Geometric Measurements of the Axiom of Choice in Neural Proof Embeddings
Pith reviewed 2026-06-30 00:43 UTC · model grok-4.3
The pith
A neural encoder trained solely on constructive proofs measures classical proofs by their distance from the axiom of choice in the dependency graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
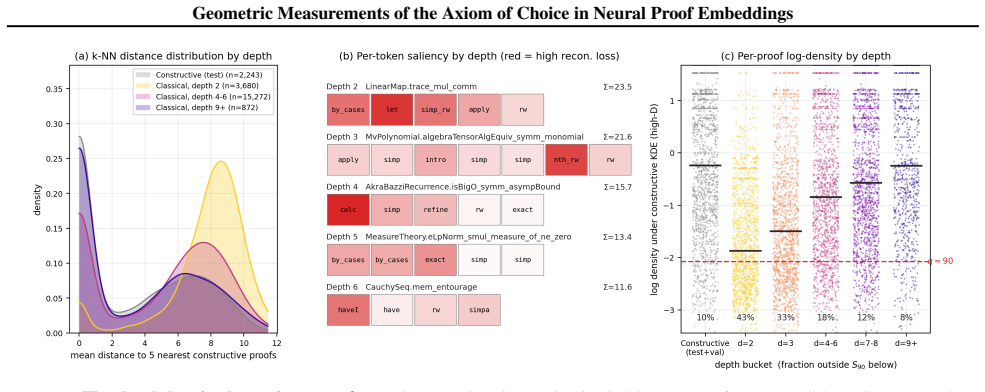
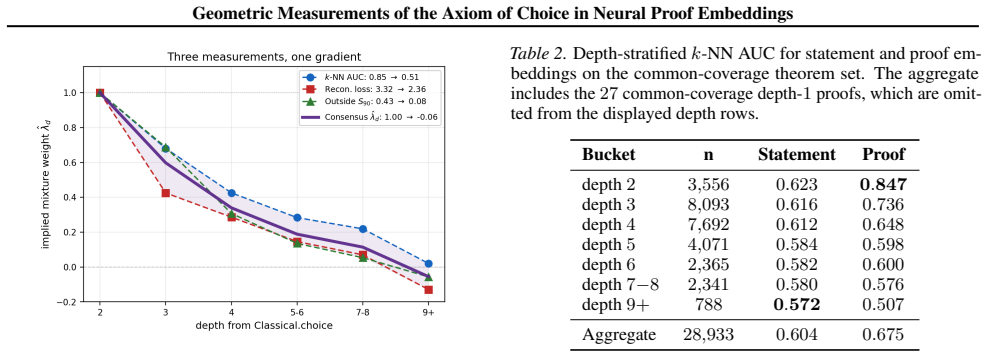
When a self-supervised proof encoder trained only on constructive theorems is applied to classical theorems, anomaly score, reconstruction loss, and density-superlevel containment all decline with the proof's distance from the axiom of choice in the dependency graph, from AUC 0.847 at distance 2 to indistinguishability at distance 9+.
What carries the argument
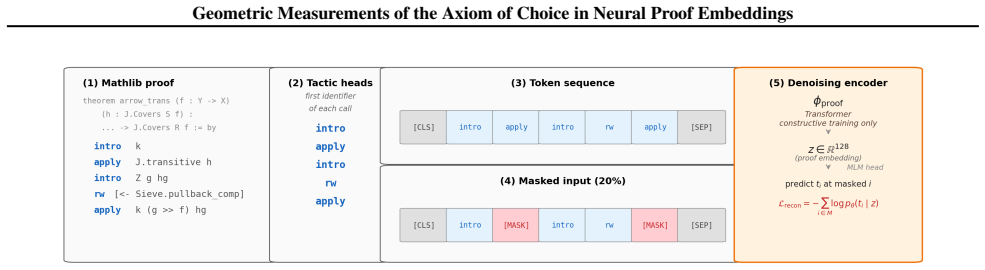
The self-supervised proof encoder that embeds sequences of tactic invocations and computes anomaly via reconstruction loss and density-superlevel containment.
If this is right
- The geometric anomaly score predicts aesop tactic failure beyond proof length.
- A neural-guided hybrid using ReProver compresses the gap in solving rate between constructive and classical theorems from 13x to 5x.
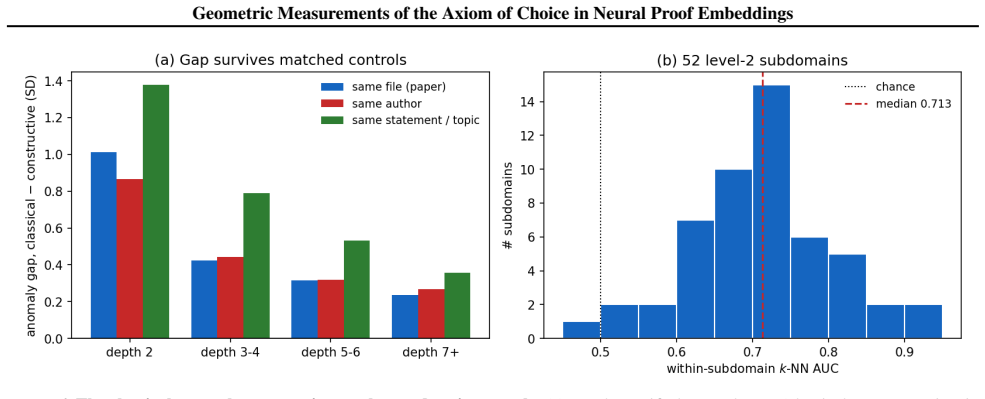
- The signature is robust under controls for length, file, author, and topic.
- Full-source encoders trained on normalised proof source replicate the decline pattern.
Where Pith is reading between the lines
- Similar geometric signatures might appear for other foundational axioms such as the law of excluded middle.
- The anomaly score could serve as a practical heuristic to prioritize theorems for proof search in mixed constructive-classical libraries.
- Training encoders on proofs that avoid specific axioms might improve generalization in automated theorem proving systems.
Load-bearing premise
The filtering and transitive closure in Lean produces a partition where the only systematic difference between constructive and classical theorems is the presence or absence of the axiom of choice itself.
What would settle it
If the anomaly metrics fail to show a decline with increasing dependency distance when the same encoder is tested on the dataset with randomized dependency labels.
Figures

read the original abstract
The axiom of choice has divided the foundations of mathematics for over a century, but the distinction between classical and constructive proofs has remained a philosophical and methodological one. We use Lean 4's kernel-level tracking of axiom dependence to show that the axiom of choice has a measurable geometric correlate in proof space that obeys a one-parameter mixture law and has operational consequences for neural theorem provers. To do this, we partition $471{,}260$ declarations of Mathlib by transitive dependence on the axiom of choice and represent a filtered population of $42{,}355$ traced theorems by their sequences of tactic invocations. We use the constructive proofs in this dataset to train a self-supervised proof encoder and show that when using it to measure classical proofs, three complementary measurements (anomaly score, reconstruction loss, and density-superlevel containment) exhibit a common decline with the proof's distance from the axiom in the dependency graph, from sharp separation at the shallow boundary (AUC $0.847$ at distance $2$) to indistinguishability at distance~$9{+}$. Robustness controls show that the signature survives length, file, author, and topic controls, and replicates under full-source encoders trained on normalised proof source. Operationally, we show that on an evaluation sample of $251$ Mathlib theorems, Lean's \texttt{aesop} tactic solves constructive theorems at $13\times$ the rate of classical ones, and a neural-guided hybrid using the ReProver tactic generator compresses the gap to $5\times$. The geometric anomaly score predicts \texttt{aesop} failure beyond proof length, providing an operational link between the geometric signature and prover performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper partitions 471,260 Mathlib declarations by transitive AC dependence in Lean's kernel, filters to 42,355 traced theorems, trains a self-supervised encoder solely on constructive proofs, and reports that anomaly score, reconstruction loss, and density-superlevel containment on classical proofs decline monotonically with graph distance to AC (AUC 0.847 at distance 2, indistinguishable at 9+). The signature survives explicit controls for length/file/author/topic and replicates with full-source encoders; operationally, aesop solves constructive theorems 13× faster than classical ones and a ReProver hybrid reduces the gap to 5×, with the geometric score predicting aesop failure beyond length.
Significance. If the quantitative claims and controls hold, the work supplies the first large-scale, kernel-grounded geometric signature of a foundational axiom in proof embeddings and demonstrates an operational link to neural prover performance, strengthening the case that self-supervised representations can surface non-syntactic distinctions in formal mathematics.
major comments (3)
- [Abstract, §4] Abstract and §4 (results on mixture law): the claim that the three metrics 'obey a one-parameter mixture law' is load-bearing for the geometric-correlate thesis, yet the manuscript provides no equation for the law, no value or fitting procedure for the free parameter, and no cross-validation or residual analysis; without these the reported monotonic decline cannot be distinguished from a post-hoc descriptive fit.
- [Abstract, §5] Abstract and §5 (AUC and speedup numbers): AUC 0.847, 13× and 5× speedups, and robustness to length/file/author/topic are reported without error bars, bootstrap intervals, or statistical tests; because these quantities are the primary evidence for both the geometric effect and its operational relevance, their uncertainty must be quantified before the central claim can be evaluated.
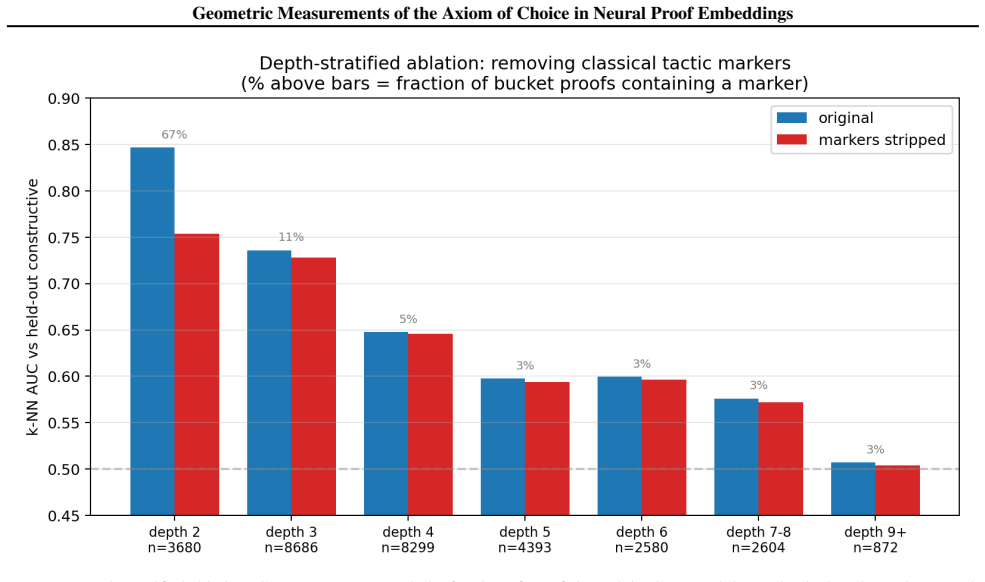
- [§3] §3 (dataset construction): the filtering to 42,355 theorems and the transitive-closure partition are presented as isolating the AC effect, but no table or appendix quantifies residual differences in proof length, tactic vocabulary, or author distribution between the constructive and classical subsets after the stated controls; if these covariates remain imbalanced the distance-to-AC correlation could be confounded.
minor comments (2)
- [§2] Notation for the three metrics (anomaly score, reconstruction loss, density-superlevel containment) is introduced without a single consolidated definition or pseudocode; a short methods subsection or appendix table would improve reproducibility.
- [§5] The 251-theorem evaluation sample for aesop/ReProver is described only by size; a breakdown by distance-to-AC bin or by the same controls used in the embedding experiments would strengthen the operational link.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major point below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results on mixture law): the claim that the three metrics 'obey a one-parameter mixture law' is load-bearing for the geometric-correlate thesis, yet the manuscript provides no equation for the law, no value or fitting procedure for the free parameter, and no cross-validation or residual analysis; without these the reported monotonic decline cannot be distinguished from a post-hoc descriptive fit.
Authors: We agree that the mixture law claim requires explicit formalization. In the revision we will add the precise equation for the one-parameter mixture law, the fitted parameter value and its estimation procedure, cross-validation results, and residual analysis to confirm that the observed monotonic decline is not a post-hoc descriptive fit. revision: yes
-
Referee: [Abstract, §5] Abstract and §5 (AUC and speedup numbers): AUC 0.847, 13× and 5× speedups, and robustness to length/file/author/topic are reported without error bars, bootstrap intervals, or statistical tests; because these quantities are the primary evidence for both the geometric effect and its operational relevance, their uncertainty must be quantified before the central claim can be evaluated.
Authors: We accept that uncertainty quantification is necessary for the primary metrics. The revised version will include bootstrap confidence intervals, error bars on the reported AUC and speedup figures, and statistical tests (e.g., permutation tests for AUC and appropriate nonparametric tests for speedups) in the abstract, §5, and associated tables/figures. revision: yes
-
Referee: [§3] §3 (dataset construction): the filtering to 42,355 theorems and the transitive-closure partition are presented as isolating the AC effect, but no table or appendix quantifies residual differences in proof length, tactic vocabulary, or author distribution between the constructive and classical subsets after the stated controls; if these covariates remain imbalanced the distance-to-AC correlation could be confounded.
Authors: We will add a supplementary table (or appendix section) that reports the residual differences in proof length, tactic vocabulary size, and author distribution between the constructive and classical subsets after the length/file/author/topic controls have been applied, allowing direct assessment of any remaining imbalance. revision: yes
Circularity Check
No significant circularity
full rationale
The paper partitions theorems using Lean's external kernel-level transitive closure on axiom dependence, trains a self-supervised encoder solely on the constructive subset, and evaluates anomaly/reconstruction/density metrics on the classical subset. The reported monotonic decline with graph distance, AUC values, and robustness to length/author/topic controls are empirical measurements, not reductions of a fitted parameter or self-citation to the target result. The one-parameter mixture law is presented as an observed pattern rather than a definitional input. No load-bearing step equates a prediction to its own training data by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- one-parameter mixture law parameter
axioms (1)
- domain assumption Lean's kernel-level tracking of axiom dependence produces an accurate transitive closure for every declaration in Mathlib.
Reference graph
Works this paper leans on
-
[1]
BERT: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[2]
M., Rute, J., Wu, Y ., Ayers, E
Han, J. M., Rute, J., Wu, Y ., Ayers, E. W., and Polu, S. Proof artifact co-training for theorem proving with language models.arXiv preprint arXiv:2102.06203,
-
[3]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
GamePad: A Learning Environment for Theorem Proving
Huang, D., Dhariwal, P., Song, D., and Sutskever, I. Gamepad: A learning environment for theorem proving. arXiv preprint arXiv:1806.00608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Enhancing the reliability of out-of-distribution image detection in neural networks
Liang, S., Li, Y ., and Srikant, R. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv preprint arXiv:1706.02690,
-
[6]
Magnushammer: A transformer-based ap- proach to premise selection
Mikuła, M., Tworkowski, S., Antoniak, S., Piotrowski, B., Jiang, Q., Zhou, J., Szegedy, C., Kuci´nski, Ł., Miło´s, P., and Wu, Y . Magnushammer: A transformer-based ap- proach to premise selection. InInternational Conference on Learning Representations, volume 2024, pp. 39326– 39350,
2024
-
[7]
Generative Language Modeling for Automated Theorem Proving
Polu, S. and Sutskever, I. Generative language model- ing for automated theorem proving.arXiv preprint arXiv:2009.03393,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
M., Zheng, K., Baksys, M., Babuschkin, I., and Sutskever, I
Polu, S., Han, J. M., Zheng, K., Baksys, M., Babuschkin, I., and Sutskever, I. Formal mathematics statement curricu- lum learning.arXiv preprint arXiv:2202.01344,
-
[9]
The Lean Mathematical Library
The mathlib Community. The Lean Mathematical Library. InProceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs, CPP 2020, New Orleans, LA, USA, January
2020
-
[10]
1145/3372885.3373824. URL https://doi.org/ 10.1145/3372885.3373824. Yang, K. and Deng, J. Learning to prove theorems via inter- acting with proof assistants. InInternational Conference on Machine Learning, pp. 6984–6994. PMLR,
-
[11]
9 Geometric Measurements of the Axiom of Choice in Neural Proof Embeddings A. Reproducibility Code, theorem identifiers, dependency-depth labels, data splits, the251-theorem operational sample, and commands to repro- duce every table and figure are available at https://github.com/rodrgo/geometric-axiom-of-choice . All randomness is seeded, and the reposit...
-
[12]
Linear probes.All probes are ℓ2-regularised scikit-learn models with C= 1.0 , L-BFGS solver, 2000 iterations, evaluated by 5-fold cross-validation
For every proof (train and test) we then subtract the fitted prediction ˜ei =e i − ˆα− ˆβℓ i, and pass the residual ˜ei to downstream analyses. Linear probes.All probes are ℓ2-regularised scikit-learn models with C= 1.0 , L-BFGS solver, 2000 iterations, evaluated by 5-fold cross-validation. The domain probe is multinomial LogisticRegression predicting Mat...
2000
-
[13]
If the depth law identifies a frontier in proof methodology, theorems on the far side of that frontier should be harder foraesopto solve
is the standard general-purpose automation in Lean 4, a best-first search over a rule set fixed at compile time. If the depth law identifies a frontier in proof methodology, theorems on the far side of that frontier should be harder foraesopto solve. Sampling and pipeline.We draw up to 60 theorems per bucket (constructive, depth 2, depth 3−4, depth 5−6, d...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.