Symbolic Mechanistic Data Attribution: Tracing Training Influence to Learned Behavioral Policies
Pith reviewed 2026-06-30 08:00 UTC · model grok-4.3
The pith
SMDA attributes individual training examples to the symbolic policies that govern a model's high-level behaviors by regressing over sparse autoencoder features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
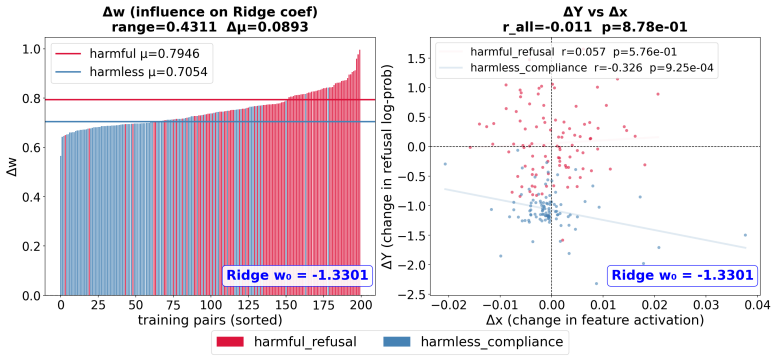
SMDA models a target behavior as a ridge regression over sparse autoencoder features, then analytically decomposes each training pair's contribution into Delta_X (feature activation change) and Delta_Y (output probability change) pathways; when applied to 200 SFT pairs for refusal in Llama-3.2-3B-Instruct, the resulting symbolic policy coefficients reveal gaps such as religious stereotyping, per-feature decompositions distinguish harmful from harmless pairs, and cross-feature interference appears in many individual examples.
What carries the argument
The SMDA framework, which fits a closed-form ridge regression over sparse autoencoder features to represent a target behavior and decomposes each training example's policy shift through separate Delta_X activation and Delta_Y probability pathways.
If this is right
- Coefficients of the fitted symbolic policy can identify categories where the base model has systematic safety gaps, such as religious stereotyping.
- Per-feature Delta_X/Delta_Y decomposition can explain why harmful versus harmless pairs produce qualitatively different effects on the same features.
- Many individual training pairs exhibit cross-feature interference, so their largest influence lands on features other than the intended policy component.
- The same decomposition can flag training examples whose net effect on the symbolic policy is unintended or counterproductive.
Where Pith is reading between the lines
- The method could be used to rank or filter future SFT data by predicted policy impact before training begins.
- If the symbolic policy generalizes across model scales, the same regression could serve as a lightweight monitor for behavioral drift during continued pretraining.
- Extending the decomposition to multi-turn conversations might reveal how early pairs shape later refusal thresholds in dialogue settings.
Load-bearing premise
The ridge regression fit over sparse autoencoder features produces coefficients and Delta pathways that faithfully represent the high-level behavioral decisions the model has actually learned.
What would settle it
Retraining the model on a subset of pairs selected by SMDA's dominant Delta_X/Delta_Y pathways and finding that the observed change in refusal behavior does not match the magnitude or direction predicted by the symbolic policy coefficients.
Figures

read the original abstract
While existing data attribution methods can identify which training examples build specific mechanistic circuits, they cannot explain how training data shapes the high-level behavioral decisions a model learns to make. To bridge this gap, we introduce Symbolic Mechanistic Data Attribution (SMDA), a framework that attributes training pairs to the interpretable symbolic policies governing model behavior. SMDA fits a closed-form Ridge regression over sparse autoencoder (SAE) features to model a target behavior, then analytically decomposes how each supervised fine-tuning example shifts that policy through feature-activation Delta_X and output-probability Delta_Y pathways. We distill a symbolic policy for refusal behavior in Llama-3.2-3B-Instruct and analyze 200 SFT training pairs. Our analysis reveals that (1) the symbolic policy's coefficients expose systematic gaps in the base model's safety behavior for categories like religious stereotyping; (2) per-feature Delta_X/Delta_Y decomposition can mechanistically explain why harmful and harmless pairs exert qualitatively different influences on certain features; and (3) individual training pairs routinely exhibit cross-feature interference, allowing SMDA to identify training pairs whose dominant effect falls on unintended features. These results demonstrate that combining mechanistic interpretability with data attribution yields a diagnostic tool that is both more fine-grained than black-box influence functions and more scalable than manual circuit analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Symbolic Mechanistic Data Attribution (SMDA), which fits a closed-form ridge regression over SAE features to distill an interpretable symbolic policy for a target behavior such as refusal in Llama-3.2-3B-Instruct, then analytically decomposes the influence of each SFT training pair on that policy through feature-activation shifts (Delta_X) and output-probability changes (Delta_Y). The framework is applied to 200 training pairs, yielding three qualitative findings: the policy coefficients reveal safety gaps (e.g., religious stereotyping), harmful versus harmless pairs exert different per-feature influences, and individual pairs show cross-feature interference that can be diagnosed by SMDA.
Significance. If the linear ridge-regression policy is shown to faithfully approximate the model's nonlinear refusal decisions, SMDA would supply a scalable bridge between data attribution and mechanistic interpretability, offering finer-grained, feature-level explanations than black-box influence functions while remaining more automated than manual circuit analysis. The closed-form nature of the Delta_X/Delta_Y decomposition is a technical strength that could enable reproducible attribution once the fidelity assumption is validated.
major comments (3)
- [Abstract and §3 (framework)] Abstract and framework introduction (refusal policy distillation): the central claim that the ridge-regression coefficients and Delta_X/Delta_Y pathways 'faithfully represent the high-level behavioral decisions' the model has learned is load-bearing for all three reported findings, yet the manuscript supplies no quantitative validation such as held-out predictive accuracy of the linear policy on refusal prompts, ablation on the regularization parameter, or causal intervention results on the identified SAE features.
- [Method (decomposition)] Method for Delta_X/Delta_Y decomposition: because the decomposition is obtained analytically from the same ridge-regression parameters used to define the symbolic policy, it is not obvious that the reported influences constitute independent mechanistic evidence rather than a direct consequence of the linear fit; this circularity must be addressed by showing that the pathways predict actual model behavior changes under feature edits.
- [Results (§5)] Results on 200 SFT pairs: the three qualitative observations (safety gaps, differential influences, cross-feature interference) rest on the unverified linear approximation; without baselines (e.g., comparison of SMDA attributions against standard influence functions or random feature perturbations) or error bars on the per-feature effects, it is unclear whether the patterns are distinctive or artifacts of the ridge fit.
minor comments (2)
- [Method] Notation for Delta_X and Delta_Y should be defined with explicit equations in the main text rather than relying solely on the abstract description.
- [Experimental setup] The choice of SAE features and the specific refusal-related features analyzed should be listed or tabulated for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify the need for stronger empirical validation of the linear policy approximation, which we will address through targeted additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3 (framework)] Abstract and framework introduction (refusal policy distillation): the central claim that the ridge-regression coefficients and Delta_X/Delta_Y pathways 'faithfully represent the high-level behavioral decisions' the model has learned is load-bearing for all three reported findings, yet the manuscript supplies no quantitative validation such as held-out predictive accuracy of the linear policy on refusal prompts, ablation on the regularization parameter, or causal intervention results on the identified SAE features.
Authors: We agree that quantitative validation is necessary to support the central claims. In the revision we will add held-out predictive accuracy of the ridge regression policy on refusal prompts and ablations over the regularization parameter. Preliminary feature-edit experiments will also be included to provide initial causal support where computationally feasible. revision: yes
-
Referee: [Method (decomposition)] Method for Delta_X/Delta_Y decomposition: because the decomposition is obtained analytically from the same ridge-regression parameters used to define the symbolic policy, it is not obvious that the reported influences constitute independent mechanistic evidence rather than a direct consequence of the linear fit; this circularity must be addressed by showing that the pathways predict actual model behavior changes under feature edits.
Authors: The analytical form is a deliberate design choice for reproducibility, yet we acknowledge the circularity concern. The revised manuscript will include validation experiments that intervene on the relevant SAE features and compare observed output-probability shifts against the predicted Delta_Y values. revision: yes
-
Referee: [Results (§5)] Results on 200 SFT pairs: the three qualitative observations (safety gaps, differential influences, cross-feature interference) rest on the unverified linear approximation; without baselines (e.g., comparison of SMDA attributions against standard influence functions or random feature perturbations) or error bars on the per-feature effects, it is unclear whether the patterns are distinctive or artifacts of the ridge fit.
Authors: We will augment the results section with direct comparisons of SMDA attributions against standard influence functions and random feature perturbations, and will report error bars (via bootstrapping) on the per-feature effects to quantify variability. revision: yes
Circularity Check
Ridge regression defines symbolic policy; Delta_X/Delta_Y attributions are analytic from the same fit
specific steps
-
fitted input called prediction
[Abstract]
"SMDA fits a closed-form Ridge regression over sparse autoencoder (SAE) features to model a target behavior, then analytically decomposes how each supervised fine-tuning example shifts that policy through feature-activation Delta_X and output-probability Delta_Y pathways."
The symbolic policy is defined by the ridge regression coefficients; the Delta_X/Delta_Y decomposition and all subsequent attributions of training-pair influence are closed-form functions of those same coefficients. Thus the reported influences on the policy are equivalent in content to the fitted parameters used to construct the policy model.
full rationale
The paper introduces SMDA by fitting ridge regression to SAE features to define the symbolic policy for a target behavior, then analytically decomposes training-pair influences via Delta_X/Delta_Y pathways. This decomposition is a direct algebraic consequence of the fitted coefficients, so the reported influences and policy insights (e.g., gaps in safety behavior, cross-feature interference) are downstream of and contain no independent information beyond the ridge fit itself. This matches the fitted_input_called_prediction pattern. No self-citation load-bearing steps or other enumerated circularity patterns are evident from the provided text. The central diagnostic claims therefore rest on the unverified assumption that the linear fit faithfully captures the model's nonlinear behavioral policy, but the derivation chain itself reduces to the fit by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Ridge regression regularization parameter
axioms (1)
- domain assumption Sparse autoencoder features correspond to interpretable mechanistic components that govern high-level behavioral policies.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of
Seungju Han and Kavel Rao and Allyson Ettinger and Liwei Jiang and Bill Yuchen Lin and Nathan Lambert and Yejin Choi and Nouha Dziri , booktitle=. WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of
-
[3]
Publications Manual , year = "1983", publisher =
1983
-
[4]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[5]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[6]
Dan Gusfield , title =. 1997
1997
-
[7]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[10]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems , volume=
Refusal in Language Models Is Mediated by a Single Direction , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[13]
2023 , eprint=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
2023
-
[14]
2026 , eprint=
Concept Influence: Leveraging Interpretability to Improve Performance and Efficiency in Training Data Attribution , author=. 2026 , eprint=
2026
-
[15]
arXiv preprint arXiv:2502.09100 , year=
Logical reasoning in large language models: A survey , author=. arXiv preprint arXiv:2502.09100 , year=
-
[17]
Do-Not-Answer: A Dataset for Evaluating Safeguards in
Wang, Yuxia and Li, Haonan and Han, Xudong and Nakov, Preslav and Baldwin, Timothy , journal=. Do-Not-Answer: A Dataset for Evaluating Safeguards in
-
[18]
International Conference on Learning Representations , year=
Finetuned Language Models Are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[19]
Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned
Betley, Jan and Tan, Daniel Chee Hian and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Mart. Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned. Proceedings of the 42nd International Conference on Machine Learning , pages=
-
[20]
Safety-Tuned
Federico Bianchi and Mirac Suzgun and Giuseppe Attanasio and Paul Rottger and Dan Jurafsky and Tatsunori Hashimoto and James Zou , booktitle=. Safety-Tuned. 2024 , url=
2024
-
[21]
Proceedings of the National Academy of Sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , volume=
-
[22]
Mechanistic Data Attribution: Tracing the Training Origins of Interpretable
Chen, Jianhui and others , journal=. Mechanistic Data Attribution: Tracing the Training Origins of Interpretable
-
[23]
2022 , howpublished=
Muennighoff, Niklas , title=. 2022 , howpublished=
2022
-
[24]
2023 , url=
Conover, Mike and Hayes, Matt and Mathur, Ankit and Xie, Jianwei and Wan, Jun and Shah, Sam and Ghodsi, Ali and Wendell, Patrick and Zaharia, Matei and Xin, Reynold , title=. 2023 , url=
2023
-
[25]
2024 , publisher=
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , booktitle=. 2024 , publisher=
2024
-
[26]
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , booktitle=
-
[27]
Bloom, Joseph and Tigges, Curt and Duong, Anthony and Chanin, David , year=
-
[28]
Hashimoto , title=
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title=. GitHub repository , howpublished=. 2023 , publisher=
2023
-
[29]
Mazeika, Mantas and Zou, Andy and Mu, Norman and Phan, Long and Wang, Zifan and Yu, Chunru and Khoja, Adam and Jiang, Fengqing and O'Gara, Aidan and Sakhaee, Ellie and Xiang, Zhen and Rajabi, Arezoo and Hendrycks, Dan and Poovendran, Radha and Li, Bo and Forsyth, David , booktitle=
-
[30]
International Conference on Learning Representations , year=
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation , author=. International Conference on Learning Representations , year=
-
[32]
International conference on machine learning , pages=
Understanding black-box predictions via influence functions , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[33]
Advances in neural information processing systems , volume=
Data distributional properties drive emergent in-context learning in transformers , author=. Advances in neural information processing systems , volume=
-
[34]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Towards tracing knowledge in language models back to the training data , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[35]
2025 , eprint=
Integrated Influence: Data Attribution with Baseline , author=. 2025 , eprint=
2025
-
[36]
2023 , eprint=
Studying Large Language Model Generalization with Influence Functions , author=. 2023 , eprint=
2023
-
[38]
2026 , eprint=
Beyond Accuracy: Introducing a Symbolic-Mechanistic Approach to Interpretable Evaluation , author=. 2026 , eprint=
2026
-
[39]
2025 , eprint=
Circuit Distillation , author=. 2025 , eprint=
2025
-
[40]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. Refusal in language models is mediated by a single direction. In Advances in Neural Information Processing Systems, volume 38
2024
-
[41]
Jan Betley, Daniel Chee Hian Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Mart \' n Soto, Nathan Labenz, and Owain Evans. 2025. Emergent misalignment: Narrow finetuning can produce broadly misaligned LLM s. In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 4043--4...
2025
-
[42]
Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Rottger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou. 2024. https://openreview.net/forum?id=gT5hALch9z Safety-tuned LL a MA s: Lessons from improving the safety of large language models that follow instructions . In The Twelfth International Conference on Learning Representations
2024
-
[43]
Joseph Bloom, Curt Tigges, Anthony Duong, and David Chanin. 2024. SAELens . https://github.com/jbloomAus/SAELens
2024
-
[44]
Stephanie Chan, Adam Santoro, Andrew Lampinen, Jane Wang, Aaditya Singh, Pierre Richemond, James McClelland, and Felix Hill. 2022. Data distributional properties drive emergent in-context learning in transformers. Advances in neural information processing systems, 35:18878--18891
2022
-
[45]
Jianhui Chen and 1 others. 2026. Mechanistic data attribution: Tracing the training origins of interpretable LLM units. arXiv preprint arXiv:2601.21996
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. 2023. https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm Free dolly: Introducing the world's first truly open instruction-tuned LLM
2023
-
[47]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. https://arxiv.org/abs/2309.08600 Sparse autoencoders find highly interpretable features in language models . Preprint, arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [48]
- [49]
-
[50]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLM s. In Advances in Neural Information Processing Systems, volume 37
2024
-
[51]
Yangsibo Huang, Samyak Gupta, Mengzhou Xia, Kai Li, and Danqi Chen. 2024. Catastrophic jailbreak of open-source llms via exploiting generation. In International Conference on Learning Representations
2024
-
[52]
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. 2024. WildTeaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models. In Advances in Neural Information Processing Systems
2024
-
[53]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, and 1 others. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521--3526
2017
-
[54]
Pang Wei Koh and Percy Liang. 2017. Understanding black-box predictions via influence functions. In International conference on machine learning, pages 1885--1894. PMLR
2017
-
[55]
Matthew Kowal, Goncalo Paulo, Louis Jaburi, Tom Tseng, Lev E McKinney, Stefan Heimersheim, Aaron David Tucker, Adam Gleave, and Kellin Pelrine. 2026. https://arxiv.org/abs/2602.14869 Concept influence: Leveraging interpretability to improve performance and efficiency in training data attribution . Preprint, arXiv:2602.14869
-
[56]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. HarmBench : A standardized evaluation framework for automated red teaming and robust refusal. In Proceedings of the 41st International Conference on Machine Learning, pages 35181--35224. PMLR
2024
-
[57]
Mantas Mazeika, Andy Zou, Norman Mu, Long Phan, Zifan Wang, Chunru Yu, Adam Khoja, Fengqing Jiang, Aidan O'Gara, Ellie Sakhaee, Zhen Xiang, Arezoo Rajabi, Dan Hendrycks, Radha Poovendran, Bo Li, and David Forsyth. 2023. TDC 2023 ( LLM edition): The trojan detection challenge. In NeurIPS Competition Track
2023
-
[58]
Niklas Muennighoff. 2022. FLAN dataset. https://huggingface.co/datasets/Muennighoff/flan
2022
-
[59]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, and 7 others. 2022. https://arxiv.org/abs/2209.11895 In-context learning and induct...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[60]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca
2023
- [61]
- [62]
-
[63]
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2022. Finetuned language models are zero-shot learners. In International Conference on Learning Representations
2022
-
[64]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.