DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
Pith reviewed 2026-05-22 14:27 UTC · model grok-4.3
The pith
Mixture-of-experts routers for vision and action let end-to-end driving models handle rare maneuvers without averaging behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
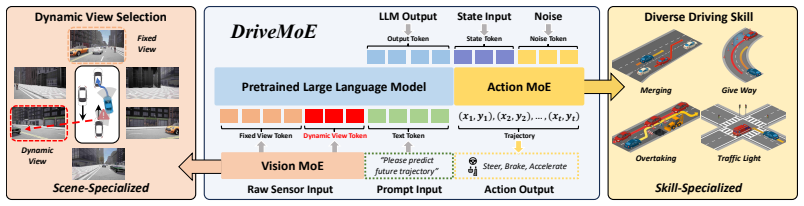
DriveMoE integrates a Scene-Specialized Vision MoE, whose router selects relevant cameras according to driving context, and a Skill-Specialized Action MoE, whose router activates behavior-specific expert modules, into the Drive-π0 vision-language-action baseline; this explicit specialization enables robust handling of diverse and complex scenarios, including rare aggressive maneuvers, and produces state-of-the-art closed-loop performance on Bench2Drive.
What carries the argument
Dual-router mixture-of-experts system: one router dynamically chooses which cameras to attend to, the other activates driving-behavior experts.
If this is right
- Dynamic camera selection reduces the need to process every sensor view at every moment.
- Behavior-specific action experts prevent dilution of rare but safety-critical maneuvers.
- The two MoE layers together produce higher closed-loop success rates than a single shared network.
- Explicit specialization supports scaling to wider ranges of driving contexts without retraining the entire model.
Where Pith is reading between the lines
- The router-based selection pattern could be reused in other multi-camera robotic control settings.
- Online fine-tuning of the routers might be needed to maintain performance as real-world conditions drift.
- Pairing this architecture with larger language models could add higher-level planning on top of the specialized low-level experts.
Load-bearing premise
Routers trained on the training distribution will correctly identify relevant cameras and driving behaviors when faced with diverse or unseen conditions.
What would settle it
A closed-loop test in which the model repeatedly selects unhelpful cameras or activates the wrong action experts on novel scenarios such as night driving or sudden weather changes, resulting in collisions or off-road events, would falsify the claim.
Figures



read the original abstract
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DriveMoE, a Mixture-of-Experts extension to the π₀ Vision-Language-Action baseline (Drive-π₀) for end-to-end autonomous driving. It introduces a Scene-Specialized Vision MoE that trains a router to dynamically select relevant camera views and a Skill-Specialized Action MoE that activates behavior-specific expert modules. The central empirical claim is that this combination yields state-of-the-art closed-loop performance on the Bench2Drive benchmark by enabling specialization without mode averaging, while mirroring human selective attention and behavioral handling of rare maneuvers.
Significance. If the empirical results hold, the work would provide evidence that MoE architectures can improve scalability and robustness in multi-view E2E-AD by avoiding parameter averaging across diverse scenarios. The planned release of code and models would further strengthen reproducibility for the community.
major comments (2)
- [Abstract and Experiments/Results section] The abstract and results description assert SOTA performance on Bench2Drive closed-loop evaluation but supply no quantitative metrics (e.g., success rate, collision rate, or route completion), baseline comparisons (including against Drive-π₀), or ablation results isolating the Vision MoE and Action MoE contributions. This absence prevents verification of the central claim that the routers drive the gains rather than the base VLA model.
- [Experiments and Discussion] No analysis is provided on router generalization or stability when visual inputs or required behaviors fall outside the training distribution (e.g., rare aggressive turns or unseen environments). Without such tests, it remains unclear whether the reported improvements stem from true specialization or from overfitting to the Bench2Drive training support.
minor comments (2)
- [Introduction and Method] The notation Drive-π₀ versus π₀ should be clarified consistently throughout to avoid confusion with the original embodied AI model.
- [Method] Figure captions and router diagrams would benefit from explicit labels indicating which router controls camera selection versus expert activation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and commit to revisions that strengthen the empirical presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and Experiments/Results section] The abstract and results description assert SOTA performance on Bench2Drive closed-loop evaluation but supply no quantitative metrics (e.g., success rate, collision rate, or route completion), baseline comparisons (including against Drive-π₀), or ablation results isolating the Vision MoE and Action MoE contributions. This absence prevents verification of the central claim that the routers drive the gains rather than the base VLA model.
Authors: We agree that the current manuscript version presents the SOTA claim in the abstract and results narrative without accompanying numerical values or ablations. This limits the reader's ability to verify the contribution of the routers. In the revised manuscript we will add a results table reporting closed-loop metrics (success rate, collision rate, route completion) for DriveMoE, the Drive-π₀ baseline, and prior methods, together with ablation tables that isolate the Vision MoE and Action MoE components. These additions will make explicit that the observed gains arise from the MoE routers rather than the base VLA architecture alone. revision: yes
-
Referee: [Experiments and Discussion] No analysis is provided on router generalization or stability when visual inputs or required behaviors fall outside the training distribution (e.g., rare aggressive turns or unseen environments). Without such tests, it remains unclear whether the reported improvements stem from true specialization or from overfitting to the Bench2Drive training support.
Authors: We acknowledge the absence of explicit out-of-distribution analysis for the routers. Bench2Drive already contains a range of challenging and infrequent maneuvers, yet we did not quantify router stability or selection patterns on held-out environments. In the revision we will add a dedicated subsection with qualitative router activation visualizations for rare aggressive turns and quantitative metrics (e.g., router entropy and performance drop) on a small set of unseen scenarios to demonstrate that the specialization generalizes beyond the training support. revision: yes
Circularity Check
No significant circularity: empirical SOTA claim on external benchmark
full rationale
The paper proposes DriveMoE as an architectural extension (Vision MoE for camera routing + Action MoE for behavior specialization) atop the Drive-π₀ baseline and reports closed-loop SOTA results on the external Bench2Drive benchmark. No derivation chain exists that reduces a claimed prediction or first-principles result to its own inputs by construction. The routers are trained on the training distribution and their generalization is an empirical question tested via benchmark metrics; the performance numbers are not forced by any self-definition, fitted-input renaming, or load-bearing self-citation of a uniqueness theorem. The central claim remains falsifiable against an independent benchmark and does not rely on internal re-labeling of fitted quantities as predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Router training hyperparameters and number of experts
axioms (1)
- domain assumption Mixture-of-Experts enables specialization that avoids mode averaging on diverse tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Scene-Specialized Vision MoE... router... Top-K... Skill-Specialized Action MoE... flow-matching planner... two-stage training
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 22 Pith papers
-
Bench2Drive-Robust: Benchmarking Closed-Loop Autonomous Driving under Deployment Perturbations
Bench2Drive-Robust is a new closed-loop benchmark that evaluates end-to-end autonomous driving models under deployment perturbations from camera failures, ego-state errors, and compute delays, showing substantial perf...
-
VECTOR-Drive: Tightly Coupled Vision-Language and Trajectory Expert Routing for End-to-End Autonomous Driving
VECTOR-DRIVE couples vision-language reasoning and trajectory planning in one Transformer via semantic expert routing and flow-matching, reaching 88.91 driving score on Bench2Drive.
-
Learning Vision-Language-Action World Models for Autonomous Driving
VLA-World improves autonomous driving by using action-guided future image generation followed by reflective reasoning over the imagined scene to refine trajectories.
-
LACO: Adaptive Latent Communication for Collaborative Driving
LACO introduces Iterative Latent Deliberation, Cross-Horizon Saliency Attribution, and Structured Semantic Knowledge Distillation to enable low-latency latent communication in collaborative driving while preserving pe...
-
One Model to Translate Them All: Universal Any-to-Any Translation for Heterogeneous Collaborative Perception
UniTrans pretrains a bank of translator experts and learns combination coefficients from modality mappings in a scene-invariant latent space to enable zero-shot any-to-any feature translation for heterogeneous collabo...
-
GuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
GuidedVLA improves VLA success rates by manually supervising separate attention heads in the action decoder with auxiliary signals for task-relevant factors.
-
CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
CoWorld-VLA extracts semantic, geometric, dynamic, and trajectory expert tokens from multi-source supervision and feeds them into a diffusion-based hierarchical planner, achieving competitive collision avoidance and t...
-
CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
CoWorld-VLA encodes world information into four expert tokens that condition a diffusion-based planner, yielding competitive collision avoidance and trajectory accuracy on the NAVSIM benchmark.
-
VECTOR-Drive: Tightly Coupled Vision-Language and Trajectory Expert Routing for End-to-End Autonomous Driving
VECTOR-DRIVE uses shared self-attention with semantic-aware expert routing of tokens to VL and trajectory experts plus flow-matching action decoding to reach 88.91 driving score on Bench2Drive.
-
SceneSelect: Selective Learning for Trajectory Scene Classification and Expert Scheduling
SceneSelect discovers a latent scene taxonomy through clustering, trains a decoupled classifier to assign inputs, and uses a scheduling policy to dispatch to optimal expert trajectory predictors, reporting 10.5% avera...
-
ST-Prune: Training-Free Spatio-Temporal Token Pruning for Vision-Language Models in Autonomous Driving
ST-Prune is a training-free spatio-temporal token pruning framework for VLMs in autonomous driving that achieves near-lossless results at 90% token reduction by exploiting motion volatility, temporal recency, and mult...
-
LMGenDrive: Bridging Multimodal Understanding and Generative World Modeling for End-to-End Driving
LMGenDrive unifies LLM-based multimodal understanding with generative world models to output both future driving videos and control signals for end-to-end closed-loop autonomous driving.
-
DVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale
DVGT-2 is a streaming vision-geometry-action model that jointly reconstructs dense 3D geometry and plans trajectories online, achieving better reconstruction than prior batch methods while transferring directly to pla...
-
CausalVAD: De-confounding End-to-End Autonomous Driving via Causal Intervention
CausalVAD applies sparse causal intervention to remove spurious correlations from end-to-end autonomous driving models, reporting state-of-the-art planning accuracy and robustness on nuScenes.
-
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
PALM improves long-horizon robotic manipulation success by distilling affordance representations for object interaction and predicting within-subtask progress in a VLA model.
-
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
SpaceDrive integrates 3D positional encodings derived from depth and ego-states into VLMs, replacing digit tokens to improve spatial reasoning and trajectory regression in autonomous driving.
-
Continually Evolving Skill Knowledge in Vision Language Action Model
Stellar VLA achieves continual learning in VLA models by maintaining a growing knowledge space and routing tasks to specialized experts conditioned on semantic relations, delivering strong LIBERO benchmark results wit...
-
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
DriveVLA-W0 adds world modeling to predict future images in VLA models, overcoming sparse action supervision and amplifying data scaling laws on NAVSIM benchmarks and a large in-house dataset.
-
ReSim: Reliable World Simulation for Autonomous Driving
ReSim is a controllable video world model trained on heterogeneous real and simulated driving data that achieves higher fidelity and controllability for both expert and non-expert actions, plus a Video2Reward module f...
-
LVDrive: Latent Visual Representation Enhanced Vision-Language-Action Autonomous Driving Model
LVDrive improves closed-loop driving on Bench2Drive by adding latent future scene prediction to VLA models via unified embedding space processing and two-stage trajectory decoding.
-
EponaV2: Driving World Model with Comprehensive Future Reasoning
EponaV2 advances perception-free driving world models by forecasting comprehensive future 3D geometry and semantic representations, achieving SOTA planning performance on NAVSIM benchmarks.
-
SceneSelect: Selective Learning for Trajectory Scene Classification and Expert Scheduling
SceneSelect discovers latent scene categories via clustering, trains a classifier to assign inputs, and dispatches to expert trajectory predictors, reporting 10.5% average gains over single-model and ensemble baseline...
Reference graph
Works this paper leans on
-
[1]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.TPAMI, 2023
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.TPAMI, 2023
work page 2023
-
[2]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InCVPR, pages 17853–17862, 2023
work page 2023
-
[3]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. ICCV, 2023
work page 2023
-
[4]
Policy pre-training for autonomous driving via self-supervised geometric modeling, 2023
Penghao Wu, Li Chen, Hongyang Li, Xiaosong Jia, Junchi Yan, and Yu Qiao. Policy pre-training for autonomous driving via self-supervised geometric modeling, 2023
work page 2023
-
[5]
Yutao Zhu, Xiaosong Jia, Xinyu Yang, and Junchi Yan. Flatfusion: Delving into details of sparse transformer-based camera-lidar fusion for autonomous driving.arXiv preprint arXiv:2408.06832, 2024
-
[6]
Hongyang Li, Chonghao Sima, Jifeng Dai, Wenhai Wang, Lewei Lu, Huijie Wang, Jia Zeng, Zhiqi Li, Jiazhi Yang, Hanming Deng, et al. Delving into the devils of bird’s-eye-view perception: A review, evaluation and recipe.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2151–2170, 2023
work page 2023
-
[7]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. InNeurIPS, 2022
work page 2022
-
[8]
Hidden biases of end-to-end driving models
Bernhard Jaeger, Kashyap Chitta, and Andreas Geiger. Hidden biases of end-to-end driving models. In Proc. of the IEEE International Conf. on Computer Vision (ICCV), 2023
work page 2023
-
[9]
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving.arXiv preprint arXiv:2503.03125, 2025
-
[10]
Tao Wang, Cong Zhang, Xingguang Qu, Kun Li, Weiwei Liu, and Chang Huang. Diffad: A unified diffusion modeling approach for autonomous driving.arXiv preprint arXiv:2503.12170, 2025
-
[11]
Xiaosong Jia, Shaoshuai Shi, Zijun Chen, Li Jiang, Wenlong Liao, Tao He, and Junchi Yan. Amp: Autoregressive motion prediction revisited with next token prediction for autonomous driving.arXiv preprint arXiv:2403.13331, 2024
-
[12]
Junqi You, Xiaosong Jia, Zhiyuan Zhang, Yutao Zhu, and Junchi Yan. Bench2drive-r: Turning real world data into reactive closed-loop autonomous driving benchmark by generative model.arXiv preprint arXiv:2412.09647, 2024
-
[13]
Waslander, Yu Liu, and Hongsheng Li
Hao Shao, Yuxuan Hu, Letian Wang, Steven L. Waslander, Yu Liu, and Hongsheng Li. Lmdrive: Closed- loop end-to-end driving with large language models, 2023
work page 2023
-
[14]
Drivelm: Driving with graph visual ques- tion answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering.arXiv preprint arXiv:2312.14150, 2023
-
[15]
Asynchronous large language model enhanced planner for autonomous driving, 2024
Yuan Chen, Zi han Ding, Ziqin Wang, Yan Wang, Lijun Zhang, and Si Liu. Asynchronous large language model enhanced planner for autonomous driving, 2024
work page 2024
-
[17]
Genad: Generative end-to-end autonomous driving.arXiv preprint arXiv: 2402.11502, 2024
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end autonomous driving.arXiv preprint arXiv: 2402.11502, 2024
-
[18]
Xiaosong Jia, Liting Sun, Masayoshi Tomizuka, and Wei Zhan. Ide-net: Interactive driving event and pattern extraction from human data.IEEE robotics and automation letters, 6(2):3065–3072, 2021
work page 2021
-
[19]
Activead: Planning- oriented active learning for end-to-end autonomous driving, 2024
Han Lu, Xiaosong Jia, Yichen Xie, Wenlong Liao, Xiaokang Yang, and Junchi Yan. Activead: Planning- oriented active learning for end-to-end autonomous driving, 2024
work page 2024
-
[20]
Wenhai Wang, Jiangwei Xie, ChuanYang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, et al. Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving.arXiv preprint arXiv:2312.09245, 2023. 11
-
[21]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[22]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi_0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Llm4drive: A survey of large language models for autonomous driving.ArXiv, abs/2311.01043, 2023
Zhenjie Yang, Xiaosong Jia, Hongyang Li, and Junchi Yan. Llm4drive: A survey of large language models for autonomous driving.ArXiv, abs/2311.01043, 2023
-
[25]
Carllava: Vision language models for camera-only closed-loop driving, 2024
Katrin Renz, Long Chen, Ana-Maria Marcu, Jan Hünermann, Benoit Hanotte, Alice Karnsund, Jamie Shotton, Elahe Arani, and Oleg Sinavski. Carllava: Vision language models for camera-only closed-loop driving, 2024
work page 2024
-
[26]
Gpt4point: A unified framework for point-language understanding and generation
Zhangyang Qi, Ye Fang, Zeyi Sun, Xiaoyang Wu, Tong Wu, Jiaqi Wang, Dahua Lin, and Hengshuang Zhao. Gpt4point: A unified framework for point-language understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26417–26427, 2024
work page 2024
-
[27]
Multi-agent trajectory prediction by combining egocentric and allocentric views
Xiaosong Jia, Liting Sun, Hang Zhao, Masayoshi Tomizuka, and Wei Zhan. Multi-agent trajectory prediction by combining egocentric and allocentric views. InConference on Robot Learning, pages 1434–1443. PMLR, 2022
work page 2022
-
[28]
Towards capturing the temporal dynamics for trajectory prediction: a coarse-to-fine approach
Xiaosong Jia, Li Chen, Penghao Wu, Jia Zeng, Junchi Yan, Hongyang Li, and Yu Qiao. Towards capturing the temporal dynamics for trajectory prediction: a coarse-to-fine approach. InCoRL, pages 910–920. PMLR, 2023
work page 2023
-
[29]
Xiaosong Jia, Penghao Wu, Li Chen, Yu Liu, Hongyang Li, and Junchi Yan. Hdgt: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding.IEEE transactions on pattern analysis and machine intelligence, 45(11):13860–13875, 2023
work page 2023
-
[30]
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[31]
Efficient large language models: A survey.arXiv preprint arXiv:2312.03863, 1, 2023
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, et al. Efficient large language models: A survey.arXiv preprint arXiv:2312.03863, 1, 2023
-
[32]
Llama-moe: Building mixture-of-experts from llama with continual pre-training
Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, and Yu Cheng. Llama-moe: Building mixture-of-experts from llama with continual pre-training. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15913–15923, 2024
work page 2024
-
[33]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner...
work page 2024
-
[35]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Trajectory-llm: A language-based data generator for trajectory prediction in autonomous driving
Kairui Yang, Zihao Guo, Gengjie Lin, Haotian Dong, Zhao Huang, Yipeng Wu, Die Zuo, Jibin Peng, Ziyuan Zhong, Xin Wang, et al. Trajectory-llm: A language-based data generator for trajectory prediction in autonomous driving. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[37]
Cunxin Fan, Xiaosong Jia, Yihang Sun, Yixiao Wang, Jianglan Wei, Ziyang Gong, Xiangyu Zhao, Masayoshi Tomizuka, Xue Yang, Junchi Yan, et al. Interleave-vla: Enhancing robot manipulation with interleaved image-text instructions.arXiv preprint arXiv:2505.02152, 2025
-
[38]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024
work page 2024
-
[39]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[41]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.arXiv preprint arXiv:2401.06066, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Suning Huang, Zheyu Zhang, Tianhai Liang, Yihan Xu, Zhehao Kou, Chenhao Lu, Guowei Xu, Zhengrong Xue, and Huazhe Xu. Mentor: Mixture-of-experts network with task-oriented perturbation for visual reinforcement learning.arXiv preprint arXiv:2410.14972, 2024
-
[43]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [45]
-
[46]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 13
work page 2017
-
[47]
Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving. InNeurIPS 2024 Datasets and Benchmarks Track, 2024
work page 2024
-
[48]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Jiang-Tian Zhai, Ze Feng, Jinhao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes. arXiv preprint arXiv:2305.10430, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Think twice before driving: Towards scalable decoders for end-to-end autonomous driving
Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. InCVPR, 2023
work page 2023
-
[50]
Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving. InICCV, 2023
work page 2023
-
[51]
Drivetransformer: Unified transformer for scalable end-to-end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to-end autonomous driving. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[52]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025. 14 A Annotation for Router Vision Router:We developed a set of heuristic rules based on annotation information from the Bench2Drive dataset to identify special driving sce...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.