Analytic Concept-Centric Memory for Agentic Embodied Manipulation
Pith reviewed 2026-06-30 06:24 UTC · model grok-4.3
The pith
Analytic concept-centric memory structures robot experience around semantic parts, poses, affordances and skills for improved long-horizon manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
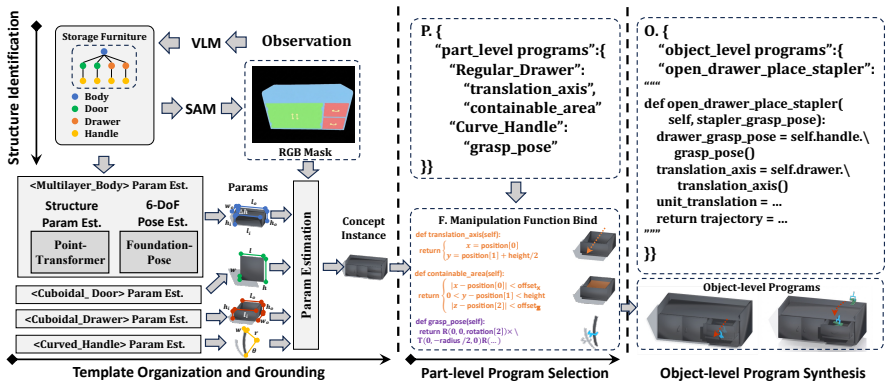
The central claim is that representing objects by semantic parts, parametric templates, grounded poses, affordances and manipulation states, then connecting these to transition memory for action-induced changes and skill memory for execution, enables structured coarse-to-fine retrieval that supports state-consistent reasoning and skill reuse, producing higher task completion, retrieval accuracy, object re-identification and generalization than unstructured or embedding-based alternatives.
What carries the argument
Analytic concept-centric memory, which represents objects and scenes via semantic parts, parametric templates, grounded poses, affordances and manipulation states, links them through transition memory and skill memory, and performs structured coarse-to-fine retrieval.
If this is right
- Task completion rates rise on memory-dependent manipulation benchmarks.
- Retrieval accuracy and object re-identification improve over embedding baselines.
- Cross-object skill generalization increases for articulated objects.
- Real-world memory evaluation shows measurable gains in state tracking and skill reuse.
Where Pith is reading between the lines
- The same concept structure could be applied to navigation or multi-step planning agents that must track object states across rooms.
- Hybrid symbolic-neural memory of this form might reduce the context length needed by language-model agents for consistent long tasks.
- Scaling the parametric templates to new object categories without per-class engineering remains an open test of practicality.
Load-bearing premise
Analytic concepts such as semantic parts, parametric templates and affordances can be extracted, maintained and retrieved reliably at runtime without prohibitive cost or manual engineering per object class.
What would settle it
A side-by-side run of the concept-centric system against unstructured and embedding baselines on a fixed set of long-horizon manipulation tasks in which the structured approach shows no statistically significant gain in task success rate or retrieval precision.
Figures

read the original abstract
Long-horizon embodied manipulation requires agents to remember persistent objects, track changing scene states, and reuse prior interaction knowledge. However, existing agent memories are often stored as unstructured histories or embedding-based records, making it difficult to retrieve manipulation-relevant object parts, physical states, action effects, and executable skills. We propose an analytic concept-centric memory framework for agentic embodied manipulation. Our memory organizes experience around structured analytic concepts, where objects are represented by semantic parts, parametric templates, grounded poses, affordances, and manipulation states. It further connects object and scene memories with transition memory for action-induced state changes and skill memory for template-grounded and policy-grounded execution. At runtime, the agent performs structured coarse-to-fine retrieval to identify relevant objects, states, transitions, and skills, supporting state-consistent reasoning and skill reuse. Experiments on memory-dependent manipulation, articulated-object generalization, real-world memory evaluation, and ablations show that our approach improves task completion, retrieval accuracy, object re-identification, and cross-object skill generalization over unstructured and embedding-based memory baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an analytic concept-centric memory framework for long-horizon agentic embodied manipulation. Objects and scenes are represented via structured analytic concepts (semantic parts, parametric templates, grounded poses, affordances, manipulation states) linked to transition memory for action-induced changes and skill memory for template- and policy-grounded execution. At runtime the agent performs structured coarse-to-fine retrieval to support state-consistent reasoning and skill reuse. Experiments on memory-dependent manipulation, articulated-object generalization, real-world evaluation, and ablations are stated to demonstrate gains in task completion, retrieval accuracy, object re-identification, and cross-object skill generalization relative to unstructured and embedding-based baselines.
Significance. If the extraction and maintenance of analytic concepts can be shown to be reliable, class-agnostic, and computationally tractable, the framework would address a recognized limitation of current memory architectures in robotic manipulation by enabling structured reuse of parts, states, and skills. The absence of any equations, extraction algorithms, or quantitative results in the supplied text, however, leaves the practical significance unassessable.
major comments (2)
- [Abstract] Abstract: the central claim that the approach 'improves task completion, retrieval accuracy, object re-identification, and cross-object skill generalization' is asserted without any dataset descriptions, error bars, ablation tables, or even the number of trials. This prevents verification of the quantitative results that are load-bearing for the paper's contribution.
- [Abstract] Framework description (abstract): no extraction algorithm, no statement on whether semantic-part or affordance detectors are class-agnostic or require per-object templates/training, and no runtime cost measurements are supplied. Because the reported gains are attributed to the memory organization itself, the lack of this information makes it impossible to determine whether the precondition of reliable, engineering-light concept extraction holds.
Simulated Author's Rebuttal
We thank the referee for the review and the focus on ensuring the abstract supports verification of the claims. We address each point below, noting that the full manuscript supplies the requested details while agreeing that the abstract can be strengthened for standalone readability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the approach 'improves task completion, retrieval accuracy, object re-identification, and cross-object skill generalization' is asserted without any dataset descriptions, error bars, ablation tables, or even the number of trials. This prevents verification of the quantitative results that are load-bearing for the paper's contribution.
Authors: We agree the abstract, being concise, omits these specifics. The full manuscript details the datasets, reports error bars and ablation tables, and states the number of trials in the Experiments section. To address the concern, we will revise the abstract to include a brief reference to the experimental scale and conditions. revision: yes
-
Referee: [Abstract] Framework description (abstract): no extraction algorithm, no statement on whether semantic-part or affordance detectors are class-agnostic or require per-object templates/training, and no runtime cost measurements are supplied. Because the reported gains are attributed to the memory organization itself, the lack of this information makes it impossible to determine whether the precondition of reliable, engineering-light concept extraction holds.
Authors: The abstract summarizes at a high level; the full manuscript describes the extraction algorithms, notes the class-agnostic nature of the detectors for semantic parts and affordances (using off-the-shelf models without per-object training), and reports runtime costs in the implementation and experiments. We will revise the abstract to briefly indicate these properties of the concept extraction process. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, fitted parameters, predictions of derived quantities, or self-citations used to justify uniqueness theorems or ansatzes. The framework is described in terms of structured concepts and retrieval, with performance claims resting on experimental comparisons to baselines rather than any reduction of outputs to inputs by construction. No load-bearing steps match the enumerated circularity patterns; the central claims remain independent of self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Objects and scenes can be decomposed into reusable analytic concepts (semantic parts, parametric templates, grounded poses, affordances, manipulation states) that remain stable enough for retrieval across interactions.
invented entities (1)
-
analytic concept-centric memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , note =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Do as i can, not as i say: Grounding language in robotic affordances , author=. arXiv preprint arXiv:2204.01691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
RT-1: Robotics Transformer for Real-World Control at Scale
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Towards Long-horizon Embodied Agents with Tool-Aligned Vision-Language-Action Models
Towards Long-horizon Embodied Agents with Tool-Aligned Vision-Language-Action Models , author=. arXiv preprint arXiv:2605.13119 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2602.21531 , year=
LiLo-VLA: Compositional long-horizon manipulation via linked object-centric policies , author=. arXiv preprint arXiv:2602.21531 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Thinkact: Vision-language-action reasoning via reinforced visual latent planning , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
2025 , eprint=
Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents , author=. 2025 , eprint=
2025
-
[15]
2023 IEEE International conference on robotics and automation (ICRA) , pages=
Code as policies: Language model programs for embodied control , author=. 2023 IEEE International conference on robotics and automation (ICRA) , pages=. 2023 , organization=
2023
-
[16]
arXiv preprint arXiv:2508.10399 , year=
Large model empowered embodied ai: A survey on decision-making and embodied learning , author=. arXiv preprint arXiv:2508.10399 , year=
-
[17]
, author=
MemGPT: towards LLMs as operating systems. , author=. 2023 , publisher=
2023
-
[18]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Skillweaver: Web agents can self-improve by discovering and honing skills , author=. arXiv preprint arXiv:2504.07079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Sun, Jianhua and Li, Yuxuan and Wei, Jiude and Xu, Longfei and Wang, Nange and Zhang, Yining and Lu, Cewu , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[20]
ConceptFactory: Facilitate 3D Object Knowledge Annotation with Object Conceptualization , volume =
Sun, Jianhua and Li, Yuxuan and Xu, Longfei and Wang, Nange and Wei, Jiude and Zhang, Yining and Lu, Cewu , booktitle =. ConceptFactory: Facilitate 3D Object Knowledge Annotation with Object Conceptualization , volume =. doi:10.52202/079017-2402 , editor =
-
[21]
Memp: Exploring Agent Procedural Memory
Memp: Exploring agent procedural memory , author=. arXiv preprint arXiv:2508.06433 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2510.24699 , year=
AgentFold: Long-Horizon Web Agents with Proactive Context Management , author=. arXiv preprint arXiv:2510.24699 , year=
-
[23]
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
Darwin godel machine: Open-ended evolution of self-improving agents , author=. arXiv preprint arXiv:2505.22954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
International Conference on Learning Representations , volume=
Sam 2: Segment anything in images and videos , author=. International Conference on Learning Representations , volume=
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Foundationpose: Unified 6d pose estimation and tracking of novel objects , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Point transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
arXiv preprint arXiv:2508.05294 , year=
Towards embodied agentic ai: Review and classification of llm-and vlm-driven robot autonomy and interaction , author=. arXiv preprint arXiv:2508.05294 , year=
-
[29]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Karma: Augmenting embodied ai agents with long-and-short term memory systems , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
-
[30]
arXiv preprint arXiv:2603.01229 , year=
Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design , author=. arXiv preprint arXiv:2603.01229 , year=
-
[31]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation , author=. arXiv preprint arXiv:2508.19236 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Where2act: From pixels to actions for articulated 3d objects , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
International Conference on Machine Learning , year=
M+: Extending MemoryLLM with Scalable Long-Term Memory , author=. International Conference on Machine Learning , year=
-
[34]
arXiv preprint arXiv:2510.20328 , year=
Memer: Scaling up memory for robot control via experience retrieval , author=. arXiv preprint arXiv:2510.20328 , year=
-
[35]
arXiv preprint arXiv:2502.14254 , year=
Mem2ego: Empowering vision-language models with global-to-ego memory for long-horizon embodied navigation , author=. arXiv preprint arXiv:2502.14254 , year=
-
[36]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y and others , booktitle=. _
-
[37]
Memory in the Age of AI Agents
Memory in the age of ai agents , author=. arXiv preprint arXiv:2512.13564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Retrieval-augmented embodied agents , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
arXiv preprint arXiv:2506.22355 , year=
Embodied ai agents: Modeling the world , author=. arXiv preprint arXiv:2506.22355 , year=
-
[40]
Science Robotics , volume=
Navigating to objects in the real world , author=. Science Robotics , volume=. 2023 , publisher=
2023
-
[41]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scene memory transformer for embodied agents in long-horizon tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sapien: A simulated part-based interactive environment , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[44]
arXiv preprint arXiv:2406.07549 , year=
A3vlm: Actionable articulation-aware vision language model , author=. arXiv preprint arXiv:2406.07549 , year=
-
[45]
arXiv preprint arXiv:2603.12942 , year=
ReMem-VLA: Empowering Vision-Language-Action Model with Memory via Dual-Level Recurrent Queries , author=. arXiv preprint arXiv:2603.12942 , year=
-
[46]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
-
[47]
arXiv preprint arXiv:2505.03673 , year=
Roboos: A hierarchical embodied framework for cross-embodiment and multi-agent collaboration , author=. arXiv preprint arXiv:2505.03673 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.