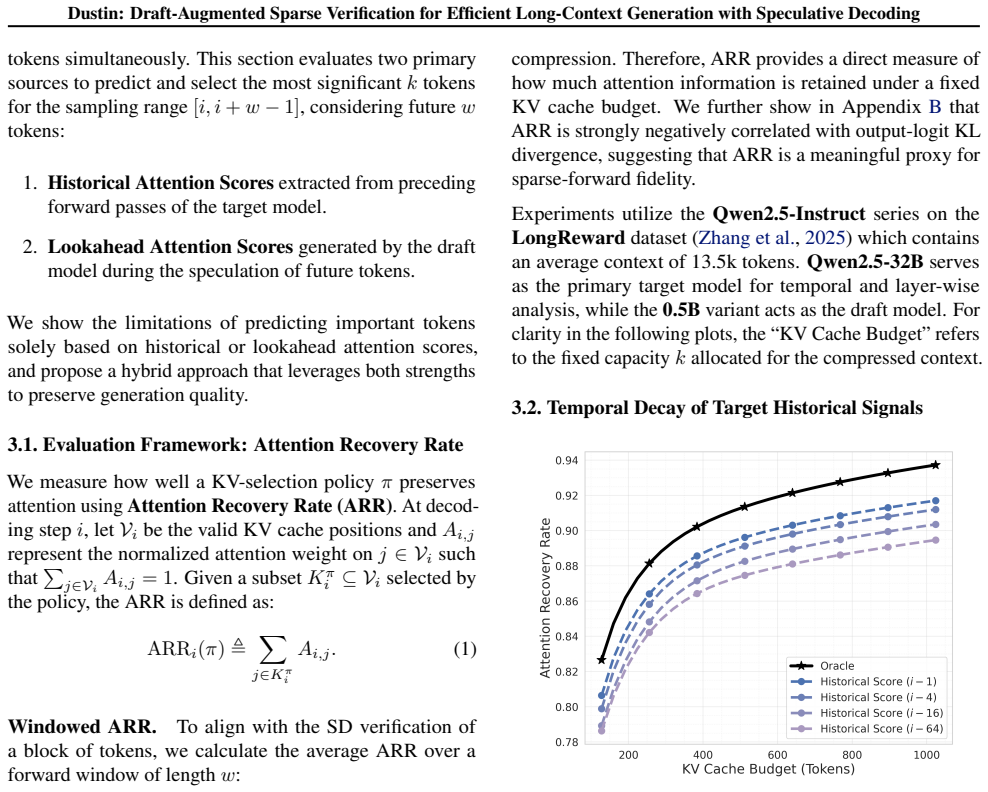
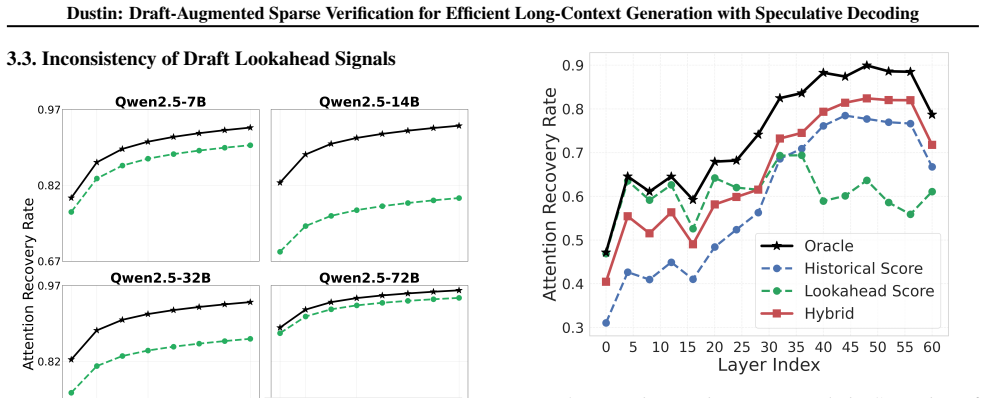
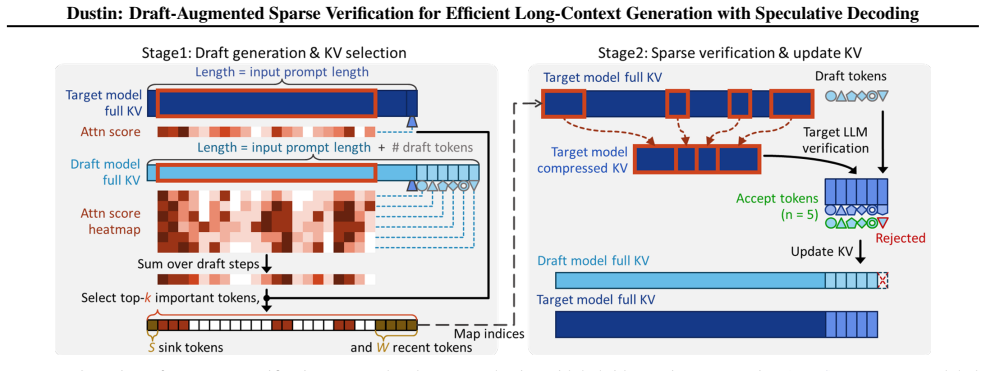
Dustin integrates lookahead signals from the draft model with historical attention from the target model to identify critical tokens with high fidelity across multi-step verification windows and employs a sparse estimation scheme that restricts importance scoring to a minimal subset of attention heads.
What carries the argument
Draft-augmented sparse verification, which merges draft-model lookahead with target-model attention history and limits importance scoring to a few heads to avoid full recomputation.
If this is right
- Self-attention latency drops by a factor of 27.85 at 32k context.
- Full decoding throughput rises by a factor of 9.17.
- Accuracy loss on long-context benchmarks remains negligible.
- The same token-selection logic works across multi-batch inference.
Where Pith is reading between the lines
- Hardware that is memory-bandwidth limited could run much longer contexts without proportional slowdown.
- The same draft-plus-history signal might reduce recomputation in other verification-heavy LLM stages.
- Repeating the head-subset choice on different model families would test whether the sparse scoring stays reliable.
Load-bearing premise
Draft lookahead plus attention history from only a few heads will keep selecting the right tokens accurately over successive verification steps.
What would settle it
At 32k length on Qwen2.5-72B, measure accuracy on LongBench after running the method; a drop larger than a few percent or an end-to-end speedup below 5x would show the token selection is not faithful enough.
Figures


read the original abstract
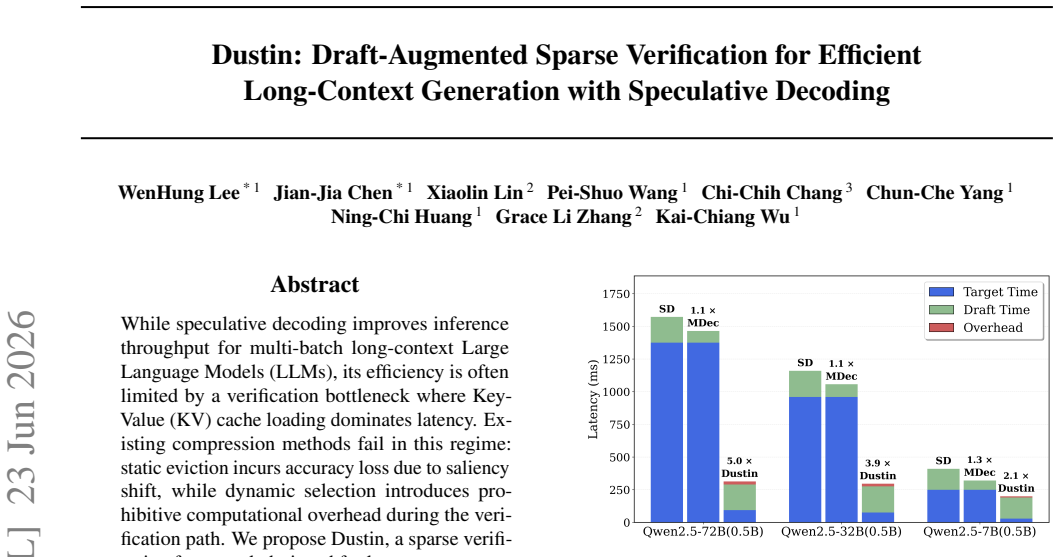
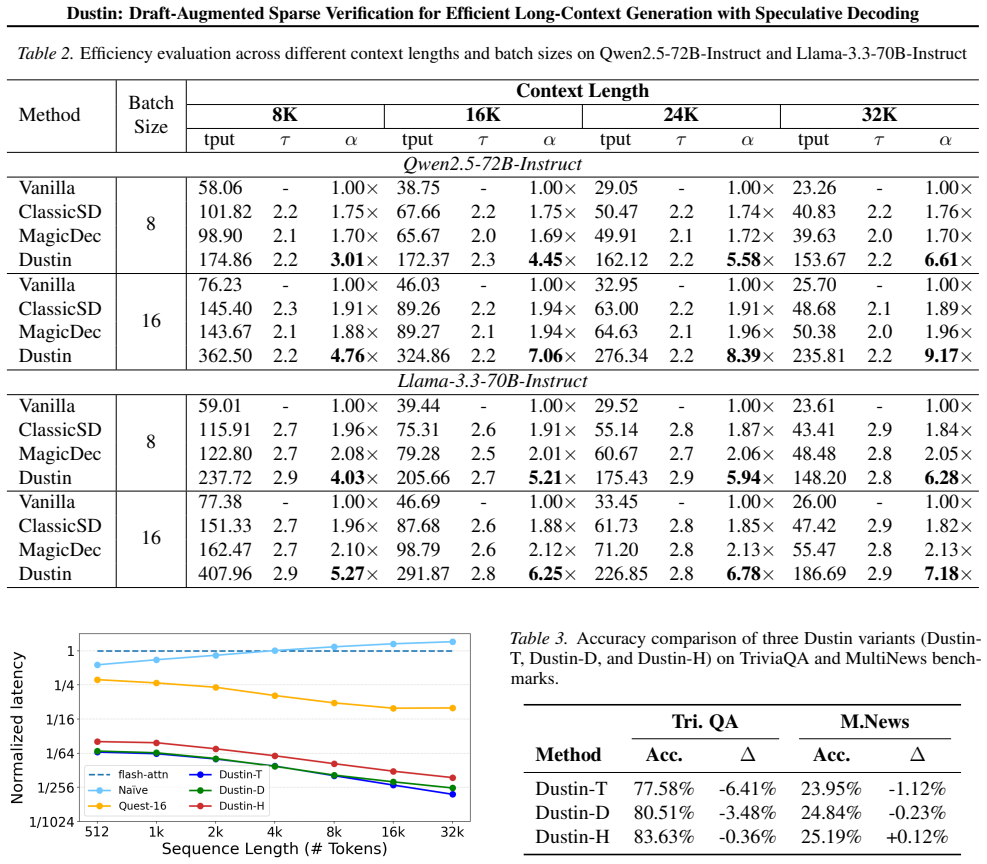
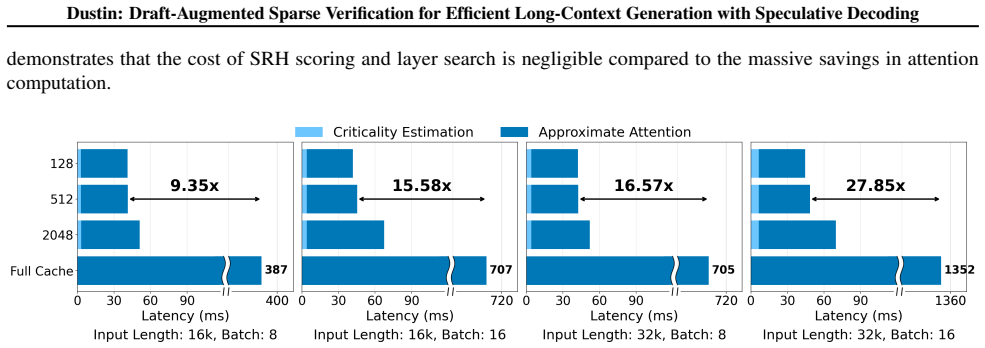
While speculative decoding improves inference throughput for multi-batch long-context Large Language Models (LLMs), its efficiency is often limited by a verification bottleneck where Key-Value (KV) cache loading dominates latency. Existing compression methods fail in this regime: static eviction incurs accuracy loss due to saliency shift, while dynamic selection introduces prohibitive computational overhead during the verification path. We propose Dustin, a sparse verification framework designed for long-context speculative decoding. Dustin integrates lookahead signals from the draft model with historical attention from the target model to identify critical tokens with high fidelity across multi-step verification windows. To reduce recomputation latency, this approach further employs a sparse estimation scheme that restricts importance scoring to a minimal subset of attention heads. Evaluations on PG-19 and LongBench with Qwen2.5-72B demonstrate that Dustin achieves a 27.85x speedup in self-attention and a 9.17x end-to-end decoding speedup at a 32k sequence length, all with negligible accuracy degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dustin, a sparse verification framework for long-context speculative decoding. It combines draft-model lookahead signals with target-model historical attention to identify critical KV tokens and applies a sparse estimation scheme that restricts importance scoring to a minimal subset of attention heads, thereby reducing recomputation latency during verification. On PG-19 and LongBench with Qwen2.5-72B at 32k context, the method is reported to deliver 27.85× self-attention speedup and 9.17× end-to-end decoding speedup while incurring negligible accuracy degradation.
Significance. If the accuracy preservation holds under the claimed conditions, Dustin would directly address the KV-cache loading bottleneck that limits speculative decoding throughput for long contexts, providing a practical route to higher inference efficiency without requiring changes to the underlying model architecture.
major comments (1)
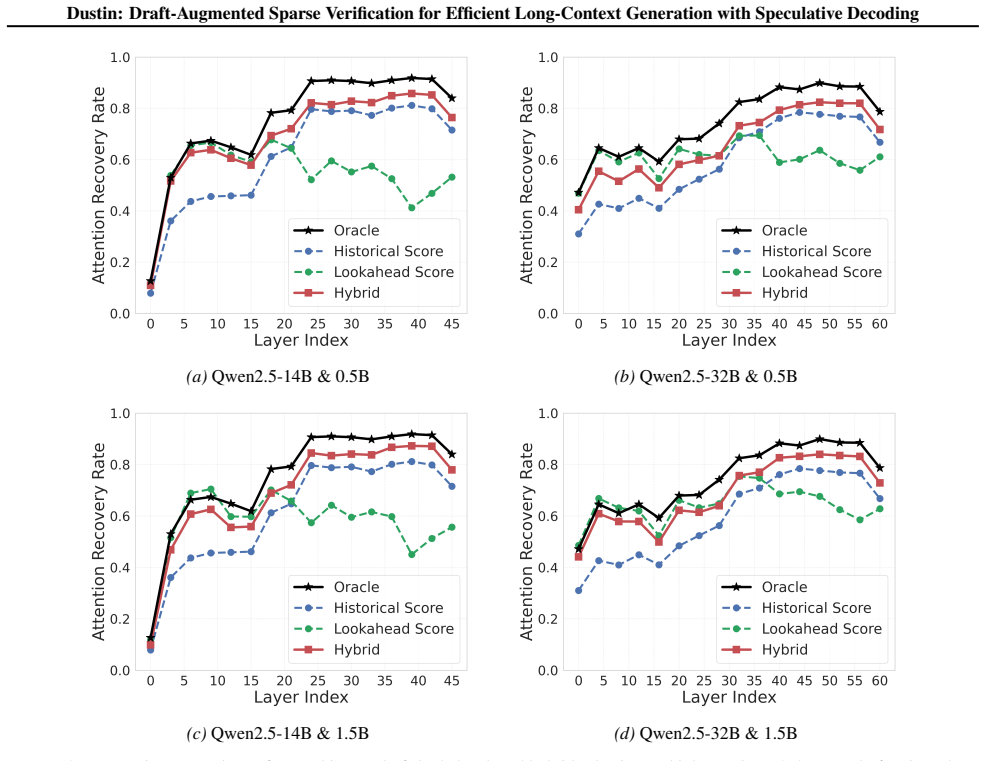
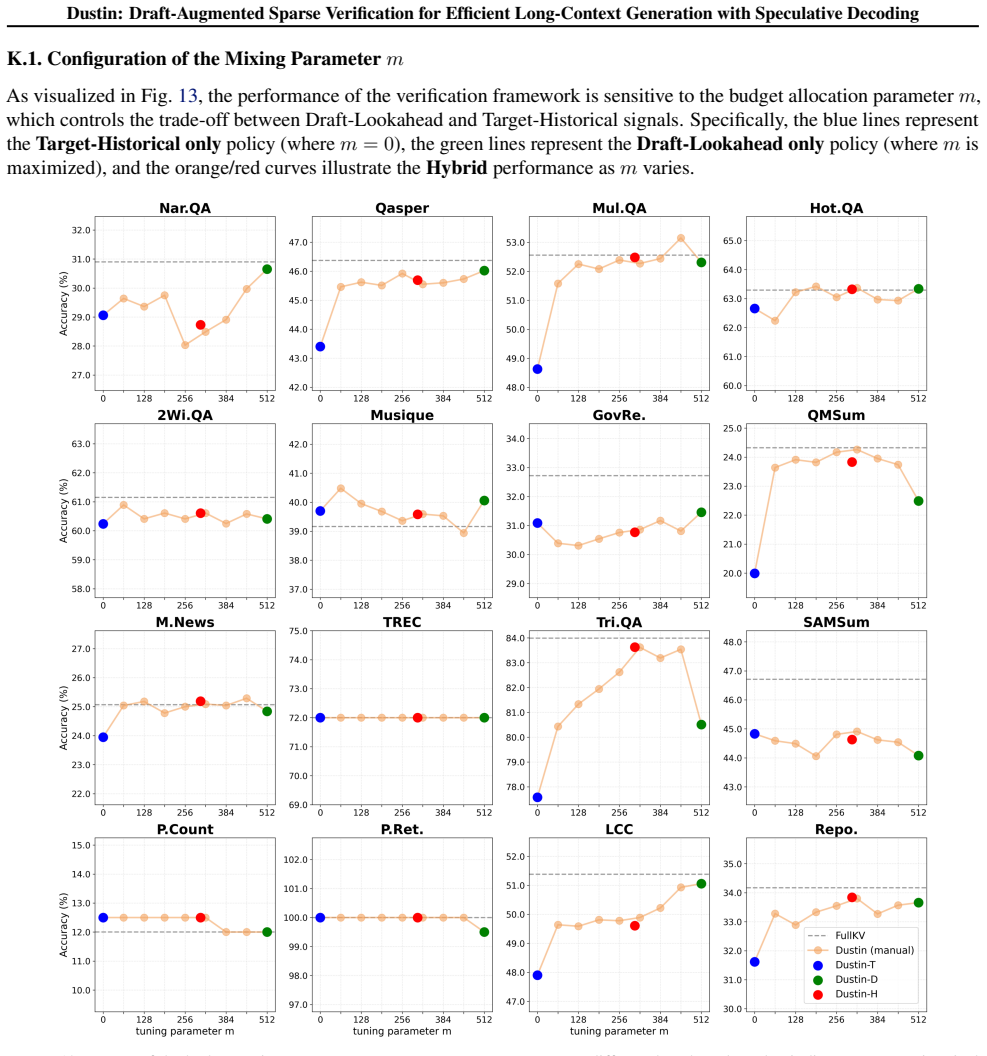
- [Abstract; §4 (Experiments) and §5 (Analysis)] The central claim of negligible accuracy degradation rests on the fidelity of the sparse head-restricted importance scorer across multi-step verification windows. No per-layer head-ablation results or multi-step token-overlap statistics are supplied to demonstrate that the minimal head subset continues to recover the same critical tokens that full-head scoring would select when saliency shifts occur.
minor comments (1)
- [§3 (Method)] The notation used to define the minimal head subset and the exact combination of draft lookahead and target historical attention scores should be formalized with equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence on the fidelity of the sparse head-restricted importance scorer. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract; §4 (Experiments) and §5 (Analysis)] The central claim of negligible accuracy degradation rests on the fidelity of the sparse head-restricted importance scorer across multi-step verification windows. No per-layer head-ablation results or multi-step token-overlap statistics are supplied to demonstrate that the minimal head subset continues to recover the same critical tokens that full-head scoring would select when saliency shifts occur.
Authors: We agree that explicit verification of the sparse scorer's fidelity is important for supporting the accuracy claim. While the end-to-end results on PG-19 and LongBench already show negligible degradation, we will add per-layer head-ablation results and multi-step token-overlap statistics to Section 5 (Analysis) in the revision. These will demonstrate that the minimal head subset recovers the same critical tokens as full-head scoring across verification windows despite saliency shifts. revision: yes
Circularity Check
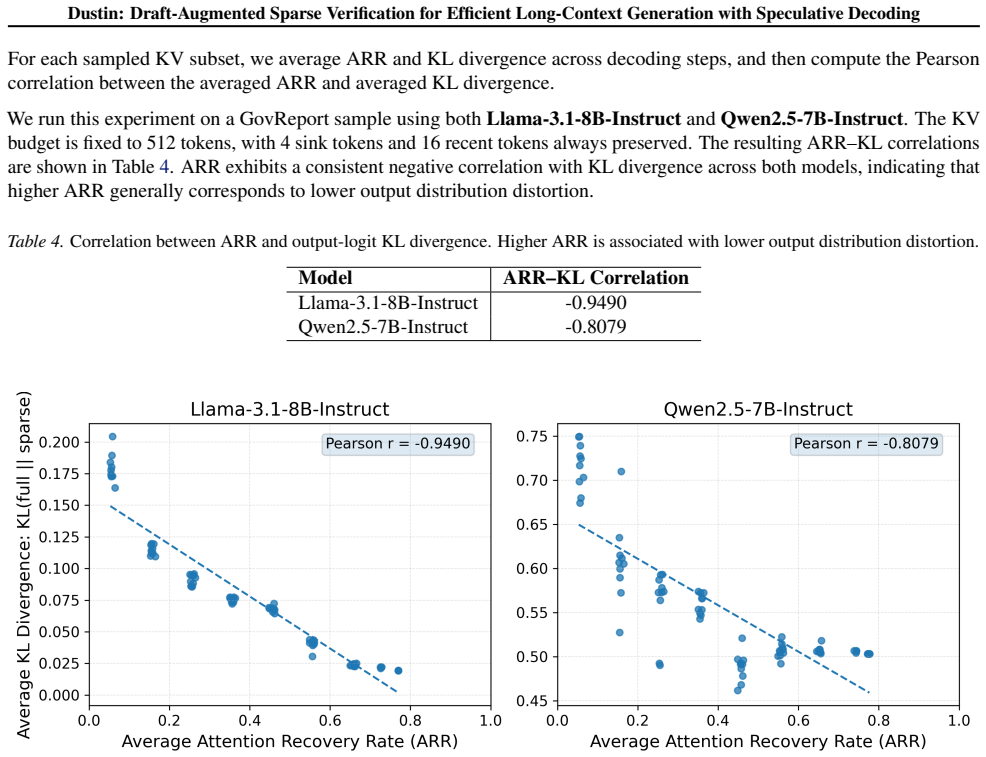
No significant circularity; empirical claims only
full rationale
The paper presents Dustin as an empirical engineering framework for sparse verification in speculative decoding. It reports measured speedups (27.85x self-attention, 9.17x end-to-end) on PG-19 and LongBench with Qwen2.5-72B at 32k length, framed as experimental outcomes rather than any derivation, fitted parameter, or self-referential prediction. No equations, ansatzes, uniqueness theorems, or self-citations that reduce claims to inputs by construction appear in the abstract or described content. The central assertions rest on benchmark measurements, which are externally falsifiable and independent of the method's internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Cai, Z., Zhang, Y ., Gao, B., Liu, Y ., Li, Y ., Liu, T., Lu, K., Xiong, W., Dong, Y ., Hu, J., et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Accelerating Large Language Model Decoding with Speculative Sampling
Chen, C., Borgeaud, S., Irving, G., Lespiau, J.-B., Sifre, L., and Jumper, J. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Sequoia: Scalable, robust, and hardware-aware speculative decoding
Chen, Z., May, A., Svirschevski, R., Huang, Y ., Ryabinin, M., Jia, Z., and Chen, B. Sequoia: Scalable, robust, and hardware-aware speculative decoding.arXiv preprint arXiv:2402.12374,
-
[5]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Transformers are multi-state rnns.arXiv preprint arXiv:2401.06104,
Oren, M., Hassid, M., Yarden, N., Adi, Y ., and Schwartz, R. Transformers are multi-state rnns.arXiv preprint arXiv:2401.06104,
-
[8]
Compressive Transformers for Long-Range Sequence Modelling
Rae, J. W., Potapenko, A., Jayakumar, S. M., and Lillicrap, T. P. Compressive transformers for long-range sequence modelling.arXiv preprint arXiv:1911.05507,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[9]
E.-H., May, A., Chen, T., and Chen, B
Sadhukhan, R., Chen, J., Chen, Z., Tiwari, V ., Lai, R., Shi, J., Yen, I. E.-H., May, A., Chen, T., and Chen, B. Magicdec: Breaking the latency-throughput tradeoff for long context generation with speculative decoding.arXiv preprint arXiv:2408.11049,
-
[10]
Specattn: Speculating sparse attention.arXiv preprint arXiv:2510.27641,
Shah, H. Specattn: Speculating sparse attention.arXiv preprint arXiv:2510.27641,
-
[11]
Sun, H., Chen, Z., Yang, X., Tian, Y ., and Chen, B. Tri- force: Lossless acceleration of long sequence generation with hierarchical speculative decoding.arXiv preprint arXiv:2404.11912,
-
[12]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
10 Dustin: Draft-Augmented Sparse Verification for Efficient Long-Context Generation with Speculative Decoding Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
W., Keutzer, K., and Gholami, A
Tiwari, R., Xi, H., Tomar, A., Hooper, C., Kim, S., Hor- ton, M., Najibi, M., Mahoney, M. W., Keutzer, K., and Gholami, A. Quantspec: Self-speculative decoding with hierarchical quantized kv cache.arXiv preprint arXiv:2502.10424,
-
[14]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yang, Q. A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y .-C., Wa...
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
Smallkv: Small model assisted compensa- tion of kv cache compression for efficient llm inference
Zhao, Y ., Peng, Y ., Nguyen, C.-T., Li, Z., Wang, X., Zhao, H., and Fu, X. Smallkv: Small model assisted compensa- tion of kv cache compression for efficient llm inference. arXiv preprint arXiv:2508.02751,
-
[18]
speculating four tokens ( Γ = 4 ). By downsizing the estimator to 1 target layer with 4 heads and 3 draft layers with 4 heads (denoted as L∗, H∗), the overhead ratio relative to the full hybrid calculation is derived as follows: Overhead Ratio= (H ∗ d ·L ∗ d ·Γ) + (H ∗ t ·L ∗ t ·1) (Hd ·L d ·Γ) + (H t ·L t ·1) = (4·3·4) + (4·1·1) (14·24·4) + (64·80·1) = 4...
2024
-
[19]
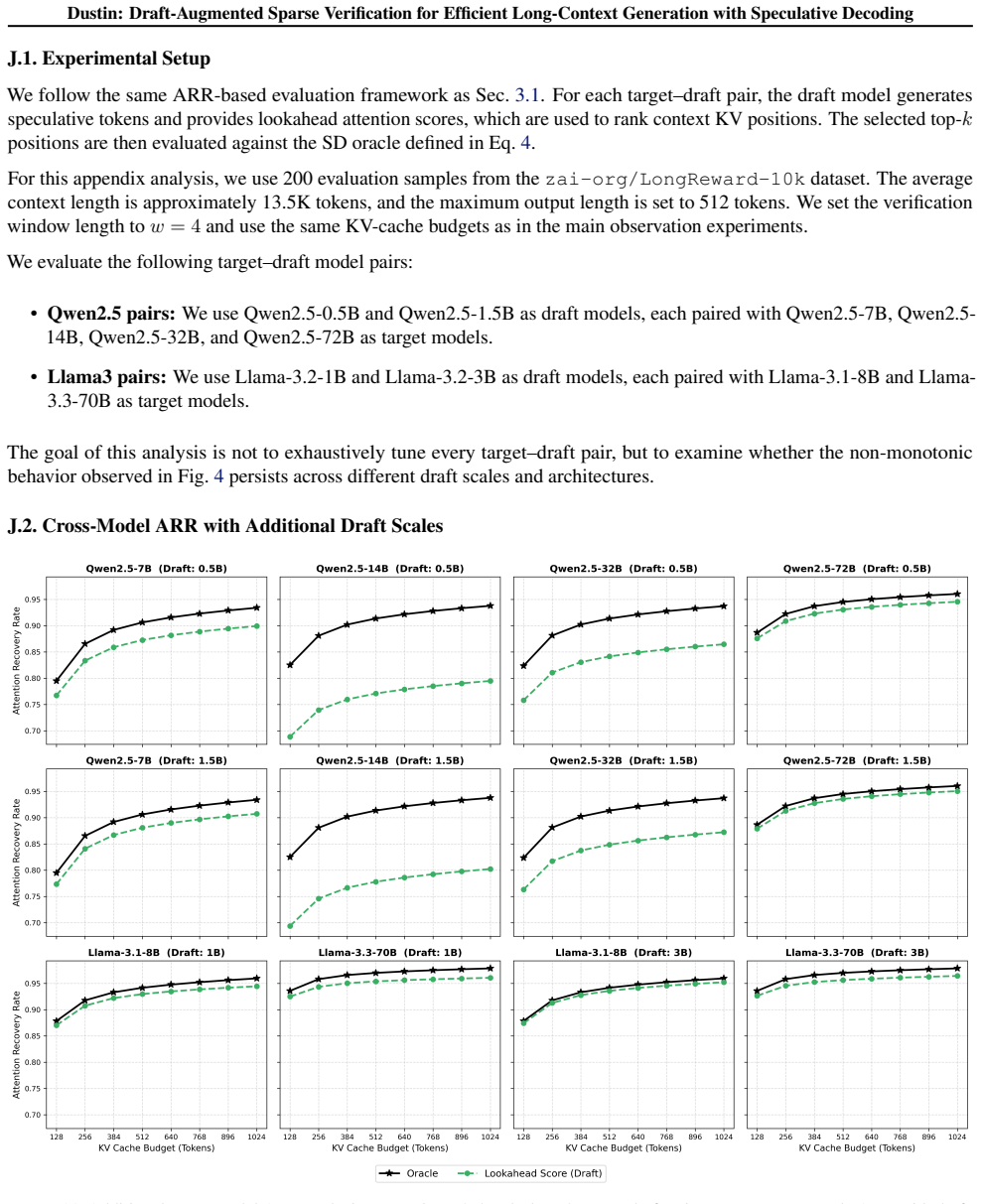
Importantly, this procedure is performed once per model pair and does not require per-task or per-dataset recalibration. SRH identification cost.We follow the SRH identification procedure of CompressKV (Lin et al., 2025), where retrieval- oriented heads are identified once for a model and then reused across downstream tasks. To quantify the practical cost...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.