ARMOR: Adaptive Retriever Optimization for Low-Resource Telecom Question Answering
Pith reviewed 2026-06-30 04:50 UTC · model grok-4.3
The pith
Adapting only the query encoder in RAG improves telecom QA performance without generator fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
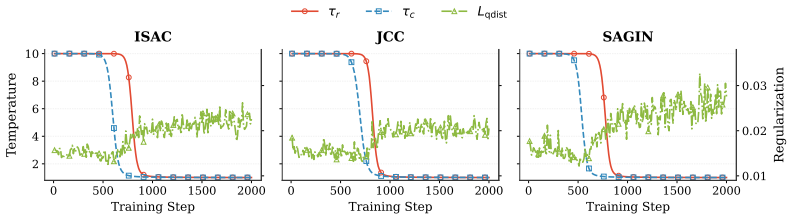
ARMOR learns separate temperatures for the RAG retrieval distribution and the InfoNCE softmax, regularizes the adapted query encoder toward the frozen base, and targets downstream QA performance; under the paper's bounded-parameter and soft-retrieval assumptions this yields a smaller estimation term than supervised fine-tuning when the query encoder's effective dimension is smaller, producing measurable improvements on in-domain telecom benchmarks.
What carries the argument
ARMOR (Adaptive Regularized Mixture Optimization for Retrievers), which jointly optimizes latent-document RAG likelihood and InfoNCE contrastive loss with per-objective temperature learning and regularization to the base encoder.
If this is right
- Query-encoder tuning reduces the estimation term relative to generator fine-tuning when effective dimension is smaller.
- Joint RAG-likelihood and InfoNCE optimization improves both retrieval geometry and generation utility.
- Regularization to the frozen base encoder limits over-specialization while retaining general capability.
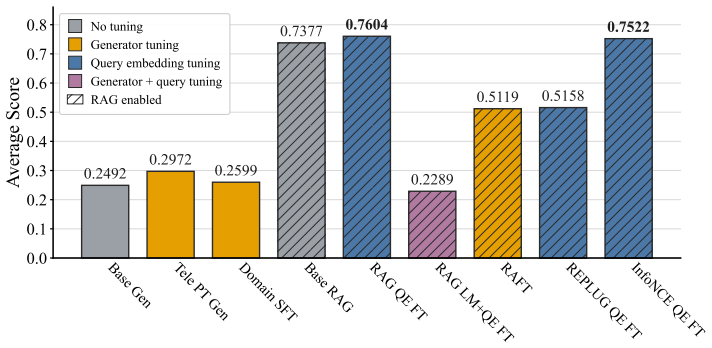
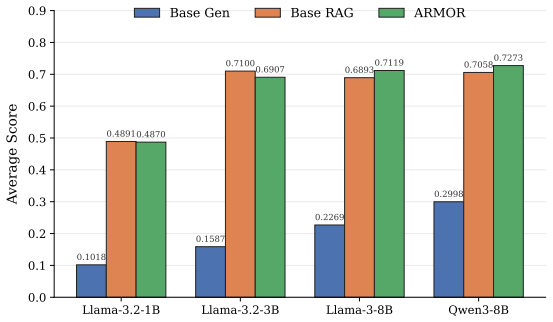
- Fixed-generator RAG systems achieve higher evidence retrieval and answer generation accuracy in several in-domain telecom settings.
Where Pith is reading between the lines
- The same query-adaptation approach could be tested on other fragmented technical domains such as legal or medical QA without retraining the generator.
- Keeping the generator frozen may preserve performance on out-of-domain or general questions while domain adaptation occurs only on the retriever side.
- Varying the regularization strength or temperature schedules offers a direct experimental knob for balancing adaptation and stability.
Load-bearing premise
Query-encoder tuning produces a smaller estimation term than supervised fine-tuning when the effective dimension is smaller, under bounded-parameter and soft-retrieval assumptions.
What would settle it
A controlled experiment that applies generator fine-tuning at the same parameter budget as the query-encoder adaptation and measures whether retrieval or answer quality on the telecom benchmarks is equal or better.
Figures
read the original abstract
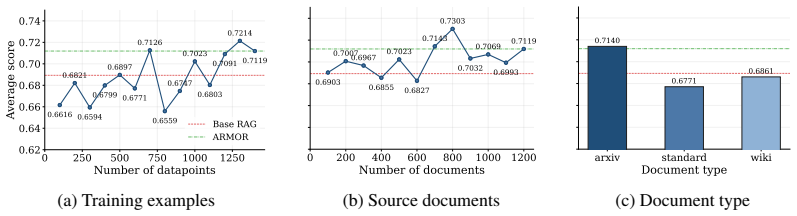
Telecom question answering (QA) is a challenging setting for retrieval-augmented generation (RAG): evidence is fragmented across standards, papers, encyclopedic resources, and web documents, and answers often hinge on technical tables, equations, and specialized protocol language. In low-resource subdomains, generator fine-tuning can over-specialize and degrade general capability, making query-side retriever adaptation an attractive alternative. To this end, we ask whether a fixed-generator, query-adapted RAG system can outperform generator-side adaptation, and which retriever objectives best support that setting. We motivate retrieval, rather than generator fine-tuning, as the adaptation target through a capacity comparison: under bounded-parameter and soft-retrieval assumptions, query-encoder tuning can have a smaller estimation term than supervised fine-tuning when its effective dimension is smaller. We identify two particularly relevant objectives -- the latent-document RAG likelihood, which optimizes generation utility, and the InfoNCE contrastive objective, which improves semantic retrieval geometry -- and leverage them jointly through a retriever optimization method targeting downstream QA performance in the telecom domain. Specifically, we introduce ARMOR, Adaptive Regularized Mixture Optimization for Retrievers, which learns separate temperatures for the RAG retrieval distribution and InfoNCE softmax and regularizes the adapted query encoder toward the frozen base query encoder. Across telecom-specific retrieval and generative QA benchmarks, we show that ARMOR improves evidence retrieval and answer generation in several in-domain settings. Code is available at https://github.com/heshandevaka/ARMOR.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARMOR, an adaptive retriever optimization method for low-resource telecom QA in RAG systems. It keeps the generator fixed and adapts only the query encoder by jointly optimizing a latent-document RAG likelihood objective and an InfoNCE contrastive objective, learning separate temperatures for each and regularizing the adapted encoder toward the base model. The approach is motivated by a capacity comparison claiming that query-encoder tuning yields a smaller estimation term than generator fine-tuning under bounded-parameter and soft-retrieval assumptions when effective dimension is smaller. Empirical results are reported to show gains in evidence retrieval and answer generation on telecom-specific benchmarks.
Significance. If the empirical gains hold under proper controls and the capacity argument is made rigorous, the work could support practical query-side adaptation strategies in specialized domains where generator fine-tuning risks capability degradation. Code release is a positive factor for reproducibility.
major comments (2)
- [Abstract / §1] Abstract and introduction: the central motivation rests on an un-derived capacity comparison stating that 'query-encoder tuning can have a smaller estimation term than supervised fine-tuning when its effective dimension is smaller.' No section defines the estimation term, specifies how effective dimension is computed for the query encoder versus the generator, or shows the dimension reduction holds under the telecom data regime. This assumption directly justifies the fixed-generator design; without the derivation the preference for retriever-side adaptation lacks theoretical support.
- [§3 / Experiments] §3 (method) and experimental sections: the joint objective combines RAG likelihood and InfoNCE with learned temperatures, but the manuscript does not report ablation results isolating the contribution of each temperature or the regularization term to the claimed QA gains. Without these controls it is unclear whether the reported improvements are attributable to the proposed ARMOR components or to generic contrastive tuning.
minor comments (1)
- Notation for the two temperatures (RAG retrieval distribution and InfoNCE softmax) should be introduced with explicit symbols and distinguished from any other temperature parameters in the base models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the theoretical motivation and empirical analysis. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and introduction: the central motivation rests on an un-derived capacity comparison stating that 'query-encoder tuning can have a smaller estimation term than supervised fine-tuning when its effective dimension is smaller.' No section defines the estimation term, specifies how effective dimension is computed for the query encoder versus the generator, or shows the dimension reduction holds under the telecom data regime. This assumption directly justifies the fixed-generator design; without the derivation the preference for retriever-side adaptation lacks theoretical support.
Authors: We agree that the capacity comparison is stated at a high level in the introduction without a full derivation. The manuscript motivates the comparison under bounded-parameter and soft-retrieval assumptions but does not define the estimation term or detail the effective-dimension calculation. In the revision we will add a formal derivation (new subsection in §2 plus appendix) that (i) defines the estimation term, (ii) specifies how effective dimension is obtained for the query encoder versus the generator, and (iii) discusses the conditions under which the dimension reduction holds in the low-resource telecom regime. This will supply the missing theoretical support for the fixed-generator design. revision: yes
-
Referee: [§3 / Experiments] §3 (method) and experimental sections: the joint objective combines RAG likelihood and InfoNCE with learned temperatures, but the manuscript does not report ablation results isolating the contribution of each temperature or the regularization term to the claimed QA gains. Without these controls it is unclear whether the reported improvements are attributable to the proposed ARMOR components or to generic contrastive tuning.
Authors: We concur that the current experiments do not isolate the learned temperatures or the regularization term. The joint objective is presented in §3, yet no component-wise ablations appear in §4. In the revised manuscript we will add a dedicated ablation table (and corresponding text) that systematically removes (a) the separate temperature parameters and (b) the regularization toward the base encoder, reporting retrieval and QA metrics for each variant. These controls will clarify the contribution of the ARMOR-specific elements beyond generic contrastive tuning. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core claims rest on empirical results for ARMOR on telecom retrieval and QA benchmarks. The capacity comparison is introduced as a stated motivation under explicit assumptions (bounded-parameter, soft-retrieval, effective dimension) without any derivation, equation, or reduction to prior fitted values shown in the text. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear. The method (joint RAG likelihood + InfoNCE with temperature regularization) is defined directly and evaluated externally, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- separate temperatures for RAG retrieval distribution and InfoNCE softmax
axioms (1)
- domain assumption bounded-parameter and soft-retrieval assumptions imply smaller estimation term for query-encoder tuning than for generator fine-tuning
Reference graph
Works this paper leans on
-
[1]
Fine-grained analysis of op- timization and generalization for overparameterized two-layer neural networks
Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of op- timization and generalization for overparameterized two-layer neural networks. InInternational 11 conference on machine learning, pages 322–332, 2019
2019
-
[2]
In-context retrieval-augmented language models.TACL, 2023
Akari Asai et al. In-context retrieval-augmented language models.TACL, 2023
2023
-
[3]
A statistical framework for data- dependent retrieval-augmented models
Soumya Basu, Ankit Singh Rawat, and Manzil Zaheer. A statistical framework for data- dependent retrieval-augmented models. InInternational Conference on Machine Learning, pages 3197–3223, 2024
2024
-
[4]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud et al. Improving language models by retrieving from trillions of tokens. ICML, 2022
2022
-
[5]
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen et al. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InICML, 2018
2018
-
[6]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V . Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Shahul Es et al. Ragas: Automated evaluation of retrieval-augmented generation.arXiv preprint arXiv:2309.15217, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Mitigating gradient bias in multi-objective learning: A provably convergent stochastic approach
Heshan Fernando, Han Shen, Miao Liu, Subhajit Chaudhury, Keerthiram Murugesan, and Tianyi Chen. Mitigating gradient bias in multi-objective learning: A provably convergent stochastic approach. InInternational Conference on Learning Representations, 2023
2023
-
[9]
Variance reduction can improve trade-off in multi-objective learning
Heshan Fernando, Lisha Chen, Songtao Lu, Pin-Yu Chen, Miao Liu, Subhajit Chaudhury, Keerthiram Murugesan, Gaowen Liu, Meng Wang, and Tianyi Chen. Variance reduction can improve trade-off in multi-objective learning. InICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6975–6979. IEEE, 2024
2024
-
[10]
Heshan Fernando, Han Shen, Parikshit Ram, Yi Zhou, Horst Samulowitz, Nathalie Baracaldo, and Tianyi Chen. Understanding forgetting in llm supervised fine-tuning and preference learning–a convex optimization perspective.arXiv preprint arXiv:2410.15483, 2024
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Realm: Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Realm: Retrieval-augmented language model pre-training. InICML, 2020
2020
-
[13]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model.arXiv preprint arXiv:2403.07691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
LoRA: Low-Rank Adaptation of Large Language Models
Edward Hu et al. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Ermo Hua, Biqing Qi, Kaiyan Zhang, Yue Yu, Ning Ding, Xingtai Lv, Kai Tian, and Bowen Zhou. Intuitive fine-tuning: Towards unifying sft and rlhf into a single process.arXiv preprint arXiv:2405.11870, 2024
-
[16]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering.arXiv preprint arXiv:2007.01282, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[17]
Unsupervised Dense Information Retrieval with Contrastive Learning
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Atlas: Few-shot Learning with Retrieval Augmented Language Models
Gautier Izacard et al. Atlas: Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InEMNLP, 2020. 12
2020
-
[20]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InCVPR, 2018
2018
-
[21]
Overcoming catastrophic forgetting in neural networks.PNAS, 2017
James Kirkpatrick et al. Overcoming catastrophic forgetting in neural networks.PNAS, 2017
2017
-
[22]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.arXiv preprint arXiv:2005.11401, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[23]
Yong Lin, Lu Tan, Hangyu Lin, Zeming Zheng, Renjie Pi, Han Zhao, Yuan Yao, et al. Speciality vs generality: An empirical study on catastrophic forgetting in fine-tuning foundation models. arXiv preprint arXiv:2309.06256, 2023
-
[24]
Conflict-averse gradient descent for multi-task learning.Advances in Neural Information Processing Systems, 34:18878–18890, 2021
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning.Advances in Neural Information Processing Systems, 34:18878–18890, 2021
2021
-
[25]
Uft: Unifying supervised and reinforce- ment fine-tuning.arXiv preprint arXiv:2505.16984, 2025
Mingyang Liu, Gabriele Farina, and Asuman Ozdaglar. Uft: Unifying supervised and reinforce- ment fine-tuning.arXiv preprint arXiv:2505.16984, 2025
-
[26]
Ali Maatouk, Kenny Chirino Ampudia, Rex Ying, and Leandros Tassiulas. Tele-llms: A series of specialized large language models for telecommunications.arXiv preprint arXiv:2409.05314, 2024
-
[27]
Teleqna: A benchmark dataset to assess large language models telecommunications knowledge.IEEE Network, 2025
Ali Maatouk, Fadhel Ayed, Nicola Piovesan, Antonio De Domenico, Merouane Debbah, and Zhi- Quan Luo. Teleqna: A benchmark dataset to assess large language models telecommunications knowledge.IEEE Network, 2025
2025
-
[28]
MIT press, 2018
Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar.Foundations of machine learning. MIT press, 2018
2018
-
[29]
Generalization bound for a shallow transformer trained using gradient descent.Transactions on Machine Learning Research, 2026
Brian Mwigo and Anirban Dasgupta. Generalization bound for a shallow transformer trained using gradient descent.Transactions on Machine Learning Research, 2026. URL https: //openreview.net/forum?id=t3iUeMOT8Z
2026
-
[30]
Kilt: A benchmark for knowledge-intensive language tasks
Fabio Petroni et al. Kilt: A benchmark for knowledge-intensive language tasks. InNAACL, 2021
2021
-
[31]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Multi-task learning as multi-objective optimization
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization. In NeurIPS, 2018
2018
-
[33]
On penalty-based bilevel gradient descent method
Han Shen, Quan Xiao, and Tianyi Chen. On penalty-based bilevel gradient descent method. Mathematical Programming, 214(1–2):539–589, 2025. doi: 10.1007/s10107-025-02194-4
-
[34]
Replug: Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 8371–8384, 2024. doi: 10.18653/...
-
[35]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Sequence length independent norm-based generalization bounds for transformers
Jacob Trauger and Ambuj Tewari. Sequence length independent norm-based generalization bounds for transformers. InInternational Conference on Artificial Intelligence and Statistics, pages 1405–1413, 2024
2024
-
[37]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 13
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InAdvances in Neural Information Processing Systems, 2020
2020
-
[40]
Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E. Gonzalez. Raft: Adapting language models to domain-specific rag.arXiv preprint arXiv:2403.10131, 2024. 14 A Experiment Details In this section, we provide additional details on the data generation, baseline implementation, and experiment setup used in this pa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.