The Heterogeneous Safety Impacts of Benign Multilingual Fine-Tuning
Pith reviewed 2026-06-30 09:50 UTC · model grok-4.3
The pith
Fine-tuning LLMs with benign data in different languages leads to highly variable safety outcomes depending on the languages chosen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
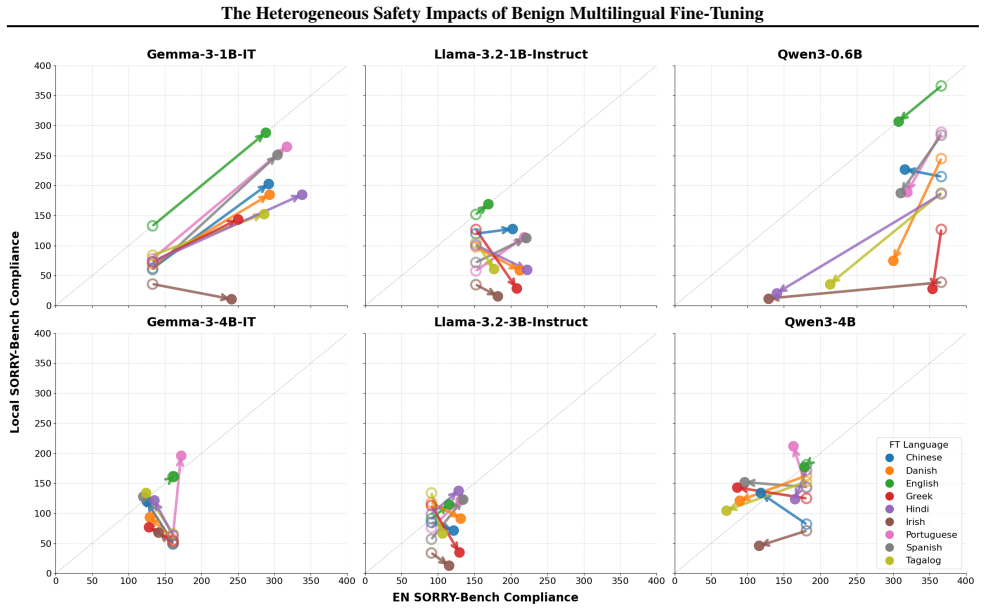
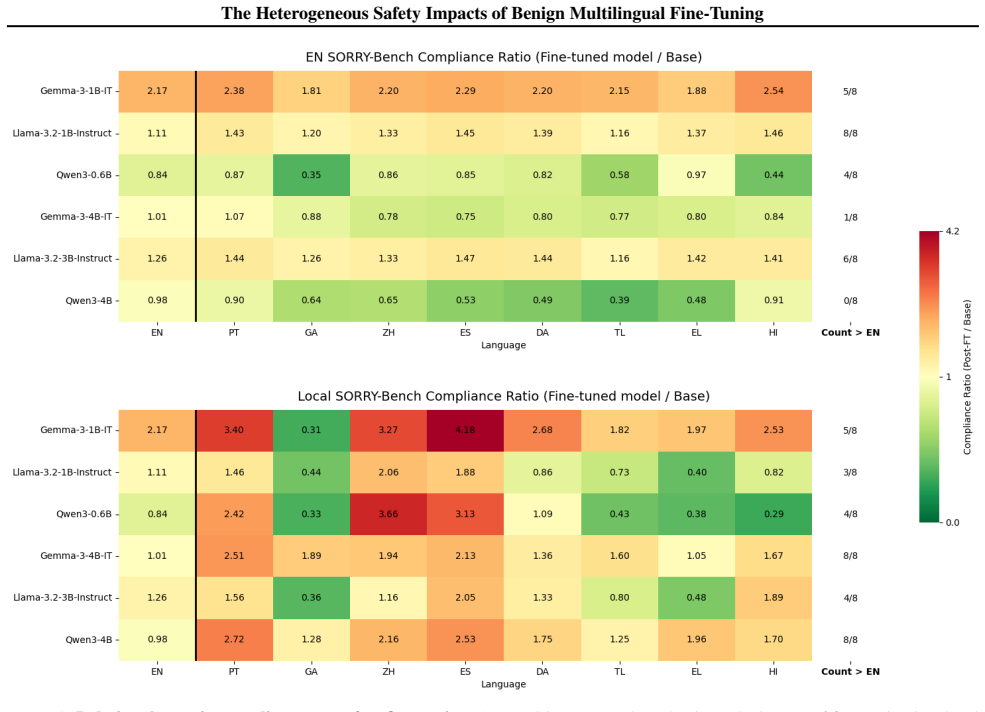
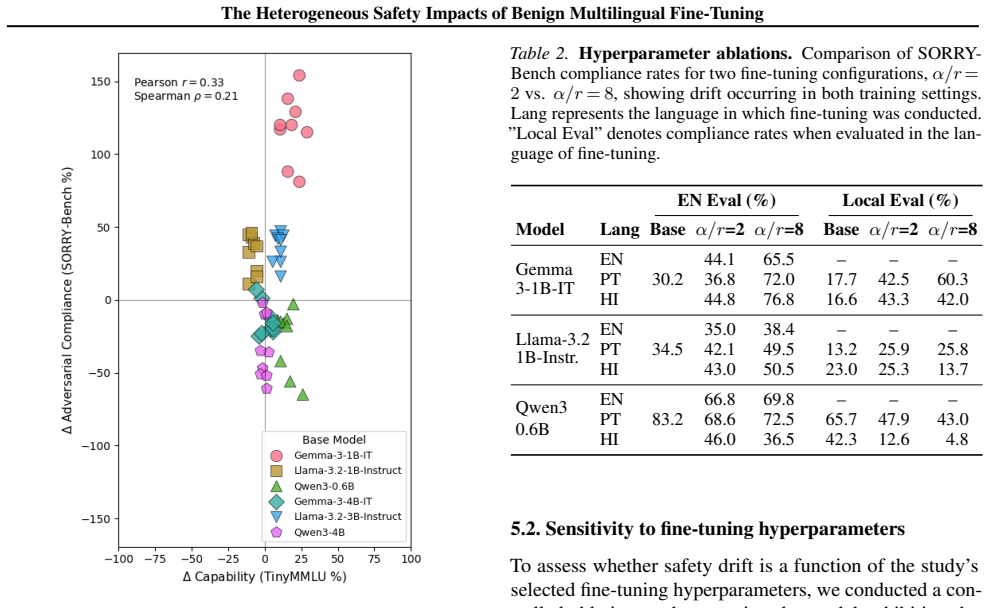
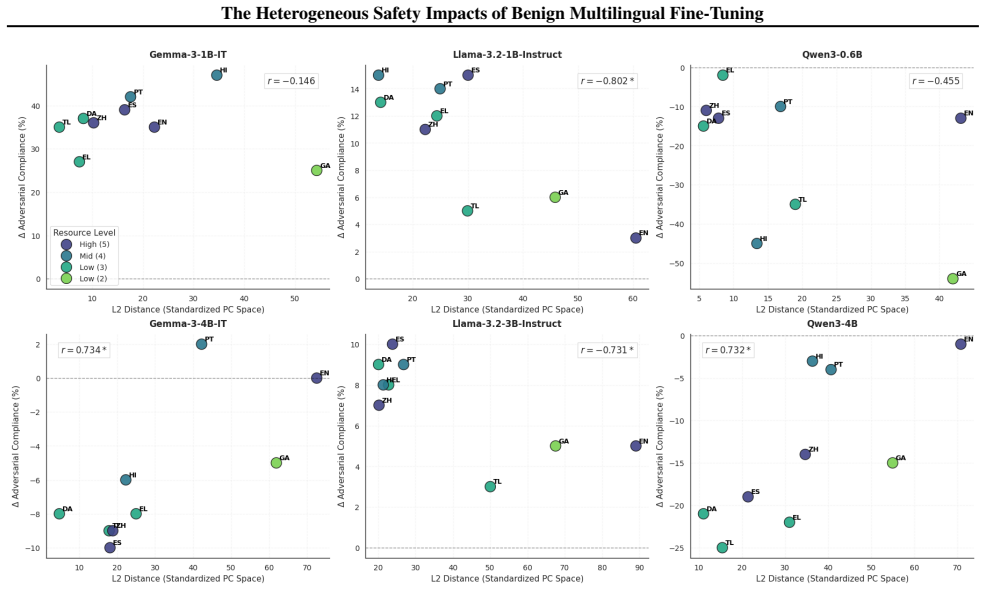
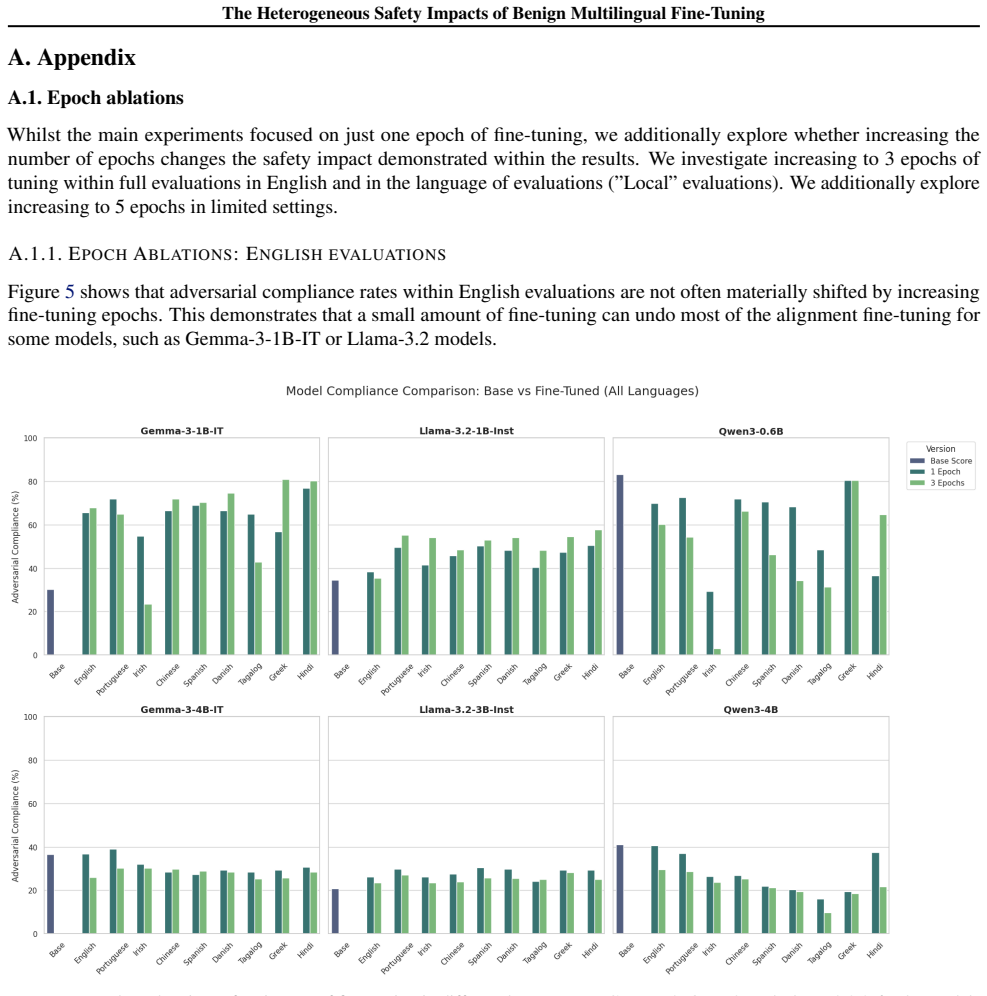
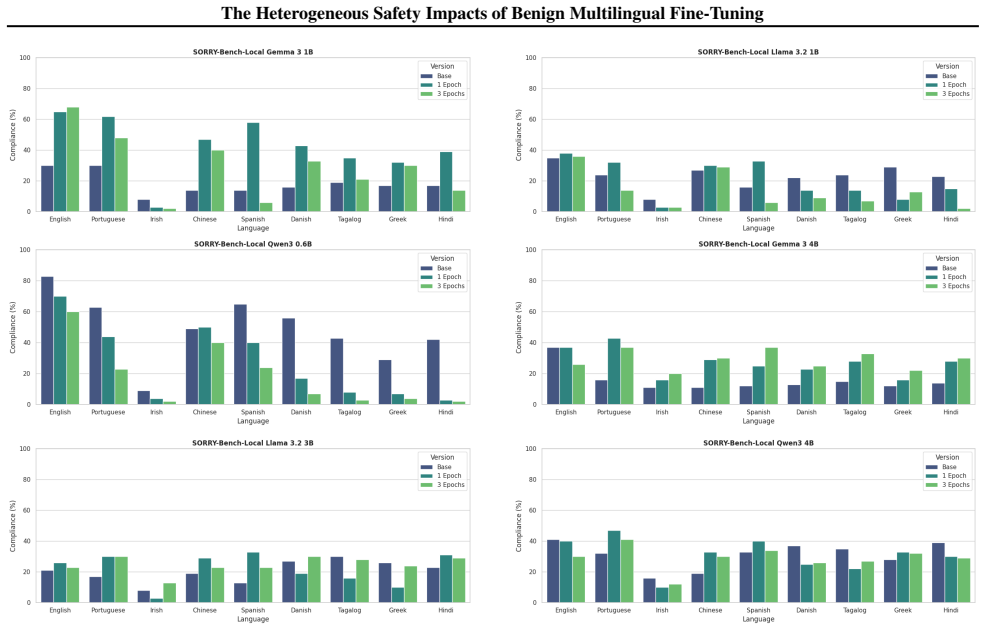
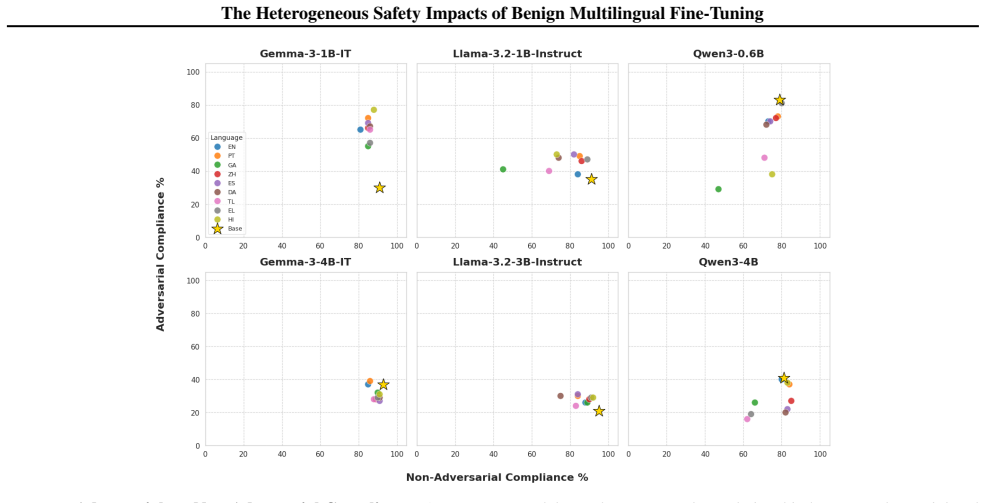
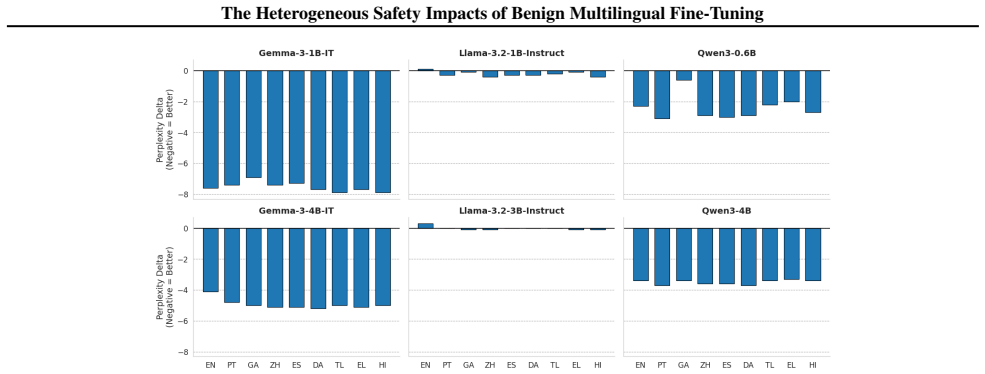
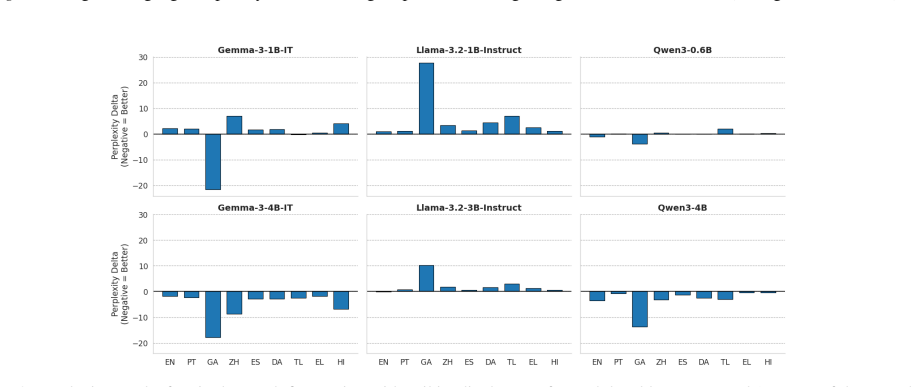
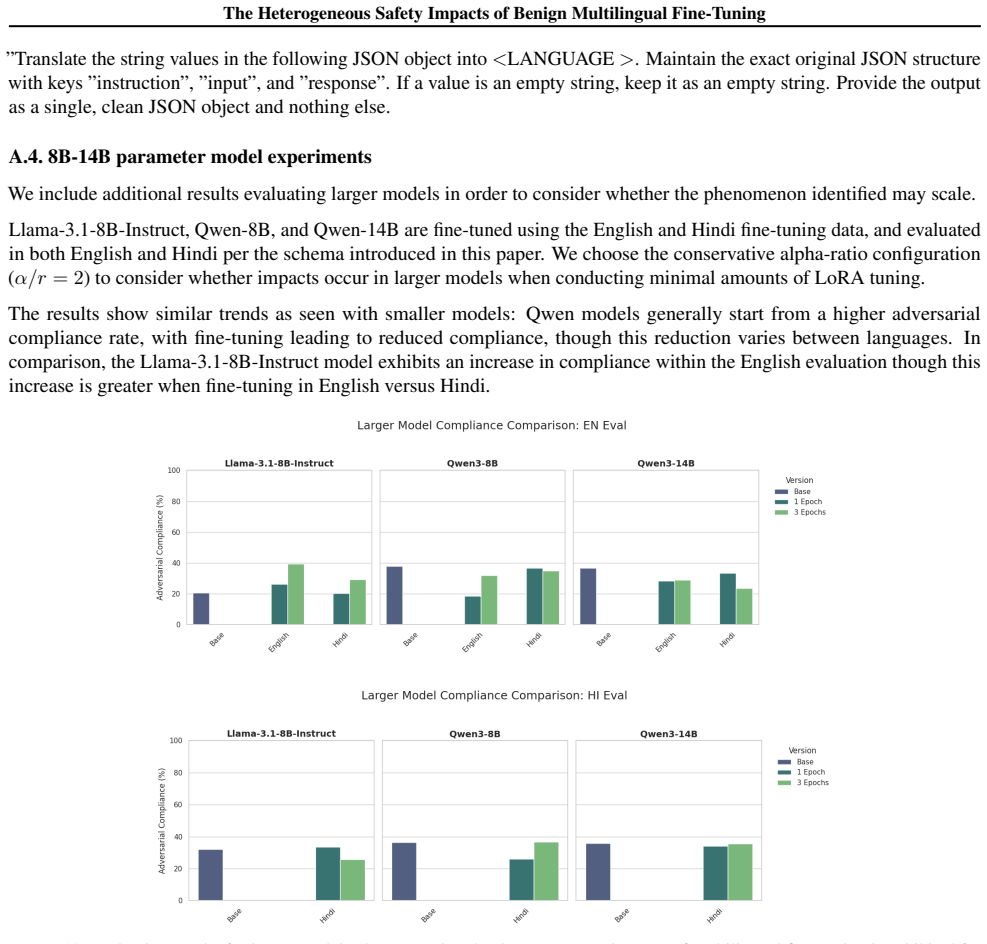
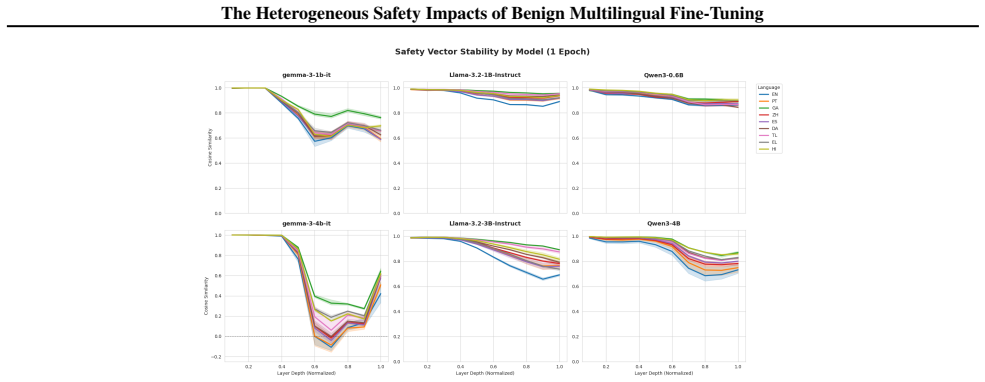
When Llama-3.2, Qwen3, and Gemma-3 models are fine-tuned on benign data translated into nine languages, safety outcomes measured by adversarial compliance rates prove highly sensitive to both the fine-tuning language and the evaluation language, with rates increasing four-fold in some settings. Multilingual safety drift occurs heterogeneously, is decoupled from general capability metrics, and fine-tuning in non-English languages often produces smaller internal representational drifts but results in models defaulting to exaggerated compliance or refusal.
What carries the argument
The heterogeneous safety drift from benign multilingual fine-tuning, which varies with language choice for training and testing.
If this is right
- Assessing safety solely in English fails to assure safe deployment in other languages.
- Models may show increased compliance to adversarial prompts after fine-tuning in certain non-English languages.
- Safety changes do not track with gains in general task performance.
- Releasing the Multilingual-Benign-Tune dataset enables further study of these effects.
Where Pith is reading between the lines
- Language-specific safety fine-tuning may be required rather than a one-size-fits-all approach.
- Translation processes could subtly alter the adversarial nature of data in ways not captured by capability metrics.
- Extending the study to additional languages or model scales might identify which language pairs pose the highest risk.
Load-bearing premise
The translated versions of the benign datasets stay equally non-adversarial and without unintended safety signals in every language.
What would settle it
Finding that adversarial compliance rates stay similar across all language combinations or that they strongly correlate with capability improvements would challenge the claim of heterogeneous decoupled safety impacts.
Figures

read the original abstract
Fine-tuning a large language model is a ubiquitous method for enhancing its capability on a specific downstream task. However, prior work has shown that this increase in capability comes with a cost: it can increase a model's tendency to respond to unsafe adversarial prompts, even when fine-tuning with non-adversarial data. We present the first comprehensive empirical study of this phenomenon in multilingual settings by fine-tuning Llama-3.2, Qwen3, and Gemma-3 models using benign data translated across nine languages. We find that safety outcomes are highly sensitive to both the choice of fine-tuning language and the evaluation language, with adversarial compliance rates increasing four-fold in some settings. Multilingual safety drift is decoupled from general capability metrics, and occurs heterogeneously across languages and models. Fine-tuning in non-English languages often induces smaller internal representational drifts than English, but these shifts lead models to default to either exaggerated compliance or refusal. As such, assessing fine-tuning impacts solely in English provides inadequate assurance for deployment. To facilitate further research into these cross-lingual safety blind spots, we release the Multilingual-Benign-Tune dataset and the SORRY-Bench-Multilingual evaluation suite.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first comprehensive empirical study of safety impacts from fine-tuning LLMs (Llama-3.2, Qwen3, Gemma-3) on benign data translated across nine languages. It reports that adversarial compliance rates are highly sensitive to both fine-tuning language and evaluation language, with increases up to four-fold in some settings; that multilingual safety drift is decoupled from general capability metrics and occurs heterogeneously across languages and models; that non-English fine-tuning often induces smaller internal representational drifts but leads to exaggerated compliance or refusal; and that English-only assessments are inadequate. The authors release the Multilingual-Benign-Tune dataset and SORRY-Bench-Multilingual evaluation suite.
Significance. If the central empirical findings hold after addressing verification concerns, the work is significant for demonstrating that benign multilingual fine-tuning produces heterogeneous safety outcomes not captured by capability metrics or English-only evaluation. The release of the two datasets is a clear strength that supports reproducibility and further research into cross-lingual safety.
major comments (2)
- [Methodology / Dataset Construction] The experimental methodology provides no reported verification (human review, safety classifier scores, or back-translation consistency) that the translated benign datasets remain equivalently non-adversarial and free of unintended safety signals across the nine languages. This assumption is load-bearing for attributing the four-fold compliance increases and heterogeneous drift to multilingual fine-tuning rather than translation artifacts.
- [Results] The claim of decoupling between safety drift and capability metrics (abstract and results) requires explicit reporting of the capability metrics used, the statistical tests applied, and per-language/model correlations; without these, the heterogeneity finding cannot be fully assessed for robustness.
minor comments (2)
- The abstract lists nine languages but does not name them; adding the list would improve clarity for readers.
- [Figures] Ensure all figures reporting compliance rates include error bars or confidence intervals and clearly label the fine-tuning vs. evaluation language axes.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and will make the indicated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methodology / Dataset Construction] The experimental methodology provides no reported verification (human review, safety classifier scores, or back-translation consistency) that the translated benign datasets remain equivalently non-adversarial and free of unintended safety signals across the nine languages. This assumption is load-bearing for attributing the four-fold compliance increases and heterogeneous drift to multilingual fine-tuning rather than translation artifacts.
Authors: The referee correctly notes that the manuscript does not report verification procedures for the translated datasets. We will revise the methodology section to include explicit verification details, such as safety classifier scores and back-translation consistency metrics applied to samples across languages, to better support attribution of the observed effects to multilingual fine-tuning. revision: yes
-
Referee: [Results] The claim of decoupling between safety drift and capability metrics (abstract and results) requires explicit reporting of the capability metrics used, the statistical tests applied, and per-language/model correlations; without these, the heterogeneity finding cannot be fully assessed for robustness.
Authors: We agree that explicit reporting of the supporting analyses is needed for full assessment. We will revise the results section to include the specific capability metrics, the statistical tests performed, and per-language/model correlation results to substantiate the decoupling claim. revision: yes
Circularity Check
Empirical measurement study with no derivation chain or fitted predictions
full rationale
The paper conducts an empirical study by fine-tuning models on translated benign data and measuring adversarial compliance rates across languages and models. No equations, self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Central results (four-fold compliance changes, heterogeneous drift) are direct experimental outcomes rather than reductions to inputs by construction. The analysis is self-contained against external benchmarks of model behavior.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A. A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., Benhaim, A., Bilenko, M., Bjorck, J., Bubeck, S., Cai, M., Cai, Q., Chaudhary, V., Chen, D., Chen, D., Chen, W., Chen, Y.-C., Chen, Y.-L., Cheng, H., Chopra, P., Dai, X., Dixon, M., Eldan, R., Fragoso, V., Gao, J., Gao, M., Gao, M., Garg...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
I., Mosbach, M., and Klakow, D
Alabi, J., Adelani, D. I., Mosbach, M., and Klakow, D. Adapting pre-trained language models to african languages via multilingual adaptive fine-tuning. In Proceedings of the 29th international conference on computational linguistics, pp.\ 4336--4349, 2022
2022
-
[3]
Refusal in language models is mediated by a single direction
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., and Nanda, N. Refusal in language models is mediated by a single direction. In Proceedings of the 38th International Conference on Neural Information Processing Systems , volume 37 of NIPS '24 , pp.\ 136037--136083, Red Hook, NY, USA, December 2024. Curran Associates Inc. ISBN 979-8...
2024
-
[4]
Bach, T., Nguyen-Tang, T., Nguyen, D., Le, T. M., and Tran, T. Curvature-aware safety restoration in llms fine-tuning, 2025. URL https://arxiv.org/abs/2511.18039
-
[5]
Safety-tuned LLaMAs : Lessons from improving the safety of large language models that follow instructions
Bianchi, F., Suzgun, M., Attanasio, G., Rottger, P., Jurafsky, D., Hashimoto, T., and Zou, J. Safety-tuned LLaMAs : Lessons from improving the safety of large language models that follow instructions. In The Twelfth International Conference on Learning Representations , October 2023. URL https://openreview.net/forum?id=gT5hALch9z
2023
-
[6]
Conover, M. et al. Free dolly: Introducing the world's first truly open instruction-tuned llm. https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm, 2023. Accessed: 2023-06-30
2023
-
[7]
Daniel Han, M. H. and team, U. Unsloth, 2023. URL http://github.com/unslothai/unsloth
2023
-
[8]
C., Dawkins, H., Nejadgholi, I., and Kiritchenko, S
Fraser, K. C., Dawkins, H., Nejadgholi, I., and Kiritchenko, S. Fine-tuning lowers safety and disrupts evaluation consistency. In Derczynski, L., Novikova, J., and Chen, M. (eds.), Proceedings of the The First Workshop on LLM Security ( LLMSEC ) , pp.\ 129--141, Vienna, Austria, August 2025. Association for Computational Linguistics. ISBN 979-8-89176-279-...
2025
-
[9]
Gemini-Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Gemma-Team. Gemma 3 technical report, 2025. URL https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
The effect of fine-tuning on language model toxicity
Hawkins, W., Mittelstadt, B., and Russell, C. The effect of fine-tuning on language model toxicity. In Neurips Safe Generative AI Workshop 2024 , October 2024. URL https://openreview.net/forum?id=YXaFxrMbVk
2024
-
[12]
Refusal behavior in large language models: A nonlinear perspective, 2025
Hildebrandt, F., Maier, A., Krauss, P., and Schilling, A. Refusal behavior in large language models: A nonlinear perspective, 2025. URL https://arxiv.org/abs/2501.08145
-
[13]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[15]
Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b, 2024
Lermen, S., Rogers-Smith, C., and Ladish, J. Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b, 2024. URL https://arxiv.org/abs/2310.20624
-
[16]
MobileLLM : Optimizing sub-billion parameter language models for on-device use cases
Liu, Z., Zhao, C., Iandola, F., Lai, C., Tian, Y., Fedorov, I., Xiong, Y., Chang, E., Shi, Y., Krishnamoorthi, R., Lai, L., and Chandra, V. MobileLLM : Optimizing sub-billion parameter language models for on-device use cases. In Proceedings of the 41st International Conference on Machine Learning , volume 235 of ICML '24 , pp.\ 32431--32454, Vienna, Austr...
2024
-
[17]
Llama-Team. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Pointer sentinel mixture models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. In International Conference on Learning Representations , February 2017. URL https://openreview.net/forum?id=Byj72udxe
2017
-
[20]
NLLB Team , Costa-jussà, M. R., Cross, J., Çelebi, O., Elbayad, M., Heafield, K., Heffernan, K., Kalbassi, E., Lam, J., Licht, D., Maillard, J., Sun, A., Wang, S., Wenzek, G., Youngblood, A., Akula, B., Barrault, L., Gonzalez, G. M., Hansanti, P., Hoffman, J., Jarrett, S., Sadagopan, K. R., Rowe, D., Spruit, S., Tran, C., Andrews, P., Ayan, N. F., Bhosale...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
OpenAI-Team. Gpt-4 technical report, 2024. URL https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
M., Weber, L., Choshen, L., Sun, Y., Xu, G., and Yurochkin, M
Polo, F. M., Weber, L., Choshen, L., Sun, Y., Xu, G., and Yurochkin, M. tinyBenchmarks : Evaluating LLMs with fewer examples. In Proceedings of the 41st International Conference on Machine Learning , pp.\ 34303--34326. PMLR, July 2024. URL https://proceedings.mlr.press/v235/maia-polo24a.html
2024
-
[24]
Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations , October 2023
Qi, X., Zeng, Y., Xie, T., Chen, P.-Y., Jia, R., Mittal, P., and Henderson, P. Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations , October 2023. URL https://openreview.net/forum?id=hTEGyKf0dZ
2023
-
[25]
H., Kirk, H
Rystrøm, J. H., Kirk, H. R., and Hale, S. Multilingual != multicultural: evaluating gaps between multilingual capabilities and cultural alignment in LLMs . In Przybyła, P., Shardlow, M., Colombatto, C., and Inie, N. (eds.), Proceedings of Interdisciplinary Workshop on Observations of Misunderstood , Misguided and Malicious Use of Language Models , pp.\ 74...
2025
-
[26]
Schulman, J. and Thinking Machines Lab . Lora without regret. Thinking Machines Lab: Connectionism, 2025. doi:10.64434/tml.20250929. https://thinkingmachines.ai/blog/lora/
-
[27]
Multilingual translation with extensible multilingual pretraining and finetuning, 2020
Tang, Y., Tran, C., Li, X., Chen, P.-J., Goyal, N., Chaudhary, V., Gu, J., and Fan, A. Multilingual translation with extensible multilingual pretraining and finetuning, 2020. URL https://arxiv.org/abs/2008.00401
-
[28]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[29]
a ger, T., Elstner, J., Geisler, S., Cohen-Addad , V., G \
Wollschl \"a ger, T., Elstner, J., Geisler, S., Cohen-Addad , V., G \"u nnemann, S., and Gasteiger, J. The geometry of refusal in large language models: Concept cones and representational independence. In Forty-Second International Conference on Machine Learning , June 2025. URL https://openreview.net/forum?id=80IwJqlXs8
2025
-
[30]
M., Huang, K., He, L., Wei, B., Li, D., Sheng, Y., Jia, R., Li, B., Li, K., Chen, D., Henderson, P., and Mittal, P
Xie, T., Qi, X., Zeng, Y., Huang, Y., Sehwag, U. M., Huang, K., He, L., Wei, B., Li, D., Sheng, Y., Jia, R., Li, B., Li, K., Chen, D., Henderson, P., and Mittal, P. SORRY-bench : Systematically evaluating large language model safety refusal. In The Thirteenth International Conference on Learning Representations , October 2024. URL https://openreview.net/f...
2024
-
[31]
On-device language models: A comprehensive review, 2024
Xu, J., Li, Z., Chen, W., Wang, Q., Gao, X., Cai, Q., and Ling, Z. On-device language models: A comprehensive review, 2024. URL https://arxiv.org/abs/2409.00088
-
[32]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
Understanding and preserving safety in fine-tuned llms, 2026
Zhang, J., Hu, Y., Chen, K., He, L., Ma, J., Lou, J., Li, D., Liu, J., Yang, X., and Jia, R. Understanding and preserving safety in fine-tuned llms, 2026. URL https://arxiv.org/abs/2601.10141
-
[35]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., Goel, S., Li, N., Byun, M. J., Wang, Z., Mallen, A., Basart, S., Koyejo, S., Song, D., Fredrikson, M., Kolter, J. Z., and Hendrycks, D. Representation engineering: A top-down approach to ai transparency, 2023. URL https://arxiv.org/abs/2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
2021 , eprint=
The Low-Resource Double Bind: An Empirical Study of Pruning for Low-Resource Machine Translation , author=. 2021 , eprint=
2021
-
[37]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[38]
The State and Fate of Linguistic Diversity and Inclusion in the
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit , editor =. The State and Fate of Linguistic Diversity and Inclusion in the. Proceedings of the 58th. doi:10.18653/v1/2020.acl-main.560 , url =
-
[39]
Xie, Tinghao and Qi, Xiangyu and Zeng, Yi and Huang, Yangsibo and Sehwag, Udari Madhushani and Huang, Kaixuan and He, Luxi and Wei, Boyi and Li, Dacheng and Sheng, Ying and Jia, Ruoxi and Li, Bo and Li, Kai and Chen, Danqi and Henderson, Peter and Mittal, Prateek , year = 2024, month = oct, url =. The
2024
-
[40]
2022 , eprint=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , eprint=
2022
-
[41]
Pointer Sentinel Mixture Models , booktitle =
Merity, Stephen and Xiong, Caiming and Bradbury, James and Socher, Richard , year = 2017, month = feb, url =. Pointer Sentinel Mixture Models , booktitle =
2017
-
[42]
Proceedings of the 41st
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , year = 2024, month = jul, pages =. Proceedings of the 41st
2024
-
[43]
Biometrics , year=
Individual Comparisons by Ranking Methods , author=. Biometrics , year=
-
[44]
Fine-Tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , booktitle =
Qi, Xiangyu and Zeng, Yi and Xie, Tinghao and Chen, Pin-Yu and Jia, Ruoxi and Mittal, Prateek and Henderson, Peter , year = 2023, month = oct, url =. Fine-Tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , booktitle =
2023
-
[45]
The Effect of Fine-Tuning on Language Model Toxicity , booktitle =
Hawkins, Will and Mittelstadt, Brent and Russell, Chris , year = 2024, month = oct, url =. The Effect of Fine-Tuning on Language Model Toxicity , booktitle =
2024
-
[46]
All Languages Matter: On the Multilingual Safety of LLMs , author=
-
[47]
Towards Understanding the Fragility of Multilingual
Poppi, Samuele and Yong, Zheng Xin and He, Yifei and Chern, Bobbie and Zhao, Han and Yang, Aobo and Chi, Jianfeng , editor =. Towards Understanding the Fragility of Multilingual. Findings of the. doi:10.18653/v1/2025.findings-naacl.126 , url =
-
[48]
Multilingual Jailbreak Challenges in Large Language Models , booktitle =
Deng, Yue and Zhang, Wenxuan and Pan, Sinno Jialin and Bing, Lidong , year = 2023, month = oct, url =. Multilingual Jailbreak Challenges in Large Language Models , booktitle =
2023
-
[49]
The Language Barrier: Dissecting Safety Challenges of
Shen, Lingfeng and Tan, Weiting and Chen, Sihao and Chen, Yunmo and Zhang, Jingyu and Xu, Haoran and Zheng, Boyuan and Koehn, Philipp and Khashabi, Daniel , editor =. The Language Barrier: Dissecting Safety Challenges of. Findings of the. doi:10.18653/v1/2024.findings-acl.156 , url =
-
[50]
and Dawkins, Hillary and Nejadgholi, Isar and Kiritchenko, Svetlana , editor =
Fraser, Kathleen C. and Dawkins, Hillary and Nejadgholi, Isar and Kiritchenko, Svetlana , editor =. Fine-Tuning Lowers Safety and Disrupts Evaluation Consistency , booktitle =
-
[51]
2025 , eprint=
Unintended Misalignment from Agentic Fine-Tuning: Risks and Mitigation , author=. 2025 , eprint=
2025
-
[52]
2024 , eprint=
LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B , author=. 2024 , eprint=
2024
-
[53]
2025 , eprint=
LoRA is All You Need for Safety Alignment of Reasoning LLMs , author=. 2025 , eprint=
2025
-
[54]
2025 , eprint=
Safe LoRA: the Silver Lining of Reducing Safety Risks when Fine-tuning Large Language Models , author=. 2025 , eprint=
2025
-
[55]
Zhang, Xuan and Rajabi, Navid and Duh, Kevin and Koehn, Philipp. Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with QL o RA. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.43
-
[56]
2025 , eprint=
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates , author=. 2025 , eprint=
2025
-
[57]
2023 , eprint=
Safe RLHF: Safe Reinforcement Learning from Human Feedback , author=. 2023 , eprint=
2023
-
[58]
2023 , howpublished =
Mike Conover and others , title =. 2023 , howpublished =
2023
-
[59]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[60]
Daniel Han, Michael Han and Unsloth team , title =
-
[61]
Safety-Tuned
Bianchi, Federico and Suzgun, Mirac and Attanasio, Giuseppe and Rottger, Paul and Jurafsky, Dan and Hashimoto, Tatsunori and Zou, James , year = 2023, month = oct, url =. Safety-Tuned. The
2023
-
[62]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[63]
Proceedings of the 29th international conference on computational linguistics , pages=
Adapting pre-trained language models to African languages via multilingual adaptive fine-tuning , author=. Proceedings of the 29th international conference on computational linguistics , pages=
-
[64]
No Error Left Behind: Multilingual Grammatical Error Correction with Pre-trained Translation Models
Luhtaru, Agnes and Korotkova, Elizaveta and Fishel, Mark. No Error Left Behind: Multilingual Grammatical Error Correction with Pre-trained Translation Models. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.73
-
[65]
2020 , eprint=
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning , author=. 2020 , eprint=
2020
-
[66]
2024 , eprint=
On-Device Language Models: A Comprehensive Review , author=. 2024 , eprint=
2024
-
[67]
2024 , eprint=
On-Device LLMs for SMEs: Challenges and Opportunities , author=. 2024 , eprint=
2024
-
[68]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[70]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[71]
2026 , eprint=
Understanding and Preserving Safety in Fine-Tuned LLMs , author=. 2026 , eprint=
2026
-
[72]
2025 , eprint=
Refusal Behavior in Large Language Models: A Nonlinear Perspective , author=. 2025 , eprint=
2025
-
[73]
Refusal in Language Models Is Mediated by a Single Direction , booktitle =
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , year = 2024, month = dec, series =. Refusal in Language Models Is Mediated by a Single Direction , booktitle =
2024
-
[74]
2025 , eprint=
Curvature-Aware Safety Restoration In LLMs Fine-Tuning , author=. 2025 , eprint=
2025
-
[75]
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence , shorttitle =
Wollschl. The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence , shorttitle =. Forty-Second
-
[76]
2023 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2023 , eprint=
2023
-
[77]
2024 , eprint=
LoRA+: Efficient Low Rank Adaptation of Large Models , author=. 2024 , eprint=
2024
-
[78]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[79]
LoRA Without Regret , journal =
John Schulman and. LoRA Without Regret , journal =. 2025 , note =
2025
-
[80]
Multilingual != multicultural: evaluating gaps between multilingual capabilities and cultural alignment in
Rystrøm, Jonathan Hvithamar and Kirk, Hannah Rose and Hale, Scott , editor =. Multilingual != multicultural: evaluating gaps between multilingual capabilities and cultural alignment in. Proceedings of. 2025 , keywords =
2025
-
[81]
2024 , eprint=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. 2024 , eprint=
2024
-
[82]
Proceedings of the 41st
Liu, Zechun and Zhao, Changsheng and Iandola, Forrest and Lai, Chen and Tian, Yuandong and Fedorov, Igor and Xiong, Yunyang and Chang, Ernie and Shi, Yangyang and Krishnamoorthi, Raghuraman and Lai, Liangzhen and Chandra, Vikas , year = 2024, month = jul, series =. Proceedings of the 41st
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.