Four Types of LLM Reliance and Their Predictors Among Undergraduate Writers: A Mixed-Methods Study at a Minority-Serving R1 University
Pith reviewed 2026-06-30 08:45 UTC · model grok-4.3
The pith
Undergraduates rely on LLMs for writing in four distinct ways, with AI literacy shaping the type chosen and value-cost beliefs shaping intensity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
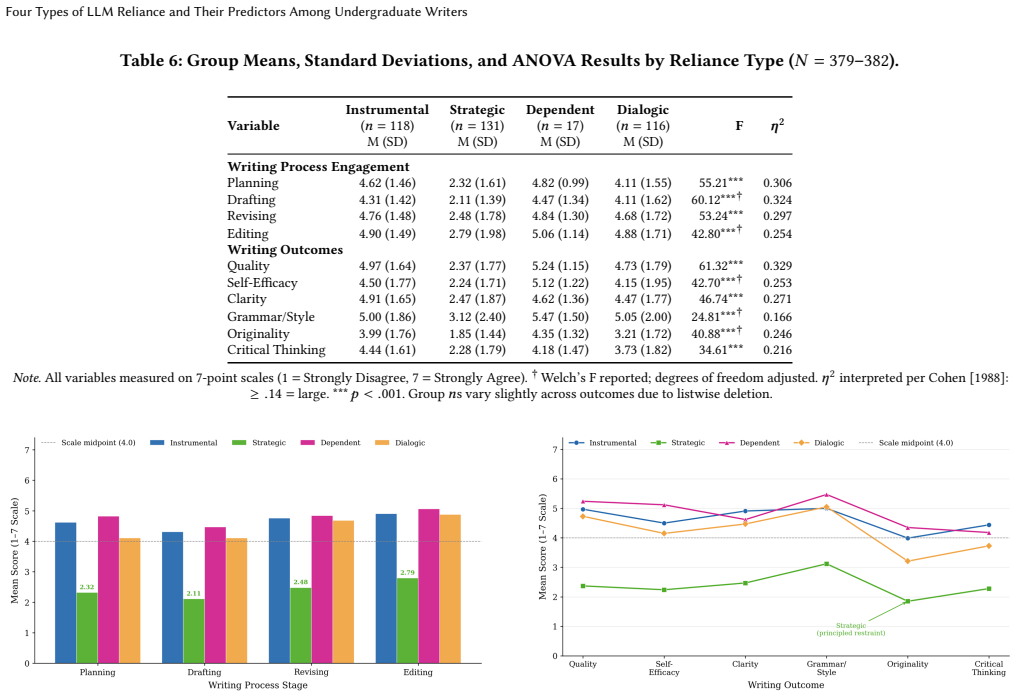
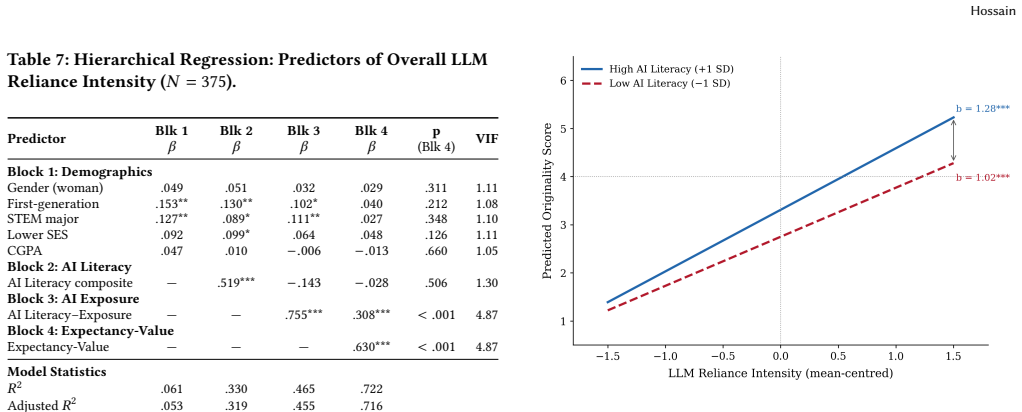
Four qualitatively distinct reliance types on LLMs were identified and validated: Strategic (34.3%), Instrumental (30.9%), Dialogic (30.4%), and Dependent (4.5%). AI literacy predicted the type of reliance adopted, whereas value and cost beliefs predicted reliance intensity. Strategic users received the lowest scores on conventional writing assessments, revealing that those instruments measure AI contribution rather than writing quality. Existing frameworks overlook roughly 13% of students who decline AI use on ethical grounds.
What carries the argument
The four-type classification of LLM reliance (Strategic, Instrumental, Dialogic, Dependent), derived from mixed-methods analysis using the AI Literacy Framework, Expectancy-Value Theory, and Biggs's Presage-Process-Product model.
If this is right
- Differentiated support is needed for each reliance type rather than uniform AI literacy training.
- Standard writing outcome measures must change to credit independent student contribution instead of AI assistance.
- AI policies at minority-serving institutions should separately address students who avoid LLMs for ethical reasons.
- Changing students' perceptions of value and cost can alter the intensity of LLM reliance.
- Strategic reliance produces the most independent work yet is penalized by existing assessments.
Where Pith is reading between the lines
- The four-type model could guide targeted classroom interventions that shift students toward strategic rather than dependent patterns.
- Ethical non-users may require distinct policy protections not captured by current AI literacy programs.
- Objective process-tracing methods, such as version histories of student documents, could test whether the self-reported types align with actual writing behaviors.
- The distribution of types may vary by institutional resources or student demographics, suggesting the need for multi-site validation.
Load-bearing premise
The study assumes that self-reported data from one minority-serving R1 university can reliably distinguish four qualitatively distinct reliance types that generalize to other settings and that current theoretical frameworks suffice to separate them.
What would settle it
Replicating the mixed-methods protocol at a different type of institution and obtaining either a different number of types or no link between AI literacy and type would undermine the central classification.
Figures

read the original abstract
Although most undergraduates now use large language models (LLMs), a form of generative artificial intelligence (GenAI) for academic writing, no validated method distinguishes the qualitatively different ways students rely on them. Existing instruments assess reliance solely by frequency of use, a measure that, as this study shows, inadvertently rewards dependence on AI rather than recognizing students' own intellectual contribution. Conducted at a public minority-serving university and grounded in the AI Literacy Framework, Expectancy-Value Theory, and Biggs's Presage-Process-Product model, the study drew on 382 undergraduates, 14 interviews, and 396 open-ended survey responses. Four distinct reliance types were identified and confirmed: Strategic (34.3%), Instrumental (30.9%), Dialogic (30.4%), and Dependent (4.5%). Students' value and cost beliefs predicted the intensity of their reliance on LLMs, whereas their AI literacy predicted the type of reliance they adopted, indicating that differentiated support is needed. Notably, Strategic users, those who engaged AI most deliberately, scored lowest on standard outcome measures. This pattern reflects a limitation of current instruments, which index AI's contribution rather than writing quality, thereby penalizing students who show the greatest independent thinking. Analysis also revealed an additional group, roughly 13%, who declined to use AI for ethical rather than practical reasons, and who existing frameworks overlook. These findings carry implications for AI literacy programs, the measurement of student learning outcomes, and equitable AI policy at minority-serving institutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a mixed-methods study of 382 undergraduates at a minority-serving R1 university, drawing on surveys, 14 interviews, and 396 open-ended responses. Grounded in the AI Literacy Framework, Expectancy-Value Theory, and Biggs's Presage-Process-Product model, it identifies and confirms four reliance types on LLMs for academic writing—Strategic (34.3%), Instrumental (30.9%), Dialogic (30.4%), and Dependent (4.5%)—finding that value and cost beliefs predict reliance intensity while AI literacy predicts type. It highlights limitations in standard outcome measures that index AI contribution rather than independent quality and notes an additional ~13% group avoiding AI for ethical reasons.
Significance. If the typology is shown to be robust, the work would advance differentiated understanding of LLM use in academic writing, with particular value for AI literacy programs and equitable policy at minority-serving institutions. The mixed-methods design, attention to measurement limitations in AI writing assessment, and identification of ethical non-users are strengths that address gaps in frequency-only instruments.
major comments (3)
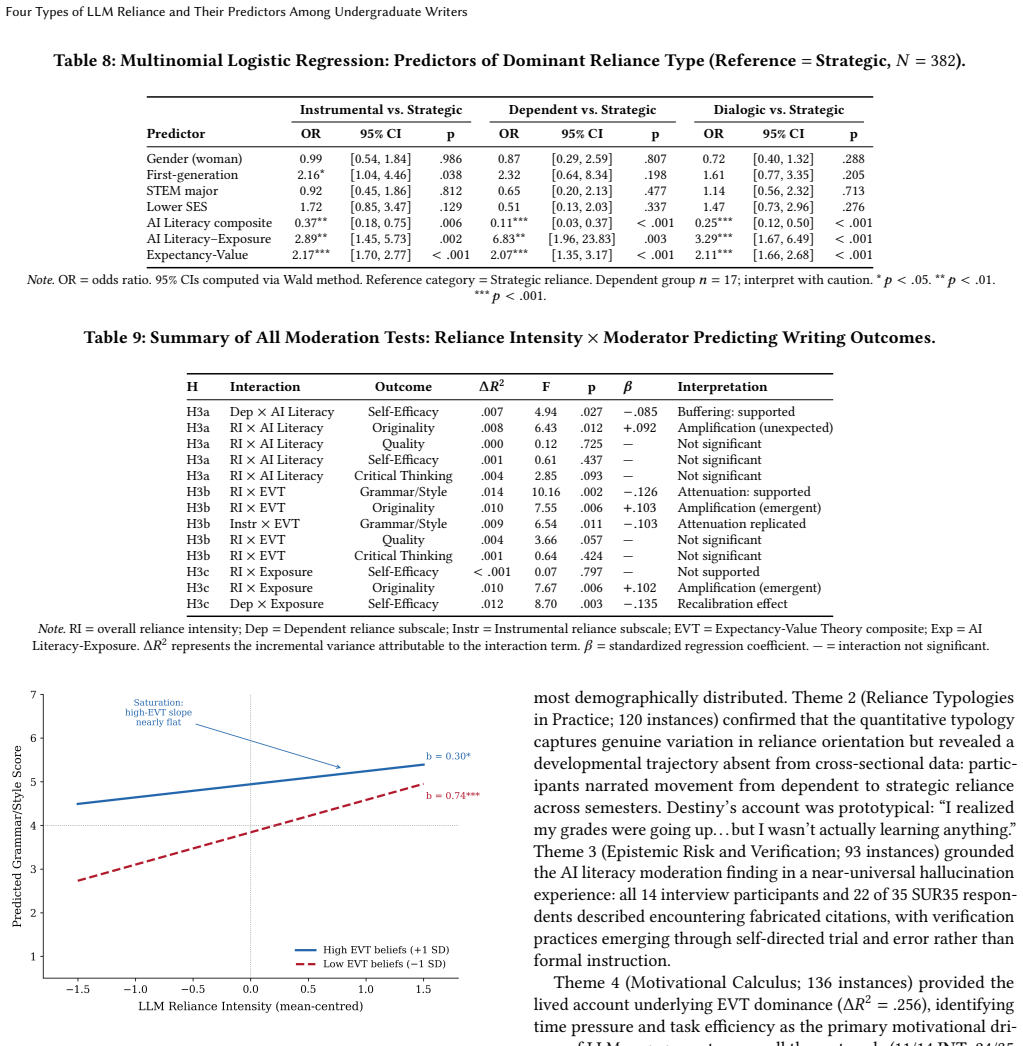
- [Methods (thematic analysis and type assignment)] The central claim that four qualitatively distinct reliance types were identified and confirmed rests on thematic analysis of 14 interviews plus 396 open-ended responses, yet no inter-rater reliability metrics (e.g., Cohen’s kappa), member-checking, or quantitative confirmation (e.g., latent class analysis or factor structure on survey items) are reported. This validation gap is load-bearing for the distinctness and reliability of the Strategic/Instrumental/Dialogic/Dependent categories.
- [Results (predictors of intensity and type)] Self-reported value/cost beliefs and AI literacy are used both to derive the reliance types and as predictors of type and intensity; this shared data source creates a circularity risk that is not addressed with independent validation or triangulation. The same self-report logic flagged as problematic for outcome measures is applied to the typology without discussion of social-desirability or recall bias.
- [Discussion and Abstract] The sample is drawn from a single minority-serving R1 university; the manuscript does not sufficiently discuss limits on generalizability of the four-type structure or the predictor relationships, despite the abstract advancing claims about differentiated support needs and outcome-measurement limitations.
minor comments (2)
- [Results] A summary table listing defining characteristics, example quotes, and prevalence for each of the four reliance types would improve clarity and allow readers to assess distinctness directly.
- [Abstract] The abstract states the four types sum to 100% while separately noting a 13% ethical non-user group; clarify whether the latter overlaps with the 382-student sample or is excluded from type assignment.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Methods (thematic analysis and type assignment)] The central claim that four qualitatively distinct reliance types were identified and confirmed rests on thematic analysis of 14 interviews plus 396 open-ended responses, yet no inter-rater reliability metrics (e.g., Cohen’s kappa), member-checking, or quantitative confirmation (e.g., latent class analysis or factor structure on survey items) are reported. This validation gap is load-bearing for the distinctness and reliability of the Strategic/Instrumental/Dialogic/Dependent categories.
Authors: We agree that additional validation details would strengthen the manuscript. In the revision, we will include inter-rater reliability metrics (Cohen’s kappa) calculated from the dual coding of a subset of the open-ended responses. Member checking was not performed, as the study design involved single interviews and anonymous surveys; we will add this as an explicit limitation. For quantitative confirmation, the typology was developed through iterative thematic analysis and then applied to classify the full sample using the open responses; we will add a description of how the survey items on reliance behaviors were used to triangulate the types, and note that a full latent class analysis is beyond the current scope but could be pursued in future work. revision: partial
-
Referee: [Results (predictors of intensity and type)] Self-reported value/cost beliefs and AI literacy are used both to derive the reliance types and as predictors of type and intensity; this shared data source creates a circularity risk that is not addressed with independent validation or triangulation. The same self-report logic flagged as problematic for outcome measures is applied to the typology without discussion of social-desirability or recall bias.
Authors: The reliance types were derived solely from qualitative thematic analysis of interviews and open-ended responses, while the value/cost beliefs and AI literacy were measured using distinct quantitative survey scales. These were then used to predict the qualitatively assigned types and intensity in regression analyses. This design avoids direct circularity. Nevertheless, we recognize the value of discussing potential biases in self-report data and will expand the limitations section to address social-desirability and recall bias in both the outcome measures and the predictor variables. revision: yes
-
Referee: [Discussion and Abstract] The sample is drawn from a single minority-serving R1 university; the manuscript does not sufficiently discuss limits on generalizability of the four-type structure or the predictor relationships, despite the abstract advancing claims about differentiated support needs and outcome-measurement limitations.
Authors: We concur that the generalizability discussion requires expansion. The revised manuscript will include a more thorough treatment of the single-site limitation in the Discussion, including how the minority-serving context may influence the observed patterns and the need for replication at other institutions. We will also revise the abstract to qualify the claims about differentiated support needs as preliminary and context-specific. revision: yes
Circularity Check
No circularity: empirical mixed-methods study with independent data sources for typology and predictors.
full rationale
The paper conducts a mixed-methods empirical investigation using survey responses, interviews, and open-ended text to identify reliance types via thematic analysis and then test predictors (value/cost beliefs, AI literacy) drawn from the same sample but analyzed as separate variables. No equations, parameter fitting presented as prediction, self-definitional constructs, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on qualitative coding and statistical associations rather than any reduction of outputs to inputs by construction, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard assumptions of survey validity and reliability in social science research hold for self-reported LLM use.
- domain assumption The AI Literacy Framework, Expectancy-Value Theory, and Biggs's Presage-Process-Product model are appropriate for classifying reliance types.
invented entities (1)
-
Four reliance types (Strategic, Instrumental, Dialogic, Dependent)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aiken and Stephen G
Leona S. Aiken and Stephen G. West. 1991.Multiple Regression: Testing and Interpreting Interactions. Sage, Newbury Park, CA. Laura K. Allen and Panayiota Kendeou
1991
-
[2]
ED-AI Lit: An Interdisciplinary Frame- work for AI Literacy in Education.Policy Insights from the Behavioral and Brain Sciences11, 1 (2024), 3–10. doi:10.1177/23727322231220339 16 Four Types of LLM Reliance and Their Predictors Among Undergraduate Writers Albert Bandura. 1997.Self-Efficacy: The Exercise of Control. W. H. Freeman, New York, NY. Karley Beck...
-
[3]
doi:10.1016/j.iheduc.2025.101036 Carl Bereiter and Marlene Scardamalia
The GenAI Divide Among University Stu- dents: A Call for Action.The Internet and Higher Education67 (2025), 101036. doi:10.1016/j.iheduc.2025.101036 Carl Bereiter and Marlene Scardamalia. 1987.The Psychology of Written Composition. Lawrence Erlbaum Associates, Hillsdale, NJ. John B. Biggs
-
[4]
Higher Education Research & Development12, 1 (1993), 73–85
From Theory to Practice: A Cognitive Systems Approach. Higher Education Research & Development12, 1 (1993), 73–85. doi:10.1080/ 0729436930120107 Ivar Bråten, Ymkje E. Haverkamp, Natalia Latini, and Helge I. Strømsø
1993
-
[5]
doi:10.3389/fpsyg.2023.1212567 Virginia Braun and Victoria Clarke
Measuring Multiple-Source Based Academic Writing Self-Efficacy.Frontiers in Psychology14 (2023), 1212567. doi:10.3389/fpsyg.2023.1212567 Virginia Braun and Victoria Clarke
-
[6]
Qualitative Research in Sport, Exercise and Health11, 4 (2019), 589–597
Reflecting on Reflexive Thematic Analysis. Qualitative Research in Sport, Exercise and Health11, 4 (2019), 589–597. doi:10.1080/ 2159676X.2019.1628806 Roger Bruning, Michael Dempsey, Douglas F. Kauffman, Courtney McKim, and Sharon Zumbrunn
-
[7]
Examining Dimensions of Self-Efficacy for Writing.Journal of Educational Psychology105, 1 (2013), 25–38. doi:10.1037/a0029692 Sahan Bulathwela, María Pérez-Ortiz, Catherine Holloway, Mutlu Cukurova, and John Shawe-Taylor
-
[8]
Artificial Intelligence Alone Will Not Democratise Education: On Educational Inequality, Techno-Solutionism and Inclusive Tools.Sustainability 16, 2 (2024),
2024
-
[9]
doi:10.3390/su16020781 Cecilia Ka Yuk Chan and Wenjie Zhou
-
[10]
An Expectancy Value Theory (EVT) Based Instrument for Measuring Student Perceptions of Generative AI.Smart Learning Environments10, 1 (2023),
2023
-
[11]
doi:10.1186/s40561-023-00284-4 Fang Fang Chen
-
[12]
doi:10.1080/10705510701301834 Jacob Cohen
Sensitivity of Goodness-of-Fit Indexes to Lack of Measurement Invariance.Structural Equation Modeling: A Multidisciplinary Journal14, 3 (2007), 464–504. doi:10.1080/10705510701301834 Jacob Cohen. 1988.Statistical Power Analysis for the Behavioral Sciences(2 ed.). Lawrence Erlbaum Associates, Hillsdale, NJ. Debby R. E. Cotton, Peter A. Cotton, and J. Reube...
-
[13]
Chatting and Cheating: Ensuring Academic Integrity in the Era of ChatGPT.Innovations in Education and Teaching International61, 2 (2024), 228–239. doi:10.1080/14703297. 2023.2190148 John W. Creswell and Vicki L. Plano Clark. 2018.Designing and Conducting Mixed Methods Research(3 ed.). Sage, Thousand Oaks, CA. Sarah Elaine Eaton
-
[14]
Postplagiarism: Transdisciplinary Ethics and Integrity in the Age of Artificial Intelligence and Neurotechnology.International Journal for Educational Integrity19, 1 (2023),
2023
-
[15]
doi:10.1007/s40979-023-00144-1 Sarah Elaine Eaton
-
[16]
Global Trends in Education: Artificial Intelligence, Postpla- giarism, and Future-Focused Learning for 2025 and Beyond.International Journal for Educational Integrity21, 1 (2025),
2025
-
[17]
doi:10.1007/s40979-025-00187-6 Yizhou Fan, Luzhen Tang, Huixiao Le, Kejie Shen, Shubham Tan, Yueying Zhao, Yuan Shen, Xinyu Li, and Dragan Gašević
-
[18]
doi:10.1111/bjet.13544 Franz Faul, Edgar Erdfelder, Albert-Georg Lang, and Axel Buchner
Beware of Metacognitive Laziness: Effects of Generative Artificial Intelligence on Learning Motivation, Processes, and Performance.British Journal of Educational Technology56, 2 (2025), 489–530. doi:10.1111/bjet.13544 Franz Faul, Edgar Erdfelder, Albert-Georg Lang, and Axel Buchner
-
[19]
doi:10.3758/ BF03193146 Michael D
G*Power 3: A Flexible Statistical Power Analysis Program for the Social, Behavioral, and Biomedical Sciences.Behavior Research Methods39, 2 (2007), 175–191. doi:10.3758/ BF03193146 Michael D. Fetters, Leslie A. Curry, and John W. Creswell
2007
-
[20]
doi:10.1111/1475-6773.12117 Linda Flower and John R
Achieving Integration in Mixed Methods Designs—Principles and Practices.Health Services Research48, 6pt2 (2013), 2134–2156. doi:10.1111/1475-6773.12117 Linda Flower and John R. Hayes
-
[21]
doi:10.2307/356600 Josh Freeman
A Cognitive Process Theory of Writing.College Composition and Communication32, 4 (1981), 365–387. doi:10.2307/356600 Josh Freeman. 2025.Student Generative AI Survey
-
[22]
Higher Education Policy Institute and Kortext
Technical Report. Higher Education Policy Institute and Kortext. https://www.hepi.ac.uk/reports/student- generative-ai-survey-2025/ Michael Gerlich
2025
-
[23]
AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking.Societies15, 1 (2025),
2025
-
[24]
doi:10.3390/soc15010006 Imogen Gilburt
-
[25]
A Machine in the Loop: The Peculiar Intervention of Artificial Intelligence in Writer’s Block.New Writing21, 1 (2024), 26–37. doi:10.1080/14790726. 2023.2223176 Steve Graham and Karen R. Harris
-
[26]
doi:10.1207/S15326985EP3501_2 Jörg Henseler, Christian M
The Role of Self-Regulation and Transcription Skills in Writing and Writing Development.Educational Psychologist35, 1 (2000), 3–12. doi:10.1207/S15326985EP3501_2 Jörg Henseler, Christian M. Ringle, and Marko Sarstedt
-
[27]
Journal of the Academy of Marketing Science43, 1 (2015), 115–135
A New Criterion for Assessing Discriminant Validity in Variance-Based Structural Equation Modeling. Journal of the Academy of Marketing Science43, 1 (2015), 115–135. doi:10.1007/ s11747-014-0403-8 Franziska Kinskofer and Maria Tulis
2015
-
[28]
doi:10.3389/feduc.2025.1677827 Jon Kleinberg and Manish Raghavan
Motivational and Appraisal Factors Shap- ing Generative AI Use and Intention in Austrian Higher Education Students and Teachers.Frontiers in Education10 (2025), 1677827. doi:10.3389/feduc.2025.1677827 Jon Kleinberg and Manish Raghavan
-
[29]
doi:10.1073/pnas.2018340118 Alexander K
Algorithmic Monoculture and Social Welfare.Proceedings of the National Academy of Sciences118, 22 (2021), e2018340118. doi:10.1073/pnas.2018340118 Alexander K. Kofinas, Crystal H.-H. Tsay, and David Pike
-
[30]
The Impact of Gener- ative AI on Academic Integrity of Authentic Assessments Within a Higher Edu- cation Context.British Journal of Educational Technology56, 6 (2025), 2522–2549. doi:10.1111/bjet.13585 Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes
-
[31]
Your Brain on ChatGPT: Accumulation of Cognitive Debt When Using an AI Assistant for Essay Writing Task. arXiv preprint. doi:10.48550/arXiv.2506.08872 Weixin Liang, Mert Yuksekgonul, Yining Mao, Eric Wu, and James Zou
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.08872
-
[32]
doi:10.1016/j.patter.2023.100779 Yvonna S
GPT Detectors Are Biased Against Non-Native English Writers.Patterns4, 7 (2023), 100779. doi:10.1016/j.patter.2023.100779 Yvonna S. Lincoln and Egon G. Guba. 1985.Naturalistic Inquiry. Sage, Newbury Park, CA. Tomáš Lintner
-
[33]
A Systematic Review of AI Literacy Scales.npj Science of Learning 9, 1 (2024),
2024
-
[34]
doi:10.1038/s41539-024-00264-4 Roderick J. A. Little
- [35]
-
[36]
InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems
What Is AI Literacy? Competencies and Design Considerations. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA, 1–16. doi:10.1145/3313831.3376727 Mary R. Lynn
-
[37]
doi:10.1097/00006199-198611000-00017 Kibum Moon, Adam E
Determination and Quantification of Content Validity.Nursing Research35, 6 (1986), 382–386. doi:10.1097/00006199-198611000-00017 Kibum Moon, Adam E. Green, and Kostadin Kushlev
-
[38]
doi:10.1016/j.chbah.2025.100207 David L
Homogenizing Effect of Large Language Models (LLMs) on Creative Diversity: An Empirical Comparison of Human and ChatGPT Writing.Computers in Human Behavior: Artificial Humans 6 (2025), 100207. doi:10.1016/j.chbah.2025.100207 David L. Morgan
-
[39]
Pragmatism as a Paradigm for Social Research.Qualitative Inquiry20, 8 (2014), 1045–1053. doi:10.1177/1077800413513733 Davy Tsz Kit Ng, Jac Ka Lok Leung, Samuel Kai Wah Chu, and Maggie Shen Qiao
-
[40]
doi:10.1016/j.caeai.2021.100041 Shakked Noy and Whitney Zhang
Conceptualizing AI Literacy: An Exploratory Review.Computers and Education: Artificial Intelligence2 (2021), 100041. doi:10.1016/j.caeai.2021.100041 Shakked Noy and Whitney Zhang
-
[41]
doi:10.1126/science.adh2586 Office of Institutional Research
Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence.Science381, 6654 (2023), 187–192. doi:10.1126/science.adh2586 Office of Institutional Research
-
[42]
InThe Twelfth International Conference on Learning Representa- tions (ICLR)
Does Writing with Language Models Reduce Content Diversity?. InThe Twelfth International Conference on Learning Representa- tions (ICLR). doi:10.48550/arXiv.2309.05196 Postsecondary National Policy Institute
-
[43]
doi:10.1016/j.dr.2016.06.004 Gregory Schraw and Rayne Sperling Dennison
Measurement Invariance Conven- tions and Reporting: The State of the Art and Future Directions for Psychological Research.Developmental Review41 (2016), 71–90. doi:10.1016/j.dr.2016.06.004 Gregory Schraw and Rayne Sperling Dennison
-
[44]
Assessing Metacognitive Aware- ness.Contemporary Educational Psychology19, 4 (1994), 460–475. doi:10.1006/ceps. 1994.1033 Kenneth S. Shultz, David J. Whitney, and Michael J. Zickar. 2014.Measurement Theory in Action: Case Studies and Exercises(2 ed.). Routledge, New York, NY. doi:10.4324/ 9781315869834 Barbara G. Tabachnick and Linda S. Fidell. 2019.Using...
-
[45]
doi:10.1016/j.heliyon.2024.e34262 Pamela Tierney and Steven M
Harnessing LLMs for Multi-Dimensional Writing Assessment: Reliability and Alignment With Human Judgments.Heliyon10, 14 (2024), e34262. doi:10.1016/j.heliyon.2024.e34262 Pamela Tierney and Steven M. Farmer
-
[46]
Creative Self-Efficacy: Its Potential Antecedents and Relationship to Creative Performance.Academy of Management Journal45, 6 (2002), 1137–1148. doi:10.2307/3069429 Lev S. Vygotsky. 1978.Mind in Society: The Development of Higher Psychological Processes. Harvard University Press, Cambridge, MA. Mark Warschauer, Waverly Tseng, Soobin Yim, Thomas Webster, S...
-
[47]
doi:10.1016/j.jslw.2023.101071 C
The Affordances and Contradictions of AI-Generated Text for Writers of English as a Second or Foreign Language.Journal of Second Language Writing62 (2023), 101071. doi:10.1016/j.jslw.2023.101071 C. Edward Watson and Lee Rainie. 2025.Leading Through Disruption: Higher Education Executives Assess AI’s Impacts on Teaching and Learning. Technical Report. Amer...
-
[48]
Testing of Detection Tools for AI-Generated Text.International Journal for Educational Integrity19 (2023),
2023
-
[49]
doi:10.1007/s40979-023-00146-z Allan Wigfield and Jacquelynne S. Eccles
-
[50]
doi:10.1006/ceps.1999.1015 Chunpeng Zhai, Santoso Wibowo, and Lily D
Expectancy–Value Theory of Achieve- ment Motivation.Contemporary Educational Psychology25, 1 (2000), 68–81. doi:10.1006/ceps.1999.1015 Chunpeng Zhai, Santoso Wibowo, and Lily D. Li
-
[51]
Smart Learning Environments11, 1 (2024),
The Effects of Over-Reliance on AI Dialogue Systems on Students’ Cognitive Abilities: A Systematic Review. Smart Learning Environments11, 1 (2024),
2024
-
[52]
All content was reviewed and verified by the author
doi:10.1186/s40561-024-00316-7 Generative AI Usage Statement The author occasionally used Claude (Anthropic, models Sonnet 4.6 and Opus 4.8) for grammar checking of passages, table formatting, and copy editing of the manuscript. All content was reviewed and verified by the author. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.