JuZhou 1.0 Technical Report: The First Edge-Native Text-to-Image Foundation Model Trained Entirely on China-Developed AI Accelerators
Pith reviewed 2026-06-30 00:58 UTC · model grok-4.3
The pith
JuZhou 1.0 is a 0.387-billion-parameter text-to-image model trained entirely on domestic Chinese accelerators that runs fully offline on smartphones and scores 0.69 on GenEval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
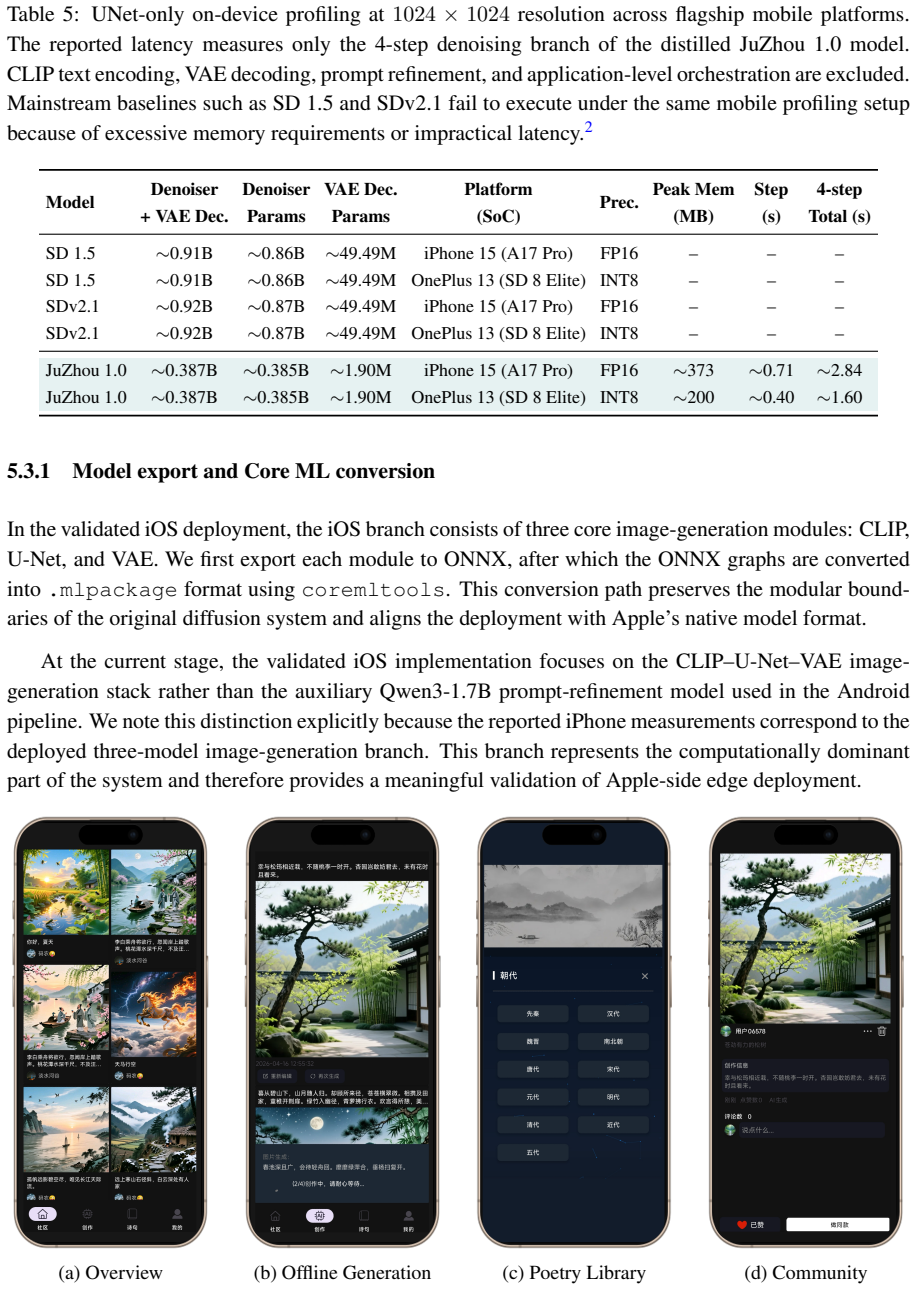
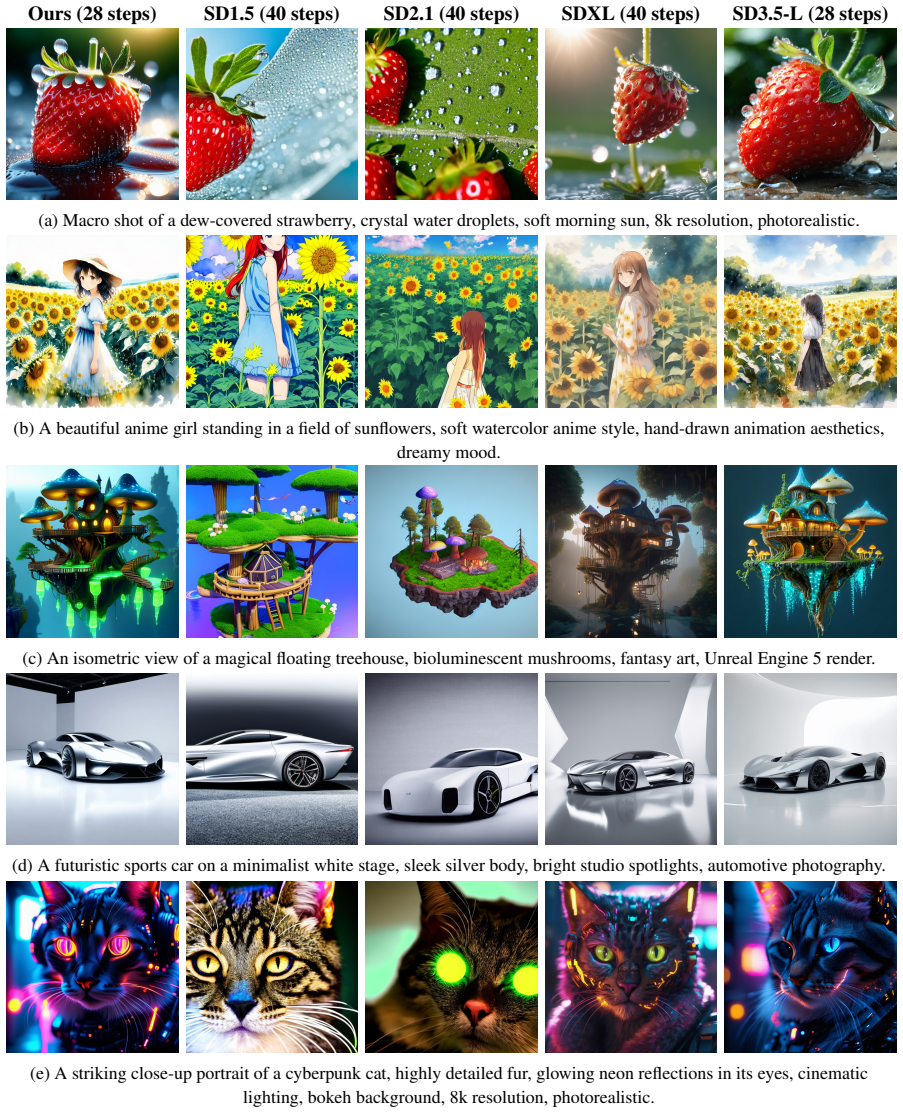
JuZhou 1.0 achieves an overall GenEval score of 0.69 with its 28-step base model, outperforming published baselines including SDXL (2.6B, 0.55), SD3-Medium (2B, 0.62), and IF-XL (4.3B, 0.61), while being designed for fully offline on-device execution on mobile platforms after training on domestic accelerators.
What carries the argument
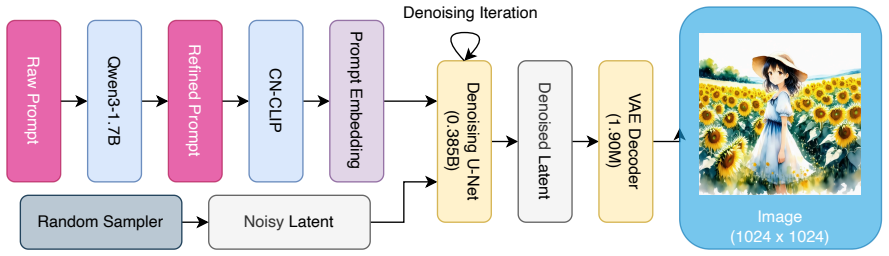
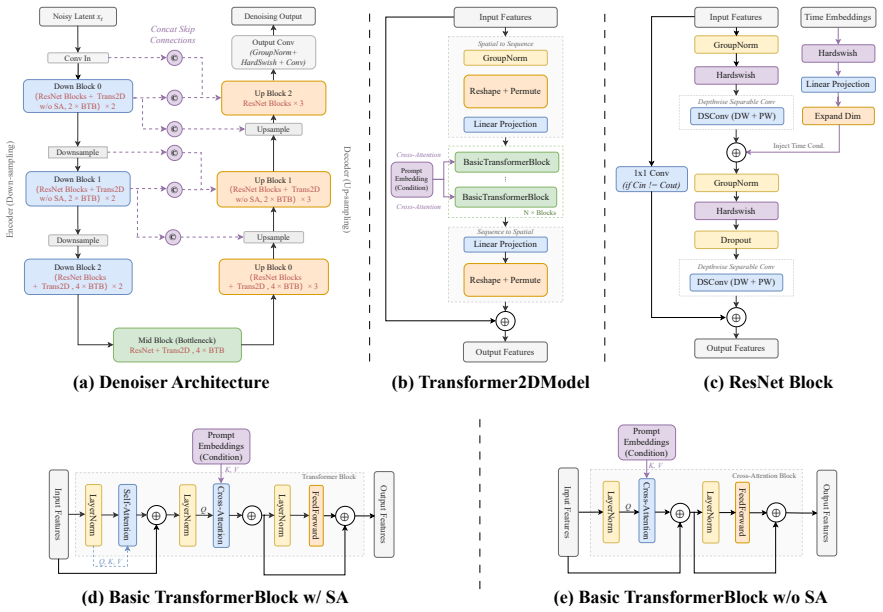
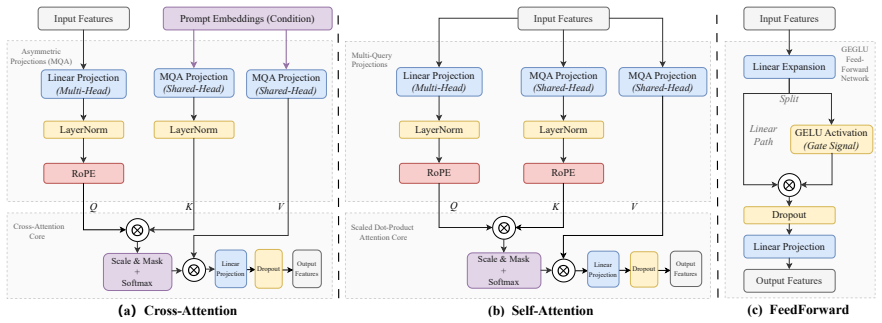
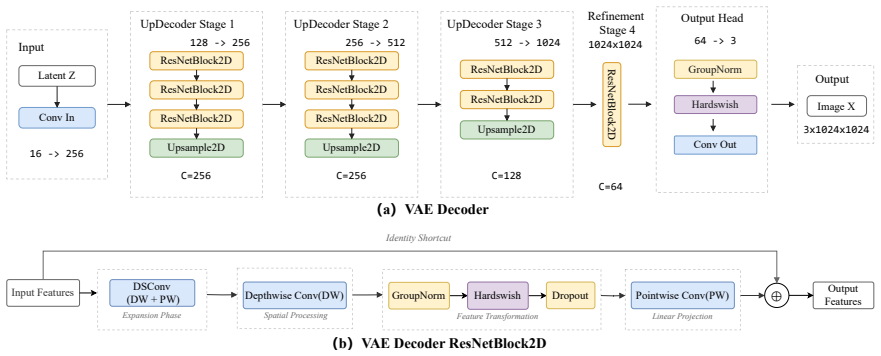
The compact image-generation backbone consisting of a 0.385B-parameter denoising U-Net and a 1.90M-parameter distilled decoder, combined with Rectified Flow training and DMD2 distillation that reduces inference to 4 sampling steps.
If this is right
- The 4-step distilled model enables practical fully offline text-to-image generation on smartphones after a single installation.
- Direct Chinese prompting works without external translation steps at inference time.
- The complete training and distillation pipeline can be executed on domestically developed Sugon K100 accelerators.
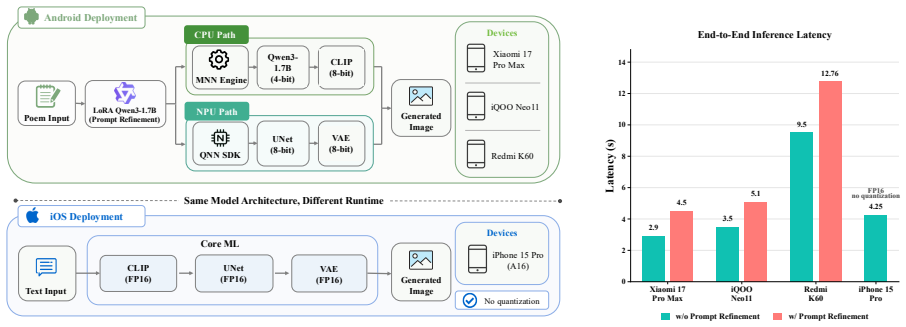
- The generation branch runs in approximately 1.6 seconds on Snapdragon 8 Elite hardware and the full Android poetry-to-image pipeline completes in 4.5 seconds.
- The same architecture validates on both Android and iOS platforms.
Where Pith is reading between the lines
- The combination of distillation and domestic hardware training could reduce dependence on foreign cloud infrastructure for image generation tasks.
- Native Chinese semantic alignment may improve prompt fidelity for users writing in Chinese compared with translated pipelines.
- The reported parameter count and step reduction suggest similar compression techniques could be tested on other edge vision or multimodal tasks.
Load-bearing premise
GenEval benchmark scores can be compared directly across models of different scales and training regimes, and the reported on-device timings reflect typical performance without undisclosed hardware-specific optimizations.
What would settle it
A side-by-side GenEval evaluation of JuZhou 1.0 and the baseline models run on the identical benchmark code and data splits, or a hardware profiler trace of the mobile inference confirming the reported latencies without hidden optimizations.
Figures




read the original abstract
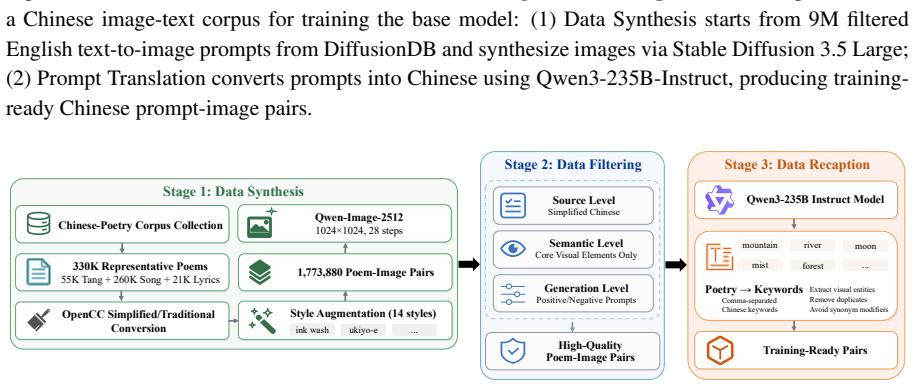
Text-to-image (T2I) diffusion models typically require substantial computational resources and cloud infrastructure, posing significant challenges for edge deployment in terms of latency, cost, and user privacy. We present JuZhou 1.0, an ultra-lightweight T2I foundation model designed for fully offline, on-device execution. JuZhou 1.0 achieves its efficiency through four key designs: (1) a compact image-generation backbone consisting of a 0.385B-parameter denoising U-Net and a 1.90M-parameter distilled decoder, totaling approximately 0.387B parameters; (2) Rectified Flow training combined with DMD2 distillation, reducing inference to 4 sampling steps; (3) Chinese semantic alignment trained on 9M curated image-text pairs, enabling direct Chinese prompting without external translation at inference time; and (4) a training and distillation pipeline completed on domestically developed Sugon K100 AI accelerators without relying on NVIDIA GPUs for training or distillation. Despite its compact scale, the 28-step base model of JuZhou 1.0 achieves an overall GenEval score of 0.69, outperforming published baselines including SDXL (2.6B, 0.55), SD3-Medium (2B, 0.62), and IF-XL (4.3B, 0.61). We further validate the full poetry-to-image pipeline on Android and the core CLIP-U-Net-VAE generation branch on iOS. On a smartphone powered by the Snapdragon 8 Elite Gen 5 Mobile Platform, the 4-step U-Net denoising branch runs in approximately 1.6 seconds, while the full Android poetry-to-image pipeline takes 4.5 seconds with on-device prompt refinement on Xiaomi 17 Pro Max. These results position JuZhou 1.0 as a practical approach to mobile text-to-image generation and provide a concrete reference for Chinese-native generation, domestic-compute training, and fully offline on-device deployment after one-time installation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JuZhou 1.0, an ultra-lightweight 0.387B-parameter text-to-image diffusion model (0.385B U-Net + 1.90M decoder) trained on 9M curated Chinese image-text pairs using Rectified Flow and DMD2 distillation on Sugon K100 accelerators. It claims a GenEval score of 0.69 for the 28-step base model (outperforming SDXL at 0.55, SD3-Medium at 0.62, and IF-XL at 0.61), 4-step inference, direct Chinese prompting, and on-device timings of ~1.6s for the U-Net on Snapdragon 8 Elite and 4.5s for the full Android poetry-to-image pipeline.
Significance. If the performance claims are substantiated under equivalent conditions, the work would demonstrate practical fully-offline on-device T2I generation with a compact model trained entirely on domestic hardware and language-specific data, providing a reference point for edge deployment, privacy, and non-Western foundation model development.
major comments (2)
- [Abstract] Abstract: The headline GenEval claim (0.69 for the 28-step base model outperforming the listed baselines) is presented without any description of the evaluation protocol, including whether the same GenEval prompt set/version, sampling steps, guidance scale, scheduler, or number of samples were used for all models, or whether baseline scores were re-computed in the authors' setup rather than taken from prior publications.
- [Abstract] Abstract: The training description stresses 9M Chinese image-text pairs and 'direct Chinese prompting without external translation,' yet GenEval is an English prompt benchmark; the manuscript does not state whether English prompts were used for JuZhou evaluation, how any language mismatch was handled, or whether this affects score comparability.
minor comments (1)
- The abstract distinguishes the 28-step base model for the GenEval claim from the 4-step distilled model used for timings, but the manuscript would benefit from an explicit results subsection separating these configurations and their respective metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation protocol and language considerations for our GenEval results. We address each point below and will revise the manuscript to improve clarity and transparency on these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline GenEval claim (0.69 for the 28-step base model outperforming the listed baselines) is presented without any description of the evaluation protocol, including whether the same GenEval prompt set/version, sampling steps, guidance scale, scheduler, or number of samples were used for all models, or whether baseline scores were re-computed in the authors' setup rather than taken from prior publications.
Authors: We agree that the abstract does not describe the evaluation protocol in sufficient detail. The reported baseline scores (SDXL 0.55, SD3-Medium 0.62, IF-XL 0.61) are taken directly from the original publications rather than re-evaluated in our environment. Our JuZhou 28-step model was evaluated on the standard GenEval benchmark using its default prompt set. In the revised manuscript we will add an explicit paragraph (likely in Section 4 or a new evaluation subsection) stating the precise protocol used for JuZhou: 28 sampling steps, guidance scale 7.5, the default Euler scheduler, and the full GenEval prompt set with the standard number of samples. We will also note that direct apples-to-apples re-computation of all baselines was not performed. revision: yes
-
Referee: [Abstract] Abstract: The training description stresses 9M Chinese image-text pairs and 'direct Chinese prompting without external translation,' yet GenEval is an English prompt benchmark; the manuscript does not state whether English prompts were used for JuZhou evaluation, how any language mismatch was handled, or whether this affects score comparability.
Authors: We acknowledge the observation. Although the model was trained exclusively on Chinese image-text pairs to support direct Chinese prompting, the GenEval score of 0.69 was obtained by running the standard English GenEval prompts through the model without any translation step. The model accepts English input because its text encoder was initialized from a multilingual checkpoint and further adapted during training. In the revision we will add a sentence clarifying that GenEval evaluation used the original English prompts and will briefly discuss the potential impact on cross-model comparability given the Chinese-centric training data. revision: yes
Circularity Check
No significant circularity; empirical benchmark results are self-contained
full rationale
The paper is a technical report presenting an empirical model (0.387B parameters, trained on 9M pairs, evaluated at 0.69 GenEval) with performance numbers and on-device timings. No derivation chain, equations, or self-referential definitions are present in the provided text. Claims rest on external benchmarks and hardware measurements that do not reduce by construction to the paper's own fitted inputs or self-citations. This is the expected honest outcome for a performance report without mathematical self-reference.
Axiom & Free-Parameter Ledger
free parameters (3)
- U-Net parameter count =
0.385B
- inference steps after distillation =
4
- curated training pairs =
9M
axioms (2)
- domain assumption GenEval benchmark provides a meaningful and unbiased measure of text-to-image quality across model scales
- domain assumption DMD2 distillation from the 28-step base preserves sufficient quality for the reported use cases
Reference graph
Works this paper leans on
-
[1]
Text-to-image diffusion models in generative ai: A survey,
C. Zhang, C. Zhang, M. Zhang, I. S. Kweon, and J. Kim, “Text-to-image diffusion models in generative ai: A survey,”arXiv preprint arXiv:2303.07909, 2023
-
[2]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
C. Saharia, W. Chan, S. Saxena, J. Li, J. Whang, E. Denton, S. M. H. A. Ghasemipour,et al., “Imagen: Photorealistic text-to-image diffusion models with deep language understanding,”arXiv preprint arXiv:2205.11487, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,”arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” inInternational Conference on Learning Representations, 2024. 5https://www.icswb.com/default.php?mod=live_text&live_id=914&temp=live_video 26
2024
-
[5]
B. F. Labs, “Flux.”https://github.com/black-forest-labs/flux, 2024
2024
-
[6]
Scalable Diffusion Models with Transformers
W. Peebles and S. Xie, “Scalable diffusion models with transformers,”arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022
2022
-
[8]
Stable diffusion 2.1 release notes
S. AI, “Stable diffusion 2.1 release notes.”https://stability.ai/news/ stable-diffusion-v2-1-release, 2022
2022
-
[9]
Cogview: Pretrained transformers for image synthesis from text,
M. Ding, Z. Yang, W. Duan, J. Lu, J. Wu, and C. Zhu, “Cogview: Pretrained transformers for image synthesis from text,”arXiv preprint arXiv:2105.13290, 2021
-
[10]
X. Wu, D. Zhang, R. Gan, J. Lu, Z. Wu,et al., “Taiyi-diffusion-xl: Advancing bilingual text-to- image generation with large vision-language model support,”arXiv preprint arXiv:2401.14688, 2024
-
[11]
Mobilediffusion: Instant text-to-image generation on mobile devices,
Y . Zhao, Y . Xu, Z. Xiao, H. Jia, and T. Hou, “Mobilediffusion: Instant text-to-image generation on mobile devices,” inEuropean Conference on Computer Vision, pp. 225–242, Springer, 2024
2024
-
[12]
D. Hu, J. Chen, X. Huang, H. Coskun,et al., “Snapgen: Taming high-resolution text-to- image models for mobile devices with efficient architectures and training,”arXiv preprint arXiv:2412.09619, 2024
-
[13]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020
2020
-
[14]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Improved distribution matching distillation for fast image synthesis,
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and W. T. Freeman, “Improved distribution matching distillation for fast image synthesis,”Advances in Neural Information Pro- cessing Systems, vol. 37, 2024
2024
-
[16]
Mnn: A universal and efficient inference engine,
X. Jiang, H. Wang, Y . Chen, Z. Wu, L. Wang, B. Zou, Y . Yang, Z. Cui, Y . Cai, T. Yu, C. Lv, and Z. Wu, “Mnn: A universal and efficient inference engine,” inMLSys, 2020
2020
-
[17]
Qualcomm ai engine direct sdk reference guide
I. Qualcomm Technologies, “Qualcomm ai engine direct sdk reference guide.”https://docs. qualcomm.com/nav/home/index_QNN.html?product=1601111740009302, 2026
2026
-
[18]
Laion-5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti,et al., “Laion-5b: An open large-scale dataset for training next generation image-text models,”Advances in Neural Information Processing Systems, vol. 35, pp. 35276–35296, 2022
2022
-
[19]
Pai-diffusion: Constructing and serving a family of open chinese diffusion models for text-to-image synthesis on the cloud,
C. Wang, Z. Duan, B. Liu, X. Zou, C. Chen, K. Jia, and J. Huang, “Pai-diffusion: Constructing and serving a family of open chinese diffusion models for text-to-image synthesis on the cloud,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023
2023
-
[20]
Accelerating dif- fusion model training under minimal budgets: A condensation-based perspective,
R. Huang, S. Shao, Z. Zhou, P. Zhao, H. Guo, T. Ye, L. Bai, S. Yang, and Z. Xie, “Accelerating dif- fusion model training under minimal budgets: A condensation-based perspective,”arXiv preprint arXiv:2507.05914, 2025. 27
-
[21]
Diffusiondb: A large-scale prompt gallery for text-to-image diffusion models,
Z. J. Wang, E. Montoya, D. Munechika, H. Yang, B. Hoover, and D. H. Chau, “Diffusiondb: A large-scale prompt gallery for text-to-image diffusion models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
2023
-
[22]
chinese-poetry: The most comprehensive database of Chinese poetry
J. Gao and contributors, “chinese-poetry: The most comprehensive database of Chinese poetry.” https://github.com/chinese-poetry/chinese-poetry, 2019. Accessed 2026- 05-27
2019
-
[23]
Open Chinese Convert (OpenCC)
BYV oid, “Open Chinese Convert (OpenCC).”https://github.com/byvoid/opencc,
-
[24]
Version 1.3.1, accessed 2026-05-27
2026
-
[25]
Qwen-image technical report,
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S. ming Yin, S. Bai, X. Xu, Y . Chen, Y . Chen, Z. Tang, Z. Zhang, Z. Wang, A. Yang, B. Yu, C. Cheng, D. Liu, D. Li, H. Zhang, H. Meng, H. Wei, J. Ni, K. Chen, K. Cao, L. Peng, L. Qu, M. Wu, P. Wang, S. Yu, T. Wen, W. Feng, X. Xu, Y . Wang, Y . Zhang, Y . Zhu, Y . Wu, Y . Cai, and Z. Liu, “Qwen-image technica...
2025
-
[26]
Reproducible scaling laws for contrastive language-image learning,
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev, “Reproducible scaling laws for contrastive language-image learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2816– 2827, 2023
2023
-
[27]
Long-clip: Unlocking the long-text capability of clip,
B. Zhang, P. Zhang, X. Dong, Y . Zang, and J. Wang, “Long-clip: Unlocking the long-text capability of clip,”arXiv preprint arXiv:2403.15378, 2024
-
[28]
Qwen3 technical report,
Q. Team, “Qwen3 technical report,” 2025
2025
-
[29]
Bridge diffusion model: Bridge chinese text-to-image diffusion model with english communities,
S. Liu, B. Cheng, Y . Ma, L. Wu, A. Ma, X. Wu, D. Leng, and Y . Yin, “Bridge diffusion model: Bridge chinese text-to-image diffusion model with english communities,” inProceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[30]
Chinese clip: Contrastive vision-language pretraining in chinese,
A. Yang, J. Pan, J. Lin, R. Men, Y . Zhang, J. Zhou, and C. Zhou, “Chinese clip: Contrastive vision-language pretraining in chinese,”arXiv preprint arXiv:2211.01335, 2022
-
[31]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis,et al., “Lora: Low-rank adaptation of large language models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Q-diffusion: Quantizing diffusion models,
X. Li, Y . Liu, L. Lian, H. Yang, Z. Dong, D. Kang, S. Zhang, and K. Keutzer, “Q-diffusion: Quantizing diffusion models,”arXiv preprint arXiv:2302.04304, 2023
-
[33]
X. Wu, C. Li, R. Yazdani Aminabadi, Z. Yao, and Y . He, “Understanding int4 quantization for transformer models: Latency speedup, composability, and failure cases,”arXiv preprint arXiv:2301.12017, 2023
-
[34]
Low-bit model quantization for deep neural networks: A survey,
K. Liu, Q. Zheng, K. Tao, Z. Li, H. Qin, W. Li, Y . Guo, X. Liu, L. Kong, G. Chen, Y . Zhang, and X. Yang, “Low-bit model quantization for deep neural networks: A survey,”arXiv preprint arXiv:2505.05530, 2025
-
[35]
Geneval: An object-focused framework for evaluating text-to-image alignment,
D. Ghosh, H. Hajishirzi, and L. Schmidt, “Geneval: An object-focused framework for evaluating text-to-image alignment,”Advances in Neural Information Processing Systems, vol. 36, pp. 52132– 52152, 2023. 28
2023
-
[36]
Lumina-next: Making lumina-t2x stronger and faster with next-dit,
L. Zhuo, R. Du, H. Xiao, Y . Li, D. Liu, R. Huang, W. Liu, L. Zhao, F.-Y . Wang, Z. Ma, X. Luo, Z. Wang, K. Zhang, X. Zhu, S. Liu, X. Yue, D. Liu, W. Ouyang, Z. Liu, Y . Qiao, H. Li, and P. Gao, “Lumina-next: Making lumina-t2x stronger and faster with next-dit,” 2024
2024
-
[37]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y . Marek, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” 2024
2024
-
[38]
Playground v2.5: Three insights towards enhancing aesthetic quality in text-to-image generation,
D. Li, A. Kamko, E. Akhgari, A. Sabet, L. Xu, and S. Doshi, “Playground v2.5: Three insights towards enhancing aesthetic quality in text-to-image generation,” 2024
2024
-
[39]
DeepFloyd IF: A modular cascaded pixel-space text-to-image diffusion model,
DeepFloyd Lab and Stability AI, “DeepFloyd IF: A modular cascaded pixel-space text-to-image diffusion model,” 2023. Official model repository
2023
-
[40]
Sana: Efficient high-resolution image synthesis with linear diffusion transformers,
E. Xie, J. Chen, J. Chen, H. Cai, H. Tang, Y . Lin, Z. Zhang, M. Li, L. Zhu, Y . Lu, and S. Han, “Sana: Efficient high-resolution image synthesis with linear diffusion transformers,” 2024
2024
-
[41]
Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding,
Z. Li, J. Zhang, Q. Lin, J. Xiong, Y . Long, X. Deng, Y . Zhang, X. Liu, M. Huang, Z. Xiao, D. Chen, J. He, J. Li, W. Li, C. Zhang, R. Quan, J. Lu, J. Huang, X. Yuan, X. Zheng, Y . Li, J. Zhang, C. Zhang, M. Chen, J. Liu, Z. Fang, W. Wang, J. Xue, Y . Tao, J. Zhu, K. Liu, S. Lin, Y . Sun, Y . Li, D. Wang, M. Chen, Z. Hu, X. Xiao, Y . Chen, Y . Liu, W. Liu...
2024
-
[42]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
S. Luo, Y . Tan, L. Huang, J. Li, and H. Zhao, “Latent consistency models: Synthesizing high- resolution images with few-step inference,”arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,
N. Ruiz, Y . Li, P. Varadharajan, D. Cohen, N. Hariri, Y . Zhang,et al., “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6840–6850, 2023
2023
-
[44]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or, “An image is worth one word: Personalizing text-to-image generation using textual inversion,”arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning,
Y . Guo, C. Yang, A. Rao, Y . Wang, Y . Qiao, D. Lin, and B. Dai, “Animatediff: Animate your personalized text-to-image diffusion models without specific tuning,” inInternational Conference on Learning Representations, 2024
2024
-
[46]
Lcm-lora: A universal stable-diffusion acceleration module,
S. Luo, Y . Tan, S. Patil, D. Gu, P. von Platen, A. Passos, L. Huang, J. Li, and H. Zhao, “Lcm-lora: A universal stable-diffusion acceleration module,”arXiv preprint arXiv:2311.05556, 2023
-
[47]
Rethinking fid: Towards a better evaluation metric for image generation,
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar, “Rethinking fid: Towards a better evaluation metric for image generation,”arXiv preprint arXiv:2308.14956, 2023. 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.