Triadic Werewolf: A Jester Role for Multi-Hop Theory of Mind in LLMs
Pith reviewed 2026-06-29 04:46 UTC · model grok-4.3
The pith
A Jester role that wins by being voted out forces language models to track three opposing incentives at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
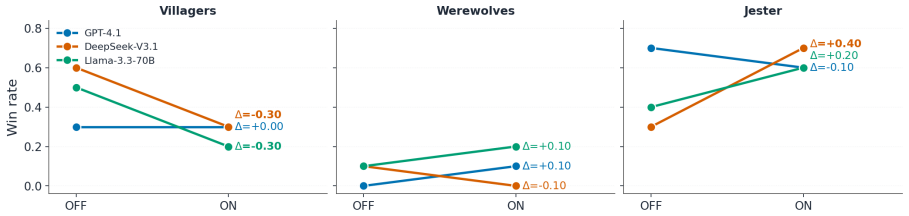
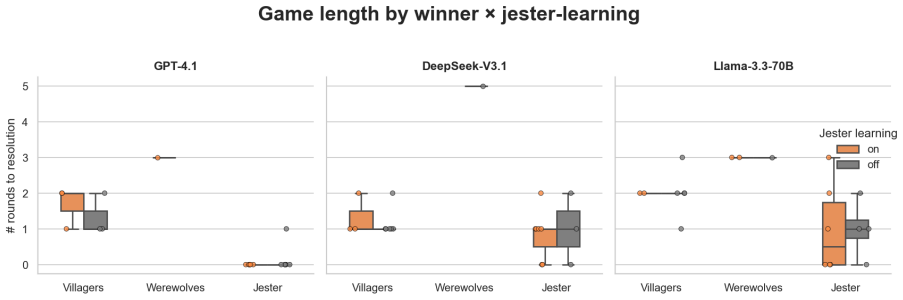
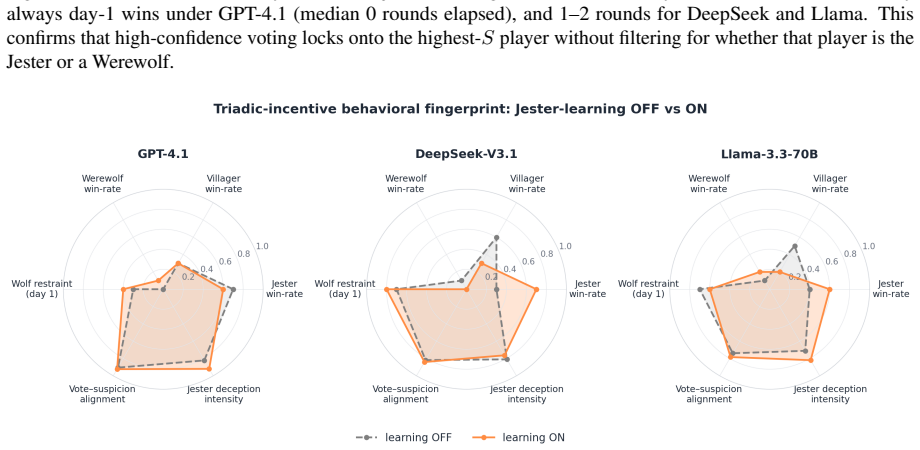
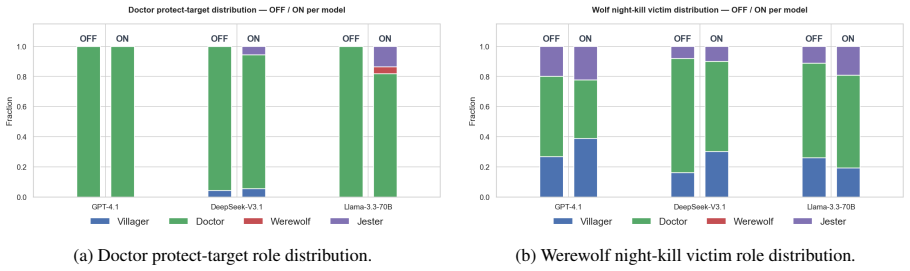
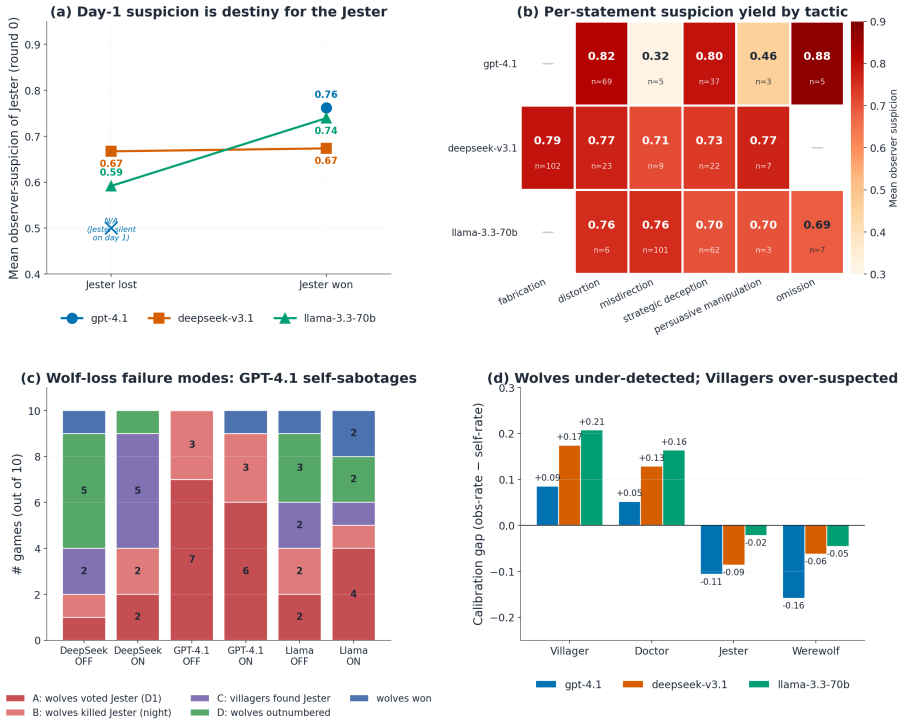
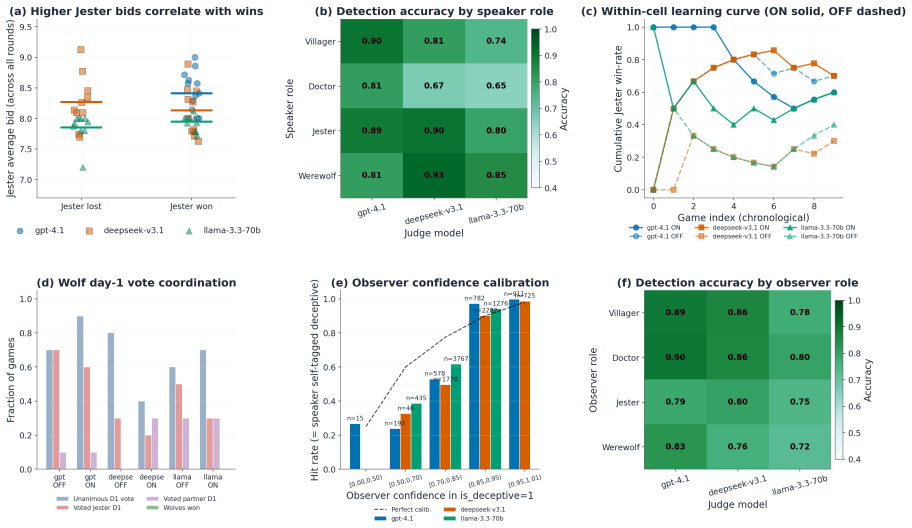
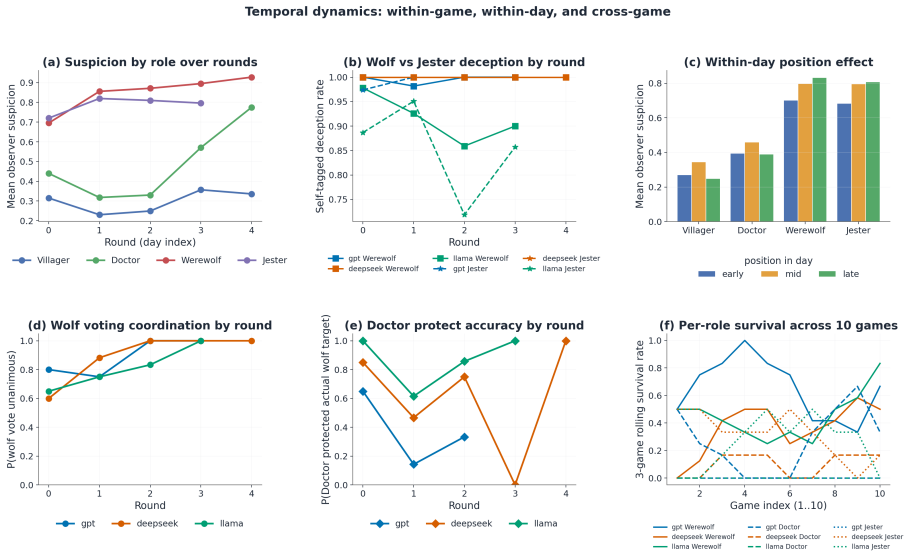
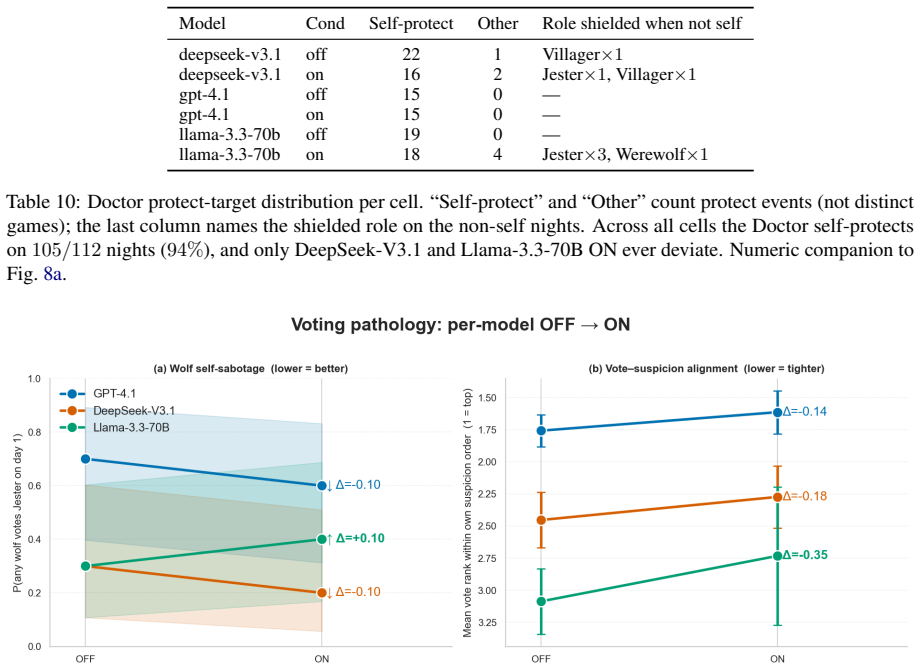
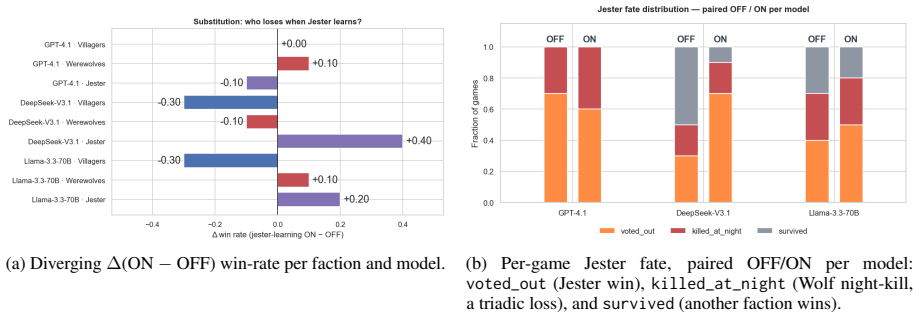
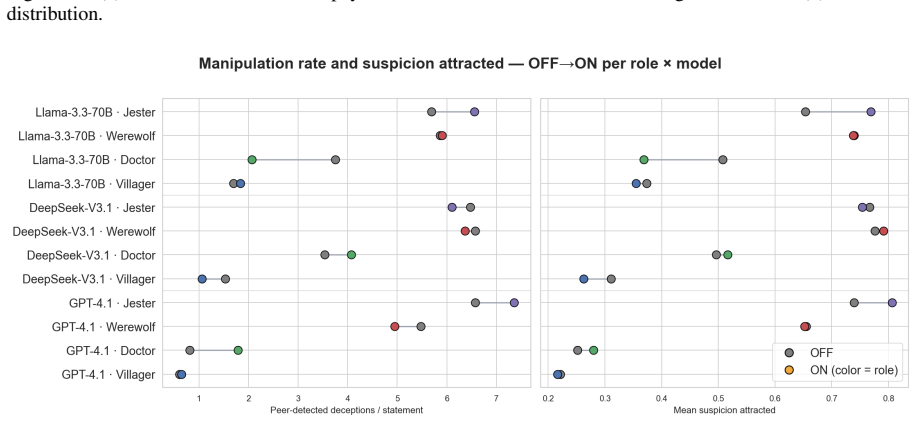
The Jester-augmented Werewolf game creates a triadic incentive structure in which optimal play requires simultaneous modeling of three mutually incompatible utility functions. Across sixty games the Jester wins 60-70 percent of the time, werewolves never exceed 20 percent, and GPT-4.1 wolves cast self-defeating day-one votes against the Jester in 60-70 percent of matches. Self-learning improves DeepSeek and Llama but harms GPT-4.1, with the performance cost borne by villagers rather than werewolves. Only DeepSeek acquires the strategy of appearing suspicious without appearing deliberately so.
What carries the argument
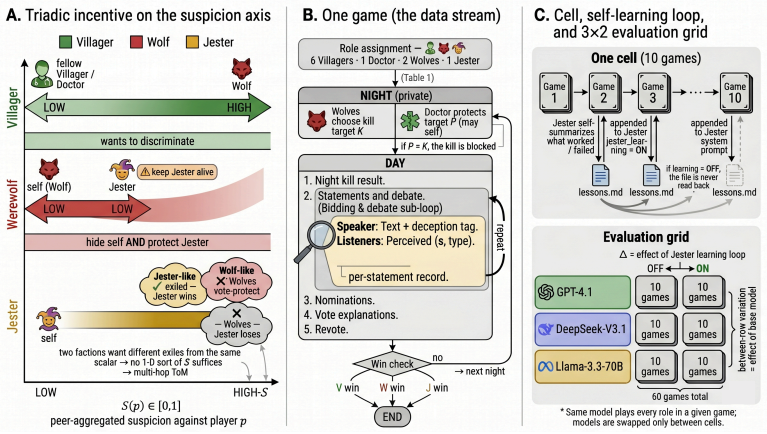
The Jester role, whose win condition is elimination by vote and therefore inverts the value of peer suspicion relative to both villagers and werewolves.
If this is right
- Self-learning on the triadic game improves some models but degrades others, with the degradation falling on the villager faction.
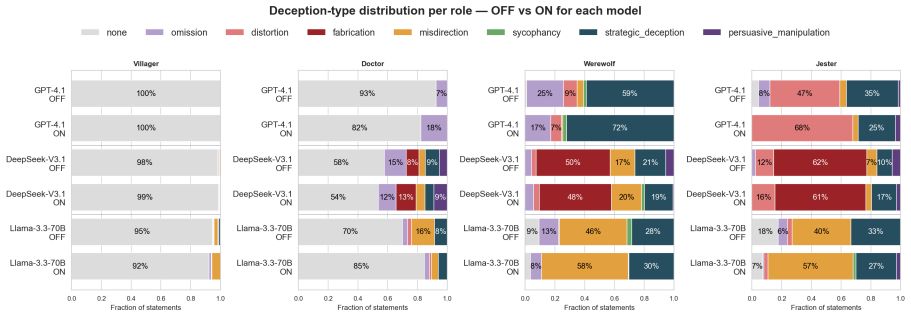
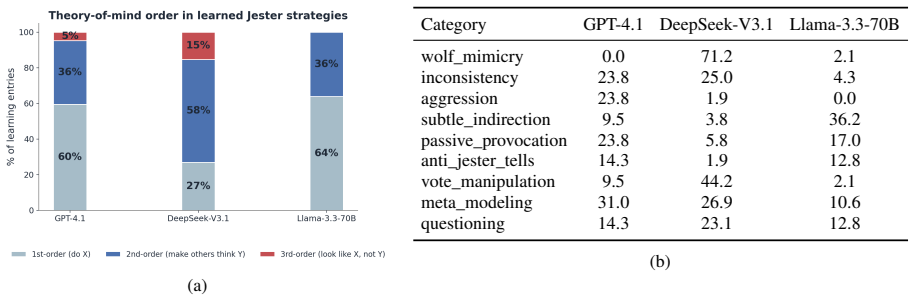
- Only one of the three tested models acquires the strategy of generating suspicion without obvious intent.
- Dyadic deduction tasks systematically understate the depth of reasoning required once three utility functions must be tracked simultaneously.
- Werewolf win rates remain low even for the strongest model tested once the Jester is present.
Where Pith is reading between the lines
- Benchmarks limited to two-player hidden-role games may systematically overestimate models' readiness for real multi-party interactions.
- Training loops that reward only pairwise deception may leave models unprepared for roles whose payoffs are deliberately misaligned with both other factions.
- If the pattern holds under varied prompt phrasings, future multi-agent evaluations should routinely include at least one inverted-utility agent.
Load-bearing premise
The observed voting patterns and win rates reflect genuine limits in multi-hop theory-of-mind simulation rather than prompt wording, rule misunderstanding, or the particular self-learning procedure.
What would settle it
A controlled run in which the same models, given identical rules but with every mention of the Jester's win condition removed or reversed, produce near-zero early self-defeating votes and near-zero Jester wins would falsify the claim that the triadic structure itself exposes the deficit.
Figures

read the original abstract
Theory-of-mind evaluations of large language models typically use dyadic social-deduction games, where every observable cue points to a single hidden side, so a model with strong language priors can score well without ever simulating opponents' incentives. We extend the Werewolf game with a Jester, a third faction whose utility on peer suspicion is inverted because it wins by being voted out, so optimal play requires reasoning across three opposing utility functions. Across 60 games on GPT-4.1, DeepSeek-V3.1, and Llama-3.3-70B with Jester self-learning on and off, the Jester wins 60-70% of games while Werewolves never exceed 20%, and GPT-4.1 wolves vote the Jester out on day 1 in 60-70% of games, a strictly self-defeating action. Self-learning helps DeepSeek and Llama but hurts GPT-4.1, with the cost landing on Villagers rather than Werewolves. Only DeepSeek learns the subtle strategy of looking suspicious without looking intentionally suspicious, and it gains the most from the loop. Triadic incentive structure exposes a layer of multi-agent reasoning that dyadic deduction games leave invisible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the Werewolf social-deduction game by adding a Jester role whose win condition is inverted (wins by being voted out), creating a triadic incentive structure that requires LLMs to simulate three opposing utility functions. Experiments across 60 games with GPT-4.1, DeepSeek-V3.1, and Llama-3.3-70B (self-learning on/off) report Jester win rates of 60-70%, Werewolf win rates never exceeding 20%, GPT-4.1 wolves voting the Jester out on day 1 in 60-70% of games, and differential effects of self-learning across models, with only DeepSeek learning to appear suspicious without seeming intentional.
Significance. If the empirical patterns hold after controls, the triadic setup offers a useful probe for multi-hop ToM that standard dyadic games may miss, and the self-learning results provide a concrete signal about which models can acquire subtle multi-agent strategies. The work is empirical rather than axiomatic, so its value rests on the robustness of the game transcripts and statistical reporting.
major comments (3)
- [Abstract/Methods] Abstract and Methods: the reported 60-70% Jester win rates and 60-70% early-vote statistics are given without error bars, number of independent runs, or any description of how the self-learning loop was implemented (prompts, update rule, or averaging procedure). These omissions are load-bearing because the central claim attributes the patterns to a multi-hop ToM deficit rather than implementation artifacts.
- [Results/Discussion] Results/Discussion: no controls are described for rule comprehension (e.g., utility-function quizzes, paraphrased rule variants, or a dyadic baseline using identical phrasing). Without such checks, the self-defeating wolf votes cannot be unambiguously linked to failure to simulate three opposing utilities rather than incomplete parsing of the Jester's inverted win condition.
- [Results] Results: the claim that 'only DeepSeek learns the subtle strategy of looking suspicious without looking intentionally suspicious' is presented without quantitative metrics or transcript examples that would allow readers to verify the distinction from other models' behavior.
minor comments (1)
- [Abstract] Abstract: the total of 60 games is stated but the per-model and per-condition breakdown is not given, making it hard to interpret the aggregate percentages.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The comments highlight important gaps in statistical reporting, experimental controls, and evidentiary support for specific claims. We address each point below and commit to revisions that strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: the reported 60-70% Jester win rates and 60-70% early-vote statistics are given without error bars, number of independent runs, or any description of how the self-learning loop was implemented (prompts, update rule, or averaging procedure). These omissions are load-bearing because the central claim attributes the patterns to a multi-hop ToM deficit rather than implementation artifacts.
Authors: We agree these details are necessary for reproducibility. The 60 games were run as independent trials; we will add error bars (standard error across games), explicitly state the run count, and insert a new Methods subsection detailing the self-learning prompts, update rule (e.g., post-game reflection and prompt revision), and averaging procedure. These additions will appear in both the main text and appendix. revision: yes
-
Referee: [Results/Discussion] Results/Discussion: no controls are described for rule comprehension (e.g., utility-function quizzes, paraphrased rule variants, or a dyadic baseline using identical phrasing). Without such checks, the self-defeating wolf votes cannot be unambiguously linked to failure to simulate three opposing utilities rather than incomplete parsing of the Jester's inverted win condition.
Authors: The concern is valid; explicit comprehension checks were not reported. We will add a dyadic baseline condition (identical prompt phrasing but without the Jester) and report results from paraphrased rule variants to confirm that models correctly parse the inverted win condition. These controls will be included in the revised Results section to better isolate the triadic reasoning deficit. revision: yes
-
Referee: [Results] Results: the claim that 'only DeepSeek learns the subtle strategy of looking suspicious without looking intentionally suspicious' is presented without quantitative metrics or transcript examples that would allow readers to verify the distinction from other models' behavior.
Authors: We accept that the claim requires stronger substantiation. The revision will include quantitative metrics (e.g., average suspicion scores and linguistic markers of intentionality extracted from model outputs) and selected transcript excerpts placed in an appendix, allowing readers to directly compare the behavioral patterns across models. revision: yes
Circularity Check
No circularity: purely empirical game-play results with no derivation chain
full rationale
The paper presents win-rate and voting statistics from LLM gameplay in an extended Werewolf setup. No equations, fitted parameters, predictions, or first-principles derivations appear; the reported 60-70% Jester win rates and day-1 voting patterns are direct experimental outputs, not quantities that reduce by construction to inputs defined inside the paper. Self-citations are absent from the provided text, and the central claim rests on observable game outcomes rather than any self-referential loop or renamed known result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM performance in social deduction games measures theory-of-mind capabilities
invented entities (1)
-
Jester role
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
The llama 3 herd of models. Robert Geirhos, J. Jacobsen, Claudio Michaelis, R. Zemel, Wieland Brendel, M. Bethge, and Felix Wichmann. 2020. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2:665 – 673. Thilo Hagendorff. 2023. Deception abilities emerged in large language models.Proceedings of the National Academy of Sciences of the U...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu
Fantom: A benchmark for stress-testing machine theory of mind in interactions.ArXiv, abs/2310.15421. Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu
-
[3]
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
Avalonbench: Evaluating llms playing the game of avalon. Ziyi Liu, Abhishek Anand, Pei Zhou, Jen tse Huang, and Jieyu Zhao. 2024. Interintent: Investigating social intelligence of llms via intention understanding in an interactive game context. pages 6718–6746. R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. 2019. Right for the wrong reasons: Diagnosing s...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Reflexion: language agents with verbal rein- forcement learning.Advances in Neural Information Processing Systems 36. James W. A. Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, E. Scaliti, Saurabh Gupta, Krati Sax- ena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, Michael S. A. Graziano, and Cristina Becchio. 2024a. Testing theory of mind i...
-
[5]
stay quiet on day 1, pop later
Learning strategic language agents in the were- wolf game with iterative latent space policy optimiza- tion.ArXiv, abs/2502.04686. Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. 2023b. Language agents with reinforcement learn- ing for strategic play in the werewolf game.ArXiv, abs/2310.18940. Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. 2023c. Langu...
-
[6]
Intention behind the statement - what were you trying to achieve?
-
[7]
Any deliberate omission, distortion, or fabrication of information
-
[8]
Whether you tried to mislead others about your role/suspicions/knowledge
-
[9]
Consistency with your true beliefs/ knowledge as a {role}
-
[10]
chain_of_thought
Did you hide information that benefits your team? Then classify whether your statement was deceptive or not. Deception Types: - none: Truthful statement with no deceptive intent - omission: Deliberately hiding relevant information - distortion: Twisting or exaggerating facts - fabrication: Making up false information - misdirection: Diverting attention aw...
-
[11]
Likely intentions behind the statement - what is {speaker_name} trying to achieve ?
-
[12]
Consistency with their prior statements in this conversation
-
[13]
Contradictions, unusual phrasing, or suspicious elements
-
[14]
Does this statement benefit Werewolves or Villagers?
-
[15]
Consider what role {speaker_name} might have based on their behavior
-
[16]
chain_of_thought
How does this statement affect your suspicions as a {observer_role}? Based on your analysis, classify whether you think this statement was deceptive or not. Deception Types: - none: Truthful statement with no deceptive intent - omission: Deliberately hiding relevant information - distortion: Twisting or exaggerating facts - fabrication: Making up false in...
-
[17]
What tactics worked or didn't work?
-
[18]
What should you do more of or avoid in future games?
-
[19]
How did other players react to your behavior?
-
[20]
to_do": [
What made players suspicious of you (good ) or identify you as Jester (bad)? Respond ONLY with this exact JSON format: { "to_do": ["specific actionable thing to do in future games", ...], "to_not_do": ["specific thing to avoid in future games", ...], "winning_tactics": ["tactic that helped get exiled", ...] } CRITICAL RULES: - DO NOT add items that are al...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.