Self-Organized Conformal Prediction: Reducing Regional Coverage Gaps with Unsupervised Group Discovery
Pith reviewed 2026-06-30 02:15 UTC · model grok-4.3
The pith
Self-Organized Conformal Prediction discovers input groups with a self-organizing map to reduce regional coverage gaps while preserving validity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
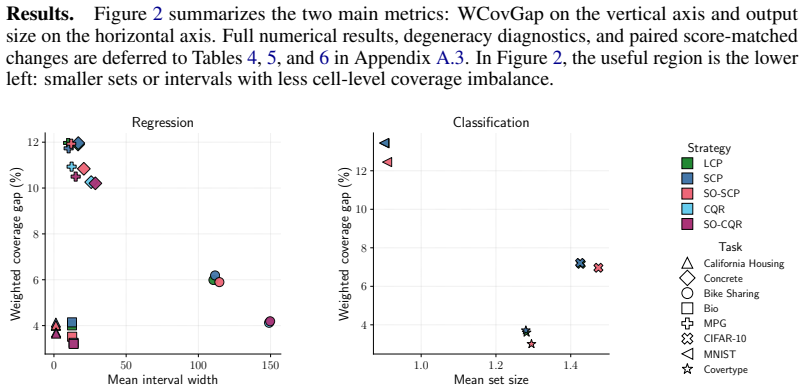
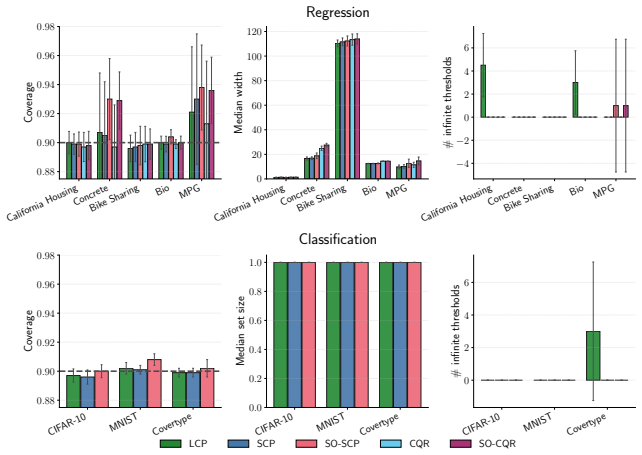
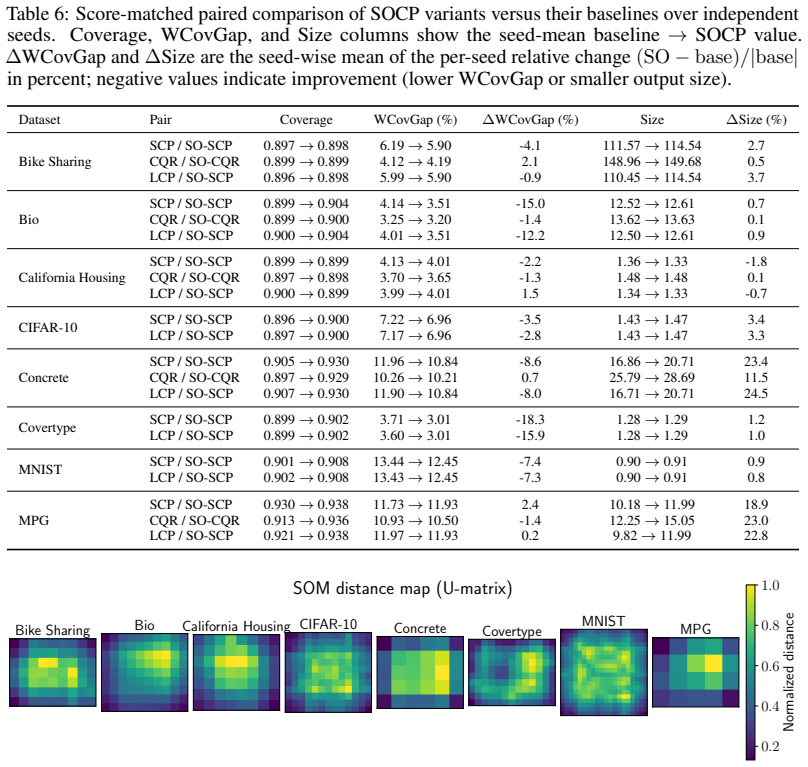
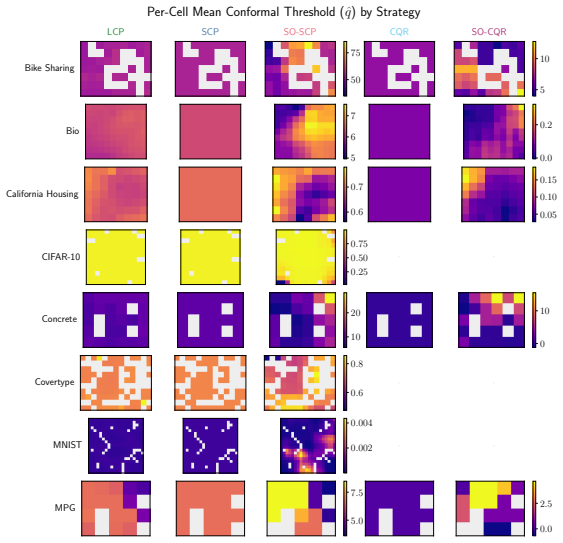
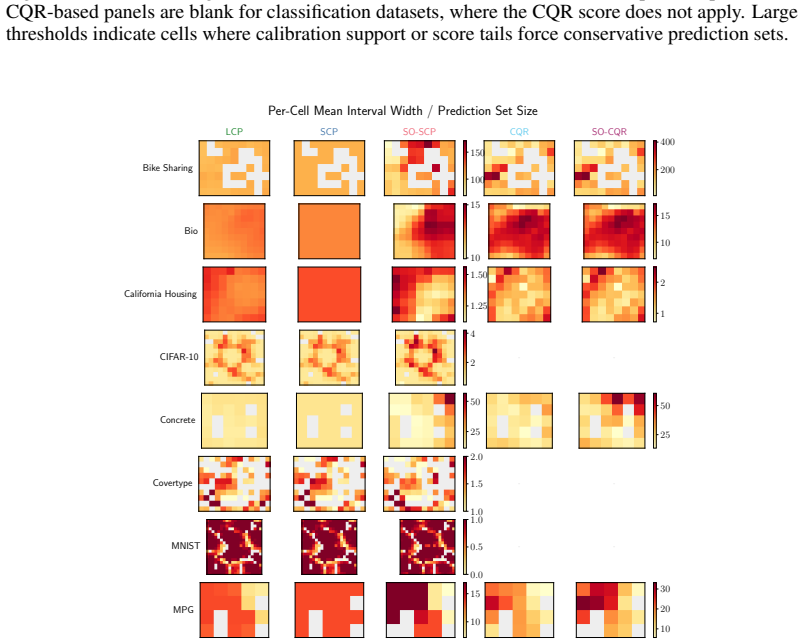
SOCP discovers input-space groups with a Self-Organizing Map and at test time draws a local calibration buffer from the query's best-matching unit cell or a fixed grid neighborhood. The same retrieval rule applies across tasks and data types. It gives exact validity for BMU-cell retrieval and fixed retrieved-set validity for neighborhood buffers, with central-cell validity holding up to a Kolmogorov-Smirnov bias term. On eight regression and classification benchmarks it reduces the weighted regional coverage gap on seven datasets (mean paired change -7.1 percent) for a mean prediction-set size increase of 6.2 percent.
What carries the argument
Self-Organizing Map that partitions the input space into cells used to retrieve local calibration buffers at test time.
If this is right
- Exact validity holds when calibration examples are drawn only from the best-matching unit cell.
- Neighborhood buffers deliver fixed retrieved-set validity.
- A split-routed extension recovers fixed retrieved-set validity conditional on the routing split.
- The weighted regional coverage gap decreases on seven of eight benchmarks with only a 6.2 percent mean increase in prediction-set size.
- The method works without supervised partitions or predictor retraining on both tabular features and image embeddings.
Where Pith is reading between the lines
- Local calibration buffers could support more reliable use in safety-critical settings where certain input regions carry higher decision risk.
- Because groups are learned unsupervised the approach could extend to data streams where labeled subgroups are unavailable.
- Alternative unsupervised partitioning methods might produce comparable reductions in regional gaps if they also align with coverage heterogeneity.
Load-bearing premise
The self-organizing map discovers cells whose local data distributions align with regions of differing coverage behavior and the Kolmogorov-Smirnov bias term remains small enough that central-cell validity for neighborhood retrieval is practically useful.
What would settle it
Running the eight benchmarks and finding that the weighted regional coverage gap fails to decrease on most datasets or that observed coverage deviates from the stated validity guarantees by more than the KS bias term.
Figures

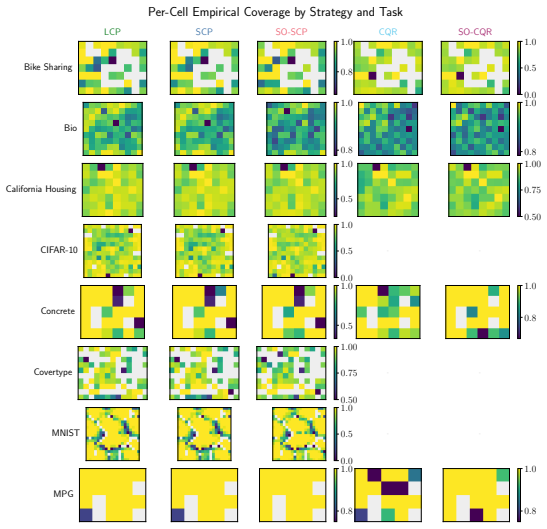

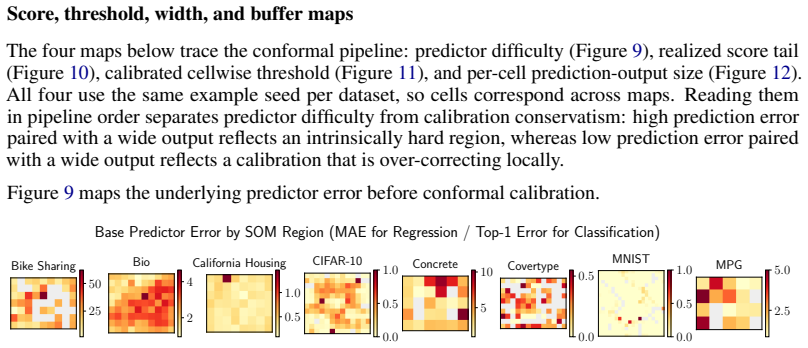
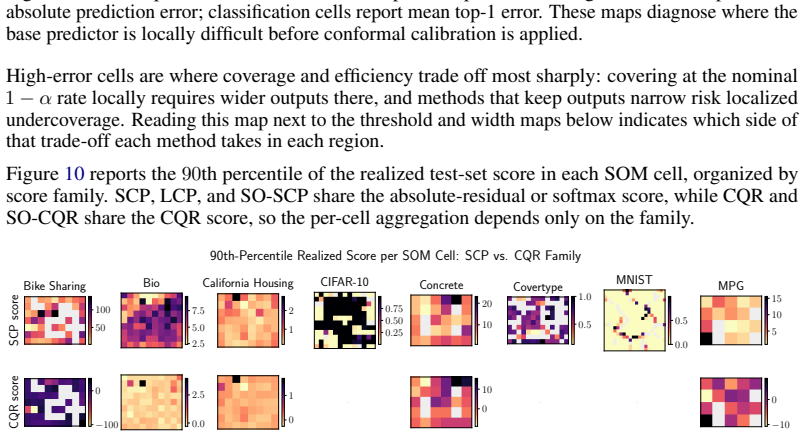
read the original abstract
Conformal prediction guarantees marginal coverage, but pooled calibration averages over heterogeneous regions and can mask regional undercoverage in safety-critical subgroups. We introduce Self-Organized Conformal Prediction (SOCP), a calibration scheme that discovers input-space groups with a Self-Organizing Map (SOM) and, at test time, draws a local calibration buffer from the query's best-matching unit (BMU) cell or a fixed grid neighborhood. The same retrieval rule applies to regression and classification tasks across tabular features and image embeddings, leaving the predictor and nonconformity score untouched. SOCP gives exact validity for BMU-cell retrieval and fixed retrieved-set validity for neighborhood buffers; central-cell validity for neighborhood retrieval holds up to a Kolmogorov-Smirnov (KS) bias term. A split-routed extension recovers fixed retrieved-set validity conditional on the routing split. On eight regression and classification benchmarks, SO-SCP reduces the weighted regional coverage gap on $7/8$ datasets (mean paired change $-7.1\%$) for a mean prediction-set size increase of $6.2\%$, with negligible overhead on the largest six datasets; SO-CQR yields smaller gains, since quantile regression already absorbs much of the heterogeneity. By learning groups directly from the input geometry, SOCP provides group-local calibration with exact fixed-group guarantees and approximate central-cell guarantees, without supervised partitions or predictor retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Self-Organized Conformal Prediction (SOCP), which uses a Self-Organizing Map (SOM) to discover input-space groups from geometry alone and retrieves local calibration sets from the query's best-matching unit (BMU) cell or a fixed grid neighborhood. It claims exact validity for BMU-cell retrieval, fixed retrieved-set validity for neighborhood buffers, and central-cell validity for neighborhoods up to a Kolmogorov-Smirnov (KS) bias term (with a split-routed variant recovering conditional fixed-set validity). On eight regression and classification benchmarks the method reduces the weighted regional coverage gap on 7/8 datasets (mean paired change -7.1%) at a mean prediction-set size increase of 6.2%, without altering the underlying predictor or nonconformity score.
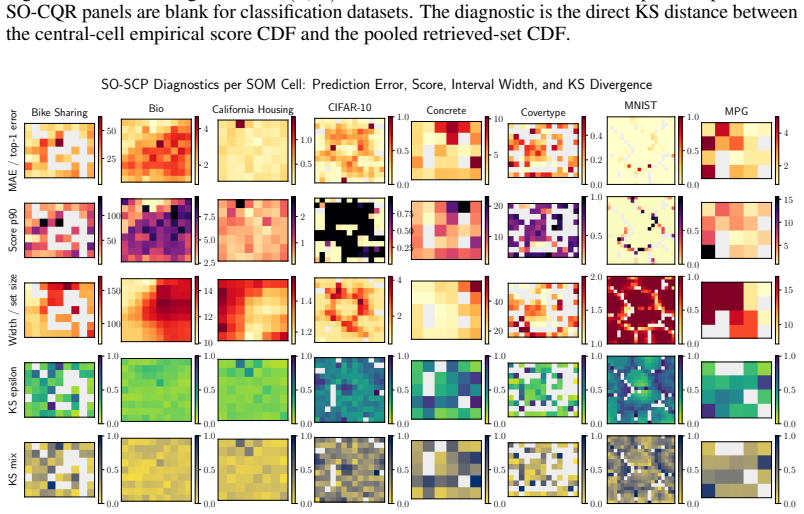
Significance. If the stated validity properties hold and the observed gap reductions can be attributed to SOM cells aligning with coverage heterogeneity (rather than input geometry alone), the approach would provide a practical, unsupervised route to group-local calibration that preserves exact or approximate guarantees while remaining applicable across tabular and embedding-based tasks. The negligible overhead on large datasets and the fact that gains are smaller when quantile regression already absorbs heterogeneity are also positive features. The lack of a bound on the KS term or empirical distribution of the statistic across benchmarks, however, limits the strength of the approximate-central-cell claim.
major comments (3)
- [Abstract] Abstract (guarantees paragraph): the central claim of practically useful approximate central-cell validity for neighborhood retrieval rests on the KS bias term remaining small relative to the reported 7.1% gap reduction, yet the manuscript supplies neither a theoretical bound on this term nor the empirical distribution of the KS statistic across the eight benchmarks; without these the attribution of the empirical improvement to the claimed validity properties cannot be assessed.
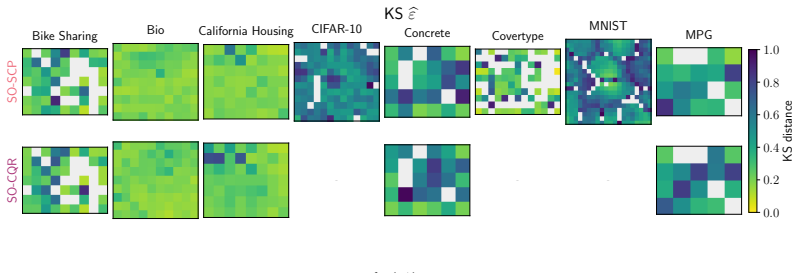
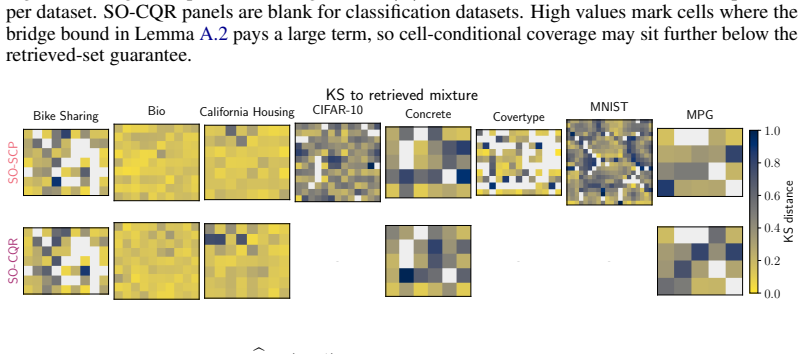
- [Abstract] Abstract and method description: the procedure relies on the unsupervised SOM discovering cells whose local nonconformity distributions differ meaningfully from the global pool and from each other; no experiment or diagnostic is reported that tests whether the discovered partitions align with coverage heterogeneity rather than merely reflecting input-space geometry, which is load-bearing for interpreting the 7/8-dataset improvement as evidence for the method's validity properties.
- [Abstract] Abstract (empirical results): the reported mean paired change of -7.1% and 6.2% size increase are presented without accompanying per-dataset tables, standard errors, or ablation on the free parameters (SOM grid size, neighborhood radius), making it impossible to judge robustness or to separate the contribution of the validity guarantees from post-hoc tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (guarantees paragraph): the central claim of practically useful approximate central-cell validity for neighborhood retrieval rests on the KS bias term remaining small relative to the reported 7.1% gap reduction, yet the manuscript supplies neither a theoretical bound on this term nor the empirical distribution of the KS statistic across the eight benchmarks; without these the attribution of the empirical improvement to the claimed validity properties cannot be assessed.
Authors: We agree that the empirical distribution of the KS statistic is needed to evaluate the practical size of the bias term. Deriving a general theoretical bound without strong distributional assumptions is not feasible while preserving the method's broad applicability. In the revision we will add the per-benchmark KS values (and their relation to the observed gap reductions) so readers can directly assess the term. revision: yes
-
Referee: [Abstract] Abstract and method description: the procedure relies on the unsupervised SOM discovering cells whose local nonconformity distributions differ meaningfully from the global pool and from each other; no experiment or diagnostic is reported that tests whether the discovered partitions align with coverage heterogeneity rather than merely reflecting input-space geometry, which is load-bearing for interpreting the 7/8-dataset improvement as evidence for the method's validity properties.
Authors: This observation is correct and highlights an important interpretive gap. While the consistent performance gains provide indirect support, a direct diagnostic is warranted. We will include in the revision an analysis that quantifies how the discovered cells differ in nonconformity-score distributions from the global pool (e.g., average cell-to-global KS distances) and will report the resulting regional coverage gaps within cells. revision: yes
-
Referee: [Abstract] Abstract (empirical results): the reported mean paired change of -7.1% and 6.2% size increase are presented without accompanying per-dataset tables, standard errors, or ablation on the free parameters (SOM grid size, neighborhood radius), making it impossible to judge robustness or to separate the contribution of the validity guarantees from post-hoc tuning.
Authors: We concur that the current aggregate reporting limits assessment of robustness. The revised manuscript will contain a supplementary table listing per-dataset metrics together with bootstrap standard errors, and we will add an ablation study varying SOM grid size and neighborhood radius to demonstrate stability of the reported gains. revision: yes
Circularity Check
No significant circularity; validity claims follow from standard CP applied to retrieved sets
full rationale
The derivation applies exchangeability-based conformal coverage to calibration subsets retrieved by BMU or neighborhood rules from an unsupervised SOM. Exact BMU-cell validity is the direct consequence of running split conformal prediction on the cell's own calibration points; neighborhood fixed-set validity likewise follows from treating the retrieved buffer as a fixed calibration set. The KS bias term is explicitly introduced as an approximation bound rather than asserted to be zero or fitted. No parameter is tuned to the coverage target and then relabeled as a prediction, no self-citation supplies a uniqueness theorem, and no ansatz is smuggled via prior work. The empirical benchmark results are presented as separate validation of practical effect size, not as the source of the theoretical guarantees. The procedure is therefore self-contained against external conformal-prediction benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- SOM grid size
- Neighborhood radius for buffer retrieval
axioms (2)
- domain assumption Data points are exchangeable conditional on the calibration set for marginal coverage
- domain assumption SOM topology reflects regions of heterogeneous nonconformity behavior
Reference graph
Works this paper leans on
-
[1]
A. N. Angelopoulos and S. Bates. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification. Dec. 2022. doi: 10.48550/arXiv.2107.07511
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.07511 2022
-
[2]
K. Bairaktari, J. Wu, and Z. S. Wu. Kandinsky Conformal Prediction: Beyond Class- and Covariate-Conditional Coverage. July 2025. doi: 10.48550/arXiv.2502.17264
-
[3]
R. F. Barber, E. J. Candès, A. Ramdas, and R. J. Tibshirani. The limits of distribution-free conditional predictive inference. Apr. 2020. doi: 10.48550/arXiv.1903.04684
-
[4]
L. Berthier, A. Shokry, M. Moreaud, G. Ramelet, and E. Moulines. Torchsom: The Reference PyTorch Library for Self-Organizing Maps. Oct. 2025. doi: 10.48550/arXiv.2510.11147
-
[5]
A. Bhattacharyya and R. F. Barber. Group-weighted conformal prediction.Electronic Journal of Statistics, 20(1):1171–1199, Jan. 2026. ISSN 1935-7524, 1935-7524. doi: 10.1214/26-EJS2506
-
[6]
J. Blackard. Covertype. UCI Machine Learning Repository, 1998. doi: 10.24432/C50K5N
-
[7]
Conditional Coverage Diagnostics for Conformal Prediction
S. Braun, D. Holzmüller, M. I. Jordan, and F. Bach. Conditional Coverage Diagnostics for Conformal Prediction. Dec. 2025. doi: 10.48550/arXiv.2512.11779
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.11779 2025
-
[8]
Campbell, S
T. Campbell, S. Syed, C.-Y . Yang, M. I. Jordan, and T. Broderick. Local Exchangeability. July
-
[9]
doi: 10.48550/arXiv.1906.09507
-
[10]
T. Ding, A. Angelopoulos, S. Bates, M. Jordan, and R. J. Tibshirani. Class-Conditional Conformal Prediction with Many Classes.Advances in Neural Information Processing Systems, 36:64555–64576, Dec. 2023
2023
-
[11]
H. Fanaee-T. Bike Sharing. UCI Machine Learning Repository, 2013. doi: 10.24432/C5W894
-
[12]
I. Gibbs, J. J. Cherian, and E. J. Candès. Conformal Prediction With Conditional Guarantees. Sept. 2024. doi: 10.48550/arXiv.2305.12616
-
[13]
L. Guan. Localized Conformal Prediction: A Generalized Inference Framework for Conformal Prediction. Feb. 2022. doi: 10.48550/arXiv.2106.08460
-
[14]
X. Han, Z. Tang, J. Ghosh, and Q. Liu. Split Localized Conformal Prediction. Feb. 2023. doi: 10.48550/arXiv.2206.13092
-
[15]
K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. Dec
-
[16]
doi: 10.48550/arXiv.1512.03385
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1512.03385
-
[17]
I-Cheng Yeh. Concrete Compressive Strength. UCI Machine Learning Repository, 1998. doi: 10.24432/C5PK67. 10
-
[18]
J. N. Kaur, M. I. Jordan, and A. Alaa. Conformal Prediction Sets with Improved Conditional Coverage using Trust Scores. Feb. 2025. doi: 10.48550/arXiv.2501.10139
-
[19]
R. Kelley Pace and R. Barry. Sparse spatial autoregressions.Statistics & Probability Letters, 33 (3):291–297, May 1997. ISSN 0167-7152. doi: 10.1016/S0167-7152(96)00140-X
-
[20]
T. Kohonen. Self-organized formation of topologically correct feature maps.Biological Cybernetics, 43(1):59–69, Jan. 1982. ISSN 1432-0770. doi: 10.1007/BF00337288
-
[21]
T. Kohonen. The self-organizing map.Proceedings of the IEEE, 78(9):1464–1480, Sept. 1990. ISSN 1558-2256. doi: 10.1109/5.58325
-
[22]
Kohonen.Self-Organizing Maps, volume 30 ofSpringer Series in Information Sciences
T. Kohonen.Self-Organizing Maps, volume 30 ofSpringer Series in Information Sciences. Springer, Berlin, Heidelberg, 2001. ISBN 978-3-540-67921-9 978-3-642-56927-2. doi: 10. 1007/978-3-642-56927-2
2001
-
[23]
Krizhevsky
A. Krizhevsky. Learning Multiple Layers of Features from Tiny Images.University of Toronto, May 2012
2012
-
[24]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, Nov. 1998. ISSN 1558-2256. doi: 10.1109/5.726791
-
[25]
Lei and L
J. Lei and L. Wasserman. Distribution-free Prediction Bands for Non-parametric Regression. Journal of the Royal Statistical Society Series B: Statistical Methodology, 76(1):71–96, Jan
- [26]
-
[27]
J. Lei, M. G’Sell, A. Rinaldo, R. J. Tibshirani, and L. Wasserman. Distribution-Free Predictive Inference For Regression. Mar. 2017. doi: 10.48550/arXiv.1604.04173
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1604.04173 2017
-
[28]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. Sept. 2020. doi: 10.48550/arXiv.1802.03426
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.03426 2020
-
[29]
H. Papadopoulos, K. Proedrou, V . V ovk, and A. Gammerman. Inductive Confidence Machines for Regression. InMachine Learning: ECML 2002, pages 345–356, Berlin, Heidelberg, 2002. Springer. ISBN 978-3-540-36755-0. doi: 10.1007/3-540-36755-1_29
-
[30]
V . Plassier, A. Fishkov, V . Dheur, M. Guizani, S. B. Taieb, M. Panov, and E. Moulines. Rectifying Conformity Scores for Better Conditional Coverage. Aug. 2025. doi: 10.48550/ arXiv.2502.16336
-
[31]
R. Quinlan. Auto MPG. UCI Machine Learning Repository, 1993. doi: 10.24432/C5859H
-
[32]
P. Rana, H. Sharma, M. Bhattacharya, and A. Shukla. Physicochemical Properties of Protein Structure. UCI Machine Learning Repository, Oct. 2015. doi: 10.24432/C5QW3H
-
[33]
Conformalized Quantile Regression
Y . Romano, E. Patterson, and E. J. Candès. Conformalized Quantile Regression. May 2019. doi: 10.48550/arXiv.1905.03222
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905.03222 2019
-
[34]
Romano, M
Y . Romano, M. Sesia, and E. J. Candès. Classification with Valid and Adaptive Coverage. June
-
[35]
doi: 10.48550/arXiv.2006.02544
-
[36]
ImageNet Large Scale Visual Recognition Challenge
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. Jan. 2015. doi: 10.48550/arXiv.1409.0575
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1409.0575 2015
-
[37]
Shafer and V
G. Shafer and V . V ovk. A Tutorial on Conformal Prediction.Journal of Machine Learning Research, 9(12):371–421, 2008. ISSN 1533-7928
2008
-
[38]
V . V ovk. Conditional Validity of Inductive Conformal Predictors. InProceedings of the Asian Conference on Machine Learning, pages 475–490. PMLR, Nov. 2012
2012
-
[39]
V ovk, D
V . V ovk, D. Lindsay, I. Nouretdinov, and A. Gammerman. Mondrian Confidence Machine. Technical report, Royal Holloway University of London, 2003
2003
-
[40]
V . V ovk, A. Gammerman, and G. Shafer.Algorithmic Learning in a Random World. Springer, New York, NY , USA, 2005. doi: 10.1007/b106715. 11 A Appendix A.1 Deferred methodological details This appendix collects the proof tools (Mondrian validity, the KS bridge, and tower-property transfer), the prototype-KNN extension, and the split-routed buffer that comp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.