PAMAE: Phase-Aware-MoE Action Experts Towards Reliable Flow-Matching Vision-Language-Action Policies
Pith reviewed 2026-06-26 05:02 UTC · model grok-4.3
The pith
PAMAE replaces the single action expert in flow-matching VLA policies with a phase-aware mixture of experts routed by execution phase cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
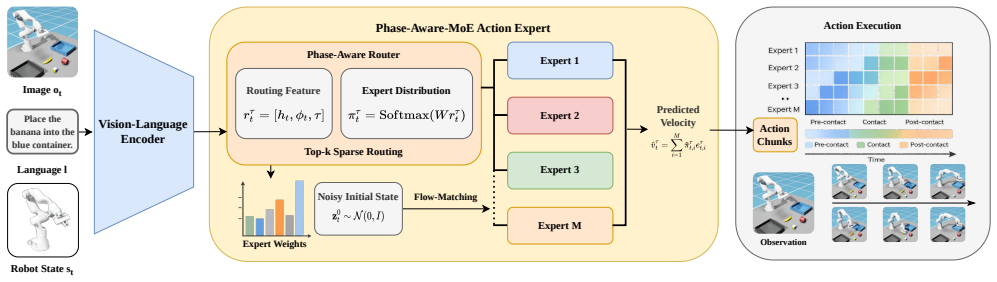
PAMAE replaces the original flow-matching action expert with a sparse expert mixture while preserving the pretrained VLA backbone. It introduces a phase-aware router that leverages execution-phase cues to allocate action generation across experts, supported by a lightweight phase prediction head and a routing alignment objective. To stabilize specialization, a two-stage training scheme first warms up the expert module under the standard flow-matching loss and then optimizes phase-consistent routing under auxiliary supervision. On multi-stage manipulation simulation tasks, PAMAE improves task success by up to 9.2 percent over strong VLA baselines, and ablations show both phase-supervised rout
What carries the argument
The Phase-Aware-MoE Action Module (PAMAE) that routes action generation to specialized experts via a phase-aware router driven by execution-phase cues from a lightweight prediction head.
If this is right
- Both phase-supervised routing and the two-stage optimization scheme are required to achieve the reported gains in task success.
- Phase-consistent expert allocation improves action quality and reliability across distinct execution stages in multi-stage tasks.
- The module functions as a plug-and-play addition that preserves the original pretrained VLA backbone.
- Sparse expert mixtures can capture phase-specific control patterns better than a single shared expert in flow-matching policies.
Where Pith is reading between the lines
- If phase prediction remains reliable under distribution shift, the same routing mechanism may extend to longer-horizon or more varied robotic tasks.
- The approach could be tested by measuring correlation between phase-prediction accuracy and final task success across multiple VLA backbones.
- Real-robot deployment would expose whether simulation-phase cues remain informative when sensor noise or dynamics mismatch is present.
Load-bearing premise
Execution-phase cues extracted by the lightweight prediction head are accurate and stable enough to guide expert routing without degrading the underlying flow-matching action generation.
What would settle it
Run an ablation that replaces the learned phase prediction head with random or fixed incorrect phase labels and measure whether the reported success-rate gains disappear or reverse.
Figures
read the original abstract
Reliable action generation for multi-stage robotic manipulation remains challenging for Vision-Language-Action (VLA) models. While existing flow-matching VLA policies offer strong multimodal grounding and generalization, they typically employ a single shared action expert, limiting their ability to capture phase-specific control patterns across distinct execution stages. We propose a plug-and-play Phase-Aware Mixture-of-Experts Action Module (PAMAE), as a step towards more reliable phase-consistent action generation. PAMAE replaces the original flow-matching action expert with a sparse expert mixture while preserving the pretrained VLA backbone. PAMAE introduces a phase-aware router that leverages execution-phase cues to allocate action generation across experts, supported by a lightweight phase prediction head and a routing alignment objective. To stabilize specialization, we adopt a two-stage training scheme that first warms up the expert module under the standard flow-matching loss and then optimizes phase-consistent routing under auxiliary supervision. On multi-stage manipulation simulation tasks, PAMAE improves task success by up to \textbf{9.2\%} over strong VLA baselines. Further ablations show that both phase-supervised routing and staged optimization are essential for the observed gains. Our results highlight phase-consistent expert allocation as an effective mechanism for improving the reliability and action quality of flow-matching VLA policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PAMAE, a plug-and-play Phase-Aware Mixture-of-Experts Action Module for flow-matching Vision-Language-Action (VLA) policies. It replaces the single action expert with a sparse mixture of experts, introduces a phase-aware router using execution-phase cues from a lightweight prediction head and a routing alignment objective, and employs a two-stage training scheme (warm-up under flow-matching loss followed by phase-consistent routing optimization). On multi-stage manipulation simulation tasks, it reports task success improvements of up to 9.2% over strong VLA baselines, with ablations indicating that both phase-supervised routing and staged optimization are essential.
Significance. If the empirical results hold, PAMAE provides a practical mechanism for improving action reliability in multi-stage robotic tasks by enabling phase-specific specialization in flow-matching VLAs while preserving the pretrained backbone. The approach is notable for its plug-and-play compatibility and the use of auxiliary supervision to stabilize expert allocation. This could contribute to more robust VLA policies in robotics, particularly where execution phases have distinct control requirements.
major comments (1)
- [Results] The central empirical claim of up to 9.2% task success improvement lacks supporting details on variance, trial counts, dataset sizes, or exact baseline configurations. This information is required to evaluate whether the gains are statistically reliable and reproducible.
minor comments (2)
- [Abstract] The abstract refers to 'strong VLA baselines' without naming them or providing citations; specifying these in the results or methods would improve clarity for readers.
- [Methods] The lightweight phase prediction head is described at a high level but without architecture details, input features, or accuracy metrics; including these would strengthen the methods section.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comment on the empirical presentation. We address the point below.
read point-by-point responses
-
Referee: [Results] The central empirical claim of up to 9.2% task success improvement lacks supporting details on variance, trial counts, dataset sizes, or exact baseline configurations. This information is required to evaluate whether the gains are statistically reliable and reproducible.
Authors: We agree that additional statistical details are necessary to substantiate the reported gains. In the revised manuscript we will expand the experimental section to report: (i) the number of evaluation trials per task (typically 50–100 episodes), (ii) mean and standard deviation of success rates across multiple random seeds, (iii) the exact sizes of the training and validation datasets, and (iv) the precise hyper-parameter and architecture configurations of each baseline. These additions will allow readers to assess reproducibility and statistical reliability. revision: yes
Circularity Check
No significant circularity; purely empirical architecture and results
full rationale
The paper introduces PAMAE as a plug-and-play module for flow-matching VLAs, describes a phase-aware router, lightweight prediction head, routing alignment objective, and two-stage training. All reported outcomes (up to 9.2% success improvement, ablation necessity of phase-supervised routing and staged optimization) are framed as measured results from simulation experiments on multi-stage manipulation tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or described claims. The central claim rests on external empirical validation rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generate subgoal images before act: Unlocking the chain- of-thought reasoning in diffusion model for robot manipulation with multimodal prompts,
F. Ni, J. Hao, S. Wu, L. Kou, J. Liu, Y . Zheng, B. Wang, and Y . Zhuang, “Generate subgoal images before act: Unlocking the chain- of-thought reasoning in diffusion model for robot manipulation with multimodal prompts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 991–14 000
2024
-
[2]
Scar: Refining skill chaining for long-horizon robotic manipulation via dual regularization,
Z. Chen, Z. Ji, J. Huo, and Y . Gao, “Scar: Refining skill chaining for long-horizon robotic manipulation via dual regularization,”Advances in Neural Information Processing Systems, vol. 37, pp. 111 679– 111 714, 2024
2024
-
[3]
Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks,
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jianget al., “Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks,” inProceedings of the IEEE/CVF International Conference on Com- puter Vision, 2025, pp. 11 142–11 152
2025
-
[4]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Open- vla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[6]
Octo: An Open-Source Generalist Robot Policy
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xuet al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Vision language action models in robotic manipulation: A systematic review,
M. U. Din, W. Akram, L. S. Saoud, J. Rosell, and I. Hussain, “Vision language action models in robotic manipulation: A systematic review,” 2025. [Online]. Available: https://arxiv.org/abs/2507.10672
-
[8]
Vision-Language-Action Models for Robotics: A Review Towards Real-World Appli- cations
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu, “Vision-language-action models for robotics: A review towards real- world applications,”IEEE Access, vol. 13, p. 162467–162504, 2025. [Online]. Available: http://dx.doi.org/10.1109/ACCESS.2025.3609980
-
[9]
Dynamicvla: A vision-language-action model for dynamic object manipulation,
H. Xie, B. Wen, J. Zheng, Z. Chen, F. Hong, H. Diao, and Z. Liu, “Dynamicvla: A vision-language-action model for dynamic object manipulation,” 2026. [Online]. Available: https://arxiv.org/abs/2601.22153
-
[10]
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models
Y . Jiang, S. Cheng, Y . Ding, F. Gao, and B. Qi, “Asyncvla: Asyn- chronous flow matching for vision-language-action models,”arXiv preprint arXiv:2511.14148, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Sa-vla: Spatially-aware flow-matching for vision-language-action reinforcement learning,
X. Pan, Z. Wan, X. Yu, X. Zheng, Y . Ke, M. Sun, R. Wang, Z. Wang, and I. Tsang, “Sa-vla: Spatially-aware flow-matching for vision-language-action reinforcement learning,”arXiv preprint arXiv:2602.00743, 2026
-
[12]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “pi 0: A vision- language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusaiet al., “π 0.5: a vision-language-action model with open-world generalization,”eprint arXiv: 2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Y . Fan, P. Ding, S. Bai, X. Tong, Y . Zhu, H. Lu, F. Dai, W. Zhao, Y . Liu, S. Huanget al., “Long-vla: Unleashing long-horizon capabil- ity of vision language action model for robot manipulation,”arXiv preprint arXiv:2508.19958, 2025
-
[15]
Lola: Long horizon latent action learning for general robot manipulation,
X. Wang, X. Gao, J. Fu, Z. Li, D. Fortier, G. Mullins, A. Kolobov, and B. Guo, “Lola: Long horizon latent action learning for general robot manipulation,”arXiv preprint arXiv:2512.20166, 2025
-
[16]
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
Z. Yang, Y . Chai, X. Jia, Q. Li, Y . Shao, X. Zhu, H. Su, and J. Yan, “Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving,”arXiv preprint arXiv:2505.16278, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Adamoe: Token- adaptive routing with null experts for mixture-of-experts language models,
Z. Zeng, Y . Miao, H. Gao, H. Zhang, and Z. Deng, “Adamoe: Token- adaptive routing with null experts for mixture-of-experts language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 6223–6235
2024
-
[18]
Himoe-vla: Hierarchical mixture-of- experts for generalist vision-language-action policies,
Z. Du, B. Liu, Y . Liang, Y . Shen, H. Cao, X. Zheng, Z. Feng, Z. Wu, J. Yang, and Y .-G. Jiang, “Himoe-vla: Hierarchical mixture-of- experts for generalist vision-language-action policies,”arXiv preprint arXiv:2512.05693, 2025
-
[19]
Ditea: Mixture-of-experts for vision-language- action model in robotic manipulation,
C. Li and X. Wang, “Ditea: Mixture-of-experts for vision-language- action model in robotic manipulation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 22, 2026, pp. 18 379– 18 387
2026
-
[20]
A process-centric manipulation taxonomy for the organization, classifica- tion and synthesis of tactile robot skills,
L. Johannsmeier, S. Schneider, Y . Li, E. Burdet, and S. Haddadin, “A process-centric manipulation taxonomy for the organization, classifica- tion and synthesis of tactile robot skills,”Nature Machine Intelligence, vol. 7, no. 6, pp. 916–927, 2025
2025
-
[21]
Dream: Dynamic routing of experts via attention-based mixture for vision- language-action modeling,
K. Sheng, L. Wang, Z. He, X. Lin, C. Liu, and Q. Chen, “Dream: Dynamic routing of experts via attention-based mixture for vision- language-action modeling,”Knowledge-Based Systems, p. 115585, 2026
2026
-
[22]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
dvla: Diffusion vision-language-action model with multimodal chain-of-thought,
J. Wen, M. Zhu, J. Liu, Z. Liu, Y . Yang, L. Zhang, S. Zhang, Y . Zhu, and Y . Xu, “dvla: Diffusion vision-language-action model with multimodal chain-of-thought,” 2025. [Online]. Available: https://arxiv.org/abs/2509.25681
-
[24]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[26]
Progressvla: Progress-guided diffusion policy for vision-language robotic manipulation,
H. Yan, Q. Li, J. Yang, and Y . Mu, “Progressvla: Progress-guided diffusion policy for vision-language robotic manipulation,”arXiv preprint arXiv:2603.27670, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.