Personalizing MLLMs via Reinforced Multimodal Reference Game
Pith reviewed 2026-06-30 10:06 UTC · model grok-4.3
The pith
A self-play reference game with contrastive rewards trains MLLMs to generate descriptions that uniquely identify personal concepts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
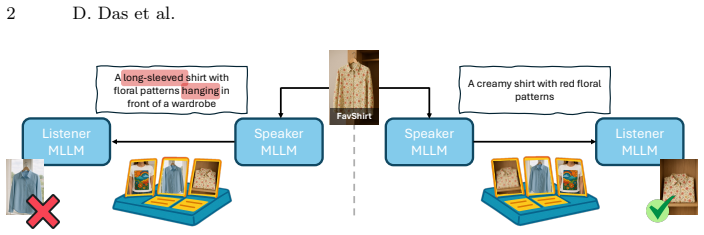
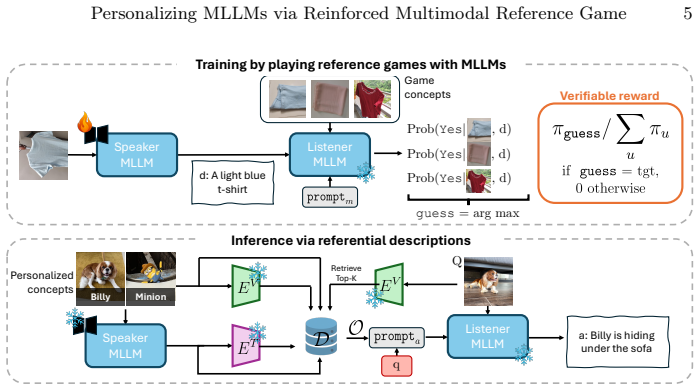
By casting personalization as a multimodal reference game in which the MLLM alternates between generating a description of a target concept and using received descriptions to select the correct image among hard positives and hard negatives, a verifiable contrastive reward produces descriptions that are accurate, discriminative, and free of distracting details.
What carries the argument
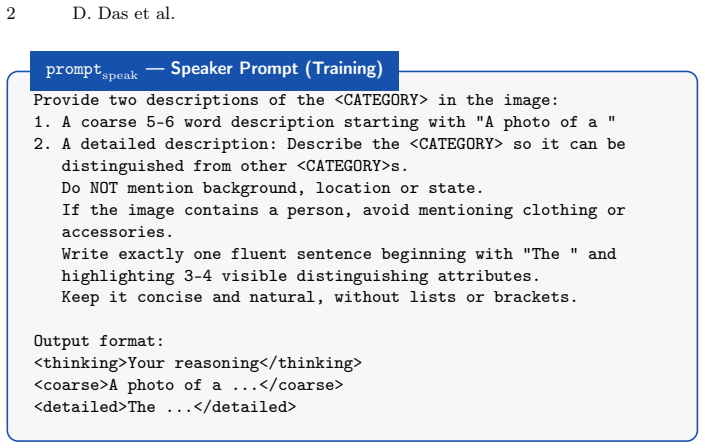
Reinforced Reference Game (RRG): a contrastive self-play loop in which the same MLLM generates candidate descriptions and evaluates them via a reward computed from identification success on dissimilar views of the same concept versus visually similar but different concepts.
If this is right
- RRG reaches state-of-the-art results on multiple personalization tasks across three benchmarks.
- The learned descriptions generalize to unseen domains.
- RRG outperforms both concept-description methods and prior personalization-specific reinforcement-learning approaches.
- The same MLLM can serve as both speaker and listener without external reward models.
Where Pith is reading between the lines
- The method may reduce reliance on manually written concept descriptions by letting the model discover discriminative features through interaction.
- The contrastive game structure could be adapted to other settings where an MLLM must communicate distinguishing visual information, such as visual question answering with ambiguous referents.
- If the reward signal proves robust, similar self-play loops might improve grounding in other multimodal tasks without task-specific fine-tuning data.
Load-bearing premise
A contrastive reward computed from hard positives and hard negatives will cause the model to drop non-discriminative details and produce descriptions that improve unique identification.
What would settle it
Running RRG on the three personalization benchmarks yields no accuracy gain over strong concept-description baselines on the held-out tasks.
Figures






read the original abstract
Personalizing Multimodal Large Language Models (MLLMs) aims to recognize users' unique concepts from visual data and provide personalized responses. Although prior work has shown the benefit of concept descriptions and reasoning for this task, MLLM descriptions often include information, such as state and context, that does not help and may in fact hinder the unique identification of the target concept among other visually similar items. Effective descriptions of personal concepts should instead be accurate, discriminative, and free of distracting details. To achieve such descriptions, we introduce Reinforced Reference Game (RRG), a learning framework that promotes discriminative descriptions through a novel reinforced multimodal reference game. The MLLM plays both the roles of speaker and listener in a contrastive game setting, whose goal is to effectively communicate discriminative information about a target concept. Our approach formulates a verifiable contrastive reward over hard positives (dissimilar views of the same concept) and hard negatives (visually similar but different concepts). Empirically, RRG achieves state-of-the-art across multiple tasks on three personalization benchmarks. RRG generalizes to unseen domains and outperforms existing methods based on concept descriptions and personalization-specific RL frameworks. We will release code and models in the project page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reinforced Reference Game (RRG), a framework in which an MLLM acts as both speaker and listener in a multimodal reference game. A contrastive reward is defined over hard positives (dissimilar views of the same concept) and hard negatives (visually similar but different concepts) to encourage generation of accurate, discriminative descriptions free of distracting details. The central empirical claim is that RRG attains state-of-the-art performance across multiple tasks on three personalization benchmarks, generalizes to unseen domains, and outperforms prior concept-description and personalization-specific RL baselines.
Significance. If the reported results hold, the work supplies a concrete mechanism for shaping MLLM outputs toward discriminative rather than merely descriptive content, which is load-bearing for personalization tasks. The explicit commitment to release code and models is a positive contribution to reproducibility.
minor comments (2)
- The abstract states SOTA results and generalization but does not include any numerical metrics, baseline names, or dataset identifiers; the experimental section should supply these in a compact table for immediate assessment.
- The description of the contrastive reward (hard positives vs. hard negatives) would benefit from an explicit equation or pseudocode block showing how the reward is computed from the listener's selection accuracy.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance for shaping discriminative MLLM outputs, and the recommendation of minor revision. We appreciate the explicit note on reproducibility via code and model release.
Circularity Check
No significant circularity
full rationale
The paper presents RRG as an empirical learning framework: an MLLM plays speaker/listener roles in a contrastive reference game optimized by a verifiable reward on hard positives/negatives. Central claims are SOTA results on three external personalization benchmarks plus generalization to unseen domains. No equations, derivations, or self-citations are shown that reduce any result to fitted inputs or prior author work by construction. The method definition and evaluation are independent of the reported outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: ECCV (2024) 1, 2, 3, 4, 9, 10, 12, 13, 14, 6
Alaluf, Y., Richardson, E., Tulyakov, S., Aberman, K., Cohen-Or, D.: Myvlm: Personalizing vlms for user-specific queries. In: ECCV (2024) 1, 2, 3, 4, 9, 10, 12, 13, 14, 6
2024
-
[3]
In: CVPR (2021) 5
Alaniz, S., Marcos, D., Schiele, B., Akata, Z.: Learning decision trees recurrently through communication. In: CVPR (2021) 5
2021
-
[4]
In: NeurIPS (2022) 1
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. In: NeurIPS (2022) 1
2022
-
[5]
arXiv preprint arXiv:2411.11706 (2024) 4, 11, 8
An, R., Yang, S., Lu, M., Zhang, R., Zeng, K., Luo, Y., Cao, J., Liang, H., Chen, Y., She, Q., et al.: Mc-llava: Multi-concept personalized vision-language model. arXiv preprint arXiv:2411.11706 (2024) 4, 11, 8
-
[6]
this is my unicorn, fluffy
Cohen, N., Gal, R., Meirom, E.A., Chechik, G., Atzmon, Y.: “this is my unicorn, fluffy”: Personalizing frozen vision-language representations. In: ECCV (2022) 4
2022
-
[7]
In: NeurIPS (2019) 5
Corona Rodriguez, R., Alaniz, S., Akata, Z.: Modeling conceptual understanding in image reference games. In: NeurIPS (2019) 5
2019
-
[8]
In: CVPR (2017) 4
Das, A., Kottur, S., Gupta, K., Singh, A., Yadav, D., Moura, J.M., Parikh, D., Batra, D.: Visual dialog. In: CVPR (2017) 4
2017
-
[9]
In: ICCV (2025) 1, 2, 3, 4, 7, 8, 9, 10, 11, 13
Das, D., Talon, D., Wang, Y., Mancini, M., Ricci, E.: Training-free personalization via retrieval and reasoning on fingerprints. In: ICCV (2025) 1, 2, 3, 4, 7, 8, 9, 10, 11, 13
2025
-
[10]
In: CVPR (2017) 4 16 D
De Vries, H., Strub, F., Chandar, S., Pietquin, O., Larochelle, H., Courville, A.: Guesswhat?! visual object discovery through multi-modal dialogue. In: CVPR (2017) 4 16 D. Das et al
2017
-
[11]
In: Conference on Language Modeling (2024) 7
Dingjie, S., Chen, S., Chen, G.H., Yu, F., Wan, X., Wang, B.: Milebench: Bench- marking mllms in long context. In: Conference on Language Modeling (2024) 7
2024
-
[12]
In: ICLR (2023) 3
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen- or, D.: An image is worth one word: Personalizing text-to-image generation using textual inversion. In: ICLR (2023) 3
2023
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025) 3, 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: CVPR (2025) 1, 2, 4, 9, 10, 11, 13, 5
Hao, H., Han, J., Li, C., Li, Y.F., Yue, X.: Remember, retrieve and generate: Understanding infinite visual concepts as your personalized assistant. In: CVPR (2025) 1, 2, 4, 9, 10, 11, 13, 5
2025
-
[15]
In: ICLR (2022) 7, 1
Hu, E.J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. In: ICLR (2022) 7, 1
2022
-
[16]
In: EMNLP (2014) 4
Kazemzadeh, S., Ordonez, V., Matten, M., Berg, T.: Referitgame: Referring to objects in photographs of natural scenes. In: EMNLP (2014) 4
2014
-
[17]
In: ICCV (2023) 4
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: ICCV (2023) 4
2023
-
[18]
In: CVPR (2023) 4
Kumari, N., Zhang, B., Zhang, R., Shechtman, E., Zhu, J.Y.: Multi-concept cus- tomization of text-to-image diffusion. In: CVPR (2023) 4
2023
-
[19]
In: ICML (2023) 1
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023) 1
2023
-
[20]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Li, Z., Yu, W., Huang, C., Liu, R., Liang, Z., Liu, F., Che, J., Yu, D., Boyd-Graber, J., Mi, H., et al.: Self-rewarding vision-language model via reasoning decomposition. arXiv preprint arXiv:2508.19652 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
In: NeurIPS (2023) 1
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023) 1
2023
-
[22]
In: ICLR (2024) 4
Liu, Y., Zhu, M., Li, H., Chen, H., Wang, X., Shen, C.: Matcher: Segment anything with one shot using all-purpose feature matching. In: ICLR (2024) 4
2024
-
[23]
Visual-RFT: Visual Reinforcement Fine-Tuning
Liu, Z., Sun, Z., Zang, Y., Dong, X., Cao, Y., Duan, H., Lin, D., Wang, J.: Visual-rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
In: NeurIPS (2024) 1, 2, 3, 4, 9, 10, 11, 12, 13, 14, 6
Nguyen, T., Liu, H., Li, Y., Cai, M., Ojha, U., Lee, Y.J.: Yo’LLaVA: Your person- alized language and vision assistant. In: NeurIPS (2024) 1, 2, 3, 4, 9, 10, 11, 12, 13, 14, 6
2024
-
[25]
In: CVPR (2025) 2, 4
Nguyen, T., Singh, K.K., Shi, J., Bui, T., Lee, Y.J., Li, Y.: Yo’chameleon: Person- alized vision and language generation. In: CVPR (2025) 2, 4
2025
-
[26]
Oh, Y., Mok, J., Chung, D., Shin, J., Park, S., Barthelemy, J., Yoon, S.: Repic: Reinforcedpost-trainingforpersonalizingmulti-modallanguagemodels.In:NeurIPS (2025) 2, 3, 4, 10, 11, 13, 5
2025
-
[27]
In: NeurIPS (2022) 4
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. In: NeurIPS (2022) 4
2022
-
[28]
arXiv preprint arXiv:2412.17610 (2024) 4
Pham, C., Phan, H., Doermann, D., Tian, Y.: Personalized large vision-language models. arXiv preprint arXiv:2412.17610 (2024) 4
-
[29]
In: ICLR (2025) 4
Pi, R., Zhang, J., Han, T., Zhang, J., Pan, R., Zhang, T.: Personalized visual instruction tuning. In: ICLR (2025) 4
2025
-
[30]
In: ICML (2018) 5
Rabinowitz, N., Perbet, F., Song, F., Zhang, C., Eslami, S.M.A., Botvinick, M.: Machine theory of mind. In: ICML (2018) 5
2018
-
[31]
In: ICML (2021) 8 Personalizing MLLMs via Reinforced Multimodal Reference Game 17
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021) 8 Personalizing MLLMs via Reinforced Multimodal Reference Game 17
2021
-
[32]
In: CVPR (2023) 4
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: CVPR (2023) 4
2023
-
[33]
In: NeurIPS (2024) 4
Samuel, D., Ben-Ari, R., Levy, M., Darshan, N., Chechik, G.: Where’s waldo: Diffusion features for personalized segmentation and retrieval. In: NeurIPS (2024) 4
2024
-
[34]
Personalization Toolkit: Training Free Personalization of Large Vision Language Models
Seifi, S., Dorovatas, V., Reino, D.O., Aljundi, R.: Personalization toolkit: Training free personalization of large vision language models. arXiv preprint arXiv:2502.02452 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
In: CVPR (2024) 4
Shi, J., Xiong, W., Lin, Z., Jung, H.J.: Instantbooth: Personalized text-to-image generation without test-time finetuning. In: CVPR (2024) 4
2024
-
[37]
In: NeurIPS (2020) 4
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., Christiano, P.F.: Learning to summarize with human feedback. In: NeurIPS (2020) 4
2020
-
[38]
In: ICLR (2025) 4
Sundaram, S., Chae, J., Tian, Y., Beery, S., Isola, P.: Personalized representation from personalized generation. In: ICLR (2025) 4
2025
-
[39]
In: ACL (2023) 5
Takmaz, E., Giulianelli, M., Pezzelle, S., Fernandez, R., et al.: Speaking the language of your listener: Audience-aware adaptation via plug-and-play theory of mind. In: ACL (2023) 5
2023
-
[40]
IJCV (2024) 4
Tang, L., Jiang, P.T., Xiao, H., Li, B.: Towards training-free open-world segmenta- tion via image prompt foundation models. IJCV (2024) 4
2024
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
In: ICLR (2025) 11, 10
Yang, T., Li, Z., Cao, J., Xu, C.: Understanding and mitigating hallucination in large vision-language models via modular attribution and intervention. In: ICLR (2025) 11, 10
2025
-
[43]
In: ICLR (2024) 4
Zhang, R., Jiang, Z., Guo, Z., Yan, S., Pan, J., Ma, X., Dong, H., Gao, P., Li, H.: Personalize segment anything model with one shot. In: ICLR (2024) 4
2024
-
[44]
arXiv preprint arXiv:2508.02419 (2025) 11, 10
Zheng, H., Zhang, Z.: Modality bias in lvlms: Analyzing and mitigating object hallucination via attention lens. arXiv preprint arXiv:2508.02419 (2025) 11, 10
-
[45]
Zhou, Y., Cui, C., Yoon, J., Zhang, L., Deng, Z., Finn, C., Bansal, M., Yao, H.: Analyzing and mitigating object hallucination in large vision-language models. In: ICLR (2024) 10 Personalizing MLLMs via Reinforced Multimodal Reference Game 1 Personalizing MLLMs via Reinforced Multimodal Reference Game Supplementary Material In this supplementary material ...
2024
-
[46]
A photo of a
A coarse 5-6 word description starting with "A photo of a "
-
[47]
<REFERENCE DESCRIPTION>
A detailed description: Describe the <CATEGORY> so it can be distinguished from other <CATEGORY>s. Do NOT mention background, location or state. If the image contains a person, avoid mentioning clothing or accessories. Write exactly one fluent sentence beginning with "The " and highlighting 3-4 visible distinguishing attributes. Keep it concise and natura...
-
[48]
Compare the subject in Image 1 with each reference description
-
[49]
Focus on distinguishing visual attributes (color, shape, pattern, texture)
-
[50]
Ignore background, lighting, and pose differences
-
[51]
Select the reference that best matches
-
[52]
Reasoning
Generate a personalized caption containing the name of the subject. Output format (JSON): { "Reasoning": "Brief comparison of key attributes", "Answer": "<one of A, B, C>", "Caption": "A personalized caption of the subject in Image 1." } Fig.7: Captioning prompt promptcap used at inference.The model receives one query image andK=3candidate descriptions re...
-
[53]
Compare the object in Image 1 with the reference description
-
[54]
Focus on identity-defining attributes (not pose, background, or lighting)
-
[55]
Reasoning
Answer ’Yes’ if it is the same object, ’No’ if different. Output format (JSON): { "Reasoning": "Brief comparison of key attributes", "Answer": "<Yes or No>" } Fig.8: Recognition promptpromptrec used at inference.Given a query image and the stored description of the personalised concept, the model determines whether the query depicts the exact same object ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.