SoK: AI Secure Code Generation: Progress, Pitfalls, and Paths Forward
Pith reviewed 2026-06-25 22:39 UTC · model grok-4.3
The pith
AI models recognize secure coding principles in text yet frequently fail to translate that recognition into secure and functional code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that secure-coding-principle understanding is a statistically strong predictor of code-level outcomes, including functional correctness, security, and joint functional-security correctness. Yet substantial knowledge-actuation gaps remain: models can recognize relevant security principles but still fail to translate them into secure and functional code. This pattern holds across both isolated function-level security benchmarks and full web-application security benchmarks.
What carries the argument
A three-level framework that measures natural-language understanding of secure coding principles, code-level actuation of those principles during generation, and the knowledge-actuation gaps between the two.
If this is right
- Principle understanding can serve as an early indicator for expected functional and security quality in generated code.
- Principle-guided generation techniques could narrow the observed knowledge-actuation gaps.
- Evaluation and benchmarking should separately track understanding, actuation, and gaps rather than only final code properties.
- Agentic workflows can be designed to explicitly surface and enforce relevant secure coding principles during code production.
Where Pith is reading between the lines
- If the gaps prove consistent across additional languages and domains, training objectives that emphasize actuation over pure understanding may become necessary.
- Current results imply that real-world deployment of AI code generators could still introduce security issues even when models appear to know the rules.
- The framework could be extended to measure how quickly gaps close under targeted fine-tuning or reinforcement learning on actuation examples.
Load-bearing premise
The chosen benchmarks for isolated function-level security and full web-application security are representative enough to support general claims about knowledge-actuation gaps across the field.
What would settle it
Repeating the three-level evaluation on a fresh benchmark set that uses different security scenarios, languages, or application types and finding that principle understanding no longer statistically predicts code outcomes or that actuation gaps shrink to negligible size.
Figures
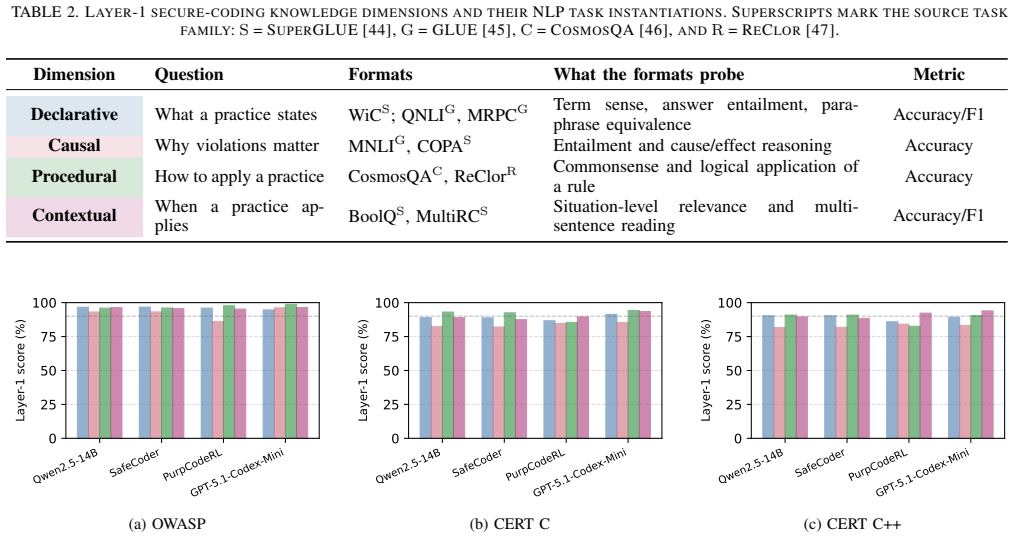

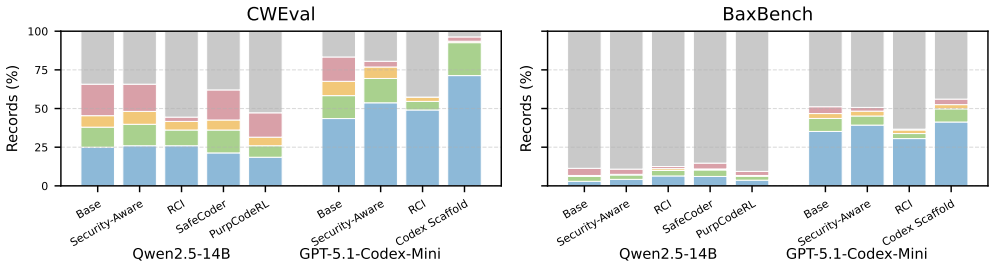

read the original abstract
The increasing use of AI systems for code generation raises a central security question: what can today's models and coding agents actually do to produce secure code, where do they still fail, and what would move the field forward? Existing work has explored prompting, fine-tuning, reinforcement learning, and agentic workflows for secure code generation, but the field still lacks a systematic understanding of how these techniques improve security and why substantial failures persist. In this SoK, we systematize the progress, pitfalls, and paths forward for AI secure code generation. We introduce a three-level framework that measures models' natural-language understanding of secure coding principles, their code-level actuation of those principles during generation, and the knowledge--actuation gaps between the two. We instantiate this framework across models and coding agents on benchmarks covering both isolated function-level security and full web-application security. Our results show that secure-coding-principle understanding is a statistically strong predictor of code-level outcomes, including functional correctness, security, and joint functional-security correctness. Yet substantial knowledge--actuation gaps remain: models can recognize relevant security principles but still fail to translate them into secure and functional code. These findings offer a principle-centered account of where AI secure code generation stands today and identify concrete paths forward through principle-guided generation, evaluation, benchmarking, and agentic workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This SoK introduces a three-level framework (natural-language understanding of secure coding principles, code-level actuation of those principles, and the resulting knowledge-actuation gap) and instantiates it on models and agents using benchmarks for isolated function-level security and full web-application security. The central empirical finding is that understanding is a statistically strong predictor of functional correctness, security, and joint outcomes, yet substantial actuation gaps persist.
Significance. If the reported correlations and gap sizes hold under the chosen evaluation protocol, the framework supplies a principle-centered lens for diagnosing why current techniques still fail at secure code generation and for guiding future work on principle-guided generation, evaluation, and agentic workflows. The explicit separation of understanding from actuation is a clear organizational contribution to the SoK literature.
major comments (1)
- [Abstract / Results] Abstract and results sections: the claim that understanding is a 'statistically strong predictor' of code-level outcomes and that 'substantial knowledge-actuation gaps remain' is instantiated only on function-level and web-application benchmarks. The manuscript does not provide cross-domain validation (e.g., cryptographic primitives, memory-safety-heavy systems code, or embedded constraints), so the field-wide framing of the predictor relationship and the gap conclusion rests on an untested assumption of domain representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the scope of our empirical claims. We address it directly below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results sections: the claim that understanding is a 'statistically strong predictor' of code-level outcomes and that 'substantial knowledge-actuation gaps remain' is instantiated only on function-level and web-application benchmarks. The manuscript does not provide cross-domain validation (e.g., cryptographic primitives, memory-safety-heavy systems code, or embedded constraints), so the field-wide framing of the predictor relationship and the gap conclusion rests on an untested assumption of domain representativeness.
Authors: The empirical instantiation is performed on the two benchmark categories that dominate the existing literature on AI secure code generation: isolated function-level security and full web-application security. These are the domains for which standardized, reproducible evaluation protocols currently exist and have been used in the majority of prior studies. The three-level framework is presented as domain-agnostic, but the reported statistical relationships and gap sizes are explicitly tied to the chosen benchmarks. We do not assert that the precise correlation coefficients or gap magnitudes hold outside these domains. To clarify the boundaries of the claims, we will revise the abstract, introduction, and results sections to replace broad phrasing with language that anchors the findings to the evaluated benchmarks, and we will add a dedicated limitations paragraph in the discussion that notes the absence of cross-domain validation (e.g., cryptographic primitives or memory-safety-heavy code) and identifies this as an important direction for future work. This change qualifies the framing without altering the core empirical results or the organizational contribution of the framework. revision: partial
Circularity Check
No circularity; framework and empirical results are independent
full rationale
The paper is an SoK that introduces a three-level framework (NL understanding of principles, code-level actuation, and knowledge-actuation gaps) independently of any results. It then applies the framework to report measured correlations and gaps on external benchmarks for function-level and web-app security. No equations, fitted parameters, or self-citations reduce the central claims to inputs by construction; the predictor relationship is an observed statistical outcome, not a definitional tautology. The derivation is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
three-level framework (understanding, actuation, knowledge-actuation gap)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,” in2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022, pp. 754–768
2022
-
[2]
Do users write more insecure code with AI assistants?
N. Perry, M. Srivastava, D. Kumar, and D. Boneh, “Do users write more insecure code with AI assistants?” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Secu- rity (CCS ’23). ACM, 2023, pp. 2785–2799
2023
-
[3]
Lost at C: A user study on the security implications of large language model code assistants,
G. Sandoval, H. Pearce, T. Nys, R. Karri, B. Dolan-Gavitt, and S. Garg, “Lost at C: A user study on the security implications of large language model code assistants,” in32nd USENIX Security Symposium (USENIX Security 23). USENIX Association, 2023, pp. 2205–2222
2023
-
[4]
How secure is code generated by ChatGPT?
R. Khoury, A. R. Avila, J. Brunelle, and B. M. Camara, “How secure is code generated by ChatGPT?” in2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2023, pp. 2445–2451
2023
-
[5]
Prompting techniques for secure code generation: A system- atic investigation,
C. Tony, N. E. D ´ıaz Ferreyra, M. Mutas, S. Dhif, and R. Scandari- ato, “Prompting techniques for secure code generation: A system- atic investigation,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 8, pp. 1–53, 2025
2025
-
[6]
Exam- ining zero-shot vulnerability repair with large language models,
H. Pearce, B. Tan, B. Ahmad, R. Karri, and B. Dolan-Gavitt, “Exam- ining zero-shot vulnerability repair with large language models,” in 2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023, pp. 2339–2356
2023
-
[7]
Rescue: Retrieval augmented secure code generation,
J. Shi and T. Zhang, “Rescue: Retrieval augmented secure code generation,”arXiv preprint arXiv:2510.18204, 2025
-
[8]
Seccoder: Towards generalizable and robust secure code generation,
B. Zhang, T. Du, J. Tong, X. Zhang, K. Chow, S. Cheng, X. Wang, and J. Yin, “Seccoder: Towards generalizable and robust secure code generation,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 14 557–14 571
2024
-
[9]
Constrained decoding for secure code generation,
Y . Fu, E. Baker, Y . Ding, and Y . Chen, “Constrained decoding for secure code generation,”arXiv preprint arXiv:2405.00218, 2024
-
[10]
Scodegen: A real-time trustworthy constrained decoding framework for secure code generation with llms,
M. Qu, J. Liu, L. Kang, S. Ling, S. Wang, D. Ye, and T. Huang, “Scodegen: A real-time trustworthy constrained decoding framework for secure code generation with llms,” in2025 IEEE 24th Interna- tional Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), 2025, pp. 492–503
2025
-
[11]
Large language models for code: Security hardening and adversarial testing,
J. He and M. Vechev, “Large language models for code: Security hardening and adversarial testing,” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’23. New York, NY , USA: Association for Computing Machinery, 2023, pp. 1865–1879. [Online]. Available: https://doi.org/10.1145/3576915.3623175
-
[12]
Instruction tuning for secure code generation,
J. He, M. Vero, G. Krasnopolska, and M. Vechev, “Instruction tuning for secure code generation,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[13]
Prosec: For- tifying code llms with proactive security alignment,
X. Xu, Z. Su, J. Guo, K. Zhang, Z. Wang, and X. Zhang, “Prosec: For- tifying code llms with proactive security alignment,”arXiv preprint arXiv:2411.12882, 2024
-
[14]
Purpcode: Reasoning for safer code generation,
J. Liu, N. Diwan, Z. Wang, H. Zhai, X. Zhou, K. Nguyen, T. Yu, M. Wahed, Y . Deng, H. Benkraoudaet al., “Purpcode: Reasoning for safer code generation,”Advances in Neural Information Processing Systems, vol. 38, pp. 55 146–55 200, 2026
2026
-
[15]
Teaching an old llm secure coding: Localized preference optimiza- tion on distilled preferences,
M. S. Hasan, S. Chakraborty, S. Karmaker, and N. Balasubramanian, “Teaching an old llm secure coding: Localized preference optimiza- tion on distilled preferences,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 26 039–26 057
2025
-
[16]
A. Nunez, N. T. Islam, S. K. Jha, and P. Najafirad, “Autosafecoder: A multi-agent framework for securing llm code generation through static analysis and fuzz testing,”arXiv preprint arXiv:2409.10737, 2024
-
[17]
R. Saul, H. Wang, K. Sen, and D. Wagner, “Scgagent: Recreating the benefits of reasoning models for secure code generation with agentic workflows,”arXiv preprint arXiv:2506.07313, 2025
-
[18]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable au- tomated software engineering,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024, arXiv:2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
SecurityEval dataset: Mining vul- nerability examples to evaluate machine learning-based code genera- tion techniques,
M. L. Siddiq and J. C. S. Santos, “SecurityEval dataset: Mining vul- nerability examples to evaluate machine learning-based code genera- tion techniques,” inProceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security (MSR4P&S ’22). ACM, 2022, pp. 29–33
2022
-
[20]
LLM- SecEval: A dataset of natural language prompts for security evalua- tions,
C. Tony, M. Mutas, N. E. D ´ıaz Ferreyra, and R. Scandariato, “LLM- SecEval: A dataset of natural language prompts for security evalua- tions,” in2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR). IEEE, 2023, pp. 588–592
2023
-
[21]
Pur- ple Llama CyberSecEval: A secure coding benchmark for language models,
M. Bhatt, S. Chennabasappa, C. Nikolaidis, S. Wan, I. Evtimov, D. Gabi, D. Song, F. Ahmad, C. Aschermann, L. Fontanaet al., “Pur- ple Llama CyberSecEval: A secure coding benchmark for language models,” 2023
2023
-
[22]
CyberSecEval 2: A wide-ranging cybersecurity evaluation suite for large language models,
M. Bhatt, S. Chennabasappa, Y . Li, C. Nikolaidis, D. Song, S. Wan, F. Ahmad, C. Aschermann, Y . Chen, D. Kapilet al., “CyberSecEval 2: A wide-ranging cybersecurity evaluation suite for large language models,” 2024
2024
-
[23]
CodeLMSec benchmark: Systematically evaluating and finding secu- rity vulnerabilities in black-box code language models,
H. Hajipour, K. Hassler, T. Holz, L. Sch ¨onherr, and M. Fritz, “CodeLMSec benchmark: Systematically evaluating and finding secu- rity vulnerabilities in black-box code language models,” 2024, iEEE SaTML 2024
2024
-
[24]
Is your AI-generated code really safe? evaluating large language models on secure code generation with CodeSecEval,
J. Wang, X. Luo, L. Cao, H. He, H. Huang, J. Xie, A. Jatowt, and Y . Cai, “Is your AI-generated code really safe? evaluating large language models on secure code generation with CodeSecEval,” 2024
2024
-
[25]
SeCodePLT: A unified platform for evaluating the security of code GenAI,
Y . Nie, Z. Wang, Y . Yang, R. Jiang, Y . Tang, X. Davies, Y . Gal, B. Li, W. Guo, and D. Song, “SeCodePLT: A unified platform for evaluating the security of code GenAI,” 2025, accepted to NeurIPS Datasets and Benchmarks Track 2025
2025
-
[26]
CWEval: Outcome- driven evaluation on functionality and security of LLM code genera- tion,
J. Peng, L. Cui, K. Huang, J. Yang, and B. Ray, “CWEval: Outcome- driven evaluation on functionality and security of LLM code genera- tion,” inProceedings of the 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 2025, arXiv:2501.08200
-
[27]
BaxBench: Can LLMs generate correct and secure backends?
M. Vero, N. M ¨undler, V . Chibotaru, V . Raychev, M. Baader, N. Jo- vanovi´c, J. He, and M. Vechev, “BaxBench: Can LLMs generate correct and secure backends?” inProceedings of the 42nd Interna- tional Conference on Machine Learning (ICML). PMLR, 2025, arXiv:2502.11844
-
[28]
SecRepoBench: Benchmarking code agents for secure code comple- tion in real-world repositories,
C. Shen, C. Dilgren, P. Chiniya, L. Griffith, Y . Ding, and Y . Chen, “SecRepoBench: Benchmarking code agents for secure code comple- tion in real-world repositories,” 2025
2025
-
[29]
RealSec-bench: A benchmark for evaluating secure code generation in real-world repositories,
Y . Wang, Z. Zhang, C. Wang, X. Xu, M. Liu, Y . Wang, J. Chen, and Z. Zheng, “RealSec-bench: A benchmark for evaluating secure code generation in real-world repositories,” 2026. 14
2026
-
[30]
SEC-bench: Automated benchmarking of LLM agents on real-world software security tasks,
H. Lee, Z. Zhang, H. Lu, and L. Zhang, “SEC-bench: Automated benchmarking of LLM agents on real-world software security tasks,” 2025
2025
-
[31]
A comprehensive study of LLM secure code generation,
S.-C. Dai, J. Xu, and G. Tao, “A comprehensive study of LLM secure code generation,” 2025
2025
-
[32]
Rethinking the evaluation of secure code generation,
——, “Rethinking the evaluation of secure code generation,” inPro- ceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE). IEEE, 2026
2026
-
[33]
Se- curity of language models for code: A systematic literature review,
Y . Chen, W. Sun, C. Fang, Z. Chen, Y . Ge, T. Han, B. Xuet al., “Se- curity of language models for code: A systematic literature review,” 2024
2024
-
[34]
OW ASP secure coding prac- tices quick reference guide,
OW ASP Foundation, “OW ASP secure coding prac- tices quick reference guide,” https://owasp.org/ www-project-secure-coding-practices-quick-reference-guide/, 2024
2024
-
[35]
SEI CERT C coding standard,
Software Engineering Institute, “SEI CERT C coding standard,” https: //wiki.sei.cmu.edu/confluence/display/c, 2024
2024
-
[36]
Hexacoder: Secure code generation via oracle-guided synthetic training data,
H. Hajipour, L. Sch ¨onherr, T. Holz, and M. Fritz, “Hexacoder: Secure code generation via oracle-guided synthetic training data,”arXiv preprint arXiv:2409.06446, 2024
-
[37]
M. Nazzal, I. Khalil, A. Khreishah, and N. Phan, “Promsec: Prompt optimization for secure generation of functional source code with large language models (llms),” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’24. New York, NY , USA: Association for Computing Machinery, 2024, pp. 2266–2280. [Online]. ...
-
[38]
Guidelines for snowballing in systematic literature stud- ies and a replication in software engineering,
C. Wohlin, “Guidelines for snowballing in systematic literature stud- ies and a replication in software engineering,” inProceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering (EASE ’14). ACM, 2014
2014
-
[39]
SALLM: Security assessment of generated code,
M. L. Siddiq, J. C. S. Santos, S. Devareddy, and A. Muller, “SALLM: Security assessment of generated code,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engi- neering Workshops (ASEW ’24). ACM, 2024
2024
-
[40]
LLMSec- Code: Evaluating large language models for secure coding,
A. Ryd ´en, E. N ¨aslund, E. M. Schiller, and M. Almgren, “LLMSec- Code: Evaluating large language models for secure coding,” 2024
2024
-
[41]
ARVO: Atlas of reproducible vulnerabilities for open source software,
X. Mei, P. S. Singaria, J. Del Castillo, H. Xi, A. Benchikh, T. Bao, R. Wang, Y . Shoshitaishvili, A. Doup ´e, H. Pearce, and B. Dolan- Gavitt, “ARVO: Atlas of reproducible vulnerabilities for open source software,” 2024
2024
-
[42]
VulnRepairEval: An exploit-based evaluation framework for assessing large language model vulnerability repair capabilities,
W. Wang, W. Ma, Q. Hu, Y . Zhang, J. Sun, B. Wu, Y . Liu, G. Xu, and L. Jiang, “VulnRepairEval: An exploit-based evaluation framework for assessing large language model vulnerability repair capabilities,” 2025
2025
-
[43]
Detect–repair–verify for LLM-generated code: A multi- language, multi-granularity empirical study,
C. Cheng, “Detect–repair–verify for LLM-generated code: A multi- language, multi-granularity empirical study,” 2026
2026
-
[44]
SuperGLUE: A stickier benchmark for general-purpose language understanding systems,
A. Wang, Y . Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “SuperGLUE: A stickier benchmark for general-purpose language understanding systems,” inProc. NeurIPS, 2019
2019
-
[45]
GLUE: A multi-task benchmark and analysis platform for natural language understanding,
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” inProc. EMNLP Workshop BlackboxNLP, 2018
2018
-
[46]
CosmosQA: Machine reading comprehension with contextual commonsense rea- soning,
L. Huang, R. Le Bras, C. Bhagavatula, and Y . Choi, “CosmosQA: Machine reading comprehension with contextual commonsense rea- soning,” inProc. EMNLP-IJCNLP, 2019
2019
-
[47]
ReClor: A reading compre- hension dataset requiring logical reasoning,
W. Yu, Z. Jiang, Y . Dong, and J. Feng, “ReClor: A reading compre- hension dataset requiring logical reasoning,” inProc. ICLR, 2020
2020
-
[48]
Language models can solve com- puter tasks,
G. Kim, P. Baldi, and S. McAleer, “Language models can solve com- puter tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[49]
Evaluating c/c++ vulnerability detectability of query-based static application security testing tools,
Z. Li, Z. Liu, W. K. Wong, P. Ma, and S. Wang, “Evaluating c/c++ vulnerability detectability of query-based static application security testing tools,”IEEE Transactions on Dependable and Secure Com- puting, vol. 21, no. 5, pp. 4600–4618, 2024
2024
-
[50]
Static application security testing (sast) tools for smart contracts: How far are we?
K. Li, Y . Xue, S. Chen, H. Liu, K. Sun, M. Hu, H. Wang, Y . Liu, and Y . Chen, “Static application security testing (sast) tools for smart contracts: How far are we?”Proc. ACM Softw. Eng., vol. 1, no. FSE, Jul. 2024. [Online]. Available: https://doi.org/10.1145/3660772
-
[51]
Comparison and Evaluation on Static Application Security Testing (SAST) Tools for Java,
K. Li, S. Chen, L. Fan, R. Feng, H. Liu, C. Liu, Y . Liu, and Y . Chen, “Comparison and evaluation on static application security testing (sast) tools for java,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ESEC/FSE 2023. New York, NY , USA: Association for Comp...
-
[52]
A broad-coverage challenge corpus for sentence understanding through inference,
A. Williams, N. Nangia, and S. R. Bowman, “A broad-coverage challenge corpus for sentence understanding through inference,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), M. Walker, H. Ji, and A. Stent, Eds. New Orleans, Louisiana: As...
2018
-
[53]
Rethinking the evaluation of secure code generation,
S.-C. Dai, J. Xu, and G. Tao, “Rethinking the evaluation of secure code generation,”arXiv preprint arXiv:2503.15554, 2025
-
[54]
Large language model for vulnerability detection and repair: Literature review and the road ahead,
X. Zhou, S. Cao, X. Sun, and D. Lo, “Large language model for vulnerability detection and repair: Literature review and the road ahead,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 5, May
-
[55]
Available: https://doi.org/10.1145/3708522
[Online]. Available: https://doi.org/10.1145/3708522
-
[56]
{SoK}: Towards effective automated vulnerability repair,
Y . Li, F. hossain Shezan, B. Wei, G. Wang, and Y . Tian, “{SoK}: Towards effective automated vulnerability repair,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 4441–4462
2025
-
[57]
SoK: Automated vulnerability repair: Methods, tools, and assessments,
Y . Hu, Z. Liu, K. Shu, S. Guan, D. Zou, S. Xu, B. Yuan, and H. Jin, “SoK: Automated vulnerability repair: Methods, tools, and assessments,” in34th USENIX Security Symposium (USENIX Security 25). Seattle, W A: USENIX Association, Aug. 2025, pp. 4421–4440. [Online]. Available: https://www.usenix.org/conference/ usenixsecurity25/presentation/hu-yiwei
2025
-
[58]
Sok: Understand- ing (new) security issues across ai4code use cases,
Q. Wu, T. Li, T. Zhou, and V . Chandrasekaran, “Sok: Understand- ing (new) security issues across ai4code use cases,”arXiv preprint arXiv:2512.18456, 2025. Appendix A. Layer-1 Question Formats: Examples and Pur- pose Table 4 gives, for each of the nine NLP task formats, the cognitive dimension it serves, what it is designed to probe, and an abbreviated ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.