Agent Safety Is Action Alignment
Pith reviewed 2026-06-30 09:48 UTC · model grok-4.3
The pith
Refusing unsafe outputs cannot secure agents because harm depends on authority relations the model never sees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
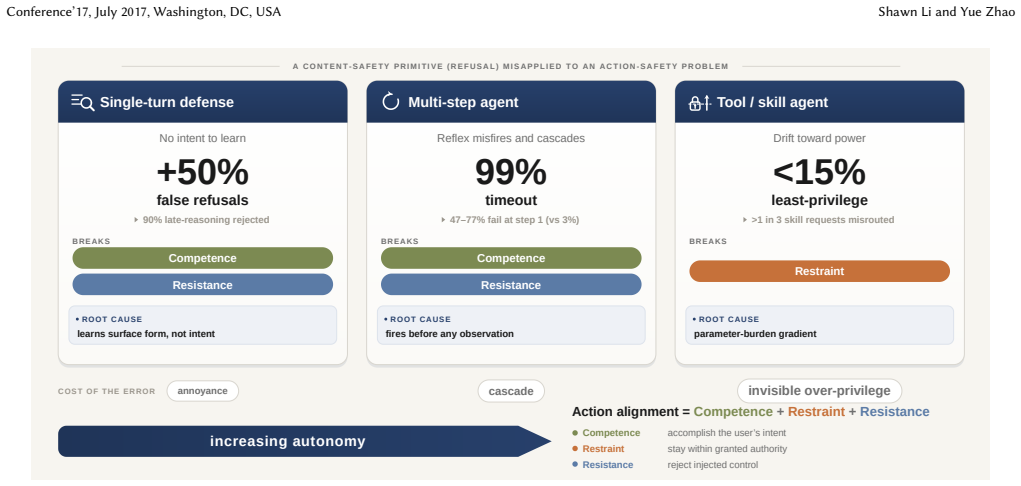
Agentic harm lies in the relation between exercised authority and granted authority, which is absent from the text the model sees and therefore cannot be learned as a function of output; importing refusal training therefore purchases negative security rather than safety.
What carries the argument
The authority relation between action and user grant, enforced by external least-privilege checks at the action boundary rather than by weight-level refusal.
If this is right
- Refusal training will degrade multi-step agent performance before any reduction in authority violations appears.
- Models will remain exploitable by prompts that stay inside the refusal surface but trigger over-privileged actions.
- Undefended frontier models will exceed granted authority in routine use, showing the problem is not solved by scale alone.
- Safety evaluation must shift from refusal scores to measured alignment between actions taken and permissions granted in a given deployment context.
Where Pith is reading between the lines
- Agent runtimes will need explicit permission objects attached to each tool call rather than relying on the model to self-limit.
- Benchmarks should test the same model across different user-granted authority scopes to expose relational failures.
- The approach implies that capability and safety can be decoupled by architecture: larger models can be used if the external boundary is strict.
Load-bearing premise
The relation between exercised authority and user-granted authority cannot be recovered from the text the model receives.
What would settle it
A controlled deployment in which a refusal-trained model is given a sequence of ordinary multi-step tasks and never exceeds the exact authority granted in the initial user prompt, measured without any external runtime checks.
Figures
read the original abstract
Large language models increasingly act as agents: they call tools, move money, delete records, and send messages on a user's behalf. To keep them safe, practitioners imported the chatbot-era recipe (train the model to refuse unsafe inputs) into the agentic setting, and treat the resulting capability loss as a manageable ``alignment tax.'' We argue this is a \emph{category error}. Refusal is a primitive for \emph{content safety}, where the harm is in the model's output and is therefore a learnable function of it. Agentic harm is different in kind: it lies not in any output but in the relation between the authority an action exercises and the authority the user granted, which is absent from the text the model sees. Importing content-safety methods into this regime does not trade capability for safety; it pays capability and buys negative security. We support this with three lines of evidence spanning the autonomy spectrum: defense-trained models learn surface patterns rather than intent; the same training collapses multi-step agents before any threat appears while leaving them exploitable; and even undefended frontier models exceed granted authority under ordinary use. We conclude that action safety cannot be installed in weights. It must be expressed as \emph{least privilege}, enforced \emph{outside} the model at the action boundary, and evaluated as \emph{action alignment} (a relational, deployment-conditioned property) rather than a refusal score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that safety for agentic LLMs cannot be achieved by importing refusal-style training from content-safety regimes. Agentic harm arises from the relational mismatch between the authority an action exercises and the authority the user granted; this relation is absent from the model's observable text, rendering refusal a category error that trades capability for negative security. The claim is supported by three lines of evidence spanning the autonomy spectrum (surface-pattern learning in defense-trained models, premature capability collapse in multi-step agents, and authority overreach in undefended frontier models) and concludes that action safety must instead be realized as externally enforced least privilege and evaluated as action alignment.
Significance. If the core distinction holds, the paper would reorient agent-safety research away from weight-level refusal toward system-level controls, potentially avoiding the capability penalties observed in current practice. The emphasis on relational, deployment-conditioned evaluation rather than refusal scores offers a falsifiable alternative framing that could be tested in deployed agent loops.
major comments (2)
- [Abstract] Abstract: The load-bearing premise that 'the authority an action exercises and the authority the user granted... is absent from the text the model sees' is not isolated from visible context in standard agent architectures. User prompts (which encode granted authority) are routinely supplied as part of the model's observation alongside proposed actions, making the relation potentially expressible as a function of (input, output) pairs. The three lines of evidence do not appear to rule out this possibility or demonstrate that authority scope cannot be learned in the same manner as other prompt-conditioned behaviors.
- [Abstract] Abstract: The manuscript references 'three lines of evidence' but provides no methods, data, or derivations in the supplied text, preventing assessment of whether the experiments control for the presence of authority information in the visible prompt context or merely demonstrate surface-pattern learning unrelated to the relational claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, maintaining the core distinction between content safety and action safety while clarifying the evidence presented.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing premise that 'the authority an action exercises and the authority the user granted... is absent from the text the model sees' is not isolated from visible context in standard agent architectures. User prompts (which encode granted authority) are routinely supplied as part of the model's observation alongside proposed actions, making the relation potentially expressible as a function of (input, output) pairs. The three lines of evidence do not appear to rule out this possibility or demonstrate that authority scope cannot be learned in the same manner as other prompt-conditioned behaviors.
Authors: We disagree on substance. While user prompts may contain textual descriptions of intended authority, the actual authority relation is a deployment-conditioned property defined externally by system policies, permissions, and enforcement boundaries that are not observable in the model's text input. The model receives the prompt and generates actions, but it has no access to the ground-truth scope of granted authority, which exists outside the text. Our three lines of evidence (surface-pattern learning in refusal-trained models, premature collapse in multi-step agents, and authority overreach in frontier models) demonstrate that models do not acquire relational understanding even when authority-related text is present in the prompt; instead, they exhibit prompt-conditioned surface behaviors that fail to prevent overreach. This supports that the relation cannot be reliably learned as a function of (input, output) pairs for safety purposes. revision: partial
-
Referee: [Abstract] Abstract: The manuscript references 'three lines of evidence' but provides no methods, data, or derivations in the supplied text, preventing assessment of whether the experiments control for the presence of authority information in the visible prompt context or merely demonstrate surface-pattern learning unrelated to the relational claim.
Authors: The supplied text was the abstract, which summarizes findings for brevity. The full manuscript details the methods, data, and derivations for each line of evidence, including how prompt context was handled. To address the concern, we will revise the abstract to include a concise high-level overview of the experimental designs and controls for authority information in prompts. revision: yes
Circularity Check
Central distinction between content and action safety asserted definitionally rather than derived
specific steps
-
self definitional
[ABSTRACT]
"Agentic harm is different in kind: it lies not in any output but in the relation between the authority an action exercises and the authority the user granted, which is absent from the text the model sees. Importing content-safety methods into this regime does not trade capability for safety; it pays capability and buys negative security."
The paper defines the nature of agentic harm as a relation absent from input text; this definition immediately entails that any method operating on output (refusal training) cannot address it, rendering the category-error conclusion a direct consequence of the initial framing rather than an independent result.
full rationale
The paper's argument proceeds by defining agentic harm as a relational property absent from model-visible text, which directly entails that output-based refusal methods are a category error. This definitional move carries the central claim without reduction to fitted parameters, equations, or self-citation chains. The three supporting lines of evidence (surface-pattern learning, capability collapse, overreach) are presented as independent but do not alter the load-bearing definitional premise. No other circularity patterns are present; the derivation is self-contained as an argumentative reframing rather than a mathematical or empirical reduction to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agentic harm lies in the relation between exercised authority and user-granted authority, which is absent from the text the model sees.
Reference graph
Works this paper leans on
-
[1]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, et al. 2022. Con- stitutional AI: Harmlessness from AI Feedback.arXiv preprint arXiv:2212.08073 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2025. StruQ: Defending Against Prompt Injection with Structured Queries. In34th USENIX Security Symposium (USENIX Security). 2383–2400
2025
-
[3]
Sihan Chen, Zhuangzhuang Qian, Wingchun Siu, Xingcan Hu, Jiaqi Li, Shawn Li, Yuehan Qin, Tiankai Yang, Zhuo Xiao, Wanghao Ye, Yichi Zhang, Yushun Dong, and Yue Zhao. 2025. PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection. InWWW. 2807–2810
2025
- [4]
- [5]
-
[6]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[7]
Wichmann
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. 2020. Shortcut Learning in Deep Neural Networks.Nature Machine Intelligence2, 11 (2020), 665–673
2020
-
[8]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec). 79–90
2023
-
[9]
Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, et al
Melody Y. Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, et al
- [10]
-
[11]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, et al . 2023. Llama Guard: LLM- Based Input-Output Safeguard for Human-AI Conversations.arXiv preprint arXiv:2312.06674(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [12]
-
[13]
Bobo Li, Hao Fei, Lizi Liao, Yu Zhao, Fangfang Su, Fei Li, and Donghong Ji. 2024. Harnessing Holistic Discourse Features and Triadic Interaction for Sentiment Quadruple Extraction in Dialogues. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), Vol. 38. AAAI Press, 18462–18470. doi:10.1609/aaai. v38i16.29807
-
[14]
Bobo Li, Yuheng Wang, Hao Fei, Juncheng Li, Wei Ji, Mong-Li Lee, and Wynne Hsu. 2025. FormFactory: An Interactive Benchmarking Suite for Multimodal Form-Filling Agents. InProceedings of the 33rd ACM International Conference on Multimedia (MM). ACM, 13273–13280. doi:10.1145/3746027.3758285
-
[15]
"Someone Hid It": Query-Agnostic Black-Box Attacks on LLM-Based Retrieval
Jiate Li, Defu Cao, Li Li, Wei Yang, Yuehan Qin, Chenxiao Yu, Tiannuo Yang, Ryan A. Rossi, Yan Liu, Xiyang Hu, and Yue Zhao. 2026. "Someone Hid It": Query- Agnostic Black-Box Attacks on LLM-Based Retrieval. arXiv:2602.00364 [cs.CR] https://arxiv.org/abs/2602.00364
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Li Li, Peilin Cai, Ryan A. Rossi, Franck Dernoncourt, Branislav Kveton, Junda Wu, Tong Yu, Linxin Song, Tiankai Yang, Yuehan Qin, Nesreen K. Ahmed, Samyadeep Basu, Subhojyoti Mukherjee, Ruiyi Zhang, Zhengmian Hu, Bo Ni, Yuxiao Zhou, Zichao Wang, Yue Huang, Yu Wang, Xiangliang Zhang, Philip S. Yu, Xiyang Hu, and Yue Zhao. 2025. A Personalized Conversationa...
-
[17]
Shawn Li, Peilin Cai, Yuxiao Zhou, Zhiyu Ni, Renjie Liang, You Qin, Yi Nian, Zhengzhong Tu, Xiyang Hu, and Yue Zhao. 2025. Secure On-Device Video OOD Detection Without Backpropagation. InICCV
2025
-
[18]
Shawn Li, Huixian Gong, Hao Dong, Tiankai Yang, Zhengzhong Tu, and Yue Zhao
-
[19]
DPU: Dynamic Prototype Updating for Multimodal Out-of-Distribution Detection. InCVPR. 10193–10202
-
[20]
Shawn Li, You Qin, Jiate Li, Charith Peris, Lisa Bauer, Roger Zimmermann, and Yue Zhao. 2026. Geometry over Density: Few-Shot Cross-Domain OOD Detection. arXiv:2605.03410 [cs.AI] https://arxiv.org/abs/2605.03410
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [21]
-
[22]
FORTIS: Benchmarking Over-Privilege in Agent Skills
Shawn Li, Chenxiao Yu, Han Wang, Wei Yang, Ryan A. Rossi, Franck Dernoncourt, Xiyang Hu, Philip Yu, Chaowei Xiao, Huan Zhang, and Yue Zhao. 2026. FORTIS: Benchmarking Over-Privilege in Agent Skills.arXiv preprint arXiv:2605.09163 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Shawn Li and Yue Zhao. 2026. The Autonomy Tax: Defense Training Breaks LLM Agents.arXiv preprint arXiv:2603.19423(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [24]
-
[25]
Runzhou Liu, Hailey Weingord, Sejal Mittal, Prakhar Dungarwal, Anusha Nan- dula, Bo Ni, Samyadeep Basu, Hongjie Chen, Nesreen K. Ahmed, Li Li, Jiayi Zhang, Koustava Goswami, Subhojyoti Mukherjee, Branislav Kveton, Puneet Mathur, Franck Dernoncourt, Yue Zhao, Yu Wang, Ryan A. Rossi, Zhengzhong Tu, and Hongru Du. 2026. Human-Aligned MLLM Judges for Fine-Gra...
-
[26]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. In33rd USENIX Security Symposium (USENIX Security). 1831–1847
2024
- [27]
-
[28]
Bo Ni, Yu Wang, Leyao Wang, Branislav Kveton, Franck Dernoncourt, Yu Xia, Hongjie Chen, Reuben Luera, Samyadeep Basu, Subhojyoti Mukherjee, Puneet Mathur, Nesreen K. Ahmed, Junda Wu, Li Li, Huixin Zhang, Ruiyi Zhang, Tong Yu, Sungchul Kim, Jiuxiang Gu, Zhengzhong Tu, Alexa Siu, Zichao Wang, Seunghyun Yoon, Nedim Lipka, Namyong Park, Zihao Lin, Trung Bui, ...
2026
-
[29]
Yi Nian, Aojie Yuan, Haiyue Zhang, Jiate Li, and Yue Zhao. 2026. Auditable Agents.arXiv preprint arXiv:2604.05485(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Yi Nian, Shenzhe Zhu, Yuehan Qin, Li Li, Ziyi Wang, Chaowei Xiao, and Yue Zhao
-
[31]
Jaildam: Jailbreak detection with adaptive memory for vision-language model, 2025
JailDAM: Jailbreak Detection with Adaptive Memory for Vision-Language Model. arXiv:2504.03770 [cs.CR] https://arxiv.org/abs/2504.03770
-
[32]
Long Ouyang, Jeffrey Wu, Xu Jiang, et al. 2022. Training Language Models to Follow Instructions with Human Feedback. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
- [33]
-
[34]
Yuehan Qin, Shawn Li, Yi Nian, Xinyan Velocity Yu, Yue Zhao, and Xuezhe Ma
-
[35]
arXiv:2504.06438 [cs.CL] https://arxiv.org/abs/2504.06438
Don’t Let It Hallucinate: Premise Verification via Retrieval-Augmented Logical Reasoning. arXiv:2504.06438 [cs.CL] https://arxiv.org/abs/2504.06438
-
[36]
Saltzer and Michael D
Jerome H. Saltzer and Michael D. Schroeder. 1975. The Protection of Information in Computer Systems.Proc. IEEE63, 9 (1975), 1278–1308
1975
-
[37]
Li Shawn, Jiashu Qu, Linxin Song, Yuxiao Zhou, Yuehan Qin, Tiankai Yang, and Yue Zhao. 2025. Treble Counterfactual VLMs: A Causal Approach to Hallucina- tion. InEMNLP
2025
-
[38]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable Privilege Control for LLM Agents. arXiv preprint arXiv:2504.11703(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Linxin Song, Yutong Dai, Viraj Prabhu, Jieyu Zhang, Taiwei Shi, Li Li, Jun- nan Li, Silvio Savarese, Zeyuan Chen, Jieyu Zhao, Ran Xu, and Caiming Xiong
-
[40]
Coact-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
CoAct-1: Computer-using Multi-Agent System with Coding Actions. arXiv:2508.03923 [cs.CL] https://arxiv.org/abs/2508.03923
-
[41]
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. 2024. The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions.arXiv preprint arXiv:2404.13208(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Rossi, Kaize Ding, Xia Hu, and Yue Zhao
Tiankai Yang, Yi Nian, Li Li, Ruiyao Xu, Yuangang Li, Jiaqi Li, Zhuo Xiao, Xiyang Hu, Ryan A. Rossi, Kaize Ding, Xia Hu, and Yue Zhao. 2025. AD-LLM: Bench- marking Large Language Models for Anomaly Detection. InACL. 1524–1547
2025
-
[43]
Ruijie Ye, Jiayi Zhang, Zhuoxin Liu, Zihao Zhu, Siyuan Yang, Li Li, Tianfu Fu, Franck Dernoncourt, Yue Zhao, Jiacheng Zhu, Ryan Rossi, Wenhao Chai, and Zhengzhong Tu. 2026. Agent Banana: High-Fidelity Image Editing with Agentic Thinking and Tooling. arXiv:2602.09084 [cs.CV] https://arxiv.org/abs/2602.09084
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.