GRAFT: Graph-Based Affordance Transfer via Part Correspondence
Pith reviewed 2026-06-25 23:25 UTC · model grok-4.3
The pith
GRAFT transfers robotic manipulation affordances to unseen objects by retrieving similar part-based graphs from one demonstration and propagating contact points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
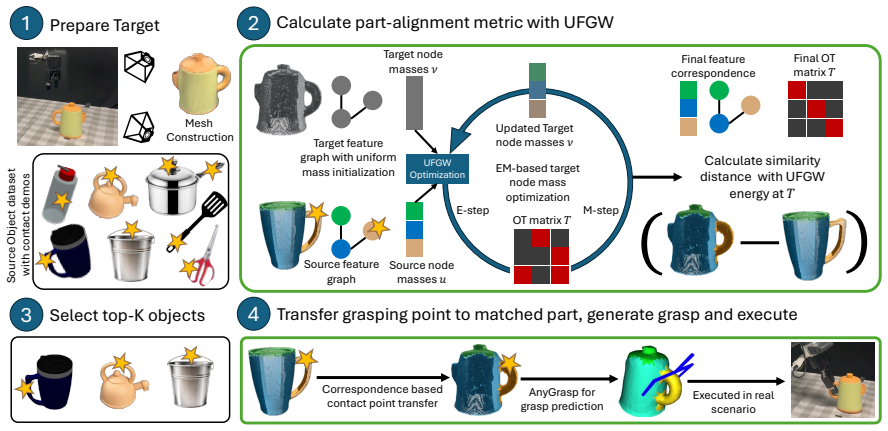
Objects are represented as part-based graphs in which part-level descriptors retrieve the most functionally and geometrically similar demonstrated instance with aligned functional parts, after which vertex-level descriptors propagate the original contact points through point-wise correspondence, achieving zero-shot transfer of manipulation from a single demonstration per object.
What carries the argument
Part-based graphs whose part-level descriptors perform global instance retrieval and part alignment while vertex-level descriptors perform fine-grained contact-point matching.
If this is right
- Robots can apply a demonstrated grasp or placement to new objects whose part structure matches a stored example.
- Geometric similarity at the part level becomes a necessary complement to semantic retrieval for reliable transfer.
- Contact-point transfer succeeds only when point-wise correspondence is computed after part alignment.
- The number of required demonstrations per object category drops to one.
Where Pith is reading between the lines
- The same graph structure could support transfer of multi-step sequences if each part also stores motion trajectories.
- Performance would degrade on objects whose functional parts do not correspond one-to-one with any demonstration.
- Combining the retrieval step with online part segmentation would test whether the method still works when part boundaries must be discovered rather than given.
Load-bearing premise
Objects can be broken into parts whose descriptors jointly support accurate global retrieval and local point matching.
What would settle it
An unseen object for which the retrieved graph produces contact points that cause the robot gripper to miss or drop the target during physical execution.
Figures



read the original abstract
Generalizing robotic manipulation to unseen objects remains challenging, as learning-based approaches require many demonstrations and fail in few-shot settings. Prior work transfers affordances through semantic retrieval, but semantics alone neglect geometric similarity, which is critical for manipulation. We propose GRAFT, a geometry-aware correspondence framework for zero-shot manipulation transfer using only one demonstration per object. Objects are represented as part-based graphs, where part-level descriptors support global instance retrieval and part correspondence, and vertex-level descriptors enable fine-grained contact point matching. For an unseen object, our method first retrieves the most functionally and geometrically similar instance from the demonstration buffer with aligned functional parts, and finally propagates the contact points through point-wise correspondence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GRAFT, a geometry-aware correspondence framework for zero-shot affordance transfer in robotic manipulation. Objects are modeled as part-based graphs, with part-level descriptors used for retrieving similar instances from a demonstration buffer and aligning functional parts, and vertex-level descriptors for propagating contact points. The method aims to generalize from a single demonstration per object to unseen instances by combining functional and geometric similarity.
Significance. If validated, the approach could advance zero-shot manipulation by explicitly incorporating geometric similarity into affordance transfer, moving beyond semantic retrieval. The dual use of part-level descriptors for both retrieval and correspondence, combined with vertex-level matching, represents a structured attempt at data-efficient generalization that merits attention if empirical support is provided.
major comments (2)
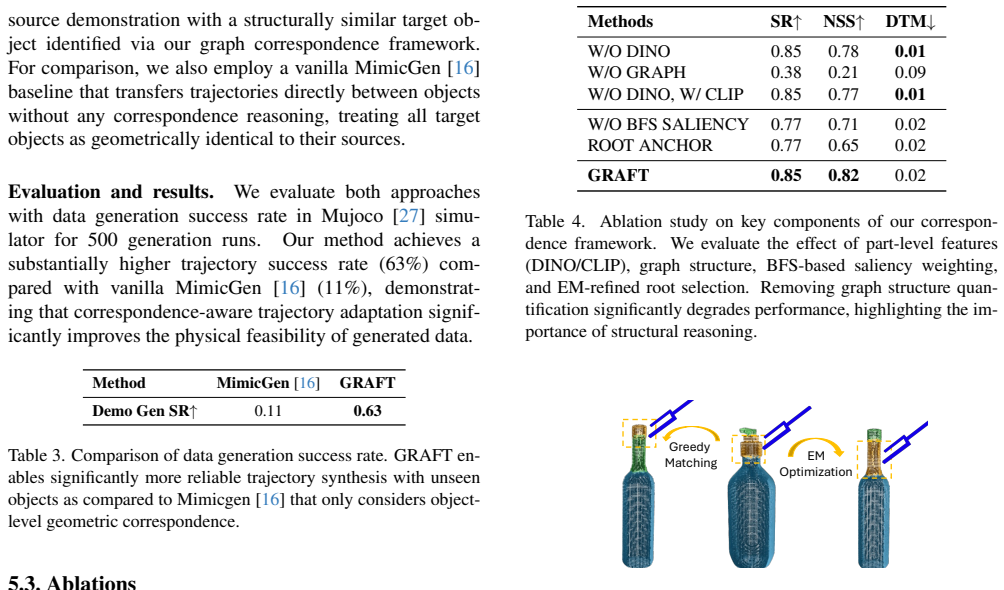
- [Abstract] Abstract: the central zero-shot claim is stated but the text supplies no results, baselines, error bars, or validation experiments on unseen objects, so the soundness of the retrieval-plus-propagation pipeline cannot be assessed from the available manuscript.
- [Framework description] Framework description (paragraph on part-based graphs): the claim that part-level descriptors simultaneously enable global instance retrieval (functional + geometric) and local part correspondence is load-bearing for the zero-shot guarantee, yet the dual-use assumption is presented without justification, ablation, or evidence that the same descriptors succeed at both scales without task-specific tuning.
minor comments (2)
- Notation for graph construction, part descriptors, and vertex descriptors should be defined more explicitly to allow reproduction.
- A pipeline diagram showing retrieval, part alignment, and contact propagation would improve clarity of the method.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central zero-shot claim is stated but the text supplies no results, baselines, error bars, or validation experiments on unseen objects, so the soundness of the retrieval-plus-propagation pipeline cannot be assessed from the available manuscript.
Authors: We agree that the abstract, per standard conventions, emphasizes the method rather than quantitative results. The full manuscript includes experimental validation with baselines, error bars, and unseen-object tests in the results section. To improve clarity, we will revise the abstract to include a concise summary of the key empirical outcomes supporting the zero-shot claim. revision: yes
-
Referee: [Framework description] Framework description (paragraph on part-based graphs): the claim that part-level descriptors simultaneously enable global instance retrieval (functional + geometric) and local part correspondence is load-bearing for the zero-shot guarantee, yet the dual-use assumption is presented without justification, ablation, or evidence that the same descriptors succeed at both scales without task-specific tuning.
Authors: The part-level descriptors are constructed from a combination of geometric and functional features within the graph representation, as described in the framework section, to support both scales by design. We acknowledge that additional explicit justification and evidence would strengthen the presentation. We will expand the relevant paragraph with design rationale and add an ablation study in the experiments to demonstrate performance on retrieval versus correspondence without task-specific retuning. revision: yes
Circularity Check
No circularity: method description contains no derivations or self-referential reductions.
full rationale
The paper describes a graph-based framework for affordance transfer without presenting equations, parameter fits, or derivation chains. The core claims rest on the design choice of part-based graphs for retrieval and correspondence, which is presented as an engineering approach rather than a mathematical result derived from prior inputs. No self-citations are invoked as load-bearing uniqueness theorems, no fitted quantities are relabeled as predictions, and no ansatzes are smuggled via citation. The abstract and framework description are self-contained as a proposed algorithm, with no evidence that any 'result' reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The wave kernel signature: A quantum me- chanical approach to shape analysis
Mathieu Aubry, Ulrich Schlickewei, and Daniel Cre- mers. The wave kernel signature: A quantum me- chanical approach to shape analysis. In2011 IEEE in- ternational conference on computer vision workshops (ICCV workshops), pages 1626–1633. IEEE, 2011. 2
2011
-
[2]
Scale- invariant heat kernel signatures for non-rigid shape recognition
Michael M Bronstein and Iasonas Kokkinos. Scale- invariant heat kernel signatures for non-rigid shape recognition. In2010 IEEE computer society con- ference on computer vision and pattern recognition, pages 1704–1711. IEEE, 2010. 2
2010
-
[3]
Nod-tamp: Multi-step manipulation planning with neural object descriptors
Shuo Cheng, Caelan Reed Garrett, Ajay Mandlekar, and Danfei Xu. Nod-tamp: Multi-step manipulation planning with neural object descriptors. InCoRL 2023 Workshop on Learning Effective Abstractions for Planning (LEAP), 2023. 2
2023
-
[4]
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning.arXiv preprint arXiv:2410.07408, 2024. 2
-
[5]
Deformed implicit field: Modeling 3d shapes with learned dense correspondence
Yu Deng, Jiaolong Yang, and Xin Tong. Deformed implicit field: Modeling 3d shapes with learned dense correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 10286–10296, 2021. 2
2021
-
[6]
Anygrasp: Robust and effi- cient grasp perception in spatial and temporal do- mains.IEEE Transactions on Robotics, 39(5):3929– 3945, 2023
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and effi- cient grasp perception in spatial and temporal do- mains.IEEE Transactions on Robotics, 39(5):3929– 3945, 2023. 4, 5, 7
2023
-
[7]
Demo2vec: Reasoning object affor- dances from online videos
Kuan Fang, Te-Lin Wu, Daniel Yang, Silvio Savarese, and Joseph J Lim. Demo2vec: Reasoning object affor- dances from online videos. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 2139–2147, 2018. 6
2018
-
[8]
Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation
Peter R Florence, Lucas Manuelli, and Russ Tedrake. Dense object nets: Learning dense visual object de- scriptors by and for robotic manipulation.arXiv preprint arXiv:1806.08756, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Caelan Garrett, Ajay Mandlekar, Bowen Wen, and Di- eter Fox. Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment. arXiv preprint arXiv:2410.18907, 2024. 2
-
[10]
Dexmimicgen: Automated data genera- tion for bimanual dexterous manipulation via imita- tion learning
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Jim Fan, and Yuke Zhu. Dexmimicgen: Automated data genera- tion for bimanual dexterous manipulation via imita- tion learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16923– 16930. IEEE, 2025. 2
2025
-
[11]
Robo-abc: Affor- dance generalization beyond categories via seman- tic correspondence for robot manipulation
Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Mingrun Jiang, and Huazhe Xu. Robo-abc: Affor- dance generalization beyond categories via seman- tic correspondence for robot manipulation. InEuro- pean Conference on Computer Vision, pages 222–239. Springer, 2024. 1, 2, 6, 7
2024
-
[12]
Yuxuan Kuang, Junjie Ye, Haoran Geng, Jiageng Mao, Congyue Deng, Leonidas Guibas, He Wang, and Yue Wang. Ram: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation.arXiv preprint arXiv:2407.04689, 2024. 1, 2
-
[13]
Rrt-connect: An efficient approach to single-query path plan- ning
James J Kuffner and Steven M LaValle. Rrt-connect: An efficient approach to single-query path plan- ning. InProceedings 2000 ICRA. Millennium con- ference. IEEE international conference on robotics and automation. Symposia proceedings (Cat. No. 00CH37065), pages 995–1001. IEEE, 2000. 5, 7
2000
-
[14]
3d scanner app – lidar scanner for ipad and iphone pro.https://3dscannerapp.com/
Laan Labs. 3d scanner app – lidar scanner for ipad and iphone pro.https://3dscannerapp.com/. Accessed: 2025-11-14. 7
2025
-
[15]
Learning affordance grounding from exocentric images
Hongchen Luo, Wei Zhai, Jing Zhang, Yang Cao, and Dacheng Tao. Learning affordance grounding from exocentric images. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 2252–2261, 2022. 6
2022
-
[16]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Ire- tiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstra- tions.arXiv preprint arXiv:2310.17596, 2023. 2, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1): 99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1): 99–106, 2021. 4
2021
-
[18]
Where2act: From pixels to actions for articulated 3d objects
Kaichun Mo, Leonidas J Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani. Where2act: From pixels to actions for articulated 3d objects. In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 6813–6823, 2021. 2, 6, 7
2021
-
[19]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust vi- sual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 1, 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Foundpose: Unseen object pose estimation with foundation features
Evin Pınar ¨Ornek, Yann Labb ´e, Bugra Tekin, Lingni Ma, Cem Keskin, Christian Forster, and Tomas Ho- dan. Foundpose: Unseen object pose estimation with foundation features. InEuropean Conference on Com- puter Vision, pages 163–182. Springer, 2024. 7
2024
-
[21]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[22]
The unbalanced gromov wasserstein distance: Conic formulation and relaxation.Advances in Neural Information Processing Systems, 34:8766– 8779, 2021
Thibault S ´ejourn´e, Franc ¸ois-Xavier Vialard, and Gabriel Peyr ´e. The unbalanced gromov wasserstein distance: Conic formulation and relaxation.Advances in Neural Information Processing Systems, 34:8766– 8779, 2021. 3
2021
-
[23]
Neural descriptor fields: Se (3)-equivariant object representations for manipulation
Anthony Simeonov, Yilun Du, Andrea Tagliasac- chi, Joshua B Tenenbaum, Alberto Rodriguez, Pulkit Agrawal, and Vincent Sitzmann. Neural descriptor fields: Se (3)-equivariant object representations for manipulation. In2022 International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2022. 2
2022
-
[24]
A concise and provably informative multi-scale signa- ture based on heat diffusion
Jian Sun, Maks Ovsjanikov, and Leonidas Guibas. A concise and provably informative multi-scale signa- ture based on heat diffusion. InComputer graphics forum, pages 1383–1392. Wiley Online Library, 2009. 2
2009
-
[25]
Emergent correspondence from image diffusion.Advances in Neural Information Processing Systems, 36: 1363–1389, 2023
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion.Advances in Neural Information Processing Systems, 36: 1363–1389, 2023. 2
2023
-
[26]
Optimal transport for structured data with application on graphs
Vayer Titouan, Nicolas Courty, Romain Tavenard, and R´emi Flamary. Optimal transport for structured data with application on graphs. InInternational Confer- ence on Machine Learning, pages 6275–6284. PMLR,
-
[27]
Mu- joco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mu- joco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelli- gent robots and systems, pages 5026–5033. IEEE,
2012
-
[28]
D 3 fields: Dynamic 3d descriptor fields for zero-shot generalizable robotic manipulation
Yixuan Wang, Mingtong Zhang, Zhuoran Li, Kather- ine Rose Driggs-Campbell, Jiajun Wu, Li Fei-Fei, and Yunzhu Li. D 3 fields: Dynamic 3d descriptor fields for zero-shot generalizable robotic manipulation. In ICRA 2024 Workshop on 3D Visual Representations for Robot Manipulation, 2023. 2
2024
-
[29]
Gendp: 3d semantic fields for category-level generalizable dif- fusion policy
Yixuan Wang, Guang Yin, Binghao Huang, Tarik Ke- lestemur, Jiuguang Wang, and Yunzhu Li. Gendp: 3d semantic fields for category-level generalizable dif- fusion policy. In8th Annual Conference on Robot Learning, 2024. 2
2024
-
[30]
Sapien: A simulated part- based interactive environment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part- based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020. 6
2020
-
[31]
Densematcher: Learning 3d semantic correspondence for category-level manipulation from a single demo
Junzhe Zhu, Yuanchen Ju, Junyi Zhang, Muhan Wang, Zhecheng Yuan, Kaizhe Hu, and Huazhe Xu. Densematcher: Learning 3d semantic correspondence for category-level manipulation from a single demo. arXiv preprint arXiv:2412.05268, 2024. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.