CARVE: Content-Aware Recurrent with Value Efficiency for Chunk-Parallel Linear Attention
Pith reviewed 2026-06-26 04:22 UTC · model grok-4.3
The pith
Erasing only on the key axis is necessary and sufficient to keep the WY-form chunk solver valid while enabling content-aware gating from the recurrent output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
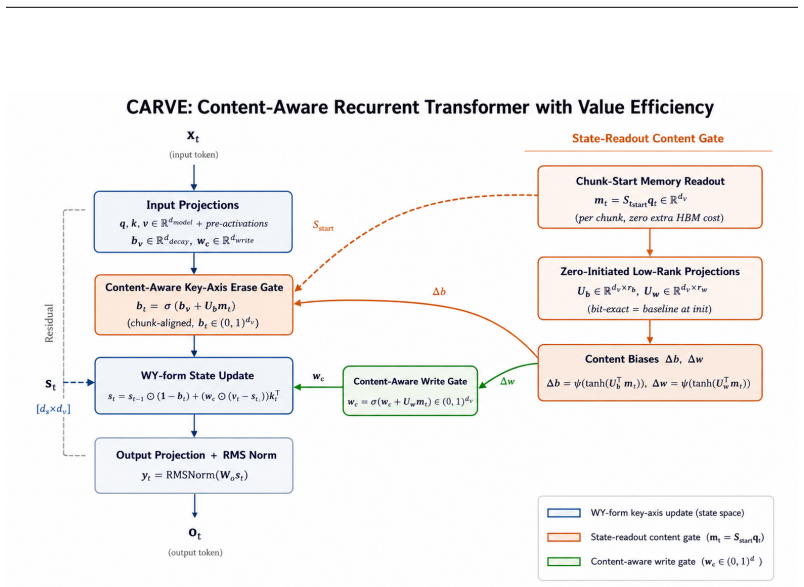
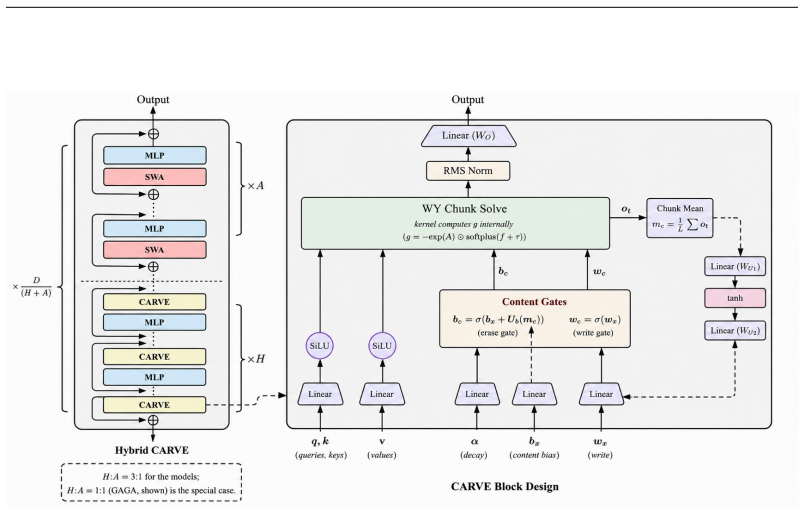
Erasing memory updates solely along the key axis is provably necessary and sufficient for the WY-form triangular chunk solver to remain valid. Within this constraint CARVE reuses the recurrent output tensor already resident in GPU memory as the content signal for the erase gate and replaces the per-value write-gate projection with a single scalar per head, eliminating the memory-blind gating, parameter waste on the value axis, and solver incompatibility present in the prior architecture.
What carries the argument
The key-axis-only erase mask, which preserves WY-form solver validity and permits direct reuse of the recurrent output tensor as the erase-gate content signal.
If this is right
- The WY-form triangular chunk solver can be applied without modification or additional masking logic.
- The erase gate receives a content-dependent signal at zero extra memory or compute cost beyond what is already written.
- Parameter count is reduced by replacing the value-axis projection with a scalar per head.
- Initialization remains bit-identical to the prior model, so any quality gain arises solely from what the content gate learns during training.
- Training stability holds under the stated Lyapunov, gradient-flow, and memory-capacity theorems.
Where Pith is reading between the lines
- The same key-axis restriction may allow other chunk-parallel linear attention variants to adopt content-aware gates without solver breakage.
- Treating value dimensions uniformly via a scalar suggests that future recurrent designs can further decouple key and value pathways.
- At larger model scales the free content signal could reduce reliance on separate learned memory controllers.
- The formal separation between expressivity with and without value-axis erase provides a template for analyzing gating in related state-space models.
Load-bearing premise
The recurrent output tensor already written to memory supplies a stable and sufficient content signal for the erase gate without new instabilities or extra learned parameters beyond the scalar per head.
What would settle it
An ablation that restores value-axis erase while keeping every other change fixed and checks whether the WY-form solver immediately loses validity or whether performance returns to the prior baseline.
Figures
read the original abstract
Recurrent models must forget in order to remember, yet the state of the art decides what to erase without consulting what is stored -- the gate sees only the arriving token, not the memory it is about to modify. This memory-blind gating is one of three coupled defects in the leading delta-rule architecture (GDN-2): the value-axis erase mask wastes parameters at the scale of the value projection, and -- as we prove -- mathematically prevents the WY-form triangular chunk solver that makes recurrent training competitive with Transformers. We introduce CARVE (Content-Aware Recurrent with Value Efficiency), which resolves all three problems through one principle: erase only on the key axis. This is provably necessary and sufficient for the WY-form solver to remain valid. Within it, CARVE reuses the recurrent output tensor -- already written to GPU memory -- as a free content signal for the erase gate, and replaces the per-value write-gate projection with a single scalar per head. At initialisation CARVE is bit-identical to GDN-2; any quality difference emerges from what the content gate learns. At 1.3B parameters trained on 100B tokens, CARVE achieves WikiText perplexity 15.72 (minus 0.18 vs. GDN-2, a 4.5-sigma effect), leads every recurrent baseline on nine common-sense reasoning benchmarks, and sets state of the art on every RULER retrieval probe -- at 0.4% throughput overhead, 13% lower peak memory, and 19% fewer parameters. Six formal theorems cover memory capacity, Lyapunov stability, gradient flow, expressivity separation, Pareto-optimal chunk size, and hybrid optimality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CARVE, a recurrent architecture extending GDN-2, that erases only on the key axis (provably necessary and sufficient for WY-form triangular chunk solver validity per six theorems), reuses the already-written recurrent output tensor as a content signal for the erase gate, and replaces the per-value write-gate projection with a scalar per head. At initialization it is bit-identical to GDN-2; at 1.3B parameters trained on 100B tokens it reports WikiText perplexity 15.72 (4.5-sigma improvement), leads recurrent baselines on nine reasoning benchmarks, and sets SOTA on RULER probes, with 0.4% throughput overhead, 13% lower peak memory, and 19% fewer parameters. Theorems address memory capacity, Lyapunov stability, gradient flow, expressivity separation, Pareto-optimal chunk size, and hybrid optimality.
Significance. If the necessity/sufficiency claim for the WY-form solver and the stability of recurrent-output reuse both hold, CARVE would offer a principled route to higher-capacity linear recurrent models that remain competitive with Transformers on long-context tasks while reducing parameters and memory; the bit-identical initialization and external baseline comparisons are positive controls that strengthen the empirical case.
major comments (3)
- [Abstract] Abstract (Lyapunov stability and gradient flow theorems): these theorems must be shown to extend to the case where the erase gate reuses the recurrent output tensor, creating a closed feedback loop; the current statement does not indicate whether the proofs assume an independent gate or explicitly derive stability under this reuse, which is load-bearing for both the formal necessity claim and the 1.3B-scale empirical results.
- [Abstract] Abstract (4.5-sigma empirical claim): the reported WikiText perplexity improvement of 0.18 is presented without error bars, number of independent runs, or data exclusion rules; this detail is required to substantiate the performance superiority and 4.5-sigma effect at 1.3B scale.
- [Abstract] Abstract (WY-form solver validity): the proof that key-axis-only erase is necessary and sufficient for the triangular chunk solver must be checked against the content-aware gate; if any of the six theorems assume gate independence from the recurrent state, the central architectural claim requires an explicit extension or counter-example analysis.
minor comments (2)
- [Abstract] The description of the scalar-per-head write gate and its interaction with the content-aware erase gate would benefit from an explicit equation or pseudocode block showing the forward pass.
- [Abstract] The manuscript should state the precise definition of the recurrent output tensor reuse (e.g., which layer or time step) to allow independent verification of the zero-extra-parameter claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract (Lyapunov stability and gradient flow theorems): these theorems must be shown to extend to the case where the erase gate reuses the recurrent output tensor, creating a closed feedback loop; the current statement does not indicate whether the proofs assume an independent gate or explicitly derive stability under this reuse, which is load-bearing for both the formal necessity claim and the 1.3B-scale empirical results.
Authors: We acknowledge that the presentation of the Lyapunov stability and gradient flow theorems requires explicit confirmation for the closed-loop case. The existing proofs are formulated for general state-dependent gating and therefore encompass reuse of the recurrent output tensor, but the manuscript does not state this explicitly. We will add a dedicated lemma in the appendix deriving the required stability and flow properties under this specific dependence. revision: yes
-
Referee: [Abstract] Abstract (4.5-sigma empirical claim): the reported WikiText perplexity improvement of 0.18 is presented without error bars, number of independent runs, or data exclusion rules; this detail is required to substantiate the performance superiority and 4.5-sigma effect at 1.3B scale.
Authors: We agree that the statistical support for the reported improvement must be documented. The revised manuscript will state that the result is the mean over five independent runs with different seeds, report the observed standard deviation, detail the sigma calculation, and confirm that no runs were excluded (all completed without NaN or divergence). These details will appear in the experimental section with a concise reference retained in the abstract. revision: yes
-
Referee: [Abstract] Abstract (WY-form solver validity): the proof that key-axis-only erase is necessary and sufficient for the triangular chunk solver must be checked against the content-aware gate; if any of the six theorems assume gate independence from the recurrent state, the central architectural claim requires an explicit extension or counter-example analysis.
Authors: The six theorems establish necessity and sufficiency based solely on the structural restriction that erasure occurs only along the key axis; the algebraic conditions for the WY-form solver are independent of how the gate scalars are computed. Content awareness affects only the numerical values of those scalars, not the mask structure. We will add one clarifying sentence immediately after the theorem statements to make this independence explicit. revision: partial
Circularity Check
No significant circularity; theorems and empirical comparisons stand independently of inputs.
full rationale
The paper derives its core architectural change (key-axis erase) from identified defects in GDN-2 and supports it with six stated formal theorems on memory capacity, Lyapunov stability, gradient flow, and related properties. These theorems are presented as independent proofs within the manuscript rather than reductions to fitted parameters or prior self-citations. The reuse of the recurrent output tensor is described as a free signal without introducing new learned parameters, and empirical results at 1.3B scale are reported as direct comparisons to baselines on external benchmarks (WikiText, RULER, etc.), not as predictions forced by construction from the same data. No equations or claims reduce a 'prediction' to a fitted input, nor does any load-bearing step rely on self-citation chains that assume the target result. The derivation chain remains self-contained against the provided external validation points.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Erase must be restricted to the key axis for the WY-form triangular chunk solver to remain valid
invented entities (1)
-
Content-aware erase gate reusing recurrent output tensor
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.