AB-RAG: Adaptive Budgeted Retrieval-Augmented Generation for Reliable Question Answering
Pith reviewed 2026-06-30 09:09 UTC · model grok-4.3
The pith
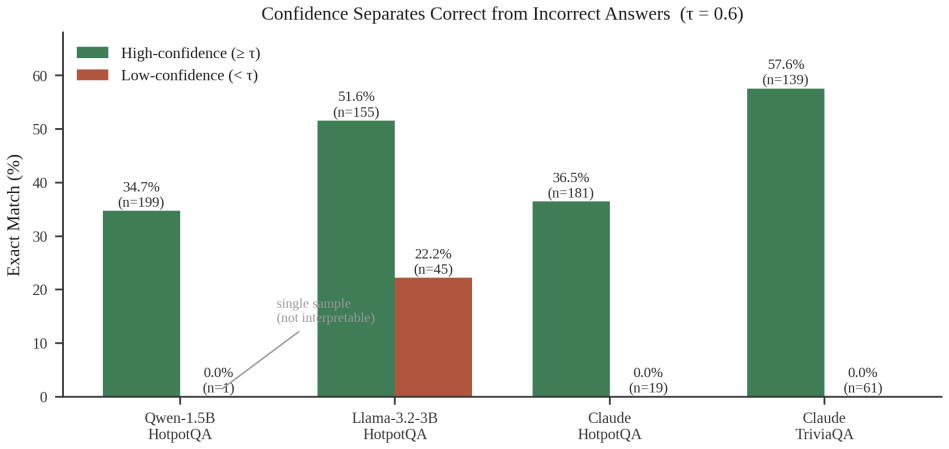
A training-free confidence score from model certainty, evidence agreement and retrieval variance separates correct RAG answers from incorrect ones at 57.6 percent versus zero percent exact match.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
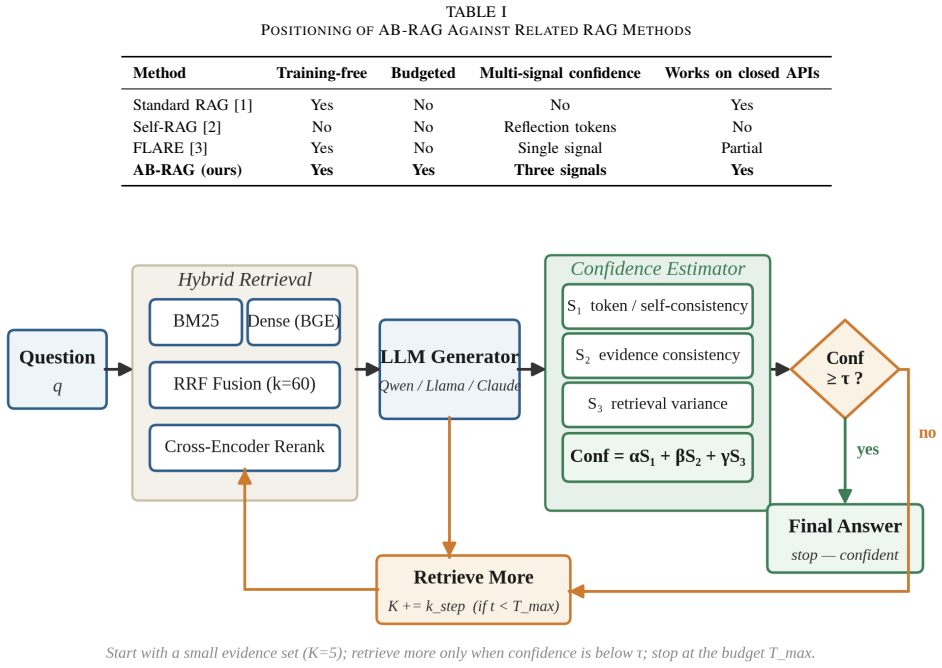
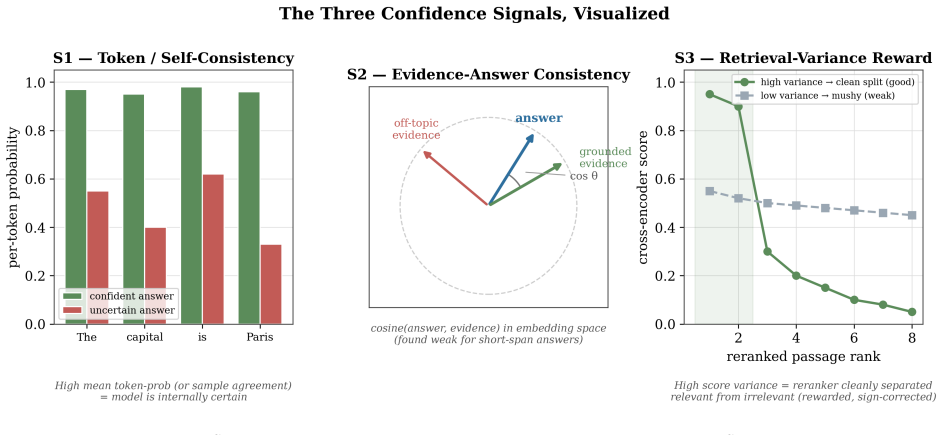
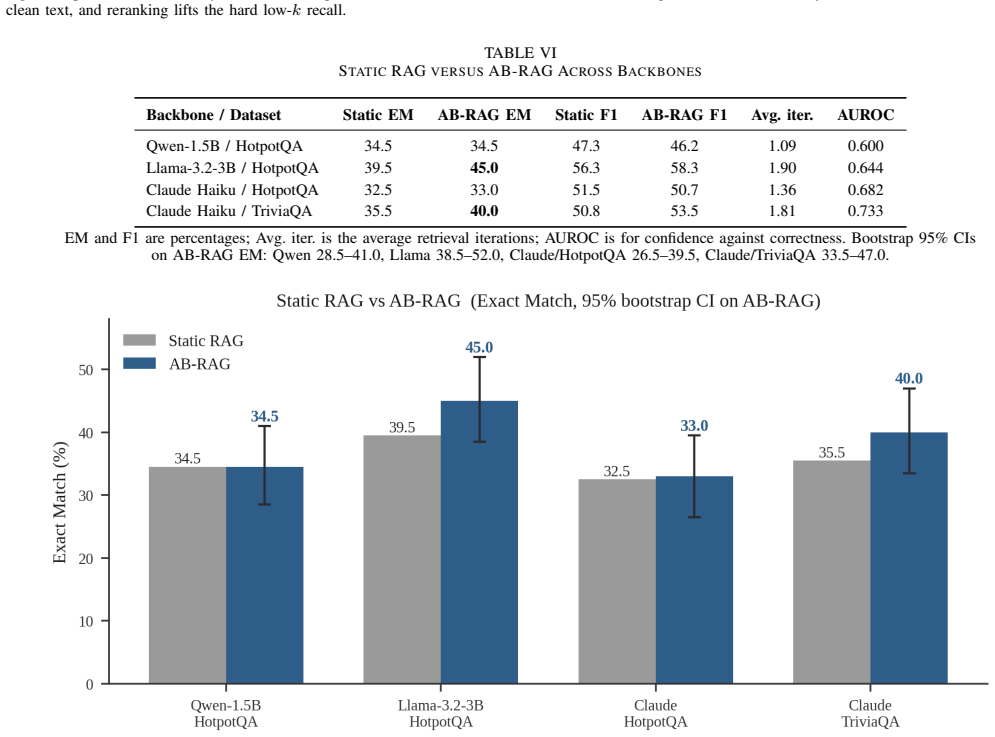
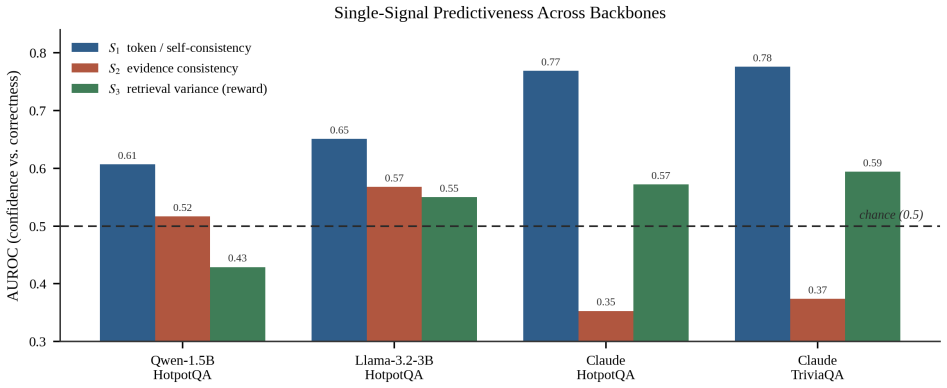
AB-RAG generates an answer, estimates its confidence from the model's own certainty (read directly or approximated by self-consistency), the agreement between the answer and the retrieved evidence, and the variance of the retrieval scores, then decides whether to stop or to retrieve more passages subject to a fixed budget. Across three backbones and two datasets the resulting confidence estimate reliably separates correct from incorrect answers, reaching a 57.6 percent versus zero percent exact-match split between high- and low-confidence answers on a factoid dataset.
What carries the argument
The adaptive confidence estimator that combines model certainty, answer-evidence agreement, and retrieval-score variance to allocate a fixed retrieval budget and to flag answer trustworthiness.
If this is right
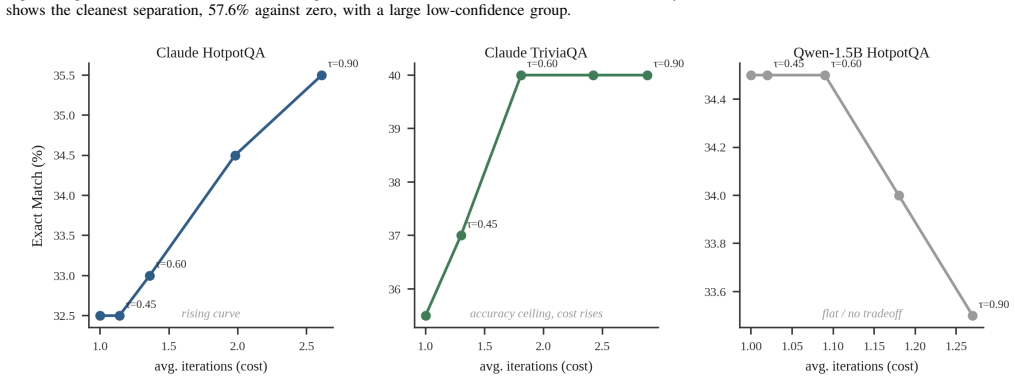
- The adaptive retrieval policy improves accuracy on capable backbones while respecting a fixed budget.
- The method works on closed commercial APIs by substituting self-consistency for direct token probabilities.
- The confidence signal proved unsuitable for short answers.
- The sign of the retrieval-score-variance signal was identified and corrected by direct measurement.
Where Pith is reading between the lines
- The same three signals might be repurposed to decide when an answer should be withheld rather than improved by more retrieval.
- Because the method is backbone-agnostic and training-free, it could be inserted as a wrapper around existing RAG pipelines that already use commercial APIs.
- If the separation generalizes, developers could route low-confidence questions to human review or to a stronger model while keeping high-confidence questions fully automatic.
Load-bearing premise
The linear or rule-based combination of the three raw signals produces a generalizable confidence score that does not require dataset-specific tuning or post-hoc threshold selection.
What would settle it
A new dataset or backbone on which high-confidence answers achieve exact-match rates no higher than low-confidence answers would falsify the claimed separation.
Figures



read the original abstract
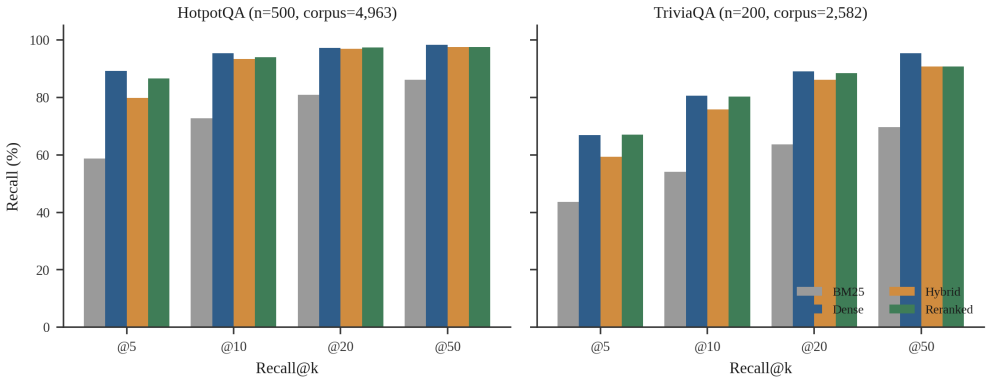
Retrieval-Augmented Generation (RAG) has become the standard way to ground large language models in external knowledge, yet most systems retrieve a fixed number of passages for every question regardless of its difficulty. This wastes computation on easy questions, starves hard ones, and gives no signal for when a generated answer can be trusted. With a growing share of question answering systems built on top of commercial language model APIs, a method that can decide how much to retrieve, and how far to trust its own answers, without retraining the underlying model, is of clear practical value. This paper presents AB-RAG (Adaptive Budgeted Retrieval-Augmented Generation), a training-free and backbone-agnostic framework that generates an answer, estimates its confidence from a combination of three signals, and then decides whether to stop or to retrieve more evidence, subject to a fixed retrieval budget. The estimator combines the model's own certainty, the agreement between the answer and the evidence, and the variance of the retrieval scores. For models that expose token probabilities the certainty signal is read directly; for closed APIs it is approximated by self-consistency, so the method works without access to model internals. Across three backbones and two datasets, the central result is that the confidence estimate reliably separates correct from incorrect answers on every backbone, reaching a clean split of 57.6% against 0% Exact Match between high- and low-confidence answers on a factoid dataset. The adaptive policy improves accuracy on capable backbones, and the study reports its negative and nuanced findings honestly, including a confidence signal that proved unsuitable for short answers and a retrieval signal whose sign was found and corrected through measurement. The entire study was carried out on a single consumer laptop with only a few dollars of API spend.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AB-RAG, a training-free, backbone-agnostic framework for adaptive budgeted RAG. It generates an answer, computes a confidence score from three signals (model certainty or self-consistency, answer-evidence agreement, and retrieval-score variance), and decides whether to retrieve additional passages within a fixed budget. The central empirical claim is that this confidence estimator reliably separates correct from incorrect answers across three backbones and two datasets, achieving a 57.6% vs. 0% Exact Match split between high- and low-confidence answers on a factoid dataset; the adaptive policy also improves accuracy on capable backbones. Negative findings (unsuitability of the signal for short answers, sign correction on one retrieval feature) are reported.
Significance. If the separation result holds with a fixed, a-priori combination rule, the work is significant for offering a practical, low-cost method to improve both efficiency and trustworthiness of RAG systems that rely on commercial APIs, without retraining or internal access. The explicit reporting of negative results and the modest experimental budget (consumer laptop, few dollars of API spend) strengthen the contribution by demonstrating real-world applicability and honest evaluation.
major comments (2)
- [Abstract / §3 (method)] Abstract and method description: the central claim that the confidence estimator 'reliably separates correct from incorrect answers on every backbone' reaching a 'clean split of 57.6% against 0% Exact Match' is load-bearing, yet no equation, pseudocode, or explicit rule is provided for how the three raw signals are normalized, weighted, or combined into a single score, nor how the high/low threshold is selected. Without this, it is impossible to verify that the reported separation uses a fixed a-priori rule rather than post-hoc tuning on the evaluation set.
- [§4 (experiments)] Experiments section: the reported separation numbers are given without error bars, confidence intervals, or statistical tests, and without explicit baseline comparisons (e.g., single-signal ablations or standard uncertainty estimators). This weakens the claim that the three-signal combination is responsible for the clean split, especially given the note that one signal required sign correction after measurement.
minor comments (2)
- [Abstract] The abstract states concrete separation numbers but provides no description of dataset statistics, number of questions, or exact definition of 'factoid dataset,' making it hard to assess generalizability.
- [§3] Minor notation inconsistency: 'retrieval-score variance' is listed as a signal, but the sign-correction note implies the raw feature was inverted; clarify the final definition used in the estimator.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the practical value of a training-free adaptive RAG method. We address each major comment below and will revise the manuscript to improve clarity and rigor where the points are valid.
read point-by-point responses
-
Referee: [Abstract / §3 (method)] Abstract and method description: the central claim that the confidence estimator 'reliably separates correct from incorrect answers on every backbone' reaching a 'clean split of 57.6% against 0% Exact Match' is load-bearing, yet no equation, pseudocode, or explicit rule is provided for how the three raw signals are normalized, weighted, or combined into a single score, nor how the high/low threshold is selected. Without this, it is impossible to verify that the reported separation uses a fixed a-priori rule rather than post-hoc tuning on the evaluation set.
Authors: We agree that the absence of an explicit combination rule limits verifiability. The manuscript will be revised to include in §3 the precise normalization procedure for each signal, the fixed linear combination formula, the a-priori weights (determined on a separate development set disjoint from the reported test sets), and the threshold selection criterion. Pseudocode for the full estimator and decision policy will also be added. This documentation will confirm that the rule is fixed prior to evaluation and not tuned on the test data. revision: yes
-
Referee: [§4 (experiments)] Experiments section: the reported separation numbers are given without error bars, confidence intervals, or statistical tests, and without explicit baseline comparisons (e.g., single-signal ablations or standard uncertainty estimators). This weakens the claim that the three-signal combination is responsible for the clean split, especially given the note that one signal required sign correction after measurement.
Authors: We accept that error bars, confidence intervals, and explicit baseline comparisons would strengthen the empirical claims. The revised experiments section will report bootstrap or multi-run standard errors for the separation metrics and will include single-signal ablations plus a standard entropy-based uncertainty baseline where token probabilities are available. The sign correction for the retrieval variance feature was performed on a small held-out development set before any test-set evaluation; we will clarify the timeline and data separation in the text. Given the modest experimental budget noted in the paper, full multi-seed runs across all backbones may be limited, but we will add what is feasible. revision: partial
Circularity Check
No significant circularity in the confidence estimator derivation
full rationale
The paper defines the AB-RAG confidence estimator directly from three observable signals (model certainty via token probabilities or self-consistency, answer-evidence agreement, and retrieval-score variance) without any equations or self-citations that reduce the reported separation to a fitted parameter or post-hoc threshold chosen on the evaluation outcomes. The framework is presented as training-free with a fixed combination rule applied across backbones and datasets; negative findings are reported explicitly. No load-bearing step reduces the central claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs produce token probabilities or self-consistent outputs that can serve as a usable certainty signal
- domain assumption Answer-evidence agreement and retrieval-score variance are independent of the model's internal parameters
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 9459–9474
2020
-
[2]
Self-RAG: Learning to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-RAG: Learning to retrieve, generate, and critique through self-reflection,” in International Conference on Learning Representations (ICLR), 2024
2024
-
[3]
Active retrieval augmented generation,
Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y . Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” in Proc. Conference on Empirical Methods in Natural Language Process- ing (EMNLP), 2023, pp. 7969–7992
2023
-
[4]
Learning to lead themselves: Agentic AI in MAS using MARL,
A. Kamthan, “Learning to lead themselves: Agentic AI in MAS using MARL,” 2025, arXiv:2510.00022
-
[5]
Retrieval augmentation reduces hallucination in conversation,
K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston, “Retrieval augmentation reduces hallucination in conversation,”Findings of the Association for Computational Linguistics: EMNLP, pp. 3784–3803, 2021. 14
2021
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProc. International Conference on Machine Learning (ICML), 2017, pp. 1321–1330
2017
-
[8]
Language Models (Mostly) Know What They Know
S. Kadavathet al., “Language models (mostly) know what they know,” arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. O ˘guz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inProc. Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 6769–6781
2020
-
[10]
REALM: Retrieval-augmented language model pre-training,
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M.-W. Chang, “REALM: Retrieval-augmented language model pre-training,” inProc. Interna- tional Conference on Machine Learning (ICML), 2020, pp. 3929–3938
2020
-
[11]
Improving language models by retrieving from trillions of tokens,
S. Borgeaudet al., “Improving language models by retrieving from trillions of tokens,” inProc. International Conference on Machine Learning (ICML), 2022, pp. 2206–2240
2022
-
[12]
Leveraging passage retrieval with generative models for open domain question answering,
G. Izacard and E. Grave, “Leveraging passage retrieval with generative models for open domain question answering,” inProc. Conf. European Chapter of the ACL (EACL), 2021, pp. 874–880
2021
-
[13]
In-context retrieval-augmented language mod- els,
O. Ram, Y . Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton- Brown, and Y . Shoham, “In-context retrieval-augmented language mod- els,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 1316–1331, 2023
2023
-
[14]
Efficient nearest neighbor language models,
J. He, G. Neubig, and T. Berg-Kirkpatrick, “Efficient nearest neighbor language models,” inProc. Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021, pp. 5703–5714
2021
-
[15]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023
2023
-
[16]
WebGPT: Browser-assisted question-answering with human feedback
R. Nakanoet al., “WebGPT: Browser-assisted question-answering with human feedback,” inarXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive NLP,
O. Khattab, K. Santhanam, X. L. Li, D. Hall, P. Liang, C. Potts, and M. Zaharia, “Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive NLP,” inarXiv preprint arXiv:2212.14024, 2022
-
[18]
Measuring and narrowing the compositionality gap in language mod- els,
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis, “Measuring and narrowing the compositionality gap in language mod- els,” inFindings of the Association for Computational Linguistics: EMNLP, 2023, pp. 5687–5711
2023
-
[19]
BEIR: A heterogeneous benchmark for zero-shot evaluation of infor- mation retrieval models,
N. Thakur, N. Reimers, A. R ¨uckl´e, A. Srivastava, and I. Gurevych, “BEIR: A heterogeneous benchmark for zero-shot evaluation of infor- mation retrieval models,” inProc. NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[20]
Natural questions: A benchmark for question answering research,
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikhet al., “Natural questions: A benchmark for question answering research,” in Transactions of the Association for Computational Linguistics, vol. 7, 2019, pp. 453–466
2019
-
[21]
ExpertQA: Expert-curated questions and attributed answers,
C. Malaviya, S. Lee, S. Chen, E. Sieber, M. Yatskar, and D. Roth, “ExpertQA: Expert-curated questions and attributed answers,” inProc. NAACL, 2024, pp. 3025–3045
2024
-
[22]
Language models as knowledge bases?
F. Petroni, T. Rockt ¨aschel, S. Riedel, P. Lewis, A. Bakhtin, Y . Wu, and A. Miller, “Language models as knowledge bases?”Proc. Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 2463–2473, 2019
2019
-
[23]
Reducing hallucination in structured outputs via retrieval-augmented generation,
P. B ´echard and O. M. Ayala, “Reducing hallucination in structured outputs via retrieval-augmented generation,” inProc. NAACL: Industry Track, 2024, pp. 228–238
2024
-
[24]
Atlas: Few-shot learning with retrieval augmented language models,
G. Izacard, P. Lewis, M. Lomeli, L. Hosseini, F. Petroni, T. Schick, J. Dwivedi-Yu, A. Joulin, S. Riedel, and E. Grave, “Atlas: Few-shot learning with retrieval augmented language models,” inJournal of Machine Learning Research, vol. 24, 2023, pp. 1–43
2023
-
[25]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 24 824–24 837
2022
-
[26]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[27]
RAGAS: Au- tomated evaluation of retrieval augmented generation,
S. Es, J. James, L. Espinosa-Anke, and S. Schockaert, “RAGAS: Au- tomated evaluation of retrieval augmented generation,” inProc. EACL: System Demonstrations, 2024, pp. 150–158
2024
-
[28]
Benchmarking large language models in retrieval-augmented generation,
J. Chen, H. Lin, X. Han, and L. Sun, “Benchmarking large language models in retrieval-augmented generation,” inProc. AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 17 754–17 762
2024
-
[29]
Interleav- ing retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Interleav- ing retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,” inProc. Annual Meeting of the Association for Computational Linguistics (ACL), 2023, pp. 10 014–10 037
2023
-
[30]
Enhanc- ing retrieval-augmented large language models with iterative retrieval- generation synergy,
Z. Shao, Y . Gong, Y . Shen, M. Huang, N. Duan, and W. Chen, “Enhanc- ing retrieval-augmented large language models with iterative retrieval- generation synergy,” inFindings of the Association for Computational Linguistics: EMNLP, 2023, pp. 9248–9274
2023
-
[31]
Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity,
S. Jeong, J. Baek, S. Cho, S. J. Hwang, and J. C. Park, “Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity,” inProc. NAACL, 2024, pp. 7036–7050
2024
-
[32]
Borui Yang, Md Afif Al Mamun, Jie M Zhang, and Gias Uddin
N. Varshney, W. Yao, H. Zhang, J. Chen, and D. Yu, “A stitch in time saves nine: Detecting and mitigating hallucinations of LLMs by vali- dating low-confidence generation,” inarXiv preprint arXiv:2307.03987, 2023
-
[33]
The probabilistic relevance framework: BM25 and beyond,
S. Robertson and H. Zaragoza, “The probabilistic relevance framework: BM25 and beyond,”Foundations and Trends in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009
2009
-
[34]
Okapi at TREC-3,
S. E. Robertson, S. Walker, S. Jones, M. M. Hancock-Beaulieu, and M. Gatford, “Okapi at TREC-3,” inProc. Third Text REtrieval Confer- ence (TREC-3), 1995, pp. 109–126
1995
-
[35]
C-Pack: Packed resources for general Chinese embeddings,
S. Xiao, Z. Liu, P. Zhang, and N. Muennighoff, “C-Pack: Packed resources for general Chinese embeddings,” inProc. Int. ACM SIGIR Conf. Research and Development in Information Retrieval, 2024, pp. 641–649
2024
-
[36]
Reciprocal rank fusion outperforms Condorcet and individual rank learning methods,
G. V . Cormack, C. L. A. Clarke, and S. B ¨uttcher, “Reciprocal rank fusion outperforms Condorcet and individual rank learning methods,” in Proc. Int. ACM SIGIR Conf. Research and Development in Information Retrieval, 2009, pp. 758–759
2009
-
[37]
R. Nogueira and K. Cho, “Passage re-ranking with BERT,”arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[38]
MS MARCO: A human generated machine reading comprehension dataset,
T. Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiwary, R. Majumder, and L. Deng, “MS MARCO: A human generated machine reading comprehension dataset,” inProc. Workshop on Cognitive Computation (NeurIPS), 2016
2016
-
[39]
ColBERT: Efficient and effective passage search via contextualized late interaction over BERT,
O. Khattab and M. Zaharia, “ColBERT: Efficient and effective passage search via contextualized late interaction over BERT,” inProc. Int. ACM SIGIR Conf. Research and Development in Information Retrieval, 2020, pp. 39–48
2020
-
[40]
How can we know when language models know? On the calibration of language models for question answering,
Z. Jiang, J. Araki, H. Ding, and G. Neubig, “How can we know when language models know? On the calibration of language models for question answering,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 962–977, 2021
2021
-
[41]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inInternational Conference on Learning Repre- sentations (ICLR), 2023
2023
-
[42]
Dropout as a Bayesian approximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a Bayesian approximation: Representing model uncertainty in deep learning,” inProc. International Conference on Machine Learning (ICML), 2016, pp. 1050–1059
2016
-
[43]
When not to trust language models: Investigating the effectiveness of parametric and non-parametric memories,
A. Mallen, A. Asai, V . Zhong, R. Das, D. Khashabi, and H. Hajishirzi, “When not to trust language models: Investigating the effectiveness of parametric and non-parametric memories,” inProc. Annual Meeting of the Association for Computational Linguistics (ACL), 2023, pp. 9802– 9822
2023
-
[44]
Teaching models to express their uncertainty in words,
S. Lin, J. Hilton, and O. Evans, “Teaching models to express their uncertainty in words,” inTransactions on Machine Learning Research, 2022
2022
-
[45]
Prompting GPT-3 to be reliable,
C. Si, Z. Gan, Z. Yang, S. Wang, J. Wang, J. Boyd-Graber, and L. Wang, “Prompting GPT-3 to be reliable,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[46]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[47]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszkeet al., “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019, pp. 8024–8035
2019
-
[48]
Transformers: State-of-the-art natural language process- ing,
T. Wolfet al., “Transformers: State-of-the-art natural language process- ing,” inProc. EMNLP: System Demonstrations, 2020, pp. 38–45. 15
2020
-
[49]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535– 547, 2021
2021
-
[50]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inProc. Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019, pp. 3982– 3992
2019
-
[51]
HotpotQA: A dataset for diverse, explainable multi- hop question answering,
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “HotpotQA: A dataset for diverse, explainable multi- hop question answering,” inProc. Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018, pp. 2369–2380
2018
-
[52]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,” inProc. Annual Meeting of the Association for Computational Linguis- tics (ACL), 2017, pp. 1601–1611
2017
-
[53]
A. Yanget al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
A. Dubeyet al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
The Claude 3 model family: Opus, Sonnet, Haiku,
Anthropic, “The Claude 3 model family: Opus, Sonnet, Haiku,” An- thropic, Tech. Rep., 2024. 16
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.