The Platonic Defense: Backdoor Defense for Self-Supervised Encoders in the Era of Large Scale Pre-training
Pith reviewed 2026-06-30 07:38 UTC · model grok-4.3
The pith
A conditional energy function over reference representations from other encoders detects and purifies backdoored self-supervised models in black-box settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Platonic Representation Defense formalizes compatible projections from large-scale independently trained encoders as a conditional energy function defined over source and reference representations. This function is optimized through noise-contrastive estimation for detection and denoising score matching for purification. The energy gap between matched and mismatched samples is lower bounded by the mutual information between the source and reference representations. The resulting test-time procedure performs both detection and purification without access to labels, attack patterns, or original training data, yielding substantial gains across multiple self-supervised encoders and more than
What carries the argument
The conditional energy function defined over a source representation and a set of reference representations from other encoders, optimized by noise-contrastive estimation for detection and denoising score matching for purification.
If this is right
- Detection operates without labels or knowledge of the attack pattern.
- Purification restores clean representations through score matching at test time.
- The approach applies across different self-supervised encoders and input modalities.
- Gains hold for more than ten distinct backdoor attacks.
- The defense requires only access to a small set of reference encoders and runs without retraining.
Where Pith is reading between the lines
- If the compatibility assumption extends beyond vision, the same energy construction could defend other representation-learning pipelines that admit multiple independent pre-trained models.
- Stronger reference encoders should increase the mutual-information lower bound and therefore detection sensitivity.
- Publicly available pre-trained models could be reused directly as references without any new training.
- Empirical verification could measure whether observed energy gaps track independent estimates of mutual information between encoders.
Load-bearing premise
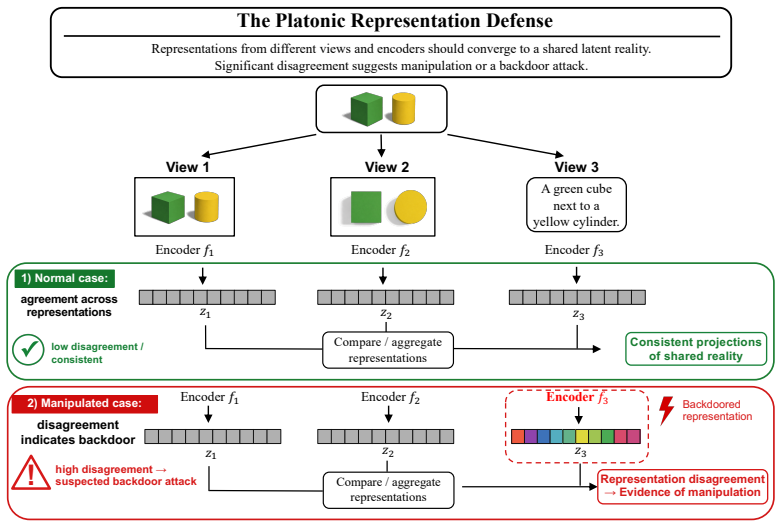
Independently trained large-scale encoders converge to compatible projections of the same underlying reality, so that reference representations can serve as reliable indicators of clean source representations.
What would settle it
A controlled test in which the energy gap between clean and backdoored samples remains near zero even when mutual information between source and reference representations is high, or in which purification fails to restore accuracy on a held-out attack.
Figures
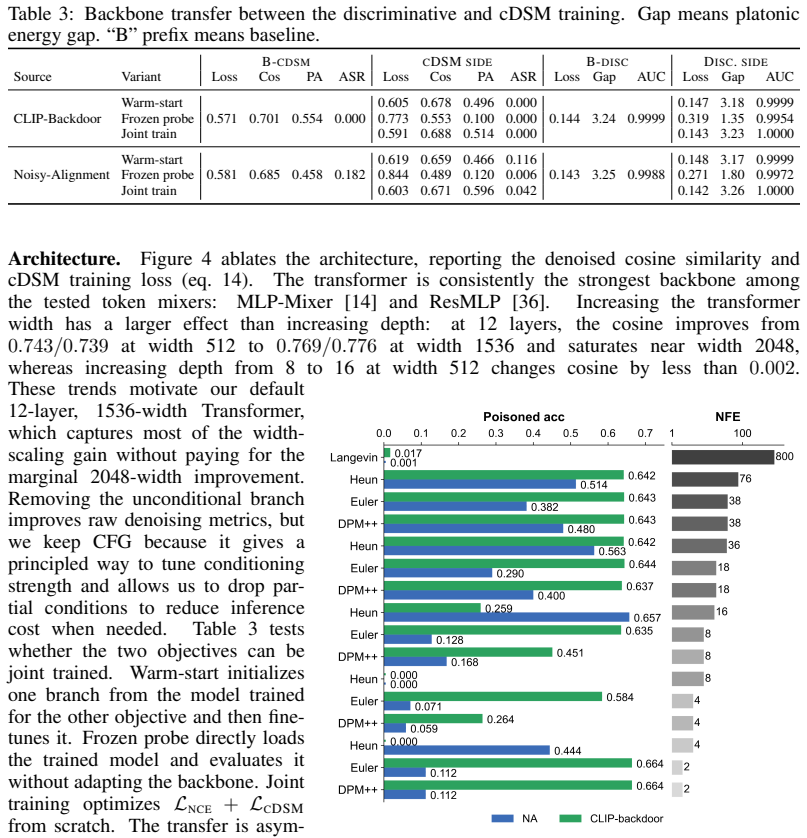
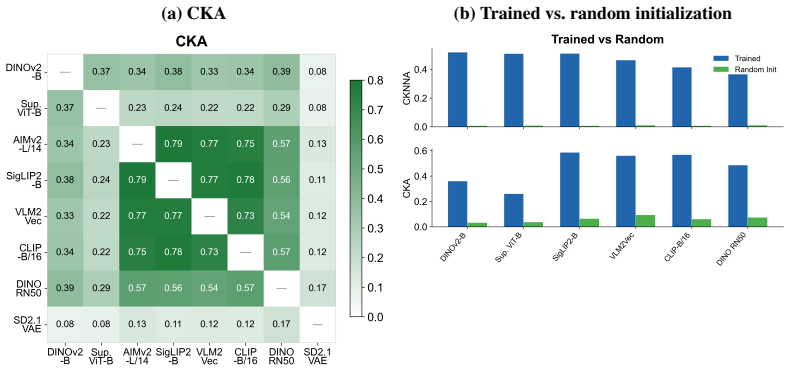
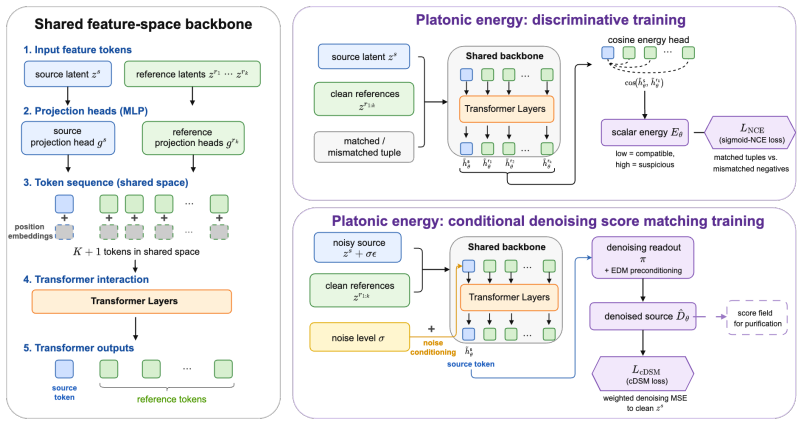
read the original abstract
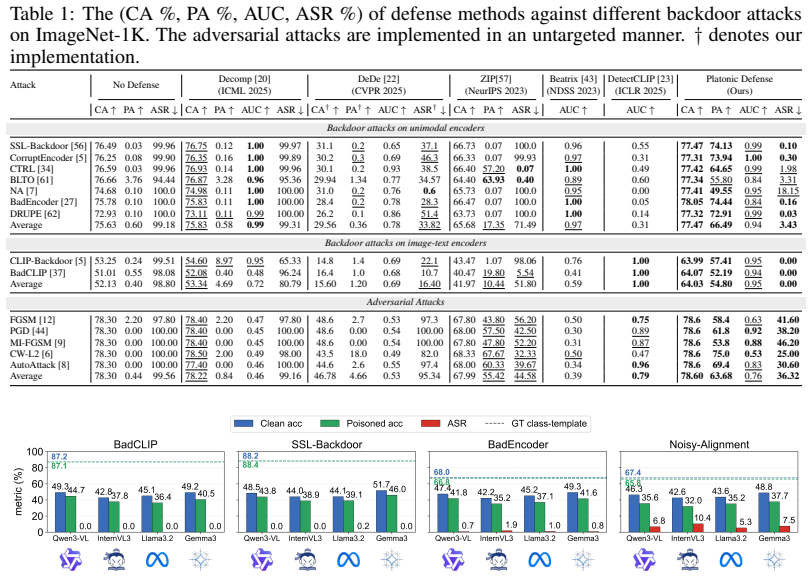
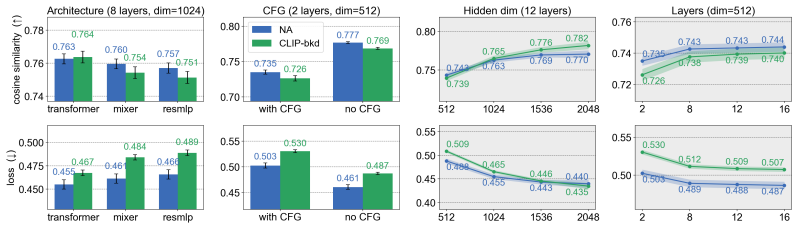
Self-supervised learning (SSL) pretrained models have become a dominant paradigm for visual representation learning, but they are vulnerable to backdoor attacks. Existing defenses struggle to defend against such attacks in a fully black-box setting because they often require access to labels, attack patterns, or training data. To tackle this issue, we propose a new attack-agnostic, model-agnostic, and modality-agnostic black-box test-time defense paradigm, called \emph{Platonic Representation Defense}. It is inspired by the Platonic Representation Hypothesis, which suggests that large-scale independently trained encoders converge toward compatible projections of the same underlying reality. We formalize this idea as a conditional energy function defined over source representations and a set of reference representations. The energy function is trained for detection through noise-contrastive estimation and for representation purification through denoising score matching. Theoretically, the energy gap between matched and mismatched samples is lower bounded by the mutual information between source and reference representations. We demonstrate the effectiveness of our method on multiple self-supervised encoders and more than 10 attacks. The method can perform both representation detection and purification, and achieves substantial performance gains across multiple attacks. Code is available \href{https://github.com/jsrdcht/Platonic-Representation-Defense}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Platonic Representation Defense, a black-box test-time method for defending self-supervised encoders against backdoor attacks. It formalizes the Platonic Representation Hypothesis via a conditional energy function over source and reference representations, trained with noise-contrastive estimation for detection and denoising score matching for purification; a theoretical claim states that the energy gap between matched and mismatched samples is lower-bounded by the mutual information between source and reference representations. The method is presented as attack-agnostic, model-agnostic, and modality-agnostic, with empirical claims of substantial gains across multiple encoders and more than 10 attacks for both detection and purification.
Significance. If the central claims hold, the work offers a novel defense paradigm that avoids reliance on labels, attack patterns, or training data, which is valuable for the dominant SSL pre-training setting. The dual detection/purification capability and the information-theoretic bound are potentially useful contributions; the public code release supports reproducibility.
major comments (3)
- [Abstract / theoretical analysis] Abstract and theoretical section: the lower bound relating energy gap to mutual information between source and reference representations is load-bearing for the detection guarantee, yet the manuscript must clarify whether the energy function parameters are estimated on the same representations used to compute the MI estimate; if so, the bound risks becoming tautological by construction.
- [Abstract / method description] Abstract and § on reference selection: the method's reliability rests on the Platonic Representation Hypothesis that independently trained encoders produce compatible projections usable as reference representations; the paper should provide a concrete test or ablation showing that backdoor attacks on the source encoder do not disrupt this compatibility, as violation would invalidate both the bound and the empirical gains.
- [Abstract / experiments] Experimental claims: the abstract asserts substantial performance gains across >10 attacks but supplies no details on datasets, attack implementations, baselines, error bars, or statistical verification; without these the support for the central empirical claim cannot be assessed.
minor comments (2)
- The GitHub link for code is provided, which aids reproducibility.
- Notation for the conditional energy function and the NCE/DSM objectives should be introduced with explicit equations early in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications, ablations, and details.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical section: the lower bound relating energy gap to mutual information between source and reference representations is load-bearing for the detection guarantee, yet the manuscript must clarify whether the energy function parameters are estimated on the same representations used to compute the MI estimate; if so, the bound risks becoming tautological by construction.
Authors: We thank the referee for this important observation. The energy function is trained via NCE on a held-out collection of source-reference pairs that is disjoint from the samples used to estimate mutual information in the theoretical analysis. The lower bound itself follows from the definition of mutual information and the properties of the conditional energy function; it does not depend on the fitted parameter values. In the revision we will add an explicit statement of this data separation together with a short derivation appendix that makes the independence clear. revision: yes
-
Referee: [Abstract / method description] Abstract and § on reference selection: the method's reliability rests on the Platonic Representation Hypothesis that independently trained encoders produce compatible projections usable as reference representations; the paper should provide a concrete test or ablation showing that backdoor attacks on the source encoder do not disrupt this compatibility, as violation would invalidate both the bound and the empirical gains.
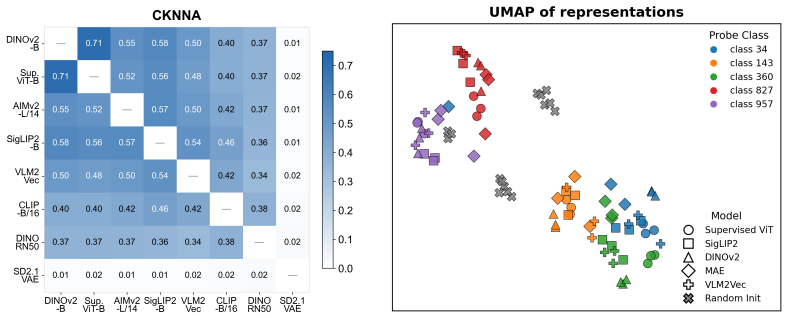
Authors: We agree that an explicit verification of compatibility under attack is necessary. The revised manuscript will include a new ablation that measures the average energy (and cosine alignment) between backdoored source representations and clean reference representations across the evaluated attacks. The results confirm that the compatibility predicted by the Platonic Representation Hypothesis remains intact, thereby supporting both the theoretical bound and the reported detection/purification performance. revision: yes
-
Referee: [Abstract / experiments] Experimental claims: the abstract asserts substantial performance gains across >10 attacks but supplies no details on datasets, attack implementations, baselines, error bars, or statistical verification; without these the support for the central empirical claim cannot be assessed.
Authors: We acknowledge the space limitation of the abstract. In the revision we will expand the abstract to name the primary datasets (ImageNet, CIFAR-10/100), list representative attacks (BadNet, Blended, WaNet, etc.), mention the baselines, and note that all quantitative results include error bars over multiple random seeds with statistical significance reported in Section 4 and the appendix. Full attack implementations, hyper-parameters, and code are already released. revision: yes
Circularity Check
No significant circularity; lower bound is a derived information-theoretic result, not a tautology or self-citation reduction
full rationale
The paper's derivation proceeds from the external Platonic Representation Hypothesis (used as inspiration, not a self-citation load-bearing premise) to a conditional energy function trained via standard NCE for detection and DSM for purification. The claimed lower bound on the energy gap by mutual information between source and reference representations is presented as a theoretical consequence of the energy function's construction and contrastive training, not equivalent to its inputs by definition. No fitted parameters are renamed as predictions, no uniqueness theorems are imported from the authors' prior work, and no ansatz is smuggled via self-citation. The method remains attack-agnostic and model-agnostic as stated, with empirical validation on multiple encoders and attacks providing independent content. The central claim does not reduce to its own assumptions or data fits.
Axiom & Free-Parameter Ledger
free parameters (1)
- energy function parameters
axioms (1)
- domain assumption Platonic Representation Hypothesis: large-scale independently trained encoders converge toward compatible projections of the same underlying reality
Reference graph
Works this paper leans on
-
[1]
A quantitative analysis of semantic information in deep representations of text and images
Santiago Acevedo, Andrea Mascaretti, Riccardo Rende, Mat ´eo Mahaut, Marco Baroni, and Alessandro Laio. A quantitative analysis of semantic information in deep representations of text and images.arXiv preprint arXiv:2505.17101, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Clean- clip: Mitigating data poisoning attacks in multimodal contrastive learning
Hritik Bansal, Nishad Singhi, Yu Yang, Fan Yin, Aditya Grover, and Kai-Wei Chang. Clean- clip: Mitigating data poisoning attacks in multimodal contrastive learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 112–123, 2023
2023
-
[4]
Yancheng Cai, Fei Yin, Dounia Hammou, and Rafal Mantiuk. Do computer vision foundation models learn the low-level characteristics of the human visual system? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20039–20048, 2025
2025
-
[5]
Poisoning and backdooring contrastive learning
Nicholas Carlini and Andreas Terzis. Poisoning and backdooring contrastive learning. In International Conference on Learning Representations, 2021
2021
-
[6]
Towards Evaluating the Robustness of Neural Networks
Nicholas Carlini and David Wagner. Towards Evaluating the Robustness of Neural Networks . In2017 IEEE Symposium on Security and Privacy (SP), pages 39–57, Los Alamitos, CA, USA, May 2017. IEEE Computer Society. doi: 10.1109/SP.2017.49. URLhttps://doi. ieeecomputersociety.org/10.1109/SP.2017.49
-
[7]
Backdooring self- supervised contrastive learning by noisy alignment
Tuo Chen, Jie Gui, Minjing Dong, Ju Jia, Lanting Fang, and Jian Liu. Backdooring self- supervised contrastive learning by noisy alignment. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 3684–3693, 2025
2025
-
[8]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pages 2206–2216. PMLR, 2020
2020
-
[9]
Boosting adversarial attacks with momentum
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial attacks with momentum. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9185–9193, 2018
2018
-
[10]
Detecting backdoors in pre-trained en- coders
Shiwei Feng, Guanhong Tao, Siyuan Cheng, Guangyu Shen, Xiangzhe Xu, Yingqi Liu, Kaiyuan Zhang, Shiqing Ma, and Xiangyu Zhang. Detecting backdoors in pre-trained en- coders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 16352–16362, 2023
2023
-
[11]
Multimodal autoregressive pre-training of large vision encoders
Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, and Sai Aitharaju. Multimodal autoregressive pre-training of large vision encoders. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[12]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples.arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravanku- mar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Susskind, Miguel ´Angel Bautista, and Bj ¨orn Ommer
Ming Gui, Johannes Schusterbauer, Timy Phan, Felix Krause, Joshua M. Susskind, Miguel ´Angel Bautista, and Bj ¨orn Ommer. Adapting self-supervised representations as a la- tent space for efficient generation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[15]
Noise-contrastive estimation of unnormalized sta- tistical models, with applications to natural image statistics.Journal of machine learning research, 13(2), 2012
Michael U Gutmann and Aapo Hyv ¨arinen. Noise-contrastive estimation of unnormalized sta- tistical models, with applications to natural image statistics.Journal of machine learning research, 13(2), 2012
2012
-
[16]
Mutual information guided backdoor mitigation for pre-trained encoders
Tingxu Han, Weisong Sun, Ziqi Ding, Chunrong Fang, Hanwei Qian, Jiaxun Li, Zhenyu Chen, and Xiangyu Zhang. Mutual information guided backdoor mitigation for pre-trained encoders. IEEE Transactions on Information Forensics and Security, 20:3414–3428, 2025. ISSN 1556- 6021
2025
-
[17]
The meaning and use of the area under a receiver operating characteristic (roc) curve.Radiology, 143:29–36, 1982
James A Hanley and Barbara J McNeil. The meaning and use of the area under a receiver operating characteristic (roc) curve.Radiology, 143:29–36, 1982
1982
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 770–778, 2016
2016
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll ´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022
2022
-
[20]
A closer look at backdoor attacks on clip
Shuo He, Zhifang Zhang, Feng Liu, Roy Ka-Wei Lee, Bo An, and Lei Feng. A closer look at backdoor attacks on clip. InForty-Second International Conference on Machine Learning, 2025
2025
-
[21]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URLhttps: //openreview.net/forum?id=qw8AKxfYbI
2021
-
[22]
Dede: Detecting backdoor samples for ssl encoders via decoders
Sizai Hou, Songze Li, and Duanyi Yao. Dede: Detecting backdoor samples for ssl encoders via decoders. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20675–20684, 2025. 12
2025
-
[23]
Detecting backdoor samples in contrastive language image pretraining
Hanxun Huang, Sarah Monazam Erfani, Yige Li, Xingjun Ma, and James Bailey. Detecting backdoor samples in contrastive language image pretraining. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[24]
Dbssl: A scheme to detect backdoor attacks in self-supervised learning models.IEEE Transactions on Dependable and Secure Computing, pages 1–12, 2025
Yuxian Huang, Geng Yang, Dong Yuan, and Shui Yu. Dbssl: A scheme to detect backdoor attacks in self-supervised learning models.IEEE Transactions on Dependable and Secure Computing, pages 1–12, 2025. ISSN 1941-0018
2025
-
[25]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InProceedings of the 41st International Conference on Machine Learning, July 2024
2024
-
[26]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(4), 2005
Aapo Hyv ¨arinen and Peter Dayan. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(4), 2005
2005
-
[27]
Badencoder: Backdoor attacks to pre- trained encoders in self-supervised learning
Jinyuan Jia, Yupei Liu, and Neil Zhenqiang Gong. Badencoder: Backdoor attacks to pre- trained encoders in self-supervised learning. In2022 IEEE Symposium on Security and Privacy (SP), pages 2043–2059, May 2022
2043
-
[28]
VLM2vec: Training vision-language models for massive multimodal embedding tasks
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. VLM2vec: Training vision-language models for massive multimodal embedding tasks. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/forum?id=TE0KOzWYAF
2025
-
[29]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[30]
Sophia Koepke, Daniil Zverev, Shiry Ginosar, and Alexei A
A. Sophia Koepke, Daniil Zverev, Shiry Ginosar, and Alexei A. Efros. Back into plato’s cave: Examining cross-modal representational convergence at scale, April 2026
2026
-
[31]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[32]
Remarkable robustness of LLMs: Stages of inference? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
Vedang Lad, Jin Hwa Lee, Wes Gurnee, and Max Tegmark. Remarkable robustness of LLMs: Stages of inference? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=Wxh5Xz7NpJ
2026
-
[33]
A tutorial on energy-based learning.Predicting structured data, 1(0), 2006
Yann LeCun, Sumit Chopra, Raia Hadsell, M Ranzato, Fujie Huang, et al. A tutorial on energy-based learning.Predicting structured data, 1(0), 2006
2006
-
[34]
An embarrassingly simple backdoor attack on self-supervised learning
Changjiang Li, Ren Pang, Zhaohan Xi, Tianyu Du, Shouling Ji, Yuan Yao, and Ting Wang. An embarrassingly simple backdoor attack on self-supervised learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4367–4378, 2023
2023
-
[35]
On the difficulty of defending contrastive learning against backdoor attacks
Changjiang Li, Ren Pang, Bochuan Cao, Zhaohan Xi, Jinghui Chen, Shouling Ji, and Ting Wang. On the difficulty of defending contrastive learning against backdoor attacks. In33rd USENIX Security Symposium (USENIX Security 24), pages 2901–2918, 2024. ISBN 978-1- 939133-44-1
2024
-
[36]
Return of unconditional generation: A self- supervised representation generation method
Tianhong Li, Dina Katabi, and Kaiming He. Return of unconditional generation: A self- supervised representation generation method. InThe Thirty-Eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[37]
Badclip: Dual-embedding guided backdoor attack on multimodal contrastive learning
Siyuan Liang, Mingli Zhu, Aishan Liu, Baoyuan Wu, Xiaochun Cao, and Ee-Chien Chang. Badclip: Dual-embedding guided backdoor attack on multimodal contrastive learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24645–24654, 2024
2024
-
[38]
Visual instruction tuning, De- cember 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, De- cember 2023. 13
2023
-
[39]
Poisonedencoder: Poisoning the unla- beled pre-training data in contrastive learning
Hongbin Liu, Jinyuan Jia, and Neil Zhenqiang Gong. Poisonedencoder: Poisoning the unla- beled pre-training data in contrastive learning. In31st USENIX Security Symposium (USENIX Security 22), pages 3629–3645, 2022. ISBN 978-1-939133-31-1
2022
-
[40]
Mudjacking: Patching backdoor vulnerabilities in foundation models
Hongbin Liu, Michael K Reiter, and Neil Zhenqiang Gong. Mudjacking: Patching backdoor vulnerabilities in foundation models. In33rd USENIX Security Symposium (USENIX Security 24), pages 2919–2936, 2024
2024
-
[41]
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025
2025
-
[42]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023. URLhttps://arxiv. org/abs/2310.04378
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
The ”beatrix” resurrections: Robust backdoor detection via gram matrices
Wanlun Ma, Derui Wang, Ruoxi Sun, Minhui Xue, Sheng Wen, and Yang Xiang. The ”beatrix” resurrections: Robust backdoor detection via gram matrices. InProceedings 2023 Network and Distributed System Security Symposium, 2023. ISBN 978-1-891562-83-9
2023
-
[44]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InInternational Con- ference on Learning Representations, 2018. URLhttps://openreview.net/forum?id= rJzIBfZAb
2018
-
[45]
Mat ´eo Mahaut and Marco Baroni. Similarity of processing steps in vision model representa- tions.arXiv preprint arXiv:2601.21621, 2026
-
[46]
Do wide and deep networks learn the same things? uncovering how neural network representations vary with width and depth
Thao Nguyen, Maithra Raghu, and Simon Kornblith. Do wide and deep networks learn the same things? uncovering how neural network representations vary with width and depth. In International Conference on Learning Representations, 2021. URLhttps://openreview. net/forum?id=KJNcAkY8tY4
2021
-
[47]
Estimating divergence func- tionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010
XuanLong Nguyen, Martin J Wainwright, and Michael I Jordan. Estimating divergence func- tionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010
2010
-
[48]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Moham- mad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christo- pher ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patr...
2024
-
[51]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K¨opf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high- perfor...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[52]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InPro- ceedings of the 38th International Conference on Machine Learning, pages 8748–8763, July 2021
2021
-
[53]
Do vision transformers see like convolutional neural networks? In A
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovit- skiy. Do vision transformers see like convolutional neural networks? In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Pro- cessing Systems, 2021. URLhttps://openreview.net/forum?id=Gl8FHfMVTZu
2021
-
[54]
High-resolution image synthesis with latent diffusion models, 2021
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models, 2021
2021
-
[55]
Clarendon Press, 1995
Andr ´e Ronveaux and Felix Medland Arscott.Heun’s differential equations. Clarendon Press, 1995
1995
-
[56]
Backdoor attacks on self-supervised learning
Aniruddha Saha, Ajinkya Tejankar, Soroush Abbasi Koohpayegani, and Hamed Pirsiavash. Backdoor attacks on self-supervised learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13337–13346, 2022. 15
2022
-
[57]
Black-box backdoor defense via zero-shot image purification
Yucheng Shi, Mengnan Du, Xuansheng Wu, Zihan Guan, Jin Sun, and Ninghao Liu. Black-box backdoor defense via zero-shot image purification. InThirty-Seventh Conference on Neural Information Processing Systems, 2023
2023
-
[58]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[59]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InPro- ceedings of the 40th International Conference on Machine Learning, pages 32211–32252, July 2023
2023
-
[60]
Cambridge University Press, 2012
Masashi Sugiyama, Taiji Suzuki, and Takafumi Kanamori.Density ratio estimation in machine learning. Cambridge University Press, 2012
2012
-
[61]
Backdoor contrastive learning via bi-level trigger optimization
Weiyu Sun, Xinyu Zhang, Hao Lu, Ying-Cong Chen, Ting Wang, Jinghui Chen, and Lu Lin. Backdoor contrastive learning via bi-level trigger optimization. InThe Twelfth International Conference on Learning Representations, October 2023
2023
-
[62]
Distribution preserving backdoor attack in self-supervised learning
Guanhong Tao, Zhenting Wang, Shiwei Feng, Guangyu Shen, Shiqing Ma, and Xiangyu Zhang. Distribution preserving backdoor attack in self-supervised learning. In2024 IEEE Symposium on Security and Privacy (SP), pages 29–29, October 2023. ISBN 979-8-3503- 3130-1
2023
-
[63]
Distribution preserving backdoor attack in self-supervised learning
Guanhong Tao, Zhenting Wang, Shiwei Feng, Guangyu Shen, Shiqing Ma, and Xiangyu Zhang. Distribution preserving backdoor attack in self-supervised learning. In2024 IEEE Symposium on Security and Privacy (SP), pages 2029–2047. IEEE, 2024
2029
-
[64]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Mer- hej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, Louis Rouil- lard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Ga¨el Liu, Francesco Visin, Kathleen Kenealy, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Defending against patch-based backdoor attacks on self-supervised learning
Ajinkya Tejankar, Maziar Sanjabi, Qifan Wang, Sinong Wang, Hamed Firooz, Hamed Pir- siavash, and Liang Tan. Defending against patch-based backdoor attacks on self-supervised learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 12239–12249, 2023
2023
-
[66]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, local- ization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in neural informa- tion processing systems, volume 30, 2017
2017
-
[68]
Cambridge university press, 2019
Martin J Wainwright.High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge university press, 2019
2019
-
[69]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Understanding contrastive representation learning through alignment and uniformity on the hypersphere
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InProceedings of the 37th International Con- ference on Machine Learning, pages 9929–9939, November 2020
2020
-
[71]
Robust contrastive language-image pretraining against data poisoning and backdoor attacks
Wenhan Yang, Jingdong Gao, and Baharan Mirzasoleiman. Robust contrastive language-image pretraining against data poisoning and backdoor attacks. In A. Oh, T. Naumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 10678–10691, 2023
2023
-
[72]
Sigmoid loss for lan- guage image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for lan- guage image pre-training. InProceedings of the IEEE/CVF international conference on com- puter vision, pages 11975–11986, 2023
2023
-
[73]
Invisible backdoor attack against self- supervised learning
Hanrong Zhang, Zhenting Wang, Boheng Li, Fulin Lin, Tingxu Han, Mingyu Jin, Chenlu Zhan, Mengnan Du, Hongwei Wang, and Shiqing Ma. Invisible backdoor attack against self- supervised learning. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, pages 25790–25801, 2025
2025
-
[74]
Ssl-cleanse: Trojan detection and mitigation in self-supervised learning
Mengxin Zheng, Jiaqi Xue, Zihao Wang, Xun Chen, Qian Lou, Lei Jiang, and Xiaofeng Wang. Ssl-cleanse: Trojan detection and mitigation in self-supervised learning. InEuropean Confer- ence on Computer Vision, pages 405–421, 2024
2024
-
[75]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017
2017
-
[76]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 17 A Related Work A.1 Backdoor Attacks on Visual Encoders Backdoor attacks on visual encoders pose ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
[1] argued that aligned representations can preserve semantically meaning- ful structure across modalities, including cross-lingual structure within text, while Lad et al
and Acevedo et al. [1] argued that aligned representations can preserve semantically meaning- ful structure across modalities, including cross-lingual structure within text, while Lad et al. [32] described middle-to-late layers as an incremental feature-construction stage that gradually assem- bles task-relevant abstractions. Moving from representational ...
2033
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.