UniTeD: Unified Temporal Diffusion for Joint Perception and Planning in Autonomous Driving
Pith reviewed 2026-06-25 21:11 UTC · model grok-4.3
The pith
UniTeD places perception and planning inside one shared diffusion denoising process for autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniTeD jointly models perception and planning through iterative denoising in a shared generative space, enabling bidirectional information exchange that facilitates mutual refinement between tasks and improves robustness via noise-conditioned multi-task training, while extending to streaming settings with TTM and ARS to achieve SOTA performance.
What carries the argument
The shared generative diffusion space in which perception outputs and planning trajectories are denoised together so that each task conditions and improves the other at every step.
If this is right
- Perception mistakes get corrected during the joint denoising steps instead of being passed forward unchanged.
- The same model can handle both tasks without separate networks or hand-off points.
- Streaming operation becomes possible once the temporal transition module aligns noise schedules across frames.
- Anchor refresh during training reduces the gap between training and test distributions in sparse trajectory prediction.
Where Pith is reading between the lines
- The joint diffusion approach could be tested on other paired vision tasks such as detection plus depth estimation to see if the refinement benefit generalizes.
- If the shared space works, it reduces the need for separate perception pre-training stages in end-to-end driving stacks.
- One could measure whether the bidirectional exchange actually occurs by tracking how much planning outputs change perception features at each denoising step.
Load-bearing premise
Placing perception and planning inside the same diffusion process will produce useful mutual refinement and robustness gains without creating new optimization problems that the noise-conditioned training cannot handle.
What would settle it
An ablation that replaces the shared diffusion space with independent perception and planning modules and measures whether planning accuracy drops more sharply when perception inputs are deliberately degraded.
Figures
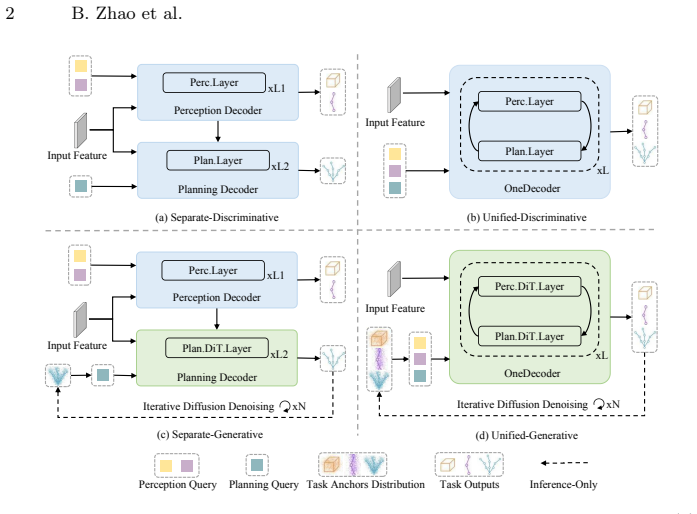
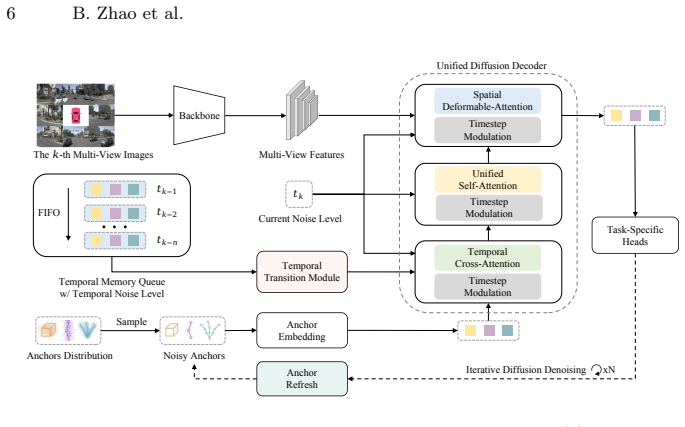
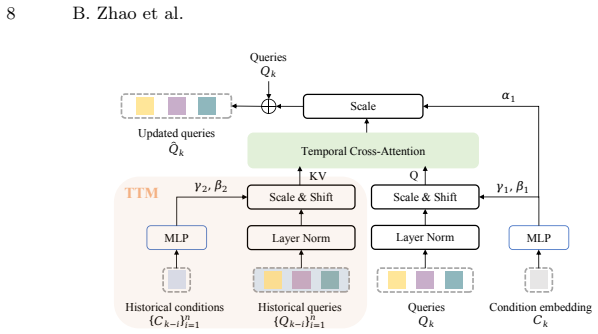
read the original abstract
Diffusion models have shown strong potential for multi-modal planning in end-to-end autonomous driving. However, most existing methods confine diffusion to the planning module, conditioning on fixed outputs from separate discriminative perception networks. This decoupled design propagates perception errors to the planner, increasing optimization difficulty and reducing robustness. To overcome these limitations, we propose UniTeD, a Unified Temporal Diffusion framework that jointly models perception and planning through iterative denoising in a shared generative space. By enabling bidirectional information exchange, the framework facilitates mutual refinement between tasks and improves robustness via noise-conditioned multi-task training. We further extend this unified diffusion paradigm to a streaming setting by incorporating temporal context. A Temporal Transition Module (TTM) is introduced to resolve the noise-level mismatch between historical and current frames. In addition, we propose an Anchor Refresh Strategy (ARS) to alleviate the training-inference distribution shift commonly observed in sparse diffusion-based end-to-end driving frameworks. Without bells and whistles, UniTeD achieves state-of-the-art performance across multiple benchmarks, surpassing both recent discriminative end-to-end methods and diffusion-based planning approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniTeD, a Unified Temporal Diffusion framework for autonomous driving that jointly models perception and planning in a shared generative diffusion space. This design aims to enable bidirectional information exchange for mutual refinement between the tasks, with robustness gains from noise-conditioned multi-task training. The framework is extended to streaming settings using a Temporal Transition Module (TTM) to handle noise-level mismatch and an Anchor Refresh Strategy (ARS) to mitigate training-inference distribution shift, claiming state-of-the-art performance on multiple benchmarks.
Significance. If the joint diffusion approach successfully achieves effective bidirectional refinement and robustness improvements, it would address a key limitation in current end-to-end driving methods where perception errors propagate to planning. The unified paradigm could lead to more integrated and robust autonomous driving systems. The streaming extensions demonstrate practical applicability.
major comments (2)
- [Abstract] Abstract: The central claim that placing perception and planning in a shared generative space produces bidirectional information exchange and mutual refinement relies on 'noise-conditioned multi-task training' as the mechanism. However, the abstract provides no explicit description of cross-task conditioning, shared attention mechanisms, or gradient balancing terms that would enforce information exchange during denoising. Without such structure, the joint objective may not prevent error propagation, undermining the robustness claim.
- [Abstract] Abstract: The SOTA performance claim is presented without reference to specific benchmarks, baselines, or quantitative improvements. Given that no experimental details, ablations, or error bars are mentioned, it is difficult to evaluate whether the gains are attributable to the unified framework or other factors.
minor comments (1)
- [Abstract] Abstract: The phrase 'Without bells and whistles' is used while simultaneously introducing TTM and ARS; clarify whether these modules are core to the unified framework or additional contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater explicitness would strengthen the summary and will revise the abstract accordingly to clarify mechanisms and results. The full manuscript provides the architectural and experimental details supporting the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that placing perception and planning in a shared generative space produces bidirectional information exchange and mutual refinement relies on 'noise-conditioned multi-task training' as the mechanism. However, the abstract provides no explicit description of cross-task conditioning, shared attention mechanisms, or gradient balancing terms that would enforce information exchange during denoising. Without such structure, the joint objective may not prevent error propagation, undermining the robustness claim.
Authors: The abstract is intentionally concise. Bidirectional exchange occurs because perception (e.g., object features) and planning (trajectories) are represented and denoised jointly in the same latent space; each denoising step updates both outputs using the shared network, allowing gradients from one task to influence the other. Noise-conditioned multi-task training applies the diffusion objective to both tasks across noise levels, which empirically balances their contributions without explicit gradient terms. The full paper (Section 3) details the shared U-Net backbone and joint loss. We will revise the abstract to briefly reference the joint iterative denoising process. revision: yes
-
Referee: [Abstract] Abstract: The SOTA performance claim is presented without reference to specific benchmarks, baselines, or quantitative improvements. Given that no experimental details, ablations, or error bars are mentioned, it is difficult to evaluate whether the gains are attributable to the unified framework or other factors.
Authors: Abstract length constraints limit detail; the manuscript reports results on nuScenes and Waymo with comparisons to recent discriminative and diffusion baselines, including ablations on TTM/ARS and error bars. We will update the abstract to name the primary benchmarks and note the nature of the gains (e.g., consistent improvements on planning metrics). revision: yes
Circularity Check
No circularity: architectural proposal remains independent of inputs
full rationale
The provided abstract and description introduce UniTeD as a new joint diffusion framework whose core mechanism (shared generative space enabling bidirectional refinement via noise-conditioned multi-task training) is presented as an architectural choice rather than a mathematical reduction. No equations appear that equate outputs to fitted parameters or prior self-defined quantities by construction, and no self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The TTM and ARS extensions are described as additions for streaming and shift mitigation without reducing the central claim to self-referential definitions. This leaves the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv e-prints pp
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-VL Technical Report. arXiv e-prints pp. arXiv–2502 (2025)
2025
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuScenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11621–11631 (2020)
2020
-
[3]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Caesar, H., Kabzan, J., Tan, K.S., Fong, W.K., Wolff, E., Lang, A., Fletcher, L., Beijbom, O., Omari, S.: nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [5]
-
[6]
Advances in Neural Information Processing Systems 36, 1863–1888 (2023)
Chen, J., Deng, R., Furukawa, Y.: Polydiffuse: Polygonal Shape Reconstruction via Guided Set Diffusion Models. Advances in Neural Information Processing Systems 36, 1863–1888 (2023)
2023
-
[7]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Chen, S., Jiang, B., Gao, H., Liao, B., Xu, Q., Zhang, Q., Huang, C., Liu, W., Wang, X.: Vadv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning. arXiv preprint arXiv:2402.13243 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, S., Sun, P., Song, Y., Luo, P.: DiffusionDet: Diffusion Model for Object De- tection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19830–19843 (2023)
2023
-
[9]
Pluto: Pushing the limit of imita- tion learning-based planning for autonomous driving,
Cheng, J., Chen, Y., Chen, Q.: PLUTO: Pushing the Limit of Imitation Learning- based Planning for Autonomous Driving. arXiv preprint arXiv:2404.14327 (2024)
-
[10]
The Inter- national Journal of Robotics Research44(10-11), 1684–1704 (2025)
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. The Inter- national Journal of Robotics Research44(10-11), 1684–1704 (2025)
2025
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving. IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Cui, A., Casas, S., Sadat, A., Liao, R., Urtasun, R.: Lookout: Diverse Multi-Future Prediction and Planning for Self-Driving. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 16107–16116 (2021)
2021
-
[13]
In: Conference on Robot Learning
Dauner, D., Hallgarten, M., Geiger, A., Chitta, K.: Parting with Misconceptions about Learning-based Vehicle Motion Planning. In: Conference on Robot Learning. pp. 1268–1281. PMLR (2023)
2023
-
[14]
Advances in Neural Information Processing Systems37, 28706–28719 (2024) 16 B
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschenski, I., Ivanovic, B., Pavone, M., et al.: NAVSIM: Data-Driven Non- Reactive Autonomous Vehicle Simulation and Benchmarking. Advances in Neural Information Processing Systems37, 28706–28719 (2024) 16 B. Zhao et al
2024
-
[15]
Ad- vances in Neural Information Processing Systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion Models Beat GANs on Image Synthesis. Ad- vances in Neural Information Processing Systems34, 8780–8794 (2021)
2021
-
[16]
In: Conference on Robot Learning
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V.: CARLA: An Open Urban Driving Simulator. In: Conference on Robot Learning. pp. 1–16. PMLR (2017)
2017
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, J., Sun, C., Zhao, H., Shen, Y., Anguelov, D., Li, C., Schmid, C.: Vector- Net: Encoding HD Maps and Agent Dynamics from Vectorized Representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11525–11533 (2020)
2020
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gu, J., Hu, C., Zhang, T., Chen, X., Wang, Y., Wang, Y., Zhao, H.: ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5496–5506 (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented Autonomous Driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17853– 17862 (2023)
2023
-
[20]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Huang, J., Huang, G., Zhu, Z., Ye, Y., Du, D.: BEVDet: High-Performance Multi- Camera 3D Object Detection in Bird-Eye-View. arXiv preprint arXiv:2112.11790 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
IEEE Robotics and Automation Letters9(11), 9836–9843 (2024)
Jia, P., Wen, T., Luo, Z., Yang, M., Jiang, K., Liu, Z., Tang, X., Lei, Z., Cui, L., Zhang, B., et al.: DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model. IEEE Robotics and Automation Letters9(11), 9836–9843 (2024)
2024
-
[22]
Advances in Neural Information Processing Systems37, 819–844 (2024)
Jia, X., Yang, Z., Li, Q., Zhang, Z., Yan, J.: Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving. Advances in Neural Information Processing Systems37, 819–844 (2024)
2024
- [23]
-
[24]
arXiv preprint arXiv:2212.02181 (2022)
Jiang, B., Chen, S., Wang, X., Liao, B., Cheng, T., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang, C.: Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction. arXiv preprint arXiv:2212.02181 (2022)
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang,B.,Chen,S.,Xu,Q.,Liao,B.,Chen,J.,Zhou,H.,Zhang,Q.,Liu,W.,Huang, C., Wang, X.: VAD: Vectorized Scene Representation for Efficient Autonomous Driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8340–8350 (2023)
2023
-
[26]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, C., Cornman, A., Park, C., Sapp, B., Zhou, Y., Anguelov, D., et al.: Motion- Diffuser: Controllable Multi-Agent Motion Prediction using Diffusion. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9644–9653 (2023)
2023
-
[27]
arXiv preprint arXiv:2503.10434 (2025)
Li, D., Li, C., Wang, Y., Ren, J., Wen, X., Li, P., Xu, L., Zhan, K., Jia, P., Lang, X., et al.: Learning Personalized Driving Styles via Reinforcement Learning from Human Feedback. arXiv preprint arXiv:2503.10434 (2025)
-
[28]
arXiv preprint arXiv:2601.05640 (2026)
Li, J., Wu, J., Hu, D., Huang, X., Sun, B., Hao, Z., Lang, X., Zhu, X., Zhang, L.: SGDrive: Scene-to-Goal Hierarchical World Cognition for Autonomous Driving. arXiv preprint arXiv:2601.05640 (2026)
-
[29]
arXiv preprint arXiv:2508.11428 (2025)
Li, J., Zhang, B., Jin, X., Deng, J., Zhu, X., Zhang, L.: ImagiDrive: A Unified Imagination-and-Planning Framework for Autonomous Driving. arXiv preprint arXiv:2508.11428 (2025)
-
[30]
arXiv preprint arXiv:2503.12820 (2025) UniTeD for Autonomous Driving 17
Li, K., Li, Z., Lan, S., Xie, Y., Zhang, Z., Liu, J., Wu, Z., Yu, Z., Alvarez, J.M.: Hydra-MDP++: Advancing End-to-End Driving via Expert-Guided Hydra- Distillation. arXiv preprint arXiv:2503.12820 (2025) UniTeD for Autonomous Driving 17
-
[31]
In: International Conference on Robotics and Automation
Li, Q., Wang, Y., Wang, Y., Zhao, H.: HDMapNet: An Online HD Map Construc- tion and Evaluation Framework. In: International Conference on Robotics and Automation. pp. 4628–4634. IEEE (2022)
2022
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-End Driving with Online Trajectory Evaluation via BEV World Model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27137–27146 (2025)
2025
-
[33]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra- Distillation. arXiv preprint arXiv:2406.06978 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(3), 2020–2036 (2024)
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spa- tiotemporal Transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence47(3), 2020–2036 (2024)
2020
-
[36]
arXiv preprint arXiv:2208.14437 (2022)
Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction. arXiv preprint arXiv:2208.14437 (2022)
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12037–12047 (2025)
2025
-
[38]
International Journal of Computer Vision133(3), 1352–1374 (2025)
Liao, B., Chen, S., Zhang, Y., Jiang, B., Zhang, Q., Liu, W., Huang, C., Wang, X.: MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construc- tion. International Journal of Computer Vision133(3), 1352–1374 (2025)
2025
-
[39]
arXiv preprint arXiv:2211.10581 (2022)
Lin, X., Lin, T., Pei, Z., Huang, L., Su, Z.: Sparse4D: Multi-view 3D Object Detec- tion with Sparse Spatial-Temporal Fusion. arXiv preprint arXiv:2211.10581 (2022)
-
[40]
arXiv preprint arXiv:2311.11722 (2023)
Lin, X., Pei, Z., Lin, T., Huang, L., Su, Z.: Sparse4D v3: Advancing End-to-End 3D Detection and Tracking. arXiv preprint arXiv:2311.11722 (2023)
-
[41]
arXiv preprint arXiv:2506.00034 (2025)
Liu, S., Liang, Q., Li, Z., Li, B., Huang, K.: GaussianFusion: Gaussian- Based Multi-Sensor Fusion for End-to-End Autonomous Driving. arXiv preprint arXiv:2506.00034 (2025)
-
[42]
In: European Conference on Computer Vision
Liu, Y., Wang, T., Zhang, X., Sun, J.: PETR: Position Embedding Transforma- tion for Multi-View 3D Object Detection. In: European Conference on Computer Vision. pp. 531–548. Springer (2022)
2022
-
[43]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Luo, R., Song, Z., Ma, L., Wei, J., Yang, W., Yang, M.: DiffusionTrack: Diffusion Model For Multi-Object Tracking. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 3991–3999 (2024)
2024
-
[44]
arXiv preprint arXiv:2509.13769 (2025)
Luo, Y., Li, F., Xu, S., Lai, Z., Yang, L., Chen, Q., Luo, Z., Xie, Z., Jiang, S., Liu, J., et al.: AdaThinkDrive: Adaptive Thinking via Reinforcement Learning for Autonomous Driving. arXiv preprint arXiv:2509.13769 (2025)
-
[45]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peebles, W., Xie, S.: Scalable Diffusion Models with Transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4195–4205 (2023)
2023
-
[46]
In: European Conference on Computer Vision
Sadat, A., Casas, S., Ren, M., Wu, X., Dhawan, P., Urtasun, R.: Perceive, Predict, and Plan: Safe Motion Planning Through Interpretable Semantic Representations. In: European Conference on Computer Vision. pp. 414–430. Springer (2020)
2020
-
[47]
arXiv preprint arXiv:2509.17940 (2025) 18 B
Shang, S., Chen, Y., Wang, Y., Li, Y., Zhang, Z.: DriveDPO: Policy Learn- ing via Safety DPO For End-to-End Autonomous Driving. arXiv preprint arXiv:2509.17940 (2025) 18 B. Zhao et al
-
[48]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising Diffusion Implicit Models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Song, Z., Jia, C., Liu, L., Pan, H., Zhang, Y., Wang, J., Zhang, X., Xu, S., Yang, L., Luo, Y.: Don’t Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22432–22441 (2025)
2025
-
[50]
arXiv preprint arXiv:2409.09777 (2024)
Su, H., Wu, W., Yan, J.: DiFSD: Ego-Centric Fully Sparse Paradigm with Uncer- tainty Denoising and Iterative Refinement for Efficient End-to-End Self-Driving. arXiv preprint arXiv:2409.09777 (2024)
-
[51]
In: 2025 IEEE International Conference on Robotics and Automation
Sun, W., Lin, X., Shi, Y., Zhang, C., Wu, H., Zheng, S.: SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation. In: 2025 IEEE International Conference on Robotics and Automation. pp. 8795–8801. IEEE (2025)
2025
-
[52]
arXiv preprint arXiv:2503.08612 (2025)
Tang,Y.,Xu,Z.,Meng,Z.,Cheng,E.:HiP-AD:HierarchicalandMulti-Granularity Planning with Deformable Attention for Autonomous Driving in a Single Decoder. arXiv preprint arXiv:2503.08612 (2025)
-
[53]
arXiv preprint arXiv:2503.12170 (2025)
Wang, T., Zhang, C., Qu, X., Li, K., Liu, W., Huang, C.: DiffAD: A Unified Diffu- sion Modeling Approach for Autonomous Driving. arXiv preprint arXiv:2503.12170 (2025)
-
[54]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, Z., Zhang, W., Zhang, W., Tan, X., Liu, H., Wang, Y., Li, G.: LaneDiffusion: Improving Centerline Graph Learning via Prior Injected BEV Feature Generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27052–27062 (2025)
2025
-
[55]
Weng, X., Ivanovic, B., Wang, Y., Wang, Y., Pavone, M.: PARA-Drive: Parallelized ArchitectureforReal-timeAutonomousDriving.In:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15449–15458 (2024)
2024
-
[56]
arXiv preprint arXiv:2506.06659 (2025)
Yao, W., Li, Z., Lan, S., Wang, Z., Sun, X., Alvarez, J.M., Wu, Z.: DriveSuprim: Towards Precise Trajectory Selection for End-to-End Planning. arXiv preprint arXiv:2506.06659 (2025)
-
[57]
arXiv preprint arXiv:2511.17150 (2025)
Yin,L.,Ju,R.,Guo,G.,Cheng,E.:DiffRefiner:CoarsetoFineTrajectoryPlanning via Diffusion Refinement with Semantic Interaction for End to End Autonomous Driving. arXiv preprint arXiv:2511.17150 (2025)
-
[58]
In: European Conference on Com- puter Vision
Zeng, F., Dong, B., Zhang, Y., Wang, T., Zhang, X., Wei, Y.: MOTR: End-to-End Multiple-Object Tracking with Transformer. In: European Conference on Com- puter Vision. pp. 659–675. Springer (2022)
2022
-
[59]
arXiv preprint arXiv:2510.11092 (2025)
Zhang, B., Song, N., Li, J., Zhu, X., Deng, J., Zhang, L.: FLARE: Learning Future- Aware Latent Representations from Vision-Language Models for Autonomous Driving. arXiv preprint arXiv:2510.11092 (2025)
-
[60]
arXiv preprint arXiv:2510.08562 (2025)
Zheng, Z., Chen, S., Yin, H., Zhang, X., Zou, J., Wang, X., Zhang, Q., Zhang, L.: ResAD: Normalized Residual Trajectory Modeling for End-to-End Autonomous Driving. arXiv preprint arXiv:2510.08562 (2025)
-
[61]
Zhou, Z., Cai, T., Zhao, S.Z., Zhang, Y., Huang, Z., Zhou, B., Ma, J.: AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adap- tive Reasoning and Reinforcement Fine-Tuning. arXiv preprint arXiv:2506.13757 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv preprint arXiv:2010.04159 (2020) UniTeD for Autonomous Driving 19
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[64]
arXiv preprint arXiv:2412.09602 (2024)
Zimmerlin, J., Beißwenger, J., Jaeger, B., Geiger, A., Chitta, K.: Hidden Biases of End-to-End Driving Datasets. arXiv preprint arXiv:2412.09602 (2024)
-
[65]
Zou, J., Chen, S., Liao, B., Zheng, Z., Song, Y., Zhang, L., Zhang, Q., Liu, W., Wang, X.: DiffusionDriveV2: Reinforcement Learning-Constrained Trun- cated Diffusion Modeling in End-to-End Autonomous Driving. arXiv preprint arXiv:2512.07745 (2025) Appendix This supplementary material is the Appendix referenced in the main manuscript. It includes additiona...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.