How to Leverage Synthetic Speech for LLM-Based ASR Systems?
Pith reviewed 2026-06-30 09:32 UTC · model grok-4.3
The pith
Identifying that real-synthetic speech differences concentrate in early-to-middle layers of an LLM backbone enables a layer-selection module plus RIR augmentation to match full real-data ASR performance with only 25% real speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
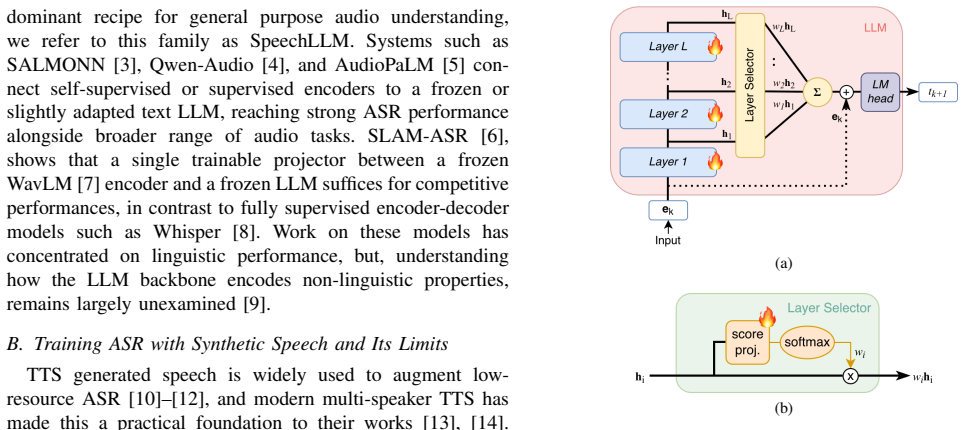
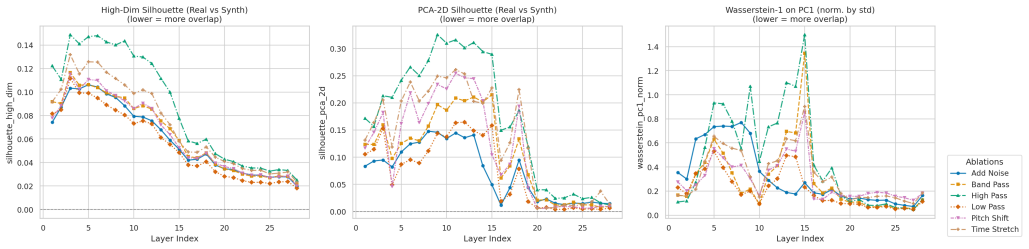
The paper establishes that the discriminative signal between real and synthetic speech in the SLAM-ASR architecture is localized to early-to-middle layers, where temporal and prosodic perturbations disrupt it most. Representation-level separability aids but does not directly predict downstream ASR gains. Convolving synthetic audio with room impulse responses narrows the distributional gap by reproducing the acoustic irregularities of real recordings rather than by increasing naturalness or cleanliness. Adding a layer-selection module combined with RIR augmentation matches a fully real-data baseline using only 25% of the real speech (13.6h) and surpasses it at all higher proportions.
What carries the argument
Layer-wise probing of the LLM backbone to localize the real-synthetic discriminative signal, followed by a layer-selection module combined with RIR augmentation.
If this is right
- Matches a fully real-data baseline using only 25% of the real speech.
- Surpasses the real-data baseline at all higher proportions of real speech.
- Representation separability between real and synthetic speech does not directly predict downstream ASR performance gains.
- RIR convolution narrows the gap by reproducing acoustic irregularities of real recordings rather than by improving perceived naturalness.
Where Pith is reading between the lines
- The same probing approach could identify minimal real-data fractions needed for other LLM-based speech tasks.
- In regulated industries the method reduces both collection costs and privacy exposure by minimizing stored real recordings.
- Testing the layer localization on additional ASR architectures would show how far the early-to-middle concentration holds.
Load-bearing premise
The localization of the real-synthetic signal to early-to-middle layers and the gap-narrowing effect of RIR convolution will generalize beyond the specific SLAM-ASR architecture and evaluation conditions tested.
What would settle it
Training the identical SLAM-ASR system without the layer-selection module or without RIR augmentation and measuring whether accuracy still matches or exceeds the full real-speech baseline at 25% and higher real-data proportions.
Figures

read the original abstract
In regulated domains such as banking and healthcare, where privacy constraints make real speech costly to collect and retain, synthetic speech from modern text-to-speech (TTS) is an appealing alternative for training automatic speech recognition (ASR) without exposing sensitive customer recordings. Yet a persistent distributional gap between synthetic and real data limits how far it can replace genuine recordings. Prior work largely treats this gap as a black box to be engineered around, but in our work, we instead examine its origin directly by probing a SLAM-ASR architecture. Then, we localise where its LLM backbone separates real from synthetic speech and find the discriminative signal concentrated in the early-to-middle layers, where temporal and prosodic perturbations disrupt it most. We further show that representation-level separability, help, but does not directly predict downstream ASR gains. On the other hand, convolving synthetic audio with room impulse responses (RIRs) narrows the gap not by making synthetic speech sound cleaner or more natural, but by reproducing the acoustic irregularities of real recordings. Translating these findings into the training procedure, by adding a layer-selection module combined with RIR augmentation matches a fully real-data baseline using only 25% of the real speech (13.6h) and surpasses it at all higher proportions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the use of synthetic speech to train LLM-based ASR systems under privacy constraints. By probing a SLAM-ASR model, it localizes the real-synthetic discriminative signal to early-to-middle layers of the LLM backbone, shows that this signal is disrupted by temporal/prosodic perturbations, demonstrates that RIR convolution narrows the distributional gap by reproducing acoustic irregularities (rather than improving naturalness), and reports that a layer-selection module plus RIR augmentation matches a full real-speech baseline using only 25% of the real data (13.6 h) while surpassing it at higher proportions.
Significance. If the empirical outcomes are robust, the work offers a concrete path to reduce real-speech requirements in regulated domains, with potential cost and privacy benefits. The layer-localization and RIR mechanism findings could inform architecture-aware augmentation strategies. The 25% efficiency result, if reproducible across conditions, would be a notable data-efficiency advance for LLM-based ASR.
major comments (2)
- Abstract: the central claim that the layer-selection module + RIR augmentation 'matches a fully real-data baseline using only 25% of the real speech' is presented without accompanying ablation tables, statistical tests, dataset sizes, or variance estimates, leaving the robustness of the 25% figure unverified and the translation from probing results to the training procedure unsupported.
- Abstract (probing and translation paragraph): the localization of the real-synthetic signal to early-to-middle layers and the specific RIR mechanism are demonstrated only inside the SLAM-ASR backbone; no cross-architecture experiments are supplied, so the assumption that the same layer range and RIR effect will produce the reported gains in other LLM-based ASR systems remains untested and load-bearing for the efficiency claim.
minor comments (1)
- Abstract: the phrasing 'representation-level separability, help, but does not directly predict' appears to contain a grammatical or typographical error and should be clarified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below, clarifying the scope of our claims and the evidence provided in the manuscript.
read point-by-point responses
-
Referee: Abstract: the central claim that the layer-selection module + RIR augmentation 'matches a fully real-data baseline using only 25% of the real speech' is presented without accompanying ablation tables, statistical tests, dataset sizes, or variance estimates, leaving the robustness of the 25% figure unverified and the translation from probing results to the training procedure unsupported.
Authors: The full manuscript reports the 25% result (13.6 h) with accompanying ablation tables in the experimental section that compare layer-selection + RIR against full real-data and other synthetic baselines across multiple real-speech proportions. Dataset sizes are stated explicitly in the data section and figure captions. Statistical significance is assessed via paired tests on the primary WER metrics, and variance across training seeds is reported for the key configurations. The link from probing to the training procedure is detailed in Sections 3–4, where the layer-localization results directly motivate the selection module. We will add a consolidated variance table in the revision to make these elements more immediately visible from the abstract claim. revision: partial
-
Referee: Abstract (probing and translation paragraph): the localization of the real-synthetic signal to early-to-middle layers and the specific RIR mechanism are demonstrated only inside the SLAM-ASR backbone; no cross-architecture experiments are supplied, so the assumption that the same layer range and RIR effect will produce the reported gains in other LLM-based ASR systems remains untested and load-bearing for the efficiency claim.
Authors: All reported results, including layer localization, RIR mechanism analysis, and the 25% efficiency figure, are explicitly tied to the SLAM-ASR backbone, as stated in the abstract and experimental setup. The paper does not assume or claim that the identical layer range or RIR effect will transfer unchanged to other LLM-based ASR architectures; the probing methodology itself is presented as a general tool that practitioners can apply to identify architecture-specific layers. The efficiency claim is therefore scoped to SLAM-ASR. We will add an explicit limitations paragraph reinforcing this scope and noting that cross-architecture validation is left for future work. revision: yes
Circularity Check
No circularity: empirical results from probing and augmentation trials
full rationale
The paper presents an empirical study involving layer probing in SLAM-ASR, localization of real-synthetic separability, and downstream ASR experiments with layer-selection and RIR augmentation. The central performance claim (matching real-data baseline at 25% real speech) is obtained directly from training and evaluation runs on held-out data, not from any equation or parameter fit that reduces by construction to the inputs. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is used to derive the reported gains. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The SLAM-ASR architecture is representative of LLM-based ASR systems for the purpose of layer-wise separability analysis.
Reference graph
Works this paper leans on
-
[1]
Regulation (eu) 2024/1689 of the european parliament and of the council of 13 june 2024 laying down harmonised rules on artificial intelligence (arti- ficial intelligence act),
European Parliament and Council of the European Union, “Regulation (eu) 2024/1689 of the european parliament and of the council of 13 june 2024 laying down harmonised rules on artificial intelligence (arti- ficial intelligence act),” Official Journal of the European Union, OJ L, 2024/1689, 12.7.2024, 2024, http://data.europa.eu/eli/reg/2024/1689/oj
2024
-
[2]
Towards explicit acoustic evidence perception in audio llms for speech deepfake detection,
X. Guo, Y . Xie, H. Cheng, J. Zhou, J. Liu, H. Huang, L. Ye, and Q. Zhang, “Towards explicit acoustic evidence perception in audio llms for speech deepfake detection,” 2026. [Online]. Available: https://arxiv.org/abs/2601.23066
-
[3]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. MA, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=14rn7HpKVk
2024
-
[4]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models,” 2023. [Online]. Available: https://arxiv.org/abs/2311.07919
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
AudioPaLM: A Large Language Model That Can Speak and Listen
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F. de Chaumont Quitry, P. Chen, D. E. Badawy, W. Han, E. Kharitonov, H. Muckenhirn, D. Padfield, J. Qin, D. Rozenberg, T. Sainath, J. Schalkwyk, M. Sharifi, M. T. Ramanovich, M. Tagliasacchi, A. Tudor, M. Velimirovi´c, D. Vincent, J. Yu, Y . Wang, V . Zayats, N. Zeghidour, Y . Zhang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Z. Ma, G. Yang, Y . Yang, Z. Gao, J. Wang, Z. Du, F. Yu, Q. Chen, S. Zheng, S. Zhang, and X. Chen, “Speech recognition meets large language model: benchmarking, models, and exploration,” inProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifte...
-
[7]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[8]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
-
[9]
How auditory knowledge in llm backbones shapes audio language models: A holistic evaluation,
K.-H. Lu, S.-W. Fu, C.-H. H. Yang, Z. Chen, S.-F. Huang, C.-K. Yang, Y .-C. Lin, C.-Y . Hsiao, W. Ren, E.-P. Hu, Y .-H. Huang, A.-Y . Cheng, C.-H. Chiang, Y . Tsao, Y .-C. F. Wang, and H. yi Lee, “How auditory knowledge in llm backbones shapes audio language models: A holistic evaluation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.19195
-
[10]
Generating synthetic audio data for attention-based speech recognition systems,
N. Rossenbach, A. Zeyer, R. Schl ¨uter, and H. Ney, “Generating synthetic audio data for attention-based speech recognition systems,” inICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 7069–7073. 1Repository withheld for blind review
2020
-
[11]
Speech recognition with augmented synthesized speech,
A. Rosenberg, Y . Zhang, B. Ramabhadran, Y . Jia, P. Moreno, Y . Wu, and Z. Wu, “Speech recognition with augmented synthesized speech,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2019, pp. 996–1002
2019
-
[12]
Large- Scale Self- and Semi-Supervised Learning for Speech Translation,
C. Wang, A. Wu, J. Pino, A. Baevski, M. Auli, and A. Conneau, “Large- Scale Self- and Semi-Supervised Learning for Speech Translation,” in Interspeech 2021, 2021, pp. 2242–2246
2021
-
[13]
Enhancing low-resource asr through versatile tts: Bridging the data gap,
G. Yang, F. Yu, Z. Ma, Z. Du, Z. Gao, S. Zhang, and X. Chen, “Enhancing low-resource asr through versatile tts: Bridging the data gap,” 2024. [Online]. Available: https://arxiv.org/abs/2410.16726
-
[14]
Towards improved speech recognition through optimized synthetic data generation,
Y . Perrin and G. Boulianne, “Towards improved speech recognition through optimized synthetic data generation,” 2025. [Online]. Available: https://arxiv.org/abs/2508.21631
-
[15]
The State Of TTS: A Case Study with Human Fooling Rates,
P. Srinivasa Varadhan, S. Thomas, S. Teja M S, S. Bhooshan, and M. M. Khapra, “The State Of TTS: A Case Study with Human Fooling Rates,” inInterspeech 2025, 2025, pp. 2285–2289
2025
-
[16]
Task arithmetic can mitigate synthetic-to-real gap in automatic speech recognition,
H. Su, H. Farn, F.-Y . Sun, S.-T. Chen, and H.-y. Lee, “Task arithmetic can mitigate synthetic-to-real gap in automatic speech recognition,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp...
2024
-
[17]
A self-refining framework for enhancing asr using tts-synthesized data,
C.-K. Chou, C.-J. Hsu, H.-L. Chung, L.-H. Tseng, H.-C. Cheng, Y .-K. Fu, K. P. Huang, and H.-Y . Lee, “A self-refining framework for enhancing asr using tts-synthesized data,” 2025. [Online]. Available: https://arxiv.org/abs/2506.11130
-
[18]
Naturalspeech: End-to-end text-to-speech synthesis with human-level quality,
X. Tan, J. Chen, H. Liu, J. Cong, C. Zhang, Y . Liu, X. Wang, Y . Leng, Y . Yi, L. He, S. Zhao, T. Qin, F. Soong, and T.-Y . Liu, “Naturalspeech: End-to-end text-to-speech synthesis with human-level quality,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 6, pp. 4234–4245, 2024
2024
-
[19]
J. Mishra, M. Chhibber, H. jin Shim, and T. H. Kinnunen, “Towards explainable spoofed speech attribution and detection:a probabilistic approach for characterizing speech synthesizer components,” 2025. [Online]. Available: https://arxiv.org/abs/2502.04049
-
[20]
Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,
X. Wang, J. Yamagishi, M. Todisco, H. Delgado, A. Nautsch, N. Evans, M. Sahidullah, V . Vestman, T. Kinnunen, K. A. Lee, L. Juvela, P. Alku, Y .-H. Peng, H.-T. Hwang, Y . Tsao, H.-M. Wang, S. L. Maguer, M. Becker, F. Henderson, R. Clark, Y . Zhang, Q. Wang, Y . Jia, K. Onuma, K. Mushika, T. Kaneda, Y . Jiang, L.-J. Liu, Y .-C. Wu, W.-C. Huang, T. Toda, K....
2019
-
[21]
Towards robust speech deepfake detection via human-inspired reasoning,
A. Dvirniak, E. Kushnir, D. Tarasov, A. Iudin, O. Kiriukhin, M. Pautov, D. Korzh, and O. Y . Rogov, “Towards robust speech deepfake detection via human-inspired reasoning,” 2026. [Online]. Available: https://arxiv.org/abs/2603.10725
-
[22]
Specializing Self-Supervised Speech Representations for Speaker Segmentation,
S. Baroudi, T. Pellegrini, and H. Bredin, “Specializing Self-Supervised Speech Representations for Speaker Segmentation,” inInterspeech 2024, 2024, pp. 3769–3773
2024
-
[23]
Speech Self-Supervised Representation Benchmarking: Are We Doing it Right?
S. Zaiem, Y . Kemiche, T. Parcollet, S. Essid, and M. Ravanelli, “Speech Self-Supervised Representation Benchmarking: Are We Doing it Right?” inInterspeech 2023, 2023, pp. 2873–2877
2023
-
[24]
On the use of self- supervised representation learning for speaker diarization and separa- tion,
S. Baroudi, H. Bredin, J. Razik, and R. Marxer, “On the use of self- supervised representation learning for speaker diarization and separa- tion,” in2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2025, pp. 1–7
2025
-
[25]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” in2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2021, pp. 914–921
2021
-
[26]
SUPERB: Speech Processing Universal PERformance Benchmark,
S. wen Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.-H. Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. Mohamed, and H. yi Lee, “SUPERB: Speech Processing Universal PERformance Benchmark,” inInterspeech 2021, 2021, pp. 1194–1198
2021
-
[27]
Anatomy of the modality gap: Dissecting the internal states of end-to-end speech llms,
M.-H. Hsu, X. Zhang, X. Tian, J. Zhang, and Z. Wu, “Anatomy of the modality gap: Dissecting the internal states of end-to-end speech llms,”
-
[28]
Available: https://arxiv.org/abs/2603.01502
[Online]. Available: https://arxiv.org/abs/2603.01502
-
[29]
A. Grattafioriet al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[31]
Distilling conversations: Abstract compression of conversational audio context for llm-based asr,
S. Kumar, E. Villatoro-Tello, S. Burdisso, K. Hacioglu, T. Ba ˜neras- Roux, H. Watawana, D. Sanchez-Cortes, S. Madikeri, P. Motlicek, and A. Stolcke, “Distilling conversations: Abstract compression of conversational audio context for llm-based asr,” 2026. [Online]. Available: https://arxiv.org/abs/2603.26246
-
[32]
Text-only adaptation in llm-based asr through text denoising,
A. Carofilis, S. Burdisso, E. Villatoro-Tello, S. Kumar, K. Hacioglu, S. Madikeri, P. Rangappa, M. K. E, P. Motlicek, S. Venkatesan, and A. Stolcke, “Text-only adaptation in llm-based asr through text denoising,” 2026. [Online]. Available: https://arxiv.org/abs/2601.20900
-
[33]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guo, X. Zhang, P. Zhang, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-tts technical report,” 2026. [Online]. Available: https://arxiv.org/abs/2601.15621
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Ma, Z. Gao, and Z. Yan, “Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,” 2024. [Online]. Available: https://arxiv.org/abs/2407.05407
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model,
E. Casanova, K. Davis, E. G ¨olge, G. G ¨oknar, I. Gulea, L. Hart, A. Alja- fari, J. Meyer, R. Morais, S. Olayemi, and J. Weber, “XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model,” inInterspeech 2024, 2024, pp. 4978–4982
2024
-
[36]
Parler-tts,
Y . Lacombe, V . Srivastav, and S. Gandhi, “Parler-tts,” https://github.com/ huggingface/parler-tts, 2024
2024
-
[37]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “Indextts2: A breakthrough in emotionally expressive and duration- controlled auto-regressive zero-shot text-to-speech,” 2025. [Online]. Available: https://arxiv.org/abs/2506.21619
-
[38]
OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
H. Zhu, L. Ye, W. Kang, Z. Yao, L. Guo, F. Kuang, Z. Han, W. Zhuang, L. Lin, and D. Povey, “Omnivoice: Towards omnilingual zero-shot text- to-speech with diffusion language models,” 2026. [Online]. Available: https://arxiv.org/abs/2604.00688
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Chatterbox-TTS,
Resemble AI, “Chatterbox-TTS,” https://github.com/resemble-ai/ chatterbox, 2025, gitHub repository
2025
-
[40]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5220–5224
2017
-
[41]
Building and evaluation of a real room impulse response dataset,
I. Sz ¨oke, M. Sk ´acel, L. Mo ˇsner, J. Paliesek, and J. ˇCernock´y, “Building and evaluation of a real room impulse response dataset,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 4, pp. 863–876, 2019
2019
-
[42]
pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe,
H. Bredin, “pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe,” inInterspeech 2023, 2023, pp. 1983–1987
2023
-
[43]
UTMOS: UTokyo-SaruLab System for V oiceMOS Chal- lenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oiceMOS Chal- lenge 2022,” inInterspeech 2022, 2022, pp. 4521–4525
2022
-
[44]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.