Same Evidence, Different Answer: Auditing Order Sensitivity in Multimodal Large Language Models
Pith reviewed 2026-06-25 19:56 UTC · model grok-4.3
The pith
Audits of 18 multimodal LLMs find none remain invariant when input order changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
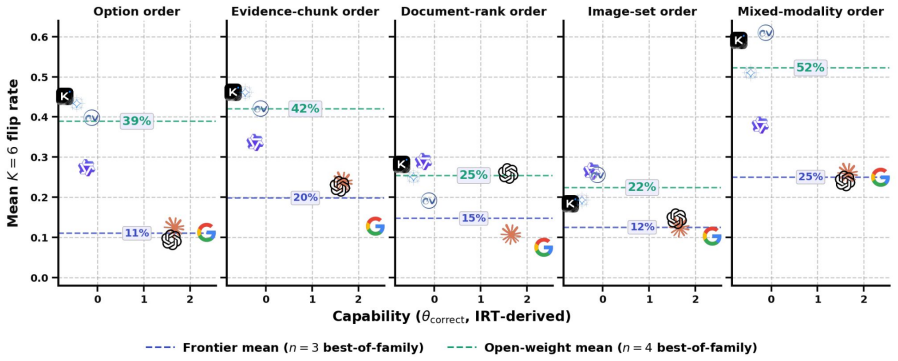
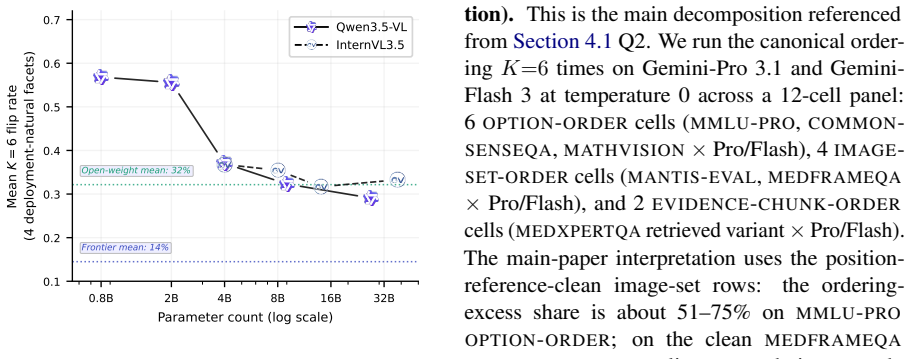
None of the 18 audited MLLMs are order-invariant. Screened per-facet panel-mean flip rates span 24-50 percent. A Bayesian item-response model isolates ordering noise from bias, and a Gemini same-ordering control at temperature 0 shows excess flips beyond the decoder-stochastic floor. Higher capability correlates with fewer flips, yet the strongest model still flips on 13.4 percent of trials. Prompt-level mitigation attempts are modality-conditional and fail to transfer from text to visual reasoning.
What carries the argument
Facet-Probe, a five-facet audit covering option ordering, evidence-chunk ordering, document-rank ordering, image-set ordering, and mixed-modality ordering, together with a Bayesian item-response model that separates ordering effects from per-facet bias and a same-ordering control that estimates decoder noise.
If this is right
- Cross-ordering flip rate should be reported as a standard evaluation axis for MLLMs.
- Prompt-level changes do not yield general order robustness across modalities.
- Training-time and architectural methods will be needed to achieve order invariance.
- Even the strongest models flip answers on more than 13 percent of reordered trials.
Where Pith is reading between the lines
- Real-world deployments that draw evidence from multiple sources in varying sequence may see inconsistent outputs from the same model.
- Benchmarks that always present inputs in one canonical order can mask reliability gaps that appear once ordering is randomized.
- If order sensitivity persists at scale, downstream systems that chain multimodal models may accumulate contradictory decisions.
Load-bearing premise
The same-ordering control at temperature 0 accurately measures the decoder-stochastic floor so that any remaining flips can be attributed to ordering sensitivity.
What would settle it
If flip rates measured under changed orderings equal those measured under identical orderings at temperature zero, the claim of ordering sensitivity beyond decoder noise would not hold.
Figures

read the original abstract
Standard benchmarks for multimodal large language models (MLLMs) score each item on one canonical ordering and miss whether order-irrelevant shuffling changes the answer, a baseline reliability property called for by emerging AI evaluation guidelines. We introduce Facet-Probe, a five-facet audit (option, evidence-chunk, document-rank, image-set, and mixed-modality ordering) of 18 frontier and open-weight MLLMs. A Bayesian item-response model separates ordering noise from per-facet bias, and a same-ordering control estimates the decoder-stochastic floor for observed flips. We find that none of the 18 MLLMs we audit are order-invariant: screened per-facet panel-mean flip rates span 24-50%. A Gemini same-ordering control at temperature 0 estimates a substantial ordering excess over a same-input decoder-noise floor in verified cells. Capability predicts but does not eliminate flips; the best model still flips on 13.4% of trials. In our Gemini mitigation tests, training-free prompt changes are modality-conditional and do not transfer from text to visual reasoning. These results suggest that prompt-level mitigation alone is unlikely to provide general order robustness, motivating future work on training-time and architectural approaches. We propose cross-ordering flip rate as a standard reporting axis for MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Facet-Probe, a five-facet audit (option, evidence-chunk, document-rank, image-set, mixed-modality) of order sensitivity in 18 frontier and open-weight MLLMs. It employs a Bayesian item-response model to separate ordering noise from bias and a same-ordering control at temperature 0 to estimate the decoder-stochastic floor. The central finding is that none of the 18 models are order-invariant, with screened per-facet panel-mean flip rates spanning 24-50%; capability predicts but does not eliminate flips, and training-free prompt mitigations are modality-conditional and non-transferable.
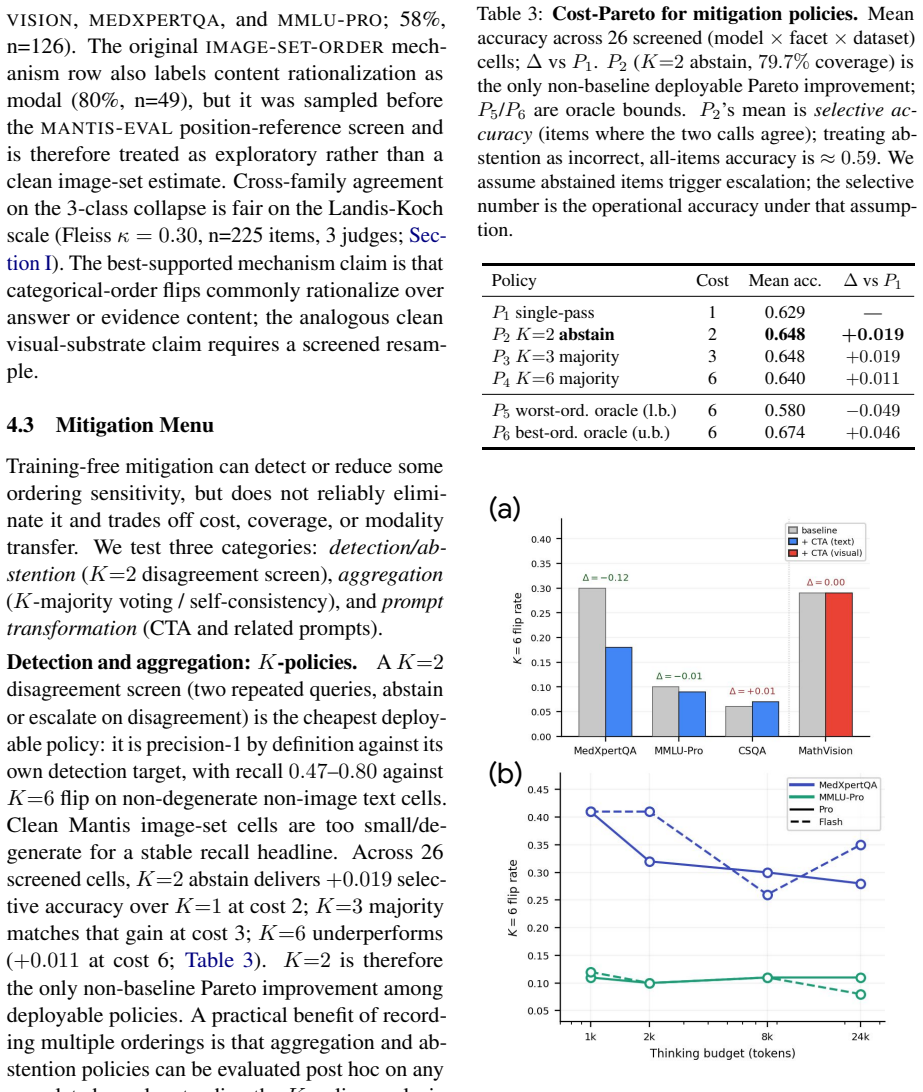
Significance. If the results hold after addressing the control-condition gap, the work supplies a concrete, falsifiable metric (cross-ordering flip rate) that directly addresses emerging AI evaluation guidelines on reliability. The explicit same-ordering control condition and Bayesian separation of noise sources are methodological strengths that distinguish this from purely observational audits. The finding that even the strongest model flips on 13.4% of trials and that prompt mitigation does not generalize motivates training-time and architectural research.
major comments (2)
- [Abstract] Abstract: the claim that none of the 18 MLLMs are order-invariant rests on attributing observed flip rates (24-50%) to ordering sensitivity rather than other output variability. However, the same-ordering control at temperature 0 that quantifies the decoder-stochastic floor is reported only for Gemini in verified cells; no equivalent per-model controls or justification for generalizing the floor are provided for the remaining 17 models.
- [Methods] Methods / Results: the data selection criteria, exclusion rules, and exact procedure for fitting the Bayesian item-response model are not visible, preventing verification that the reported panel-mean flip rates are supported by the underlying item-level data.
minor comments (2)
- [Abstract] The abstract states that 'capability predicts but does not eliminate flips' yet does not cite the specific correlation coefficient or regression table supporting this claim.
- Figure captions should explicitly label which panels include the Gemini same-ordering control versus the main ordering conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important issues of verifiability and scope in our audit of order sensitivity. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that none of the 18 MLLMs are order-invariant rests on attributing observed flip rates (24-50%) to ordering sensitivity rather than other output variability. However, the same-ordering control at temperature 0 that quantifies the decoder-stochastic floor is reported only for Gemini in verified cells; no equivalent per-model controls or justification for generalizing the floor are provided for the remaining 17 models.
Authors: We agree that the same-ordering control at temperature 0 was performed exclusively for Gemini, as indicated by the phrase 'in verified cells' in the manuscript. The central claim that none of the 18 models are order-invariant is based on the observed per-facet flip rates (24-50%) across all models, which we interpret as evidence of ordering sensitivity; the Gemini control serves to demonstrate that these rates exceed the decoder-stochastic floor in at least one case. However, without equivalent controls for the other models, the separation of ordering effects from other variability is less rigorous for those 17. We will revise the abstract and discussion to explicitly qualify the decoder-noise comparison as Gemini-specific and to note that generalization of the floor relies on the assumption that decoder stochasticity is comparable across models of similar scale and architecture. This constitutes a partial revision, as collecting new same-order controls for all models would require additional experiments beyond the current study. revision: partial
-
Referee: [Methods] Methods / Results: the data selection criteria, exclusion rules, and exact procedure for fitting the Bayesian item-response model are not visible, preventing verification that the reported panel-mean flip rates are supported by the underlying item-level data.
Authors: We acknowledge that the submitted manuscript did not provide sufficient detail on data selection criteria, exclusion rules, and the precise Bayesian item-response model specification and fitting procedure. In the revised manuscript we will expand the Methods section to include: (i) the full item sampling and filtering criteria, (ii) any exclusion rules applied to responses or items, and (iii) the complete model formulation (including likelihood, priors, and inference method) together with code or pseudocode for reproducibility. These additions will directly support verification of the reported panel-mean flip rates from the item-level data. revision: yes
Circularity Check
No circularity; empirical audit reports observed flip rates with explicit control condition
full rationale
The paper presents an empirical audit of 18 MLLMs using Facet-Probe across five ordering facets, reporting per-facet panel-mean flip rates of 24-50% and noting that none are order-invariant. A Bayesian item-response model is used to separate noise from bias, and a same-ordering control at temperature 0 is invoked to estimate the decoder-stochastic floor (explicitly limited to Gemini verified cells). No equations, derivations, or first-principles results are claimed that reduce the reported flip rates or invariance conclusions to fitted parameters or self-citations by construction. The central claims rest on direct measurements against an external benchmark (model outputs under controlled orderings), with the control serving as a methodological check rather than a definitional or fitted-input reduction. This is a standard empirical measurement setup with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of the American Medical Informatics Association , volume=
The impact of nuance DAX ambient listening AI documentation: a cohort study , author=. Journal of the American Medical Informatics Association , volume=. 2024 , publisher=
2024
-
[2]
NEJM Catalyst Innovations in Care Delivery , volume=
Ambient artificial intelligence scribes to alleviate the burden of clinical documentation , author=. NEJM Catalyst Innovations in Care Delivery , volume=. 2024 , publisher=
2024
-
[3]
Journal of Primary Care & Community Health , volume=
The use of an artificial intelligence platform OpenEvidence to augment clinical decision-making for primary care physicians , author=. Journal of Primary Care & Community Health , volume=. 2025 , publisher=
2025
-
[4]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[5]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Ask in any modality: A comprehensive survey on multimodal retrieval-augmented generation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[6]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Who is in the Spotlight: The Hidden Bias Undermining Multimodal Retrieval-Augmented Generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[7]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Tool Preferences in Agentic LLMs are Unreliable , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[9]
arXiv preprint arXiv:2507.13334 , year=
A survey of context engineering for large language models , author=. arXiv preprint arXiv:2507.13334 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Measuring what matters: Construct validity in large language model benchmarks , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2505.10573 , year=
Measurement to meaning: A validity-centered framework for ai evaluation , author=. arXiv preprint arXiv:2505.10573 , year=
-
[12]
2026 , note =
Practices for Automated Benchmark Evaluations of Language Models , author =. 2026 , note =
2026
-
[13]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2501.18362 , year=
Medxpertqa: Benchmarking expert-level medical reasoning and understanding , author=. arXiv preprint arXiv:2501.18362 , year=
-
[15]
arXiv preprint arXiv:2405.01483 , year=
Mantis: Interleaved multi-image instruction tuning , author=. arXiv preprint arXiv:2405.01483 , year=
-
[16]
arXiv preprint arXiv:2410.16983 , year=
Order matters: Exploring order sensitivity in multimodal large language models , author=. arXiv preprint arXiv:2410.16983 , year=
-
[17]
arXiv preprint arXiv:2509.03986 , year=
Promptception: How Sensitive Are Large Multimodal Models to Prompts? , author=. arXiv preprint arXiv:2509.03986 , year=
-
[18]
arXiv preprint arXiv:2603.02663 , year=
Evaluating Cross-Modal Reasoning Ability and Problem Characteristics with Multimodal Item Response Theory , author=. arXiv preprint arXiv:2603.02663 , year=
-
[19]
arXiv preprint arXiv:2605.22544 , year=
One prompt is not enough: Instruction Sensitivity Undermines Embedding Model Evaluation , author=. arXiv preprint arXiv:2605.22544 , year=
-
[20]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Large language models sensitivity to the order of options in multiple-choice questions , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[21]
arXiv preprint arXiv:2311.08596 , year=
Are you sure? challenging llms leads to performance drops in the flipflop experiment , author=. arXiv preprint arXiv:2311.08596 , year=
-
[22]
arXiv preprint arXiv:2402.08939 , year=
Premise order matters in reasoning with large language models , author=. arXiv preprint arXiv:2402.08939 , year=
-
[23]
" what’s up, doc?": Analyzing how users seek health information in large-scale conversational ai datasets , author=. arXiv preprint arXiv:2506.21532 , year=
-
[24]
arXiv preprint arXiv:2604.16383 , year=
Same Verdict, Different Reasons: LLM-as-a-Judge and Clinician Disagreement on Medical Chatbot Completeness , author=. arXiv preprint arXiv:2604.16383 , year=
-
[25]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[27]
International Conference on Learning Representations , volume=
Large language models are not robust multiple choice selectors , author=. International Conference on Learning Representations , volume=
-
[28]
International Conference on Learning Representations , volume=
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. International Conference on Learning Representations , volume=
-
[29]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Identifying and mitigating position bias of multi-image vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Betterbench: Assessing ai benchmarks, uncovering issues, and establishing best practices , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
arXiv preprint arXiv:2402.14992 , year=
tinyBenchmarks: evaluating LLMs with fewer examples , author=. arXiv preprint arXiv:2402.14992 , year=
-
[34]
arXiv preprint arXiv:2603.13285 , year=
Brittlebench: Quantifying LLM robustness via prompt sensitivity , author=. arXiv preprint arXiv:2603.13285 , year=
-
[35]
International Conference on Learning Representations , volume=
Eliminating position bias of language models: A mechanistic approach , author=. International Conference on Learning Representations , volume=
-
[36]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[37]
Transactions of the Association for Computational Linguistics , volume=
State of what art? a call for multi-prompt llm evaluation , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[38]
arXiv preprint arXiv:2509.24125 , year=
The Impossibility of Inverse Permutation Learning in Transformer Models , author=. arXiv preprint arXiv:2509.24125 , year=
-
[39]
2024 , eprint=
MMBench: Is Your Multi-modal Model an All-around Player? , author=. 2024 , eprint=
2024
-
[40]
2023 , eprint=
Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks , author=. 2023 , eprint=
2023
-
[41]
International Conference on Learning Representations (ICLR) , year =
Lu, Pan and Bansal, Hritik and Xia, Tony and Liu, Jiacheng and Li, Chunyuan and Hajishirzi, Hannaneh and Cheng, Hao and Chang, Kai-Wei and Galley, Michel and Gao, Jianfeng , title =. International Conference on Learning Representations (ICLR) , year =
-
[42]
2023 , eprint=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
2023
-
[43]
2024 , eprint=
Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models , author=. 2024 , eprint=
2024
-
[44]
2024 , eprint=
Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization , author=. 2024 , eprint=
2024
-
[45]
2019 , eprint=
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge , author=. 2019 , eprint=
2019
-
[46]
MathCoder-
Ke Wang and Junting Pan and Linda Wei and Aojun Zhou and Weikang Shi and Zimu Lu and Han Xiao and Yunqiao Yang and Houxing Ren and Mingjie Zhan and Hongsheng Li , booktitle=. MathCoder-. 2025 , url=
2025
-
[47]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[48]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=
-
[49]
2022 , eprint=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. 2022 , eprint=
2022
-
[50]
2024 , eprint=
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries , author=. 2024 , eprint=
2024
-
[51]
arXiv preprint arXiv:2505.16964 , year=
MedFrameQA: A Multi-Image Medical VQA Benchmark for Clinical Reasoning , author=. arXiv preprint arXiv:2505.16964 , year=
-
[52]
arXiv preprint arXiv:2502.04176 , year=
MRAMG-Bench: A BeyondText Benchmark for Multimodal Retrieval-Augmented Multimodal Generation , author=. arXiv preprint arXiv:2502.04176 , year=
-
[53]
2025 , eprint=
Benchmarking Retrieval-Augmented Multimodal Generation for Document Question Answering , author=. 2025 , eprint=
2025
-
[54]
2021 , eprint=
MultiModalQA: Complex Question Answering over Text, Tables and Images , author=. 2021 , eprint=
2021
-
[55]
arXiv preprint arXiv:2508.18265 , year=
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
-
[56]
Kimi Team and Angang Du and Bohong Yin and Bowei Xing and Bowen Qu and Bowen Wang and Cheng Chen and Chenlin Zhang and Chenzhuang Du and Chu Wei and Congcong Wang and Dehao Zhang and Dikang Du and Dongliang Wang and Enming Yuan and Enzhe Lu and Fang Li and Flood Sung and Guangda Wei and Guokun Lai and Han Zhu and Hao Ding and Hao Hu and Hao Yang and Hao Z...
-
[57]
arXiv preprint arXiv:2507.05201 , year=
MedGemma Technical Report , author=. arXiv preprint arXiv:2507.05201 , year=
-
[58]
Mountain View, CA: Google , year=
A new era of intelligence with gemini 3 , author=. Mountain View, CA: Google , year=
-
[59]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[60]
2026 , url =
Introducing. 2026 , url =
2026
-
[61]
, author=
The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. , author=. J. Mach. Learn. Res. , volume=
-
[62]
arXiv preprint arXiv:1912.11554 , year=
Composable effects for flexible and accelerated probabilistic programming in NumPyro , author=. arXiv preprint arXiv:1912.11554 , year=
Pith/arXiv arXiv 1912
-
[63]
JAX: composable transformations of Python+ NumPy programs , author=
-
[64]
Statistical theories of mental test scores , year=
Some latent trait models and their use in inferring an examinee's ability , author=. Statistical theories of mental test scores , year=
-
[65]
2025 , publisher=
Item response theory: Foundations for psychologists and social scientists , author=. 2025 , publisher=
2025
-
[66]
Challenges to the Monitoring of Deployed AI Systems , author=
-
[67]
Proceedings of the conference on fairness, accountability, and transparency , pages=
Model cards for model reporting , author=. Proceedings of the conference on fairness, accountability, and transparency , pages=
-
[68]
Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
The fallacy of AI functionality , author=. Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
2022
-
[69]
arXiv preprint arXiv:2503.10694 , year=
Medical large language model benchmarks should prioritize construct validity , author=. arXiv preprint arXiv:2503.10694 , year=
-
[70]
Advances in Neural Information Processing Systems , volume=
Set-llm: A permutation-invariant llm , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
Statistically valid post-deployment monitoring should be standard for AI-based digital health , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
arXiv preprint arXiv:2405.01470 , year=
Wildchat: 1m chatgpt interaction logs in the wild , author=. arXiv preprint arXiv:2405.01470 , year=
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Visionarena: 230k real world user-vlm conversations with preference labels , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.