Can OCR-VLMs Read Devanagari? A Stress-Test Benchmark and Post-Correction Study
Pith reviewed 2026-06-30 07:53 UTC · model grok-4.3
The pith
Real Devanagari scans cause nine of ten OCR systems to collapse, with scores spanning a 76-point range that synthetic tests hide.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
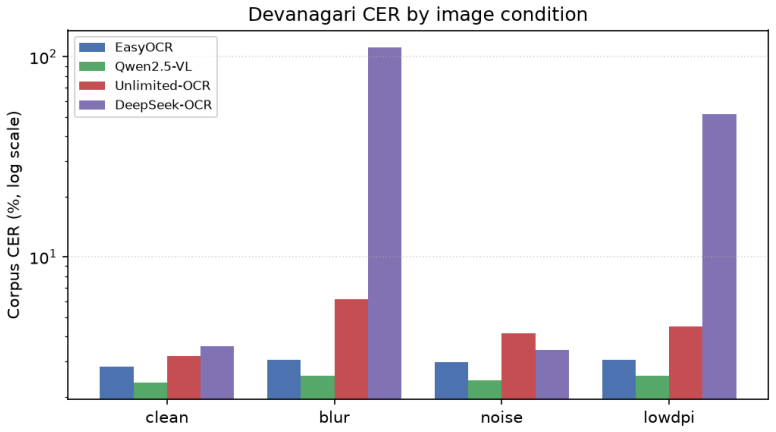
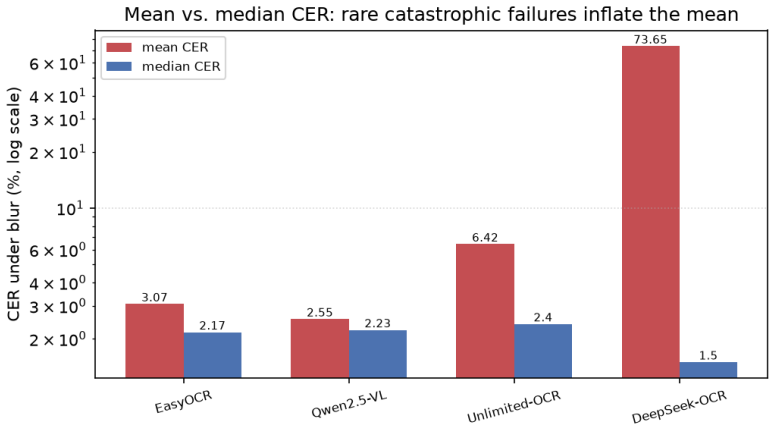
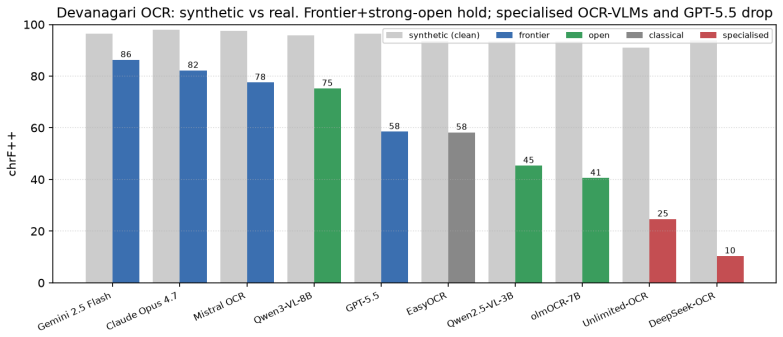
On real printed Devanagari scans nine of the ten systems collapse relative to synthetic conditions, EasyOCR falling from chrF++ 93.6 to 58.3 and the field spreading across a 76-point range, while synthetic renders keep all systems clustered within 91-98. Specialized OCR-VLMs show rare catastrophic repetition failures that distort mean scores, English OCR strength does not predict Indic results, and a ByT5 post-corrector raises performance on its training distribution but fails to generalize across engines.
What carries the argument
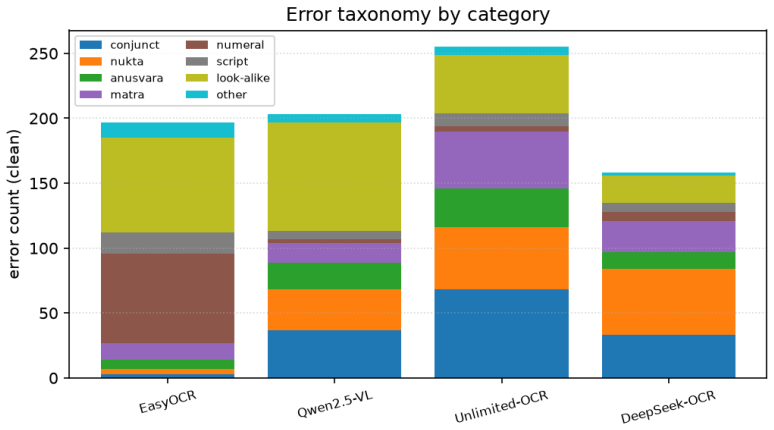
A benchmark of ten OCR systems across four synthetic degradation conditions and 300 real printed scans, measured by chrF++ and an error taxonomy that separates surface errors from structural ones such as conjuncts and matras.
If this is right
- Specialized OCR-VLMs remain fragile under degradation even when their median scores look strong.
- English OCR performance is a poor predictor of results on Devanagari.
- Byte-level post-correction yields gains only on the engine whose errors it was trained on.
- Synthetic text fails to separate model capabilities on Devanagari and therefore cannot substitute for real scans.
Where Pith is reading between the lines
- Evaluations of OCR for non-Latin scripts should rely primarily on real scanned documents rather than synthetic renders.
- Open models such as Qwen3-VL-8B can match or approach some closed frontier systems on this task while running on modest hardware.
- Future benchmarks would benefit from including handwritten or low-quality historical Devanagari material to test additional failure modes.
Load-bearing premise
The four synthetic degradation conditions and the 300 real printed scans are representative of the challenges faced by OCR systems on Devanagari documents in practice.
What would settle it
A larger test set of real Devanagari documents drawn from varied sources and print conditions in which all ten systems maintain chrF++ scores within a narrow band near their synthetic levels would falsify the claim that synthetic renders overstate quality.
Figures
read the original abstract
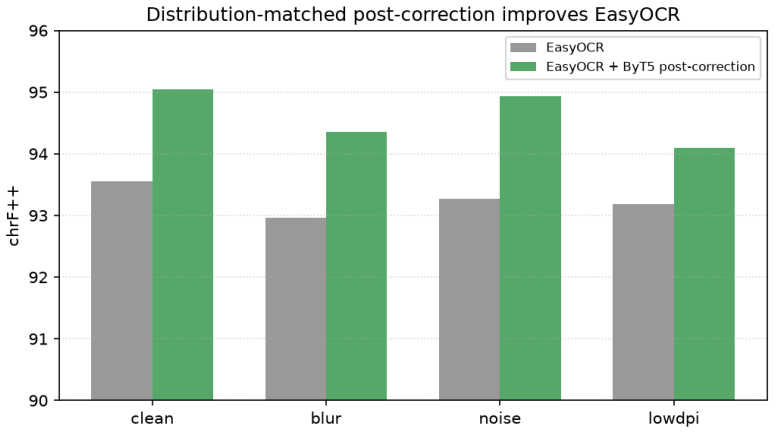
OCR systems, ranging from classical engines to specialised OCR vision-language models (OCR-VLMs) and frontier multimodal LLMs, report strong results on English and Chinese document benchmarks, yet their behaviour on Indic scripts is largely uncharacterised. We benchmark ten systems on Devanagari (Hindi): classical EasyOCR; open VLMs (Qwen2.5-VL-3B, Qwen3-VL-8B, olmOCR-7B); specialised OCR-VLMs (DeepSeek-OCR, Unlimited-OCR); and frontier closed models (Gemini 2.5 Flash, Claude Opus 4.7, GPT-5.5, Mistral OCR), across four synthetic degradation conditions and 300 real printed scans. We report four findings. First, on clean rendered text all ten cluster within chrF++ 91 to 98, so synthetic text does not separate them. Second, under degradation the specialised OCR-VLMs are the most fragile: DeepSeek-OCR suffers rare but catastrophic repetition failures (outputs up to 71 the reference length) that wreck its corpus mean even though its median is the best of any system, which is why we report median and catastrophic-rate instead of the mean. Third, on real scans nine of the ten systems collapse (EasyOCR falls from chrF++ 93.6 to 58.3) and the field spreads across a 76-point range, so synthetic renders badly overstate Devanagari quality. Fourth, strong English OCR does not predict Indic OCR: GPT-5.5 drops to chrF++ 58.5 (tying classical EasyOCR) and olmOCR-7B, the model behind olmOCR-Bench, falls to 40.5, while the open Qwen3-VL-8B (75.2, runnable on a single 24 GB GPU) beats GPT-5.5 and approaches Mistral; Gemini and Claude lead at 86.3 and 82.2. An error taxonomy separates surface errors (numerals, punctuation) from structural ones (conjuncts, matras, nukta), and a byte-level (ByT5) post-corrector improves a cheap engine on its own error distribution (chrF++ +1.2 to +1.5) but does not transfer across engines. We release the benchmark, code, and models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks ten OCR systems (classical EasyOCR, open VLMs like Qwen2.5-VL/Qwen3-VL/olmOCR, specialized OCR-VLMs like DeepSeek-OCR/Unlimited-OCR, and frontier models like Gemini/Claude/GPT/Mistral) on Devanagari using four synthetic degradation conditions and 300 real printed scans. Key findings: all systems cluster at high chrF++ (91-98) on clean synthetic text; specialized VLMs show fragility with rare catastrophic repetition failures (prompting median and catastrophic-rate metrics); nine of ten systems collapse on real scans (e.g., EasyOCR from 93.6 to 58.3, 76-point spread); English OCR performance does not predict Indic results; an error taxonomy distinguishes surface vs. structural errors; and a ByT5 post-corrector yields small gains on matched error distributions but does not transfer. The benchmark, code, and models are released.
Significance. If the real scans are representative, the results establish that synthetic benchmarks substantially overstate OCR quality on Devanagari and that current systems (including frontier models) have major gaps on Indic scripts, with the resource release aiding reproducibility. The switch to median/catastrophic-rate metrics is a sound response to observed failure modes.
major comments (2)
- [Dataset / real scans subsection] The section describing the 300 real printed scans provides no selection criteria, sources, document types, resolution/noise statistics, or diversity measures. This is load-bearing for the central claim (abstract and finding 3) that synthetic renders 'badly overstate Devanagari quality,' as the large drop (e.g., EasyOCR 93.6 o 58.3) and 76-point spread could reflect a non-representative subset rather than a general property of real Devanagari material.
- [§3 / synthetic degradation conditions] The implementation of the four synthetic degradation conditions lacks specific parameters or algorithms (e.g., exact noise models, blur kernels, or distortion levels). This undermines the comparison to real scans and the inference that synthetic conditions fail to capture practical challenges.
minor comments (2)
- [Abstract] Abstract: 'outputs up to 71 the reference length' is missing 'times'.
- [Post-correction study] Clarify whether the post-correction experiments include cross-validation or hold-out sets to support the claim of non-transfer across engines.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive comments on the need for greater transparency. We address each major comment below.
read point-by-point responses
-
Referee: [Dataset / real scans subsection] The section describing the 300 real printed scans provides no selection criteria, sources, document types, resolution/noise statistics, or diversity measures. This is load-bearing for the central claim (abstract and finding 3) that synthetic renders 'badly overstate Devanagari quality,' as the large drop (e.g., EasyOCR 93.6 to 58.3) and 76-point spread could reflect a non-representative subset rather than a general property of real Devanagari material.
Authors: We agree that additional details on the real scans are required to support the central claims. In the revised manuscript we will expand the relevant subsection to specify the sources (public-domain printed Hindi books and periodicals from digitized archives), document types, selection criteria (random sampling across available high-resolution scans), and any available statistics on resolution, noise, and diversity (e.g., number of unique documents and fonts). We will also note any limitations in representativeness. revision: yes
-
Referee: [§3 / synthetic degradation conditions] The implementation of the four synthetic degradation conditions lacks specific parameters or algorithms (e.g., exact noise models, blur kernels, or distortion levels). This undermines the comparison to real scans and the inference that synthetic conditions fail to capture practical challenges.
Authors: We acknowledge the need for precise implementation details. We will revise §3 to include the exact algorithms and parameters for each degradation condition (noise models, blur kernels with specific sizes and sigmas, distortion levels, etc.) together with references to the released code repository to ensure full reproducibility. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential reductions
full rationale
The paper is a benchmark study reporting measured performance of ten OCR systems on synthetic degradations and 300 real scans. It states four findings based on direct chrF++ comparisons (e.g., clean synthetic 91-98, real scans collapse to 58.3 for EasyOCR with 76-point spread). No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described structure. The representativeness concern raised by the skeptic is an external-validity issue, not a circular reduction of any claimed derivation to its own inputs. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Wei, Y. Sun, Y. Li. DeepSeek-OCR: Contexts Optical Compression. arXiv:2510.18234, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Y. Yin et al. Unlimited OCR Works. arXiv:2606.23050, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
S. Bai et al. Qwen2.5-VL Technical Report. arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
H. Wei et al. General OCR Theory: Towards OCR-2.0 via a Unified End-to-End Model. arXiv:2409.01704, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Ouyang et al
L. Ouyang et al. OmniDocBench. CVPR, 2025. 8 Figure 5: A ByT5 post-corrector trained on EasyOCR’s own error distribution improves EasyOCR chrF++ in every condition. 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.