Cross-view Multimodal Vision-Based Assessment Framework for Traditional Chinese Medicine Rehabilitation Training
Pith reviewed 2026-06-29 04:00 UTC · model grok-4.3
The pith
A cross-view video system with visual-pose fusion improves automated scoring of acupuncture and Tuina skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the CME-AQA framework, which fuses visual and pose information from synchronized first-person and third-person videos, delivers superior or comparable mean performance to competitive baselines on action quality assessment for TCM techniques, including more than 10 percent relative improvement in weighted F1 on Needle Depth and Quick Needle Insertion tasks along with reduced mean absolute error for insertion time and manipulation frequency, while producing comparable results on several posture criteria in a CPR dataset.
What carries the argument
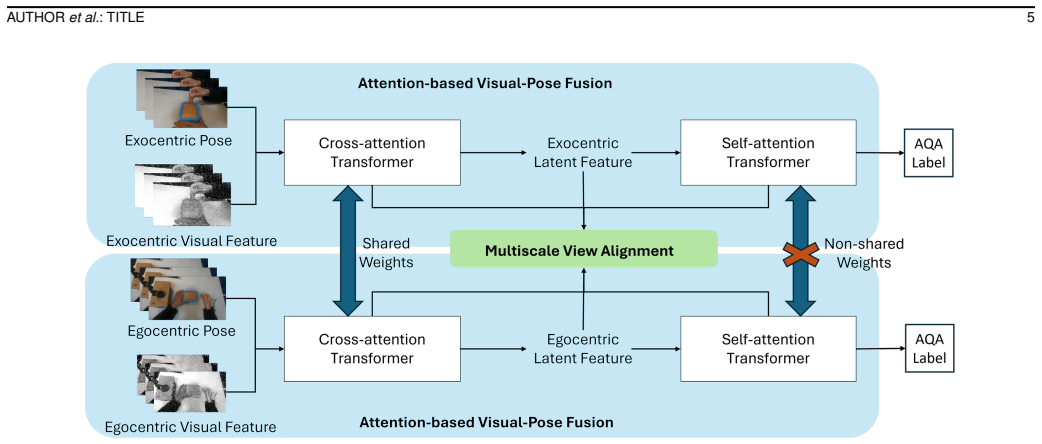
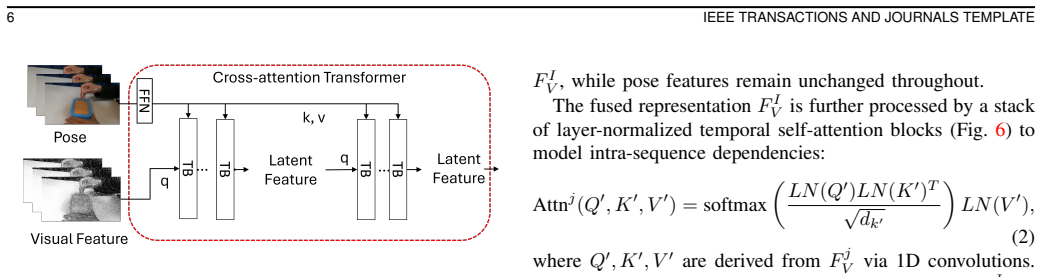
The CME-AQA framework that performs cross-view multimodal fusion of visual and pose data from first-person and third-person videos to handle self-occlusion and hand-object interactions.
If this is right
- Rating accuracy rises for TCM tasks that involve dense hand movements and object interactions.
- Quantitative measures such as insertion time and manipulation frequency are estimated with lower error than single-view baselines.
- The approach transfers to other structured clinical skill assessments centered on participant posture and motion, such as CPR.
- Video-based evaluation reduces reliance on constant in-person expert observation during training.
Where Pith is reading between the lines
- The system could support remote or self-paced feedback loops for TCM students without requiring an instructor to be physically present.
- Real deployment would need checks against broader ranges of patient body types and practitioner experience levels beyond the 61-subject sets.
- Adding non-visual signals like force sensors on needles could strengthen the multimodal component for finer manipulation scoring.
Load-bearing premise
The collected dual-view videos with expert annotations on 61 subjects represent the variability present in actual clinical TCM training sessions.
What would settle it
Performance gains disappear when the same model is tested on videos from a new group of practitioners and patients recorded under different lighting or camera placements not seen in the original TCM-AQA61 collections.
Figures




read the original abstract
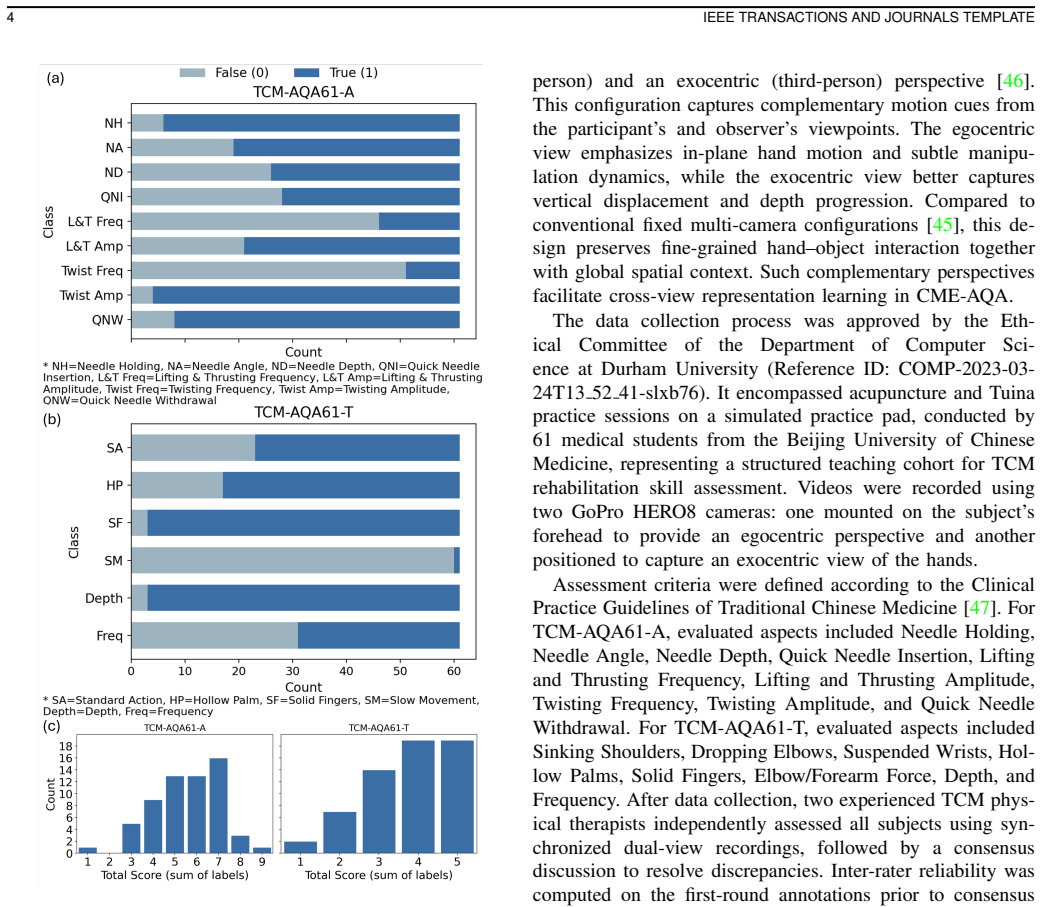
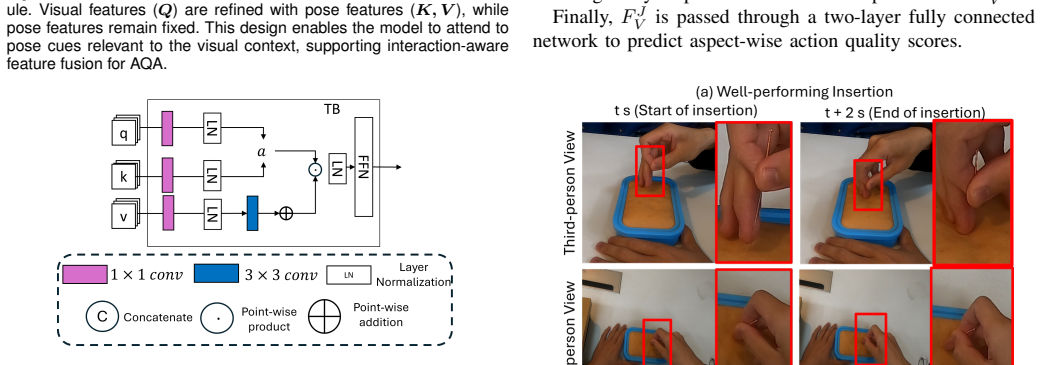
Vision-based assessment can provide convenient and cost-effective evaluation in Traditional Chinese Medicine (TCM) rehabilitation training, where action quality assessment (AQA) from computer vision offers a promising solution. Existing automatic AQA frameworks for physical therapy typically rely on skeletal data captured from a single viewpoint, which is inefficient for TCM techniques such as acupuncture or Tuina that involve dense hand self-occlusion and complex hand-object interactions. To address these challenges, we propose CME-AQA, a cross-view, multimodal vision-based assessment framework that integrates visual-pose fusion to enhance understanding of environmental context and leverages both first-person and third-person videos during training to improve inference robustness. We collected two dual-view datasets, TCM-AQA61-A (Acupuncture) and TCM-AQA61-T (Tuina), each containing synchronized first-person and third-person recordings of 61 subjects with expert annotations. Experimental results show that our approach achieves superior or comparable mean performance against competitive baselines, achieving over 10% relative improvement in weighted F1 over the best competing method on key rating tasks such as Needle Depth and Quick Needle Insertion, while also reducing mean absolute error in quantitative measures such as insertion time and manipulation frequency. Testing on a CPR dataset further demonstrates comparable performance on several posture-based criteria, suggesting applicability to related structured simulated clinical skill assessments where participant motion is central to evaluation. Overall, CME-AQA enhances assessment accuracy for structured TCM rehabilitation training and facilitates more convenient and effective training-oriented skill evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
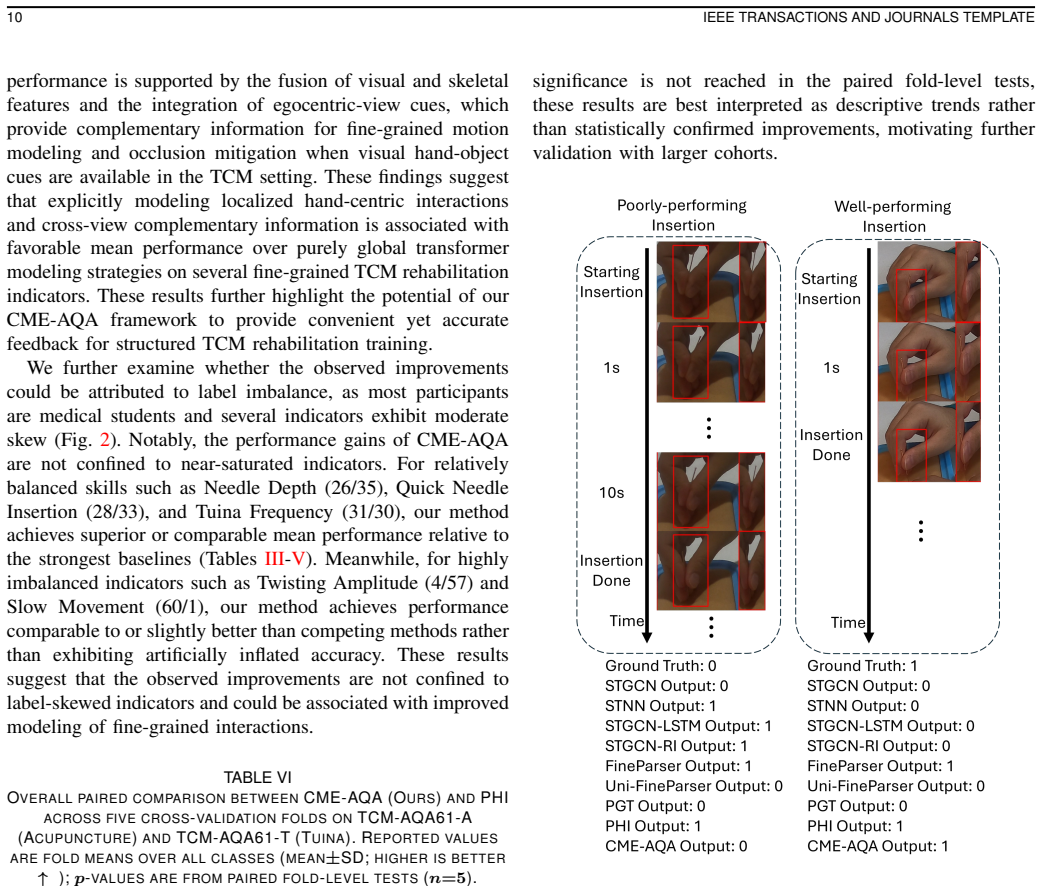
Summary. The manuscript introduces CME-AQA, a cross-view multimodal vision-based framework for action quality assessment (AQA) in Traditional Chinese Medicine rehabilitation training (acupuncture and Tuina). It combines visual-pose fusion with synchronized first-person and third-person videos to handle hand self-occlusion and hand-object interactions, unlike single-view skeletal approaches. The authors collect two new dual-view datasets (TCM-AQA61-A and TCM-AQA61-T) from 61 subjects with expert annotations, report >10% relative weighted-F1 gains on tasks such as Needle Depth and Quick Needle Insertion versus baselines, reduced MAE on quantitative measures like insertion time, and comparable results when tested on a CPR dataset.
Significance. If the performance deltas are shown to arise from the proposed cross-view fusion rather than dataset or input-format advantages, the work would strengthen multi-view video methods for assessing complex, occluded motor skills in clinical training. The new TCM-specific dual-view datasets and the CPR transfer experiment provide concrete resources and evidence of broader applicability. These elements would be notable strengths for a computer-vision journal if the experimental controls are tightened.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of >10% relative weighted-F1 improvement on Needle Depth and Quick Needle Insertion rests on comparisons whose fairness cannot be verified from the given information; no description is supplied of how single-view baselines were adapted (or not) to consume the same synchronized first-/third-person pairs that CME-AQA receives at training and test time.
- [§3] §3 (Dataset): the weakest assumption—that expert annotations on TCM-AQA61 constitute unbiased, reproducible ground truth that generalizes to clinical variability—is unsupported; the manuscript supplies no inter-rater reliability statistics, annotation protocol, or analysis of subject or action diversity.
minor comments (2)
- [Abstract] The abstract states that the method 'leverages both first-person and third-person videos during training to improve inference robustness,' yet the precise training/inference split and whether third-person views are available at test time are not stated.
- Notation for the visual-pose fusion weights and backbone hyperparameters is introduced without an accompanying equation or table reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of >10% relative weighted-F1 improvement on Needle Depth and Quick Needle Insertion rests on comparisons whose fairness cannot be verified from the given information; no description is supplied of how single-view baselines were adapted (or not) to consume the same synchronized first-/third-person pairs that CME-AQA receives at training and test time.
Authors: We agree that the input configurations require explicit clarification to isolate the contribution of cross-view fusion. The single-view baselines were evaluated on the third-person view alone, consistent with their original design, while CME-AQA receives synchronized dual-view pairs. In revision we will expand §4 with a precise description of each method's inputs and add an ablation comparing our model under single-view versus dual-view conditions to demonstrate that gains arise from the proposed fusion rather than input format. revision: yes
-
Referee: [§3] §3 (Dataset): the weakest assumption—that expert annotations on TCM-AQA61 constitute unbiased, reproducible ground truth that generalizes to clinical variability—is unsupported; the manuscript supplies no inter-rater reliability statistics, annotation protocol, or analysis of subject or action diversity.
Authors: We acknowledge the need for greater transparency on annotation quality. The revised §3 will include the annotation protocol (conducted by certified TCM experts using standardized rubrics) and a summary table of subject demographics and action distributions. Inter-rater reliability statistics were not collected during dataset creation; we will explicitly state this limitation and its implications for generalizability. revision: partial
Circularity Check
No significant circularity; empirical evaluation on held-out expert-annotated data is independent of model construction.
full rationale
The paper proposes CME-AQA, a cross-view multimodal framework, and reports empirical performance gains on newly collected TCM-AQA61 datasets with expert annotations. No equations or claims reduce a prediction to a fitted input by construction, no self-citation chain bears the central result, and no uniqueness theorem or ansatz is smuggled in. The performance numbers are measured on separate test splits against adapted baselines; the derivation chain (feature fusion and training procedure) remains self-contained and externally falsifiable via the reported metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- visual-pose fusion weights
- backbone hyperparameters
axioms (1)
- domain assumption Expert annotations constitute reliable ground truth for action quality
Reference graph
Works this paper leans on
-
[1]
W.-W. Tao, H. Jiang, X.-M. Tao, P. Jiang, L.-Y . Sha, and X.-C. Sun, “Effects of acupuncture, tuina, tai chi, qigong, and traditional chinese medicine five-element music therapy on symptom management and quality of life for cancer patients: a meta-analysis,”Journal of pain and symptom management, vol. 51, no. 4, pp. 728–747, 2016. 1
2016
-
[2]
Effect of acupuncture treatment on cortical activation in patients with tinnitus: a functional near-infrared spectroscopy study,
X. Yu, B. Gong, H. Yang, Z. Wang, G. Qi, J. Sun, Y . Fang, and X. Fan, “Effect of acupuncture treatment on cortical activation in patients with tinnitus: a functional near-infrared spectroscopy study,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 729–737, 2023. 1
2023
-
[3]
Evidence-based practice of chinese medicine in physical rehabilitation science,
A. de S ´a Ferreira, “Evidence-based practice of chinese medicine in physical rehabilitation science,”Chinese journal of integrative medicine, vol. 19, no. 10, pp. 723–729, 2013. 1
2013
-
[4]
A mobile natural human–robot interaction method for virtual chinese acupuncture,
G. Du, Y . Li, K. Su, C. Li, and P. X. Liu, “A mobile natural human–robot interaction method for virtual chinese acupuncture,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–10, 2022. 1, 3, 5
2022
-
[5]
Design and development of a mixed reality acupuncture training system,
Q. Sun, J. Huang, H. Zhang, P. Craig, L. Yu, and E. G. Lim, “Design and development of a mixed reality acupuncture training system,” in2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR). IEEE, 2023, pp. 265–275. 1
2023
-
[6]
Ai-driven stroke rehabilitation systems and assessment: a systematic review,
S. Rahman, S. Sarker, A. N. Haque, M. M. Uttsha, M. F. Islam, and S. Deb, “Ai-driven stroke rehabilitation systems and assessment: a systematic review,”IEEE Transactions on Neural Systems and Reha- bilitation Engineering, vol. 31, pp. 192–207, 2022. 2
2022
-
[7]
Vision-based human action quality assessment: A systematic review,
J. Liu, H. Wang, K. Stawarz, S. Li, Y . Fu, and H. Liu, “Vision-based human action quality assessment: A systematic review,”Expert Systems with Applications, p. 125642, 2024. 2
2024
-
[8]
A survey on video action recognition in sports: Datasets, methods and applications,
F. Wu, Q. Wang, J. Bian, N. Ding, F. Lu, J. Cheng, D. Dou, and H. Xiong, “A survey on video action recognition in sports: Datasets, methods and applications,”IEEE Transactions on Multimedia, 2022. 2
2022
-
[9]
Standards for reporting interventions in clinical trials of tuina/massage (strictotm): Extending the consort statement,
X. Zhang, F. Liang, C. T. Lau, J. C. Chan, N. Wang, J. Deng, J. Wang, Y . Ma, L. L. Zhong, C. Zhaoet al., “Standards for reporting interventions in clinical trials of tuina/massage (strictotm): Extending the consort statement,”Journal of Evidence-Based Medicine, vol. 16, no. 1, pp. 68–81, 2023. 2
2023
-
[10]
A deep learning framework for assessing physical rehabilitation exercises,
Y . Liao, A. Vakanski, and M. Xian, “A deep learning framework for assessing physical rehabilitation exercises,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 28, no. 2, pp. 468– 477, 2020. 2, 3, 5, 6, 7, 8, 9
2020
-
[11]
Graph convolutional networks for assessment of physical rehabilitation exercises,
S. Deb, M. F. Islam, S. Rahman, and S. Rahman, “Graph convolutional networks for assessment of physical rehabilitation exercises,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 30, pp. 410–419, 2022. 2, 8, 9 14 IEEE TRANSACTIONS AND JOURNALS TEMPLATE
2022
-
[12]
A skeleton-based rehabilitation exercise assessment system with rotation invariance,
K. Zheng, J. Wu, J. Zhang, and C. Guo, “A skeleton-based rehabilitation exercise assessment system with rotation invariance,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023. 2, 3, 5, 6, 8, 9
2023
-
[13]
Dynamic multiview refinement of 3d hand datasets using differentiable ray tracing,
G. Karvounas, N. Kyriazis, I. Oikonomidis, and A. Argyros, “Dynamic multiview refinement of 3d hand datasets using differentiable ray tracing,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3156–3166. 2
2023
-
[14]
Trends in acupuncture training research: focus on practical phantom models,
J. E. Jang, Y . S. Lee, W. S. Jang, W. S. Sung, E.-J. Kim, S. D. Lee, K. H. Kim, and C. Y . Jung, “Trends in acupuncture training research: focus on practical phantom models,” 2022. 2, 3
2022
-
[15]
A contrastive learning network for performance metric and assessment of physical rehabilita- tion exercises,
L. Yao, Q. Lei, H. Zhang, J. Du, and S. Gao, “A contrastive learning network for performance metric and assessment of physical rehabilita- tion exercises,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023. 2, 3, 5, 6
2023
-
[16]
Finediving: A fine-grained dataset for procedure-aware action quality assessment,
J. Xu, Y . Rao, X. Yu, G. Chen, J. Zhou, and J. Lu, “Finediving: A fine-grained dataset for procedure-aware action quality assessment,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 2949–2958. 2
2022
-
[17]
Logo: A long-form video dataset for group action quality assessment,
S. Zhang, W. Dai, S. Wang, X. Shen, J. Lu, J. Zhou, and Y . Tang, “Logo: A long-form video dataset for group action quality assessment,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 2405–2414. 2
2023
-
[18]
Pose- guided transformer for fine-grained action quality assessment,
Y . Zhang, X. Li, W. Chai, C. Yan, W. Wang, and G. Wang, “Pose- guided transformer for fine-grained action quality assessment,”IEEE Transactions on Circuits and Systems for Video Technology, 2025. 2, 3, 5, 8, 9
2025
-
[19]
Lucidaction: A hierarchical and multi-model dataset for comprehensive action quality assessment,
L. Dong, W. Wang, Y . Qiao, and X. Sun, “Lucidaction: A hierarchical and multi-model dataset for comprehensive action quality assessment,” Advances in neural information processing systems, vol. 37, pp. 96 468– 96 482, 2024. 2, 3, 7
2024
-
[20]
M. D. Constable, F. X. Zhang, T. Conner, D. Monk, J. Rajsic, C. Ford, L. J. Park, A. Platt, D. Porteous, L. Griersonet al., “Advancing healthcare practice and education via data sharing: demonstrating the utility of open data by training an artificial intelligence model to assess cardiopulmonary resuscitation skills,”Advances in Health Sciences Education,...
2024
-
[21]
Clinical video analysis with geometric feature enhanced deep learning,
X. Zhang, “Clinical video analysis with geometric feature enhanced deep learning,” Doctoral Thesis, Durham University, Durham, UK, 2025, available under Creative Commons Attribution 3.0 (CC BY). [Online]. Available: https://etheses.dur.ac.uk/16017/ 2
2025
-
[22]
A survey of video-based action quality assessment,
S. Wang, D. Yang, P. Zhai, Q. Yu, T. Suo, Z. Sun, K. Li, and L. Zhang, “A survey of video-based action quality assessment,” in2021 International conference on networking systems of AI (INSAI). IEEE, 2021, pp. 1–9. 3, 7
2021
-
[23]
Assessing the quality of actions,
H. Pirsiavash, C. V ondrick, and A. Torralba, “Assessing the quality of actions,” inEuropean conference on computer vision. Springer, 2014, pp. 556–571. 3
2014
-
[24]
What and how well you performed? a mul- titask learning approach to action quality assessment,
P. Parmar and B. T. Morris, “What and how well you performed? a mul- titask learning approach to action quality assessment,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 304–313. 3
2019
-
[25]
Fineparser: A fine- grained spatio-temporal action parser for human-centric action quality assessment,
J. Xu, S. Yin, G. Zhao, Z. Wang, and Y . Peng, “Fineparser: A fine- grained spatio-temporal action parser for human-centric action quality assessment,” inProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2024, pp. 14 628–14 637. 3, 8, 9
2024
-
[26]
Human-centric fine-grained action qual- ity assessment,
J. Xu, S. Yin, and Y . Peng, “Human-centric fine-grained action qual- ity assessment,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3, 8, 9
2025
-
[27]
Phi: Bridging domain shift in long-term action quality assessment via progressive hierarchical instruction,
K. Zhou, H. P. Shum, F. W. Li, X. Zhang, and X. Liang, “Phi: Bridging domain shift in long-term action quality assessment via progressive hierarchical instruction,”IEEE Transactions on Image Processing, 2025. 3, 8, 9, 10
2025
-
[28]
Aifit: Automatic 3d human-interpretable feedback models for fitness training,
M. Fieraru, M. Zanfir, S. C. Pirlea, V . Olaru, and C. Sminchisescu, “Aifit: Automatic 3d human-interpretable feedback models for fitness training,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9919–9928. 3
2021
-
[29]
Learning sparse temporal video mapping for action quality assessment in floor gymnastics,
S. Zahan, G. M. Hassan, and A. Mian, “Learning sparse temporal video mapping for action quality assessment in floor gymnastics,”IEEE Transactions on Instrumentation and Measurement, 2024. 3
2024
-
[30]
Inertial sensor-based analysis of equestrian sports between beginner and professional riders under different horse gaits,
Z. Wang, J. Li, J. Wang, H. Zhao, S. Qiu, N. Yang, and X. Shi, “Inertial sensor-based analysis of equestrian sports between beginner and professional riders under different horse gaits,”IEEE Transactions on Instrumentation and Measurement, vol. 67, no. 11, pp. 2692–2704,
-
[31]
Haptic virtual rehabilitation exercises for poststroke diagnosis,
A. Alamri, M. Eid, R. Iglesias, S. Shirmohammadi, and A. El Saddik, “Haptic virtual rehabilitation exercises for poststroke diagnosis,”IEEE transactions on instrumentation and measurement, vol. 57, no. 9, pp. 1876–1884, 2008. 3
2008
-
[32]
Sensorized glove for measuring hand finger flexion for rehabilitation purposes,
M. Borghetti, E. Sardini, and M. Serpelloni, “Sensorized glove for measuring hand finger flexion for rehabilitation purposes,”IEEE Trans- actions on Instrumentation and Measurement, vol. 62, no. 12, pp. 3308– 3314, 2013. 3
2013
-
[33]
Taichi action capture and performance analysis with multi-view rgb cameras,
J. Li, S. Mo, and Y . Shen, “Taichi action capture and performance analysis with multi-view rgb cameras,”arXiv preprint arXiv:2306.14490,
-
[34]
Ai-driven tai chi mastery using deep learning framework for movement assessment and personalized training,
X. Zhao, “Ai-driven tai chi mastery using deep learning framework for movement assessment and personalized training,”Scientific Reports, vol. 15, no. 1, p. 31700, 2025. 3
2025
-
[35]
Development of a motion capture and feedback system for qigong,
M. Baldinger, K. Lippmann, G. Lisca, and V . Senner, “Development of a motion capture and feedback system for qigong,”Sports Engineering, vol. 28, no. 1, p. 23, 2025. 3
2025
-
[36]
Tui na (or tuina) massage: a minireview of pertinent literature, 1970-2017,
A. Al-Bedah, G. Ali, T. Abushanab, and N. Qureshi, “Tui na (or tuina) massage: a minireview of pertinent literature, 1970-2017,”Journal of Complementary and Alternative Medical Research, vol. 3, no. 1, pp. 1–14, 2017. 3
1970
-
[37]
Multiview video-based 3-d pose estimation of patients in computer-assisted reha- bilitation environment (caren),
W. Xu, D. Xiang, G. Wang, R. Liao, M. Shao, and K. Li, “Multiview video-based 3-d pose estimation of patients in computer-assisted reha- bilitation environment (caren),”IEEE Transactions on Human-Machine Systems, vol. 52, no. 2, pp. 196–206, 2022. 3
2022
-
[38]
3d human pose estimation in multi-view operating room videos using differentiable cam- era projections,
B. G. Gerats, J. M. Wolterink, and I. A. Broeders, “3d human pose estimation in multi-view operating room videos using differentiable cam- era projections,”Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, vol. 11, no. 4, pp. 1197–1205,
-
[39]
Multi- view surgical video action detection via mixed global view attention,
A. Schmidt, A. Sharghi, H. Haugerud, D. Oh, and O. Mohareri, “Multi- view surgical video action detection via mixed global view attention,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part IV 24. Springer, 2021, pp. 626–635. 3
2021
-
[40]
A multi-camera, multi-view system for training and skill assessment for robot-assisted surgery,
A. E. Abdelaal, A. Avinash, M. Kalia, G. D. Hager, and S. E. Salcudean, “A multi-camera, multi-view system for training and skill assessment for robot-assisted surgery,”International journal of computer assisted radiology and surgery, vol. 15, no. 8, pp. 1369–1377, 2020. 3
2020
-
[41]
A data set of human body movements for physical rehabilitation exercises,
A. Vakanski, H.-p. Jun, D. Paul, and R. Baker, “A data set of human body movements for physical rehabilitation exercises,”Data, vol. 3, no. 1, p. 2, 2018. 3
2018
-
[42]
The kimore dataset: Kinematic assessment of movement and clinical scores for remote monitoring of physical rehabilitation,
M. Capecci, M. G. Ceravolo, F. Ferracuti, S. Iarlori, A. Monteriu, L. Romeo, and F. Verdini, “The kimore dataset: Kinematic assessment of movement and clinical scores for remote monitoring of physical rehabilitation,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 27, no. 7, pp. 1436–1448, 2019. 3
2019
-
[43]
Intel- lirehabds (irds)—a dataset of physical rehabilitation movements,
A. Miron, N. Sadawi, W. Ismail, H. Hussain, and C. Grosan, “Intel- lirehabds (irds)—a dataset of physical rehabilitation movements,”Data, vol. 6, no. 5, p. 46, 2021. 3
2021
-
[44]
A medical low-back pain physical rehabilitation database for human body movement analysis,
M. Devanne, O. R. Neris, M. Lempereur, A. Thepautet al., “A medical low-back pain physical rehabilitation database for human body movement analysis,” in2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–8. 3
2024
-
[45]
Finerehab: A multi-modality and multi-task dataset for rehabilitation analysis,
J. Li, J. Xue, R. Cao, X. Du, S. Mo, K. Ran, and Z. Zhang, “Finerehab: A multi-modality and multi-task dataset for rehabilitation analysis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 3184–3193. 3, 4
2024
-
[46]
An exocentric look at egocentric actions and vice versa,
S. Ardeshir and A. Borji, “An exocentric look at egocentric actions and vice versa,”Computer Vision and Image Understanding, vol. 171, pp. 61–68, 2018. 4
2018
-
[47]
Evaluation specification of clinical prac- tice guidelines of traditional chinese medicine,
C. A. of Chinese Medicine, “Evaluation specification of clinical prac- tice guidelines of traditional chinese medicine,” China Association of Chinese Medicine, Tech. Rep., January 2021, draft version. 4
2021
-
[48]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”biometrics, pp. 159–174, 1977. 4
1977
-
[49]
Crossvit: Cross-attention multi- scale vision transformer for image classification,
C.-F. R. Chen, Q. Fan, and R. Panda, “Crossvit: Cross-attention multi- scale vision transformer for image classification,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 357–
2021
-
[50]
Early vs late fusion in multimodal convolutional neural networks,
K. Gadzicki, R. Khamsehashari, and C. Zetzsche, “Early vs late fusion in multimodal convolutional neural networks,” in2020 IEEE 23rd international conference on information fusion (FUSION). IEEE, 2020, pp. 1–6. 5 AUTHORet al.: TITLE 15
2020
-
[51]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778. 6, 7
2016
-
[52]
MediaPipe: A Framework for Building Perception Pipelines
C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, F. Zhang, C.-L. Chang, M. G. Yong, J. Leeet al., “Mediapipe: A framework for building perception pipelines,”arXiv preprint arXiv:1906.08172, 2019. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 1906
- [53]
-
[54]
Umetrack: Unified multi-view end-to-end hand tracking for vr,
S. Han, P.-c. Wu, Y . Zhang, B. Liu, L. Zhang, Z. Wang, W. Si, P. Zhang, Y . Cai, T. Hodanet al., “Umetrack: Unified multi-view end-to-end hand tracking for vr,” inSIGGRAPH Asia 2022 conference papers, 2022, pp. 1–9. 6
2022
-
[55]
A compre- hensive survey of action quality assessment: Method and benchmark,
K. Zhou, R. Cai, L. Wang, H. P. H. Shum, and X. Liang, “A compre- hensive survey of action quality assessment: Method and benchmark,” Pattern Recognition, vol. 179, p. 113933, 2026. 7
2026
-
[56]
Towards a general-purpose foundation model for computational pathology,
R. J. Chen, T. Ding, M. Y . Lu, D. F. Williamson, G. Jaume, A. H. Song, B. Chen, A. Zhang, D. Shao, M. Shabanet al., “Towards a general-purpose foundation model for computational pathology,”Nature medicine, vol. 30, no. 3, pp. 850–862, 2024. 7
2024
-
[57]
Spatial temporal graph convolutional networks for skeleton-based action recognition,
S. Yan, Y . Xiong, and D. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018. 8, 9
2018
-
[58]
High-velocity insertion of acupuncture needle is related to lower level of pain,
C. S. Yin, J.-H. Kim, and H.-J. Park, “High-velocity insertion of acupuncture needle is related to lower level of pain,”The Journal of Alternative and Complementary Medicine, vol. 17, no. 1, pp. 27–32,
-
[59]
A systematic review of skeleton-based action recognition: Methods, chal- lenges, and future directions,
Y . Liu, R. Liu, Y . Hu, M. Wu, W. Xin, Q. Miao, S. Wu, and L. Li, “A systematic review of skeleton-based action recognition: Methods, chal- lenges, and future directions,”IEEE Transactions on Neural Networks and Learning Systems, 2025. 11
2025
-
[60]
An audiovisual feedback device for compression depth, rate and complete chest recoil can improve the cpr performance of lay persons during self-training on a manikin,
V . Krasteva, I. Jekova, and J.-P. Didon, “An audiovisual feedback device for compression depth, rate and complete chest recoil can improve the cpr performance of lay persons during self-training on a manikin,” Physiological measurement, vol. 32, no. 6, pp. 687–699, 2011. 12
2011
-
[61]
Hierarchical temporal transformer for 3d hand pose estimation and action recognition from egocentric rgb videos,
Y . Wen, H. Pan, L. Yang, J. Pan, T. Komura, and W. Wang, “Hierarchical temporal transformer for 3d hand pose estimation and action recognition from egocentric rgb videos,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 21 243– 21 253. 13
2023
-
[62]
Geometric features informed multi-person human-object interaction recognition in videos,
T. Qiao, Q. Men, F. W. Li, Y . Kubotani, S. Morishima, and H. P. Shum, “Geometric features informed multi-person human-object interaction recognition in videos,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 474–491. 13
2022
-
[63]
Geometric fea- tures enhanced human-object interaction detection,
M. Zhu, E. S. Ho, S. Chen, L. Yang, and H. P. Shum, “Geometric fea- tures enhanced human-object interaction detection,”IEEE Transactions on Instrumentation and Measurement, 2024. 13
2024
-
[64]
Adaptive graph learning from spatial information for surgical workflow anticipation,
F. X. Zhang, J. Deng, R. Lieck, and H. P. Shum, “Adaptive graph learning from spatial information for surgical workflow anticipation,” IEEE Transactions on Medical Robotics and Bionics, 2024. 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.