LinStereo: Linear-Complexity Global Attention for Multi-Scale Iterative Stereo Matching
Pith reviewed 2026-06-25 21:03 UTC · model grok-4.3
The pith
LinStereo replaces local recurrence in stereo matching with a linear-cost global attention module that spreads reliable disparities from clear to degraded regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
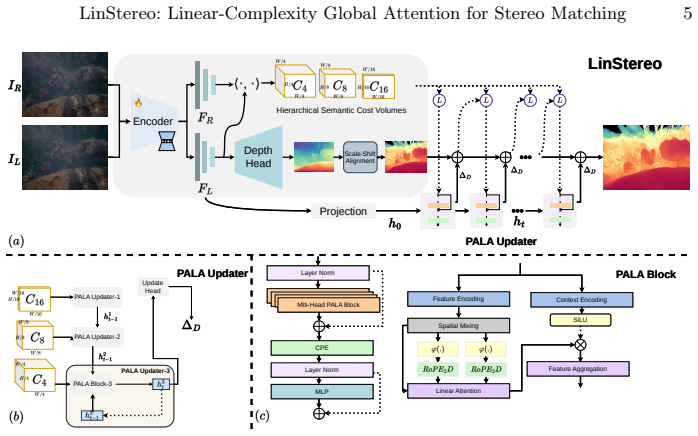
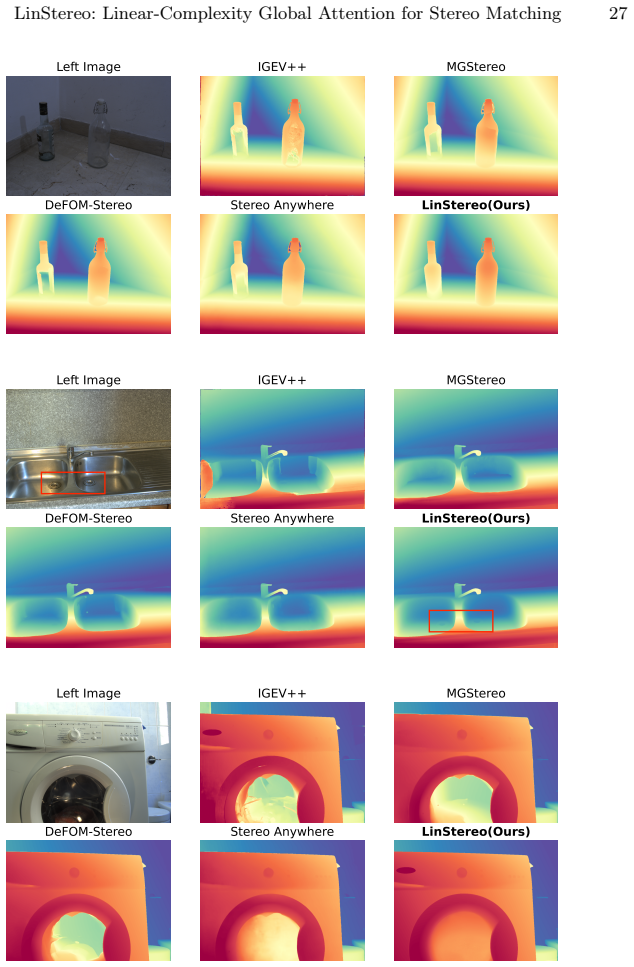
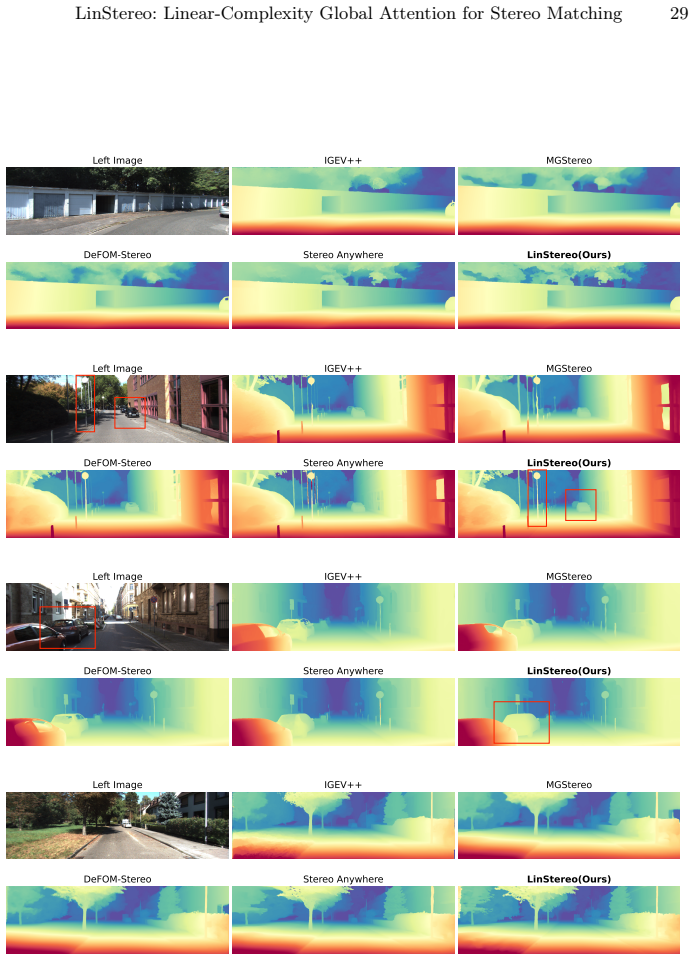
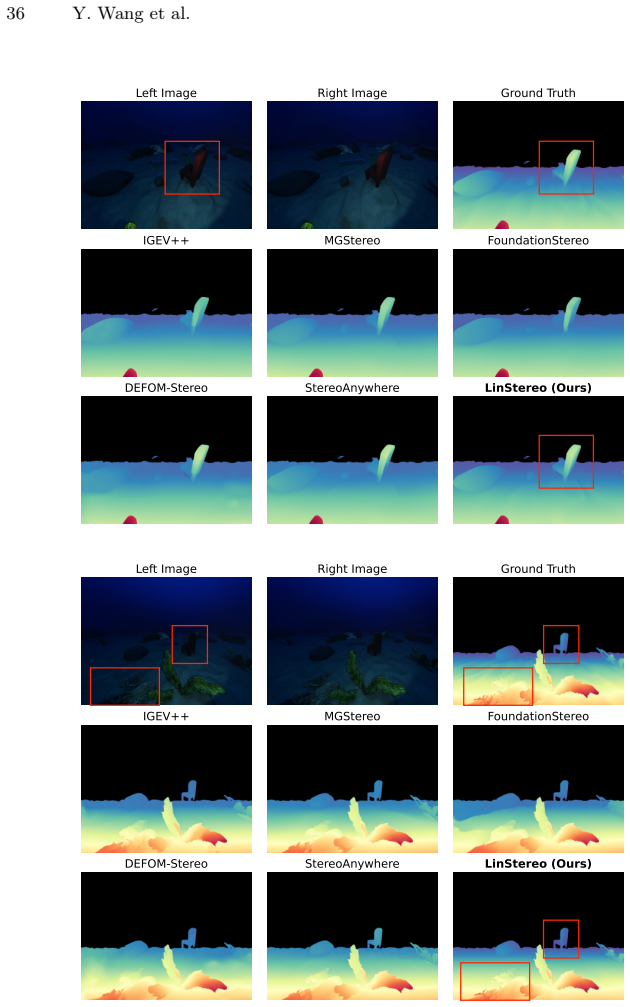
The paper establishes that the Position-Aware Linear Attention module, when combined with scale-aligned Hierarchical Semantic Cost Volumes and Depth Prior Initialization inside an iterative stereo pipeline built on Depth Anything V3, achieves global context propagation at linear complexity, yielding the best overall accuracy on standard benchmarks and consistent error reductions of 28 percent AbsRel on TartanAir-UW and 26 percent on SQUID.
What carries the argument
Position-Aware Linear Attention (PALA) module, which replaces local recurrence with global aggregation of disparity information at linear computational cost while preserving structure.
If this is right
- Reliable disparity estimates can be propagated across the entire image without quadratic global attention cost.
- Multi-scale VFM features can be used directly as scale-aligned correlations rather than collapsed to a single level.
- Monocular depth estimates can serve as an effective metrically calibrated initialization for stereo refinement.
- Performance gains hold across both standard indoor/outdoor benchmarks and severely degraded underwater domains.
Where Pith is reading between the lines
- The same linear global aggregation pattern could be tested on related dense correspondence tasks such as optical flow where long-range propagation is also needed.
- If the propagation mechanism works, future stereo pipelines may be able to reduce the number of local refinement iterations while maintaining accuracy.
- The approach highlights that hierarchical cost volumes can bridge the gap between monocular priors and stereo geometry without requiring additional network branches.
Load-bearing premise
The underlying VFM features and hierarchical cost volumes supply enough reliable signal for the attention module to propagate accurate disparity estimates from well-matched regions into areas with degraded photometric cues.
What would settle it
Apply the pipeline to a controlled test set in which large contiguous regions have their initial matches deliberately corrupted or removed and measure whether final disparity accuracy still exceeds local-recurrence baselines.
Figures





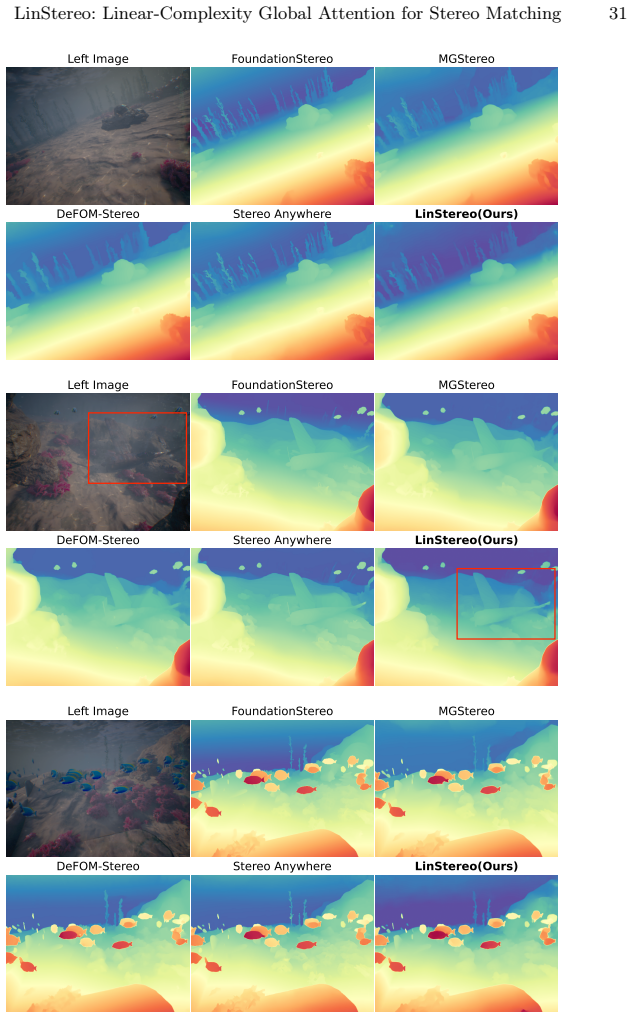
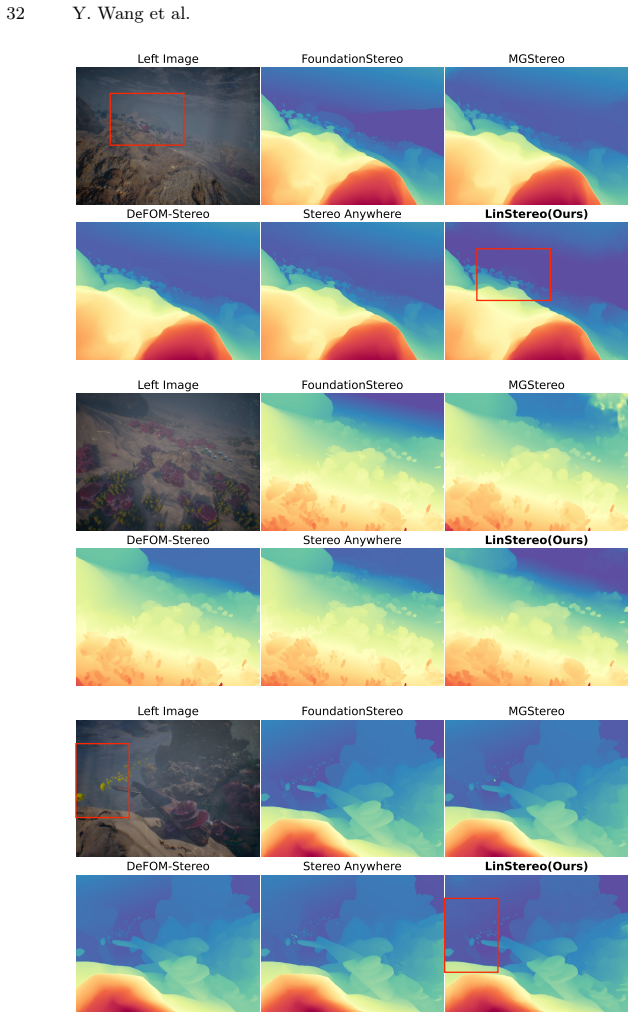
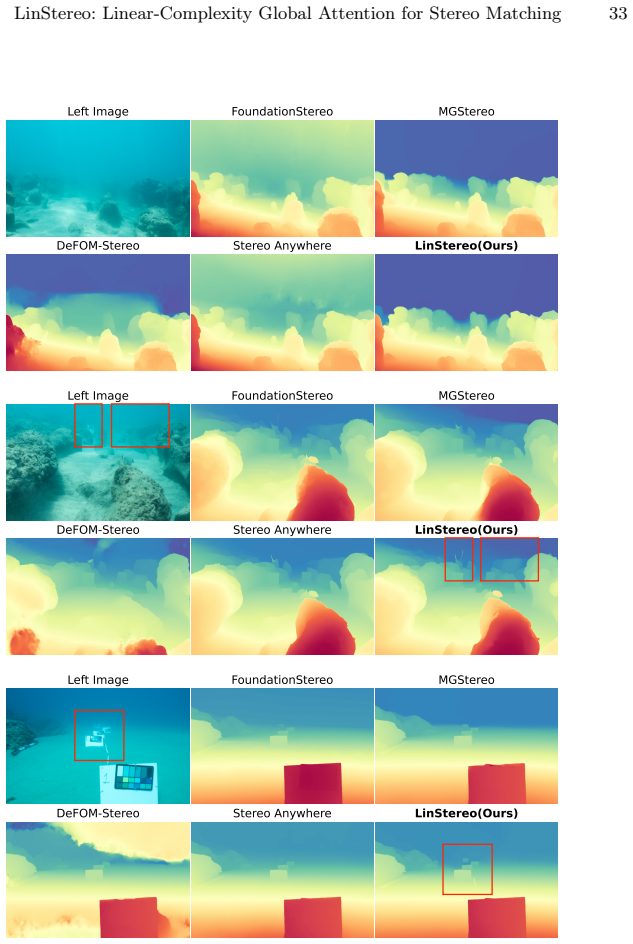

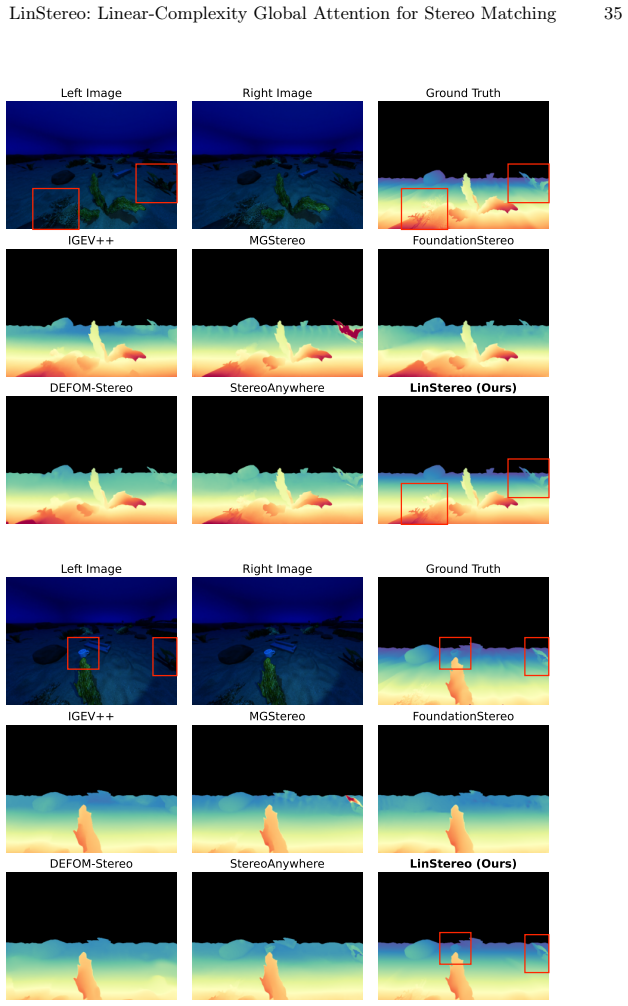
read the original abstract
Existing Vision Foundation Model (VFM)-based iterative stereo pipelines under-exploit three information pathways: multi-scale backbone features are collapsed into single-level correlations, geometric priors remain untapped at initialization, and context propagates only locally. These gaps widen under degraded photometric cues, making underwater scenes a stringent generalization test. To address this, we propose LinStereo, built upon Depth Anything V3, whose core is a Position-Aware Linear Attention (PALA) module that replaces local recurrence with global aggregation at linear cost, propagating reliable estimates from well-matched regions into degraded areas while preserving disparity structure. PALA is made effective by two enabling components: Hierarchical Semantic Cost Volumes (HSCV), which supply scale-aligned correlations from the VFM feature hierarchy, and a Depth Prior Initialization (DPI) that converts monocular depth into a metrically calibrated warm start. LinStereo achieves state-of-the-art-level accuracy on standard benchmarks and strong cross-domain generalization, particularly on underwater scene where severe photometric degradation makes stereo matching particularly challenging, attaining the best overall accuracy with consistent gains 28% lower AbsRel on TartanAir-UW, 26% on SQUID, a real-world underwater dataset).
Editorial analysis
A structured set of objections, weighed in public.
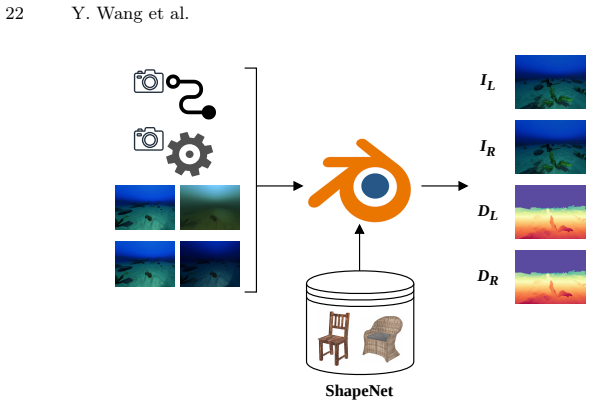
Referee Report
Summary. The manuscript proposes LinStereo, an iterative stereo matching method built on Depth Anything V3. Its core contributions are the Position-Aware Linear Attention (PALA) module for global context aggregation at linear cost, Hierarchical Semantic Cost Volumes (HSCV) to supply scale-aligned correlations from the VFM feature hierarchy, and Depth Prior Initialization (DPI) that converts monocular depth into a metrically calibrated warm start. The central empirical claim is state-of-the-art-level accuracy on standard benchmarks together with strong cross-domain generalization on underwater scenes, specifically 28% lower AbsRel on TartanAir-UW and 26% on the real-world SQUID dataset.
Significance. If the reported accuracy gains and cross-domain improvements hold under rigorous evaluation, the work would show that linear-complexity global attention combined with semantic cost volumes and geometric priors can improve propagation of disparity estimates into photometrically degraded regions while remaining computationally tractable. This would be a meaningful advance for stereo matching in challenging environments such as underwater vision.
major comments (1)
- Abstract: the performance numbers (28% lower AbsRel on TartanAir-UW, 26% on SQUID) and the claim of 'state-of-the-art-level accuracy' are presented without any description of experimental protocol, baselines, metrics, or error analysis. Because these numbers constitute the central empirical claim, the absence of supporting experimental details prevents evaluation of whether the reported gains are load-bearing or reproducible.
minor comments (1)
- Abstract, final sentence: 'underwater scene where' should read 'underwater scenes where'; the closing parenthesis after 'dataset' is misplaced.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity in the abstract regarding our central empirical claims. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the performance numbers (28% lower AbsRel on TartanAir-UW, 26% on SQUID) and the claim of 'state-of-the-art-level accuracy' are presented without any description of experimental protocol, baselines, metrics, or error analysis. Because these numbers constitute the central empirical claim, the absence of supporting experimental details prevents evaluation of whether the reported gains are load-bearing or reproducible.
Authors: We agree that the abstract would benefit from additional context to support the reported performance numbers and SOTA-level claim. In the revised version, we will update the abstract to briefly specify the evaluation benchmarks (TartanAir-UW and SQUID), the primary metric (AbsRel), and a reference to the full experimental protocol, baselines, and analysis detailed in Section 4. This change will improve evaluability while preserving conciseness. The full details, including comparisons and error breakdowns, remain in the Experiments section as before. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical architecture (PALA for global linear attention, HSCV for hierarchical correlations, DPI for monocular initialization) built on an existing VFM backbone and reports benchmark accuracy numbers as experimental outcomes. No derivation chain, equations, or first-principles claims are present that reduce by construction to fitted parameters, self-definitions, or self-citation load-bearing premises. The central claims rest on measured performance rather than identities internal to the method itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Depth Anything V3 provides reliable multi-scale features suitable for building hierarchical semantic cost volumes
- domain assumption Monocular depth estimates can be converted into a metrically calibrated warm-start disparity map
invented entities (3)
-
Position-Aware Linear Attention (PALA)
no independent evidence
-
Hierarchical Semantic Cost Volumes (HSCV)
no independent evidence
-
Depth Prior Initialization (DPI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Akkaynak, D., Treibitz, T.: A revised underwater image formation model. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6723–
2018
-
[2]
IEEE (2018).https://doi.org/10.1109/CVPR.2018.00703
-
[3]
In: IEEE/RJS International Conference on Intelligent RObots and Systems
Bangunharcana, A., Cho, J.W., Lee, S., Kweon, I.S., Kim, K.S., Kim, S.: Correlate- and-excite: Real-time stereo matching via guided cost volume excitation. In: IEEE/RJS International Conference on Intelligent RObots and Systems. pp. 3542–
-
[4]
IEEE, IEEE (2021).https://doi.org/10.1109/IROS51168.2021.9635909
-
[6]
Berman, D., Levy, D., Avidan, S., Treibitz, T.: Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Transactions on Pattern Analysis and Machine Intelligence43(8), 2822–2837 (2018).https: //doi.org/10.1109/tpami.2020.2977624
-
[7]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Bochkovskiy, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S.R., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. In: arXiv.org (2024).https://doi.org/10.48550/arXiv.2410.02073
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.02073 2024
-
[8]
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: ShapeNet: An Information-Rich 3D Model Repository. Tech. Rep. arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago (2015)
Pith/arXiv arXiv 2015
-
[9]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chang, J.R., Chen, Y.S.: Pyramid stereo matching network. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5410–5418. IEEE (2018).https://doi.org/10.1109/CVPR.2018.00567
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cheng, J., Liu, L., Xu, G., Wang, X., Zhang, Z., Deng, Y., Zang, J., Chen, Y., Cai, Z., Yang, X.: Monster: Marry monodepth to stereo unleashes power. In: Computer Vision and Pattern Recognition. pp. 6273–6282. IEEE (2025).https://doi.org/ 10.1109/CVPR52734.2025.00588
-
[12]
In: IEEE International Con- ference on Computer Vision
Duggal, S., Wang, S., Ma, W.C., Hu, R., Urtasun, R.: Deeppruner: Learning effi- cient stereo matching via differentiable patchmatch. In: IEEE International Con- ference on Computer Vision. pp. 4383–4392. IEEE (2019).https://doi.org/10. 1109/ICCV.2019.00448
arXiv 2019
-
[13]
In: 2012 IEEE Conference on Computer Vision and Pattern Recognition
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? The KITTI vision benchmark suite. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition. pp. 3354–3361. IEEE (2012).https://doi.org/10. 1109/CVPR.2012.6248074
arXiv 2012
-
[14]
Gómez, Á.: GA-Net: Guided aggregation net for end-to-end stereo matching. In: Image Processing On Line. pp. 185–194 (2023).https://doi.org/10.5201/ipol. 2023.441
-
[15]
Gu, X., Fan, Z., Zhu, S., Dai, Z., Tan, F., Tan, P.: Cascade cost volume for high- resolution multi-view stereo and stereo matching. In: Computer Vision and Pattern Recognition. pp. 2495–2504 (2019).https://doi.org/10.1109/CVPR42600.2020. 00257 LinStereo: Linear-Complexity Global Attention for Stereo Matching 17
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Guan, T., Guo, J., Wang, C., Liu, Y.: Bridgedepth: Bridging monocular and stereo reasoning with latent alignment. In: IEEE International Conference on Computer Vision. pp. 27681–27691. IEEE (2025).https://doi.org/10.1109/ICCV51701. 2025.02570
-
[17]
UniDepth: Universal Monocular Metric Depth Estimation
Guan, T., Wang, C., Liu, Y.H.: Neural markov random field for stereo matching. In: Computer Vision and Pattern Recognition. pp. 5459–5469. IEEE (June 2024). https://doi.org/10.1109/CVPR52733.2024.00522
-
[18]
Guo, X., Zhang, C., Nie, D., Zheng, W., Zhang, Y., Chen, L.: Lightstereo: Chan- nel boost is all you need for efficient 2d cost aggregation. In: IEEE International Conference on Robotics and Automation (2024).https://doi.org/10.1109/ ICRA55743.2025.11127711
arXiv 2024
-
[19]
In: Computer Vision and Pattern Recognition
Guo, X., Yang, K., Yang, W., Wang, X., Li, H.: Group-wise correlation stereo net- work. In: Computer Vision and Pattern Recognition. pp. 3268–3277. IEEE (2019). https://doi.org/10.1109/CVPR.2019.00339
-
[20]
Hu, M., Yin, W., Zhang, C., Cai, Z., Long, X., Chen, H., Wang, K., Yu, G., Shen, C., Shen, S.: Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10579–10596 (2024).https: //doi.org/10.1109/TPAMI.2024.3444912
-
[21]
In: Computer Vision and Pattern Recognition
Jiang, H., Lou, Z., Ding, L., Xu, R., Tan, M., Jiang, W., Huang, R.: DEFOM- Stereo: Depth foundation model based stereo matching. In: Computer Vision and Pattern Recognition. pp. 21857–21867. IEEE (2025).https://doi.org/10.1109/ CVPR52734.2025.02036
arXiv 2025
-
[22]
In: 2017 IEEE International Conference on Computer Vision (ICCV)
Kendall, A., Martirosyan, H., Dasgupta, S., Henry, P., Kennedy, R., Bachrach, A., Bry, A.: End-to-end learning of geometry and context for deep stereo regression. In: 2017 IEEE International Conference on Computer Vision (ICCV). pp. 66–75. IEEE (2017).https://doi.org/10.1109/iccv.2017.17
-
[23]
In: European Conference on Computer Vision
Khamis, S., Fanello, S., Rhemann, C., Kowdle, A., Valentin, J., Izadi, S.: Stere- onet: Guided hierarchical refinement for real-time edge-aware depth prediction. In: European Conference on Computer Vision. pp. 596–613. Springer International Publishing (2018).https://doi.org/10.1007/978-3-030-01267-0_35
-
[24]
Li, J., Wang, P., Xiong, P., Cai, T., Yan, Z., Yang, L., Liu, J., Fan, H., Liu, S.: Practicalstereomatchingviacascadedrecurrentnetworkwithadaptivecorrelation. In: Computer Vision and Pattern Recognition. pp. 16242–16251. IEEE (2022). https://doi.org/10.1109/CVPR52688.2022.01578
-
[25]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv.org (2025).https: //doi.org/10.48550/arXiv.2511.10647
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.10647 2025
-
[26]
IEEE International Conference on 3D Vision (3DV) , volume =
Lipson, L., Teed, Z., Deng, J.: Raft-stereo: Multilevel recurrent field transforms for stereo matching. In: International Conference on 3D Vision. pp. 218–227. IEEE, IEEE (2021).https://doi.org/10.1109/3DV53792.2021.00032
-
[27]
Lv, Q., Dong, J., Li, Y., Chen, S., Yu, H., Zhang, S., Wang, W.: Uwstereo: A large synthetic dataset for underwater stereo matching. IEEE transactions on cir- cuits and systems for video technology (Print) (2024).https://doi.org/10.1109/ TCSVT.2025.3572044
arXiv 2024
-
[28]
In: Computer Vision and Pattern Recognition
Mayer, N., Ilg, E., Häusser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Computer Vision and Pattern Recognition. pp. 4040– 4048 (2015).https://doi.org/10.1109/CVPR.2016.438 18 Y. Wang et al
-
[29]
In: Computer Vision and Pattern Recognition
Menze, M., Geiger, A.: Object scene flow for autonomous vehicles. In: Computer Vision and Pattern Recognition. pp. 3061–3070. IEEE (2015).https://doi.org/ 10.1109/CVPR.2015.7298925
-
[30]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Trans. Mach. Learn. Res. (2023).https:// doi.org/10.48550/arXiv.2304.07193
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.07193 2023
-
[31]
In: Computer Vision and Pattern Recog- nition
Ramirez,P.Z.,Tosi,F.,Poggi,M.,Salti,S.,Mattoccia,S.,Stefano,L.D.:Openchal- lenges in deep stereo: the booster dataset. In: Computer Vision and Pattern Recog- nition. pp. 21136–21146. IEEE (2022).https://doi.org/10.1109/CVPR52688. 2022.02049
-
[32]
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: IEEE International Conference on Computer Vision. pp. 12159–12168. IEEE (October 2021).https://doi.org/10.1109/ICCV48922.2021.01196
-
[33]
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence44(3), 1623–1637 (2019).https://doi.org/10.1109/TPAMI.2020.3019967
-
[34]
In: German Conference on Pattern Recognition
Scharstein, D., Hirschmüller, H., Kitajima, Y., Krathwohl, G., Nesic, N., Wang, X., Westling, P.: High-resolution stereo datasets with subpixel-accurate ground truth. In: German Conference on Pattern Recognition. pp. 31–42. Springer International Publishing (2014).https://doi.org/10.1007/978-3-319-11752-2_3
-
[35]
IEEE (2017).https://doi.org/10.1109/CVPR.2017.272
Schöps, T., Schönberger, J.L., Galliani, S., Sattler, T., Schindler, K., Pollefeys, M., Geiger, A.: A multi-view stereo benchmark with high-resolution images and multi-cameravideos.In:ComputerVisionandPatternRecognition.pp.2538–2547. IEEE (2017).https://doi.org/10.1109/CVPR.2017.272
-
[36]
In: IEEE Workshop/Winter Conference on Applications of Computer Vision
Shamsafar,F.,Woerz,S.,Rahim,R.,Zell,A.:Mobilestereonet:Towardslightweight deep networks for stereo matching. In: IEEE Workshop/Winter Conference on Applications of Computer Vision. pp. 2417–2426 (2021).https://doi.org/10. 1109/WACV51458.2022.00075
arXiv 2021
-
[37]
Shen, Z., Dai, Y., Song, X., Rao, Z., Zhou, D., Zhang, L.: Pcw-net: Pyramid combi- nation and warping cost volume for stereo matching. In: European Conference on Computer Vision. pp. 280–297. Springer (2020).https://doi.org/10.1007/978- 3-031-19824-3_17
-
[38]
Su, J., Lu, Y., Pan, S., Wen, B., Liu, Y.: Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568, 127063 (2021).https://doi. org/10.1016/j.neucom.2023.127063
-
[39]
In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Tankovich, V., Häne, C., Fanello, S., Zhang, Y., Izadi, S., Bouaziz, S.: Hitnet: Hierarchical iterative tile refinement network for real-time stereo matching. In: Computer Vision and Pattern Recognition. pp. 14362–14372 (2020).https://doi. org/10.1109/CVPR46437.2021.01413
-
[40]
The Newer College Dataset: Handheld LiDAR, inertial and vision with ground truth,
Wang, W., Zhu, D., Wang, X., Hu, Y., Qiu, Y., Wang, C., Hu, Y., Kapoor, A., Scherer, S.: Tartanair: A dataset to push the limits of visual slam. In: IEEE/RJS International Conference on Intelligent RObots and Systems. pp. 4909–4916. IEEE (2020).https://doi.org/10.1109/IROS45743.2020.9341801
-
[41]
Wang, X., Xu, G., Jia, H., Yang, X.: Selective-stereo: Adaptive frequency infor- mation selection for stereo matching. In: Computer Vision and Pattern Recogni- tion. pp. 19701–19710. IEEE (June 2024).https://doi.org/10.1109/CVPR52733. 2024.01863 LinStereo: Linear-Complexity Global Attention for Stereo Matching 19
-
[42]
Wang, Y., Li, K., Wang, L., Hu, J., Wu, D.O., Guo, Y.: Adstereo: Efficient stereo matchingwithadaptivedownsamplinganddisparityalignment.IEEETransactions on Image Processing34, 1204–1218 (2025).https://doi.org/10.1109/TIP.2025. 3540282
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wen, B., Trepte, M., Aribido, J., Kautz, J., Gallo, O., Birchfield, S.: Foundation- Stereo: Zero-shot stereo matching. In: Computer Vision and Pattern Recognition. pp. 5249–5260. IEEE (2025).https://doi.org/10.1109/CVPR52734.2025.00495
-
[44]
Cambridge University Press, 2nd edn
Wrobel, B.P.: Multiple View Geometry in Computer Vision. Cambridge University Press, 2nd edn. (2001)
2001
-
[45]
In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xu, B., Xu, Y., Yang, X., Jia, W., Guo, Y.: Bilateral grid learning for stereo matching networks. In: Computer Vision and Pattern Recognition. pp. 12492– 12501. IEEE (2021).https://doi.org/10.1109/CVPR46437.2021.01231
-
[46]
Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild
Xu, G., Wang, X., Ding, X., Yang, X.: Iterative geometry encoding volume for stereo matching. In: Computer Vision and Pattern Recognition. pp. 21919–21928. IEEE (June 2023).https://doi.org/10.1109/CVPR52729.2023.02099
-
[47]
IEEE Transactions on Pattern Analysis and Machine Intelligence47, 7108–7122 (2024).https://doi
Xu, G., Wang, X., Zhang, Z., Cheng, J., Liao, C., Yang, X.: Igev++: Iterative multi-range geometry encoding volumes for stereo matching. IEEE Transactions on Pattern Analysis and Machine Intelligence47, 7108–7122 (2024).https://doi. org/10.1109/TPAMI.2025.3569218
-
[48]
Xu, G., Wang, Y., Cheng, J., Tang, J., Yang, X.: Accurate and efficient stereo matching via attention concatenation volume. IEEE Transactions on Pattern Anal- ysis and Machine Intelligence46(4), 2461–2474 (2022).https://doi.org/10. 1109/TPAMI.2023.3335480
arXiv 2022
-
[49]
arXiv.org (2023).https://doi.org/10.48550/ arXiv.2301.02789
Xu, G., Zhou, H., Yang, X.: Cgi-stereo: Accurate and real-time stereo matching via context and geometry interaction. arXiv.org (2023).https://doi.org/10.48550/ arXiv.2301.02789
arXiv 2023
-
[50]
Xu, H., Zhang, J., Cai, J., Rezatofighi, H., Yu, F., Tao, D., Geiger, A.: Unifying flow, stereo and depth estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 13941–13960 (2022).https://doi.org/10.1109/ TPAMI.2023.3298645
arXiv 2022
-
[51]
Xu, H., Zhang, J.: Aanet: Adaptive aggregation network for efficient stereo match- ing. In: Computer Vision and Pattern Recognition. pp. 1956–1965. IEEE (2020). https://doi.org/10.1109/cvpr42600.2020.00203
-
[52]
In: Computer Vision and Pat- tern Recognition
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: Computer Vision and Pat- tern Recognition. pp. 10371–10381. IEEE (2024).https://doi.org/10.1109/ CVPR52733.2024.00987
arXiv 2024
-
[53]
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything V2. In: Neural Information Processing Systems. pp. 21875–21911. Neu- ral Information Processing Systems Foundation, Inc. (NeurIPS) (2024).https: //doi.org/10.48550/arXiv.2406.09414
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09414 2024
-
[54]
In: IEEE International Conference on Computer Vision
Yao, C., Yu, L., Liu, Z., Zeng, J., Wu, Y., Jia, Y.: Diving into the fusion of monoc- ular priors for generalized stereo matching. In: IEEE International Conference on Computer Vision. pp. 14887–14897. IEEE (2025).https://doi.org/10.1109/ ICCV51701.2025.01381
arXiv 2025
-
[55]
Remote Sensing16(23), 4570 (2024).https://doi.org/ 10.3390/rs16234570 20 Y
Zhu, L., Gao, Y., Zhang, J., Li, Y., Li, X.: Reliable and effective stereo matching for underwater scenes. Remote Sensing16(23), 4570 (2024).https://doi.org/ 10.3390/rs16234570 20 Y. Wang et al. Appendix A Additional Ablation Studies We supplement the ablation studies in the main text with additional hyper- parameter sweeps covering HSCV structure (Tab. 8...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.