Benchmarking the Alignment of Data-Quality Metrics, Human Judgment and Land-Cover Segmentation Performance for Earth Observation
Pith reviewed 2026-06-25 21:43 UTC · model grok-4.3
The pith
Automatic metrics for synthetic Earth observation images misalign with human judgment and segmentation performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results reveal a stark misalignment: semantics-preserving perturbations such as rotation drastically alter metric scores while leaving human recognition unaffected, and synthetic samples that score poorly on automatic metrics achieve comparable or higher perceived realism, and can improve downstream performance when combined with real data. By benchmarking semantic segmentation models trained on mixed real-synthetic datasets, we demonstrate that quality metrics rooted in ImageNet-pretrained feature spaces are unreliable indicators for geospatial data.
What carries the argument
Benchmarking semantic segmentation models on mixed real-synthetic Earth observation datasets while comparing automatic fidelity metrics to human perception ratings.
If this is right
- Semantics-preserving perturbations such as rotation change automatic metric scores substantially while leaving human recognition unaffected.
- Synthetic samples that score poorly on automatic metrics can achieve comparable or higher perceived realism to humans.
- Synthetic data that scores poorly on metrics can still improve land-cover segmentation performance when combined with real data.
- Quality metrics rooted in ImageNet-pretrained feature spaces are unreliable indicators for geospatial data utility.
- Automatic quality evaluation of synthetic datasets should be grounded in downstream task performance and human evaluation.
Where Pith is reading between the lines
- The misalignment may extend to other remote sensing tasks such as object detection or change detection that also rely on spatial structure.
- Task-specific quality metrics designed around geospatial semantics could replace or supplement general fidelity measures.
- Data curation pipelines for Earth observation models may need to incorporate routine human evaluation alongside or instead of automatic scores.
- Similar divergences could appear in other structured imaging domains that differ from the natural-image statistics underlying ImageNet features.
Load-bearing premise
The specific semantics-preserving perturbations tested and the land-cover segmentation task serve as valid proxies for general data utility in Earth observation applications.
What would settle it
If the ranking of mixed real-synthetic training sets by segmentation accuracy exactly matched their ranking by FID or KID scores across multiple perturbations, that would show the metrics are reliable and falsify the misalignment claim.
Figures
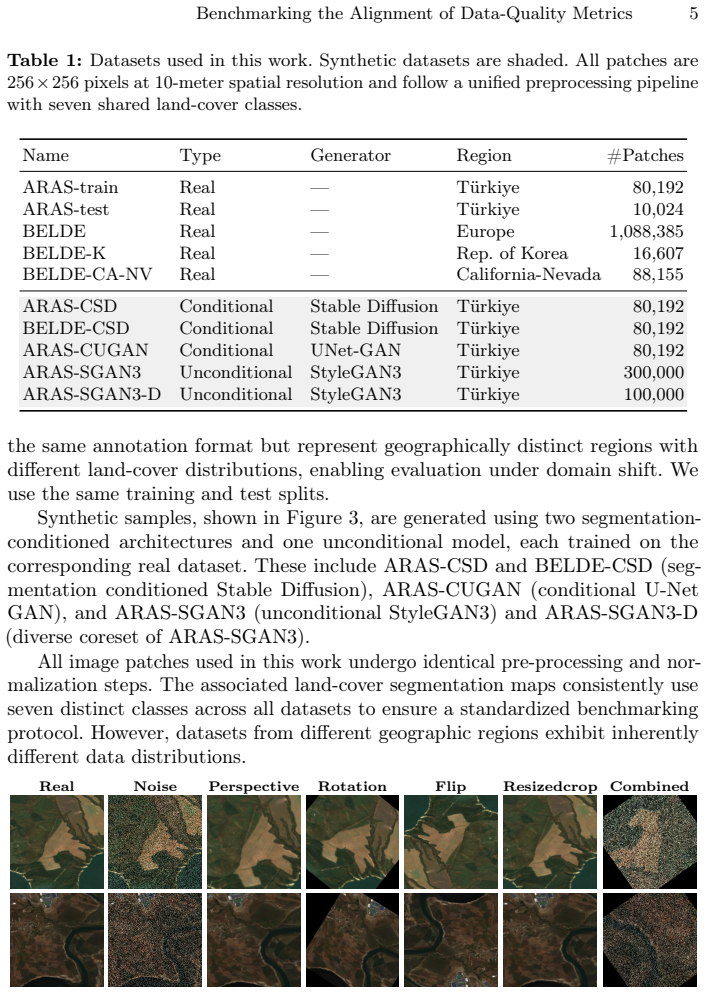

read the original abstract
Volume and quality of datasets are crucial for deep learning model training, yet they are often constrained by availability and data acquisition costs. Synthetic data augmentation can extend existing datasets with realistic images, and the quality of these images is generally assessed through fidelity metrics such as FID, KID, IS, LPIPS and SSIM that measure structural or distributional similarity. However, such metrics, including the widely used FID, focus on visual fidelity without reflecting downstream utility, and can diverge from human perception under perturbations that are imperceptible to human observers. In this work, we systematically evaluate Earth observation datasets alongside synthetic counterparts generated by deep generative models, comparing automatic metrics against human perception and downstream tasks. Our results reveal a stark misalignment: semantics-preserving perturbations such as rotation drastically alter metric scores while leaving human recognition unaffected, and synthetic samples that score poorly on automatic metrics achieve comparable or higher perceived realism, and can improve downstream performance when combined with real data. By benchmarking semantic segmentation models trained on mixed real-synthetic datasets, we demonstrate that quality metrics rooted in ImageNet-pretrained feature spaces are unreliable indicators for geospatial data. Our findings underscore that automatic quality evaluation of synthetic datasets should be grounded in downstream task performance and human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks automatic data-quality metrics (FID, KID, IS, LPIPS, SSIM) against human perception and land-cover semantic segmentation performance on Earth observation datasets and their synthetic counterparts generated by deep generative models. It reports misalignment under semantics-preserving perturbations such as rotation (which alter metric scores but not human recognition), shows that synthetics with poor metric scores can achieve comparable or higher perceived realism and improve downstream performance when mixed with real data, and concludes that ImageNet-pretrained feature-space metrics are unreliable indicators for geospatial data, advocating evaluation grounded in downstream tasks and human judgment.
Significance. If the empirical results hold under broader conditions, the work is significant for the EO community because it supplies concrete benchmarking evidence that standard generative-model metrics, calibrated on natural images, diverge from utility in geospatial applications. The mixed real-synthetic segmentation experiments offer a practical template for task-aware evaluation and could shift assessment practices away from purely distributional metrics.
major comments (2)
- [Conclusion] Conclusion and abstract: the claim that 'quality metrics rooted in ImageNet-pretrained feature spaces are unreliable indicators for geospatial data' is load-bearing on the tested semantics-preserving perturbations and the single land-cover segmentation downstream task serving as representative proxies; the manuscript provides no ablation on other EO tasks (e.g., object detection or change detection) or data regimes to establish that the observed misalignment is not task- or perturbation-specific.
- [Results] Results on downstream performance: the assertion that synthetics scoring poorly on automatic metrics can improve segmentation performance when combined with real data lacks reported dataset sizes, number of training runs, statistical significance tests, or error bars, making it impossible to judge whether the reported gains are robust or merely within noise.
minor comments (1)
- [Abstract] Abstract: quantitative details (dataset cardinalities, number of human raters, exact metric values) are omitted, which reduces the abstract's utility as a standalone summary.
Simulated Author's Rebuttal
Thank you for the constructive review. We address the major comments below by qualifying our claims and improving experimental reporting. We believe these revisions will strengthen the manuscript without requiring entirely new experiments.
read point-by-point responses
-
Referee: [Conclusion] Conclusion and abstract: the claim that 'quality metrics rooted in ImageNet-pretrained feature spaces are unreliable indicators for geospatial data' is load-bearing on the tested semantics-preserving perturbations and the single land-cover segmentation downstream task serving as representative proxies; the manuscript provides no ablation on other EO tasks (e.g., object detection or change detection) or data regimes to establish that the observed misalignment is not task- or perturbation-specific.
Authors: We agree that the claim as stated in the abstract and conclusion is broader than the specific evidence provided. In the revision we will qualify the language to indicate that the unreliability is shown for the evaluated semantics-preserving perturbations (e.g., rotation) and the land-cover semantic segmentation task. We will also insert a limitations paragraph noting that extension to other EO tasks such as object detection or change detection remains future work. This prevents overgeneralization while preserving the core finding that ImageNet-based metrics can diverge from human judgment and segmentation utility under the tested conditions. revision: yes
-
Referee: [Results] Results on downstream performance: the assertion that synthetics scoring poorly on automatic metrics can improve segmentation performance when combined with real data lacks reported dataset sizes, number of training runs, statistical significance tests, or error bars, making it impossible to judge whether the reported gains are robust or merely within noise.
Authors: We accept this criticism. The revised manuscript will report the precise sizes of the real and synthetic training sets used in the mixed-data experiments, the number of independent runs (five runs with distinct random seeds), standard-deviation error bars on all mIoU and accuracy figures, and the results of statistical significance tests (paired t-test or Wilcoxon signed-rank test) against the real-only baseline. These additions will allow readers to evaluate whether the observed improvements exceed experimental variability. revision: yes
Circularity Check
No circularity: empirical benchmarking with no derivations or self-referential claims
full rationale
The paper performs an empirical comparison of automatic fidelity metrics (FID, KID, etc.), human perception, and downstream land-cover segmentation performance on real and synthetic EO datasets. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on experimental outcomes rather than any reduction of results to inputs by construction. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2026)
Adamkiewicz, K., Moser, B.B., Frolov, S., Nauen, T.C., Raue, F., Dengel, A.: When pretty isn’t useful: Investigating why modern text-to-image models fail as reliable training data generators. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2026)
2026
-
[2]
Iscience28(5) (2025)
Adams, T., Birkenbihl, C., Otte, K., Ng, H.G., Rieling, J.A., Näher, A.F., Sax, U., Prasser, F., Fröhlich, H.: On the fidelity versus privacy and utility trade-off of synthetic patient data. Iscience28(5) (2025)
2025
-
[3]
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying MMD GANs (2018)
2018
-
[4]
arXiv preprint arXiv:2606.20909 (2026)
Çağlar, Ü.M., Temizel, A.: Belde: Building a large-scale earth-observation land-cover dataset for europe. arXiv preprint arXiv:2606.20909 (2026)
Pith/arXiv arXiv 2026
-
[5]
arXiv preprint arXiv:2603.09625 (2026)
Çağlar, Ü.M., Temizel, A.: Grounding synthetic data generation with vision and language models. arXiv preprint arXiv:2603.09625 (2026)
Pith/arXiv arXiv 2026
-
[6]
arXiv preprint arXiv:2406.18430 (2024) Benchmarking the Alignment of Data-Quality Metrics 15
Cetin, D., Schesch, B., Stamenkovic, P., Huber, N.B., Zünd, F., Helou, M.E.: Facial image feature analysis and its specialization for Fréchet distance and neighborhoods. arXiv preprint arXiv:2406.18430 (2024) Benchmarking the Alignment of Data-Quality Metrics 15
arXiv 2024
-
[7]
In: ECCV (2018)
Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: ECCV (2018)
2018
-
[8]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Franchi, G., Belkhir, N., Trong, D.N., Xia, G., Pilzer, A.: Towards understanding and quantifying uncertainty for text-to-image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8062–8072 (2025)
2025
-
[10]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: CLIPScore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[11]
Advances in neural information processing systems30(2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[12]
ISPRS International Journal of Geo-Information14(12), 481 (2025)
Hisam, E., Gimeno, J., Miraut, D., Pérez-Aixendri, M., Fernández, M., Gini, R., Rodríguez, R., Meoni, G., Seker, D.Z.: Impact of synthetic data on deep learning models for earth observation: Photovoltaic panel detection case study. ISPRS International Journal of Geo-Information14(12), 481 (2025)
2025
-
[13]
Journal of King Saud University Computer and Information Sciences (2026)
Huang, Q., Hu, C.: Survey on remote sensing scene classification: from traditional methods to large generative ai models. Journal of King Saud University Computer and Information Sciences (2026)
2026
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jayasumana, S., Ramalingam, S., Veit, A., Glasner, D., Chakrabarti, A., Kumar, S.: Rethinking FID: Towards a better evaluation metric for image generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9307–9315 (2024)
2024
-
[15]
arXiv preprint arXiv:2603.08064 (2026)
Jia, Z., Luo, P., Zhong, Y., Zhang, J., Zhou, J.: Evaluating generative models via one-dimensional code distributions. arXiv preprint arXiv:2603.08064 (2026)
arXiv 2026
-
[16]
In: ICLR Machine Learning for Remote Sensing (ML4RS) Workshop (2024)
Khammari, S., Fernandez-Laguilhoat, E., Sukhanov, S., Tankoyeu, I.: Synthetic data augmentation for earth observation object detection tasks. In: ICLR Machine Learning for Remote Sensing (ML4RS) Workshop (2024)
2024
-
[17]
arXiv preprint arXiv:2203.06026 (2022)
Kynkäänniemi, T., Karras, T., Aittala, M., Aila, T., Lehtinen, J.: The role of imagenet classes in Fréchet inception distance. arXiv preprint arXiv:2203.06026 (2022)
arXiv 2022
-
[18]
Li, H., Xiong, P., An, J., Wang, L.: Pyramid attention network for semantic segmentation. arXiv:1805.10180 (2018)
Pith/arXiv arXiv 2018
-
[19]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
2017
-
[20]
JMIR AI4, e65729 (2025)
Miletic, M., Sariyar, M.: Utility-based analysis of statistical approaches and deep learning models for synthetic data generation with focus on correlation structures: algorithm development and validation. JMIR AI4, e65729 (2025)
2025
-
[21]
Remote Sensing18(3), 466 (2026)
Mutakabbir, A., Lung, C.H., Zaman, M., Upadhyay, D., Naik, K., Millard, K., Ravichandran, T., Purcell, R.: Noah: A multi-modal and sensor fusion dataset for generative modeling in remote sensing. Remote Sensing18(3), 466 (2026)
2026
-
[22]
Pan, J., Lei, S., Fu, Y., Li, J., Liu, Y., Sun, Y., He, X., Peng, L., Huang, X., Zhao, B.: Earthsynth: Generating informative earth observation with diffusion models (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Parmar, G., Zhang, R., Zhu, J.Y.: On aliased resizing and surprising subtleties in GAN evaluation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11410–11420 (2022) 16 Ü.M. Çağlar A. Temizel
2022
-
[24]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[25]
In: Advances in Neural Information Processing Systems
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Im- proved techniques for training GANs. In: Advances in Neural Information Processing Systems. vol. 29, pp. 2234–2242 (2016)
2016
-
[26]
Information16(2), 81 (2025)
Sousa, T., Ries, B., Guelfi, N.: Data augmentation in earth observation: A diffusion model approach. Information16(2), 81 (2025)
2025
-
[27]
In: International Conference on Learning Representations (ICLR) (2016)
Theis, L., van den Oord, A., Bethge, M.: A note on the evaluation of generative models. In: International Conference on Learning Representations (ICLR) (2016)
2016
-
[28]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[29]
Advances in neural information processing systems34, 12077–12090 (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems34, 12077–12090 (2021)
2021
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[31]
In: International workshop on deep learning in medical image analysis (2018)
Zhou, Z., Rahman Siddiquee, M.M., Tajbakhsh, N., Liang, J.: Unet++: A nested u-net architecture for medical image segmentation. In: International workshop on deep learning in medical image analysis (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.