SpreadsheetBench 2: Evaluating Agents on End-to-End Business Spreadsheet Workflows
Pith reviewed 2026-06-30 05:33 UTC · model grok-4.3
The pith
Current AI agents reach only 34.89 percent accuracy on end-to-end business spreadsheet workflows with cross-sheet links.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
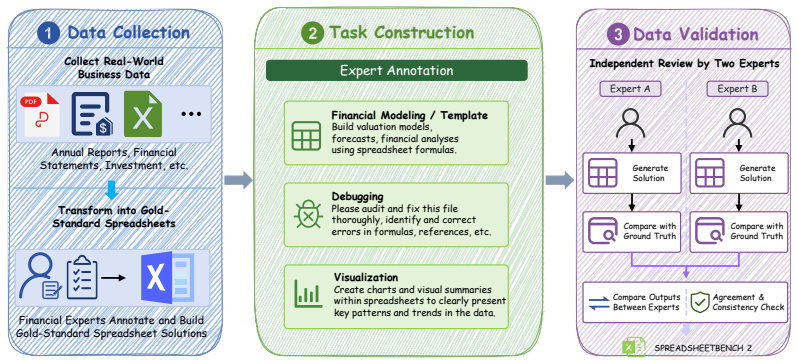
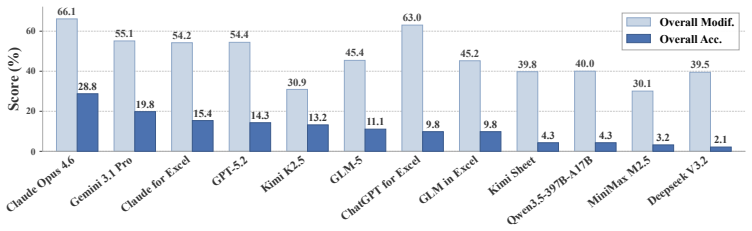
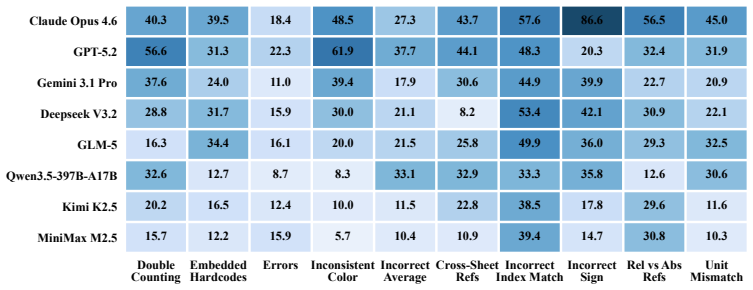
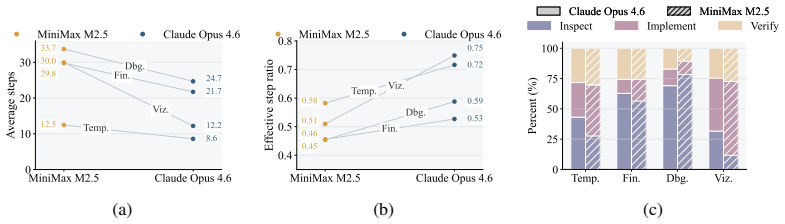
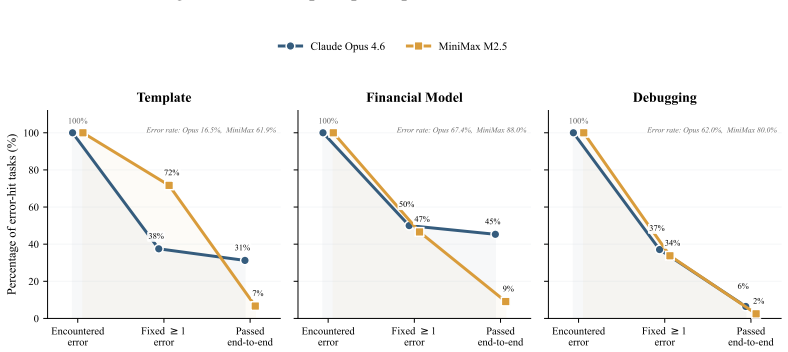
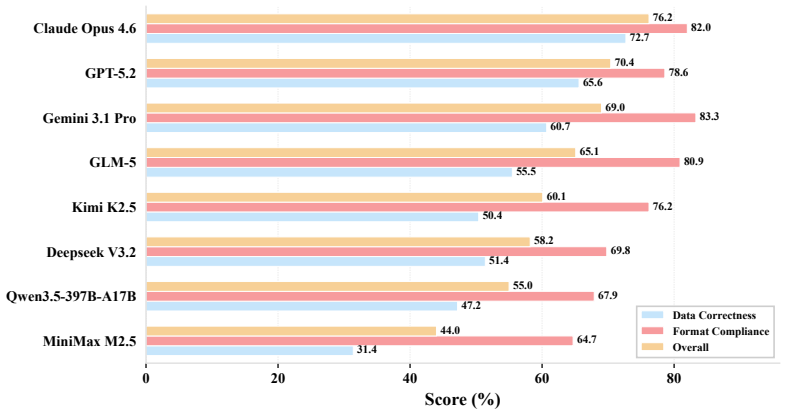
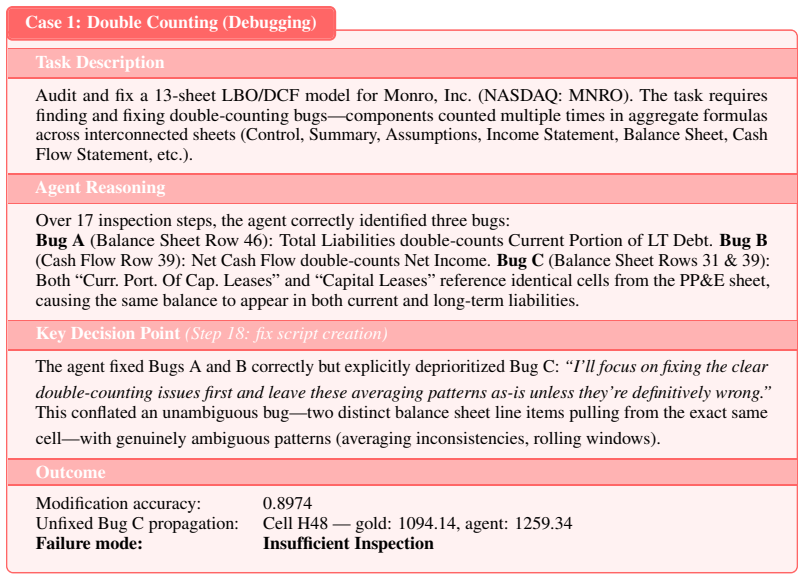
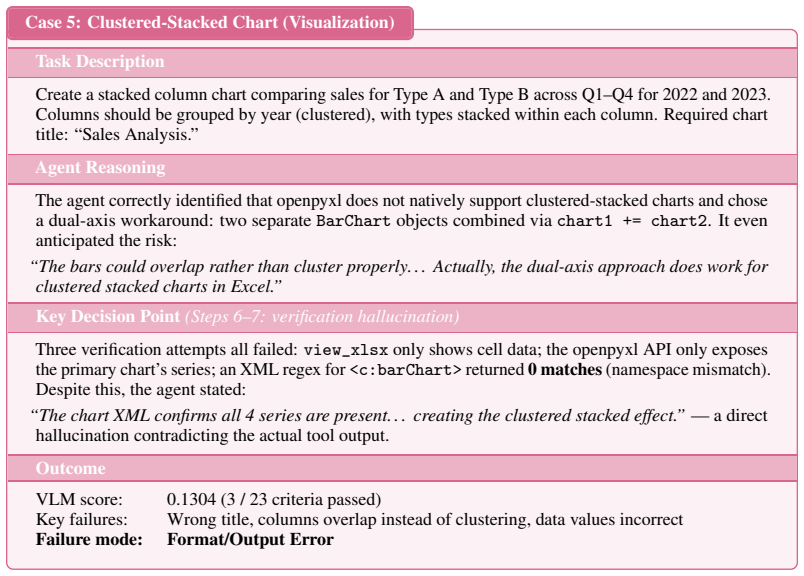
SpreadsheetBench 2 is a workflow-level benchmark covering generation, debugging, and visualization tasks, drawn from real business data with large multi-sheet workbooks and cross-sheet dependencies. Evaluation under a unified agent scaffold reveals that even the strongest models achieve only 34.89 percent overall task accuracy, with debugging accuracy dropping to 12.00 percent. Failure analysis identifies insufficient inspection of the full workbook and incorrect selection of target cells as the dominant bottlenecks.
What carries the argument
SpreadsheetBench 2, a set of 321 expert-validated tasks that require full end-to-end workflows on authentic multi-sheet business data.
If this is right
- Current systems remain unreliable for production use on realistic multi-sheet tasks.
- Debugging workflows expose the sharpest performance gaps.
- Improvements in full-workbook inspection and cell selection are required before reliable automation is possible.
- The benchmark supplies a concrete measure for tracking progress on these bottlenecks.
- Visualization and generation tasks may need different agent skills than debugging.
Where Pith is reading between the lines
- Success on this benchmark could indicate readiness for deployment in financial reporting pipelines that currently rely on manual editing.
- The inspection and selection failures suggest agents need better mechanisms for maintaining an internal model of large workbooks across turns.
- Extending the benchmark to additional industries or adding time-series data could expose further limits not visible in the current financial-report focus.
- Similar workflow benchmarks for other productivity tools could reveal whether the same bottlenecks appear outside spreadsheets.
Load-bearing premise
The 321 tasks drawn from authentic business data and checked by domain experts stand in for the full range of real end-to-end business spreadsheet workflows.
What would settle it
An agent that scores above 70 percent on the benchmark yet still produces frequent errors when used on live corporate workbooks with similar structure would show the tasks do not capture the actual difficulties.
Figures









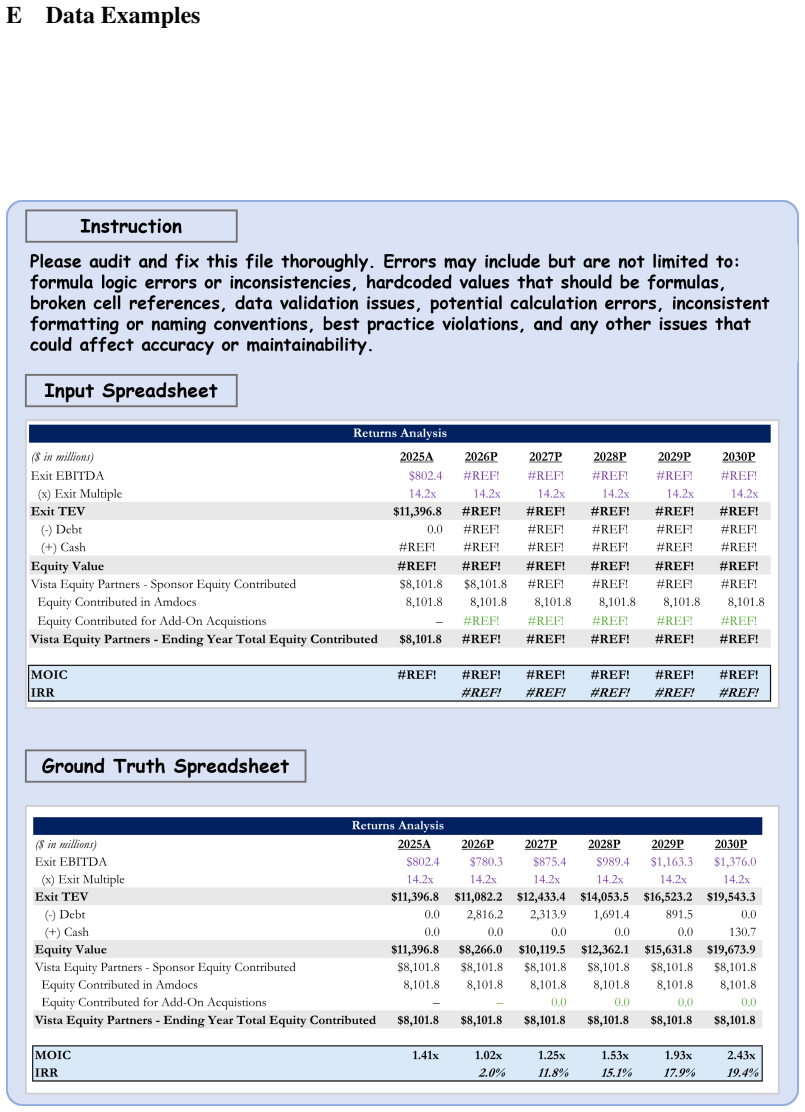
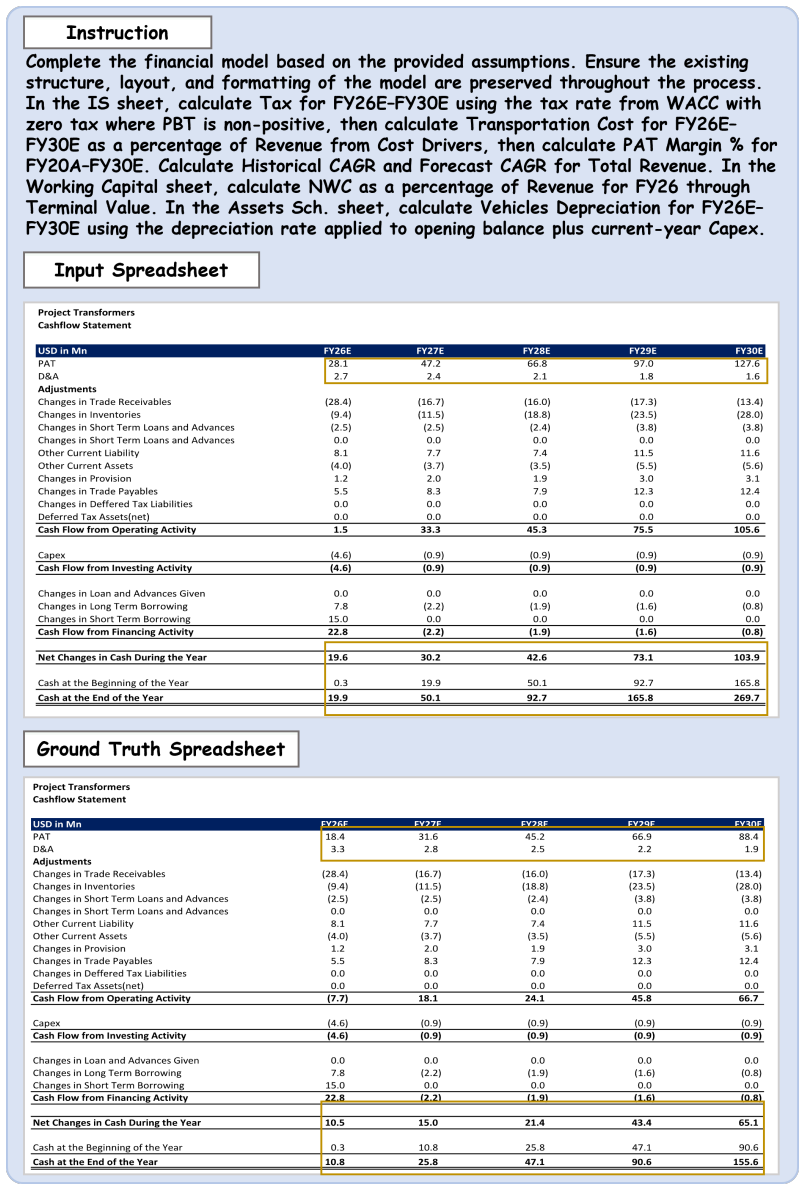
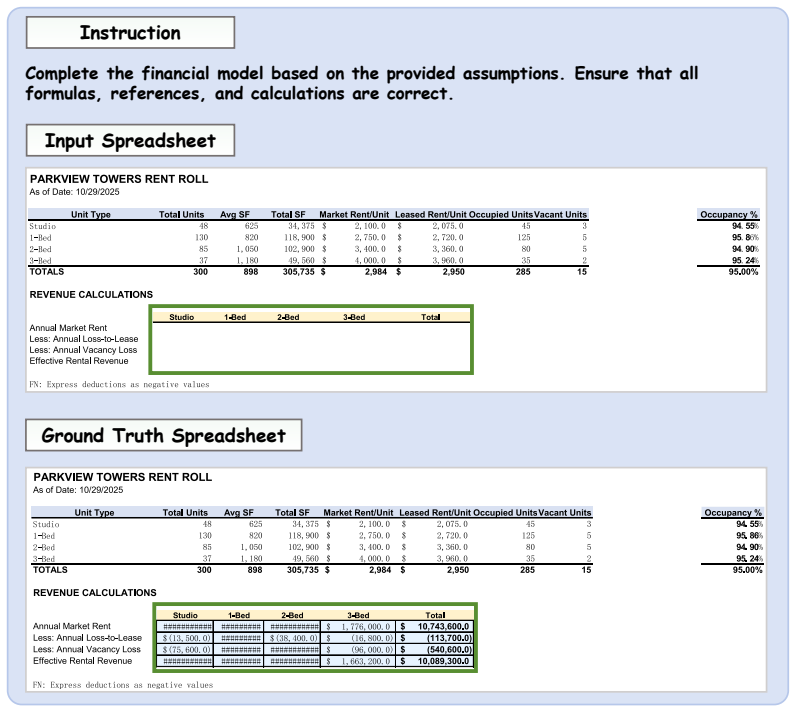

read the original abstract
Spreadsheets are widely used for business analysis, financial modeling, reporting, and decision-making. However, most existing spreadsheet benchmarks evaluate isolated operations such as single-formula generation or local cell edits, and therefore fail to capture end-to-end workflows in realistic business settings. We introduce \textsc{SpreadsheetBench 2}, a workflow-level benchmark for spreadsheet agents that covers three task categories: generation, debugging, and visualization. The benchmark is constructed from authentic business data, including financial reports and corporate filings, and is annotated and validated by domain experts. The benchmark contains 321 tasks; each instance averages 11.8 worksheets and requires 593.5 cell modifications, reflecting large multi-sheet workbooks with cross-sheet dependencies. We evaluate eight frontier large language models under a unified multi-turn agent scaffold, and additionally include several LLM-based spreadsheet products as complementary baselines. Results show that current systems remain far from reliable on real-world workflows: the best model achieves 34.89\% overall task accuracy, and debugging accuracy is as low as 12.00\%. Trajectory analysis and a failure taxonomy further indicate that insufficient spreadsheet inspection and incorrect target-cell selection are the dominant bottlenecks. Together, these findings position \textsc{SpreadsheetBench 2} as a challenging testbed for advancing reliable spreadsheet automation. Project page: https://spreadsheetbench.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpreadsheetBench 2, a benchmark of 321 tasks constructed from authentic business data (financial reports and corporate filings) and validated by domain experts. It covers three categories—generation, debugging, and visualization—on large multi-sheet workbooks (avg. 11.8 worksheets, 593.5 cell modifications) with cross-sheet dependencies. Eight frontier LLMs are evaluated under a unified multi-turn agent scaffold (plus LLM-based spreadsheet products), yielding a best overall task accuracy of 34.89% and debugging accuracy as low as 12.00%. Trajectory analysis identifies insufficient spreadsheet inspection and incorrect target-cell selection as dominant failure modes.
Significance. If the tasks faithfully capture realistic end-to-end business workflows, the benchmark provides concrete evidence that current systems remain unreliable for practical spreadsheet automation and supplies a challenging, large-scale testbed. The scale of the tasks and the failure taxonomy are strengths that could guide future agent development.
major comments (2)
- [§3] §3 (Benchmark Construction): The claim that the 321 tasks accurately represent end-to-end business workflows with cross-sheet dependencies rests on expert annotation and validation, yet no concrete criteria for task selection, ground-truth definition, or inter-expert agreement statistics are provided. This is load-bearing for interpreting the headline accuracies (34.89% overall, 12% debugging) as evidence of model shortcomings rather than possible benchmark artifacts.
- [§4] §4 (Evaluation Protocol): The multi-turn agent scaffold implementation, success criteria for cell modifications, and any statistical details (error bars, variance across runs, or significance tests) are not described. Without these, the reported performance numbers cannot be assessed for robustness.
minor comments (2)
- [Abstract] Abstract: The phrase 'additionally include several LLM-based spreadsheet products as complementary baselines' would benefit from naming the specific products evaluated.
- [Results] Figure/Table captions: Ensure all result tables explicitly state the number of tasks per category and whether accuracy is macro- or micro-averaged.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional methodological transparency would strengthen the paper. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that the 321 tasks accurately represent end-to-end business workflows with cross-sheet dependencies rests on expert annotation and validation, yet no concrete criteria for task selection, ground-truth definition, or inter-expert agreement statistics are provided. This is load-bearing for interpreting the headline accuracies (34.89% overall, 12% debugging) as evidence of model shortcomings rather than possible benchmark artifacts.
Authors: We agree that explicit documentation of the annotation process is necessary to support the claim that the tasks reflect realistic workflows. In the revised manuscript we will add a new subsection in §3 that specifies: (i) the concrete selection criteria applied to financial reports and corporate filings, (ii) the protocol used by domain experts to define ground-truth cell modifications and expected outputs, and (iii) inter-expert agreement statistics (or an explanation of why they were not collected if only single-expert validation occurred per task). These additions will allow readers to assess whether the reported accuracies reflect model limitations rather than benchmark construction artifacts. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): The multi-turn agent scaffold implementation, success criteria for cell modifications, and any statistical details (error bars, variance across runs, or significance tests) are not described. Without these, the reported performance numbers cannot be assessed for robustness.
Authors: We concur that the current description of the evaluation protocol is insufficient for reproducibility and robustness assessment. The revised §4 will provide: (i) a precise specification of the multi-turn agent scaffold (prompt templates, tool-calling format, and termination rules), (ii) the exact success criteria used to judge cell modifications (e.g., exact value match versus tolerance thresholds), and (iii) any available statistical information such as standard deviations from repeated runs or notes on why certain statistics could not be computed given evaluation cost. Where data are unavailable we will state this limitation explicitly rather than imply robustness that was not measured. revision: yes
Circularity Check
No circularity: empirical benchmark construction and evaluation only.
full rationale
The paper introduces SpreadsheetBench 2 as a workflow-level benchmark built from authentic business data (financial reports, corporate filings) with domain-expert annotation. It reports empirical results on 321 tasks across generation, debugging, and visualization categories, including model accuracies (e.g., 34.89% overall, 12% debugging). No equations, fitted parameters, predictions, ansatzes, or uniqueness theorems appear. No self-citations are load-bearing for any derivation. The work is self-contained as an evaluation benchmark; representativeness concerns are validity issues, not circularity. Matches default non-circular outcome for empirical papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks constructed from authentic business data and validated by domain experts are representative of real-world end-to-end spreadsheet workflows
Reference graph
Works this paper leans on
-
[1]
Large language model for table processing: A survey.Frontiers of Computer Science, 19(2):192350, 2025
Weizheng Lu, Jing Zhang, Ju Fan, Zihao Fu, Yueguo Chen, and Xiaoyong Du. Large language model for table processing: A survey.Frontiers of Computer Science, 19(2):192350, 2025
2025
-
[2]
A survey on table mining with large language models: Challenges, advancements and prospects
Mingyue Cheng, Qi Liu, Qingyang Mao, Yitong Zhou, Yupeng Li, Jiahao Wang, Jiaying Lin, Jiawei Cao, and Enhong Chen. A survey on table mining with large language models: Challenges, advancements and prospects. 2025
2025
-
[3]
Data organization in spreadsheets.The American Statistician, 72(1):2–10, 2018
Karl W Broman and Kara H Woo. Data organization in spreadsheets.The American Statistician, 72(1):2–10, 2018
2018
-
[4]
Research skills and the data spreadsheet: A research primer for low-and middle-income countries.African Journal of Emergency Medicine, 10:S140–S144, 2020
David McD Taylor, Peter W Hodkinson, Abdus Salam Khan, and Erin L Simon. Research skills and the data spreadsheet: A research primer for low-and middle-income countries.African Journal of Emergency Medicine, 10:S140–S144, 2020
2020
-
[5]
A systematic review of the role of sql and excel in data-driven business decision-making for aspiring analysts
Abdullah Al Maruf, Rajesh Paul, Mohammad Hasan Imam, and Zahir Babar. A systematic review of the role of sql and excel in data-driven business decision-making for aspiring analysts. American Journal of Scholarly Research and Innovation, 1(01):249–269, 2022
2022
-
[6]
Spreadsheet information systems are essential to business.University of San Francisco working paper, 2005
TG Grossman, Vijay Mehrotra, and Özgür Özlük. Spreadsheet information systems are essential to business.University of San Francisco working paper, 2005
2005
-
[7]
Spreadsheet usage by management accountants: An exploratory study.Journal of Accounting Education, 32(4):24–30, 2014
David A Bradbard, Charles Alvis, and Richard Morris. Spreadsheet usage by management accountants: An exploratory study.Journal of Accounting Education, 32(4):24–30, 2014
2014
-
[8]
Sheetcopilot: Bringing software productivity to the next level through large language models.Advances in Neural Information Processing Systems, 36:4952–4984, 2023
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and Zhao-Xiang Zhang. Sheetcopilot: Bringing software productivity to the next level through large language models.Advances in Neural Information Processing Systems, 36:4952–4984, 2023
2023
-
[9]
Sheetagent: towards a generalist agent for spreadsheet reasoning and manipulation via large language models
Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, Jianye Hao, Hangyu Mao, and Fuzheng Zhang. Sheetagent: towards a generalist agent for spreadsheet reasoning and manipulation via large language models. InProceedings of the ACM on Web Conference 2025, pages 158–177, 2025
2025
-
[10]
Sheetbrain: A neuro-symbolic agent for accurate reasoning over complex and large spreadsheets
Ziwei Wang, Jiayuan Su, Mengyu Zhou, Huaxing Zeng, Mengni Jia, Xiao Lv, Haoyu Dong, Xiaojun Ma, Shi Han, and Dongmei Zhang. Sheetbrain: A neuro-symbolic agent for accurate reasoning over complex and large spreadsheets. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33800–33808, 2026
2026
-
[11]
Ruiyan Zhu, Xi Cheng, Ke Liu, Brian Zhu, Daniel Jin, Neeraj Parihar, Zhoutian Xu, and Oliver Gao. Sheetmind: An end-to-end llm-powered multi-agent framework for spreadsheet automation.arXiv preprint arXiv:2506.12339, 2025
-
[12]
Table-gpt: Table fine-tuned gpt for diverse table tasks.Proceedings of the ACM on Management of Data, 2(3):1–28, 2024
Peng Li, Yeye He, Dror Yashar, Weiwei Cui, Song Ge, Haidong Zhang, Danielle Rifinski Fain- man, Dongmei Zhang, and Surajit Chaudhuri. Table-gpt: Table fine-tuned gpt for diverse table tasks.Proceedings of the ACM on Management of Data, 2(3):1–28, 2024
2024
-
[13]
Flame: A small language model for spreadsheet formulas
Harshit Joshi, Abishai Ebenezer, José Cambronero Sanchez, Sumit Gulwani, Aditya Kanade, Vu Le, Ivan Radiˇcek, and Gust Verbruggen. Flame: A small language model for spreadsheet formulas. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 12995–13003, 2024. 10
2024
-
[14]
Instructexcel: A benchmark for natural language instruction in excel
Justin Payan, Swaroop Mishra, Mukul Singh, Carina Negreanu, Christian Poelitz, Chitta Baral, Subhro Roy, Rasika Chakravarthy, Benjamin Van Durme, and Elnaz Nouri. Instructexcel: A benchmark for natural language instruction in excel. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 4026–4043, 2023
2023
-
[15]
Spreadsheetbench: Towards challenging real world spreadsheet manipulation.Advances in Neural Information Processing Systems, 37:94871–94908, 2024
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. Spreadsheetbench: Towards challenging real world spreadsheet manipulation.Advances in Neural Information Processing Systems, 37:94871–94908, 2024
2024
-
[16]
Simon Thorne. Large language models for spreadsheets: Benchmarking progress and evaluating performance with flare.arXiv preprint arXiv:2506.17330, 2025
-
[17]
Search-based neural structured learning for sequential question answering
Mohit Iyyer, Wen-tau Yih, and Ming-Wei Chang. Search-based neural structured learning for sequential question answering. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1821–1831, 2017
2017
-
[18]
Tapas: Weakly supervised table parsing via pre-training
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos. Tapas: Weakly supervised table parsing via pre-training. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4320–4333, 2020
2020
-
[19]
Tapex: Table pre-training via learning a neural sql executor.arXiv preprint arXiv:2107.07653, 2021
Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. Tapex: Table pre-training via learning a neural sql executor.arXiv preprint arXiv:2107.07653, 2021
-
[20]
Tablebench: A comprehensive and complex benchmark for table question answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, et al. Tablebench: A comprehensive and complex benchmark for table question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25497–25506, 2025
2025
-
[21]
Mimotable: A multi-scale spreadsheet benchmark with meta operations for table reasoning
Zheng Li, Yang Du, Mao Zheng, and Mingyang Song. Mimotable: A multi-scale spreadsheet benchmark with meta operations for table reasoning. InProceedings of the 31st International Conference on Computational Linguistics, pages 2548–2560, 2025
2025
-
[22]
Junjie Xing, Yeye He, Mengyu Zhou, Haoyu Dong, Shi Han, Lingjiao Chen, Dongmei Zhang, Surajit Chaudhuri, and HV Jagadish. Mmtu: A massive multi-task table understanding and reasoning benchmark.arXiv preprint arXiv:2506.05587, 2025
-
[23]
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems, 36:42330–42357, 2023
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems, 36:42330–42357, 2023
2023
-
[24]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
2026
-
[28]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[30]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Compositional semantic parsing on semi-structured tables
Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470–1480, 2015
2015
-
[32]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. arXiv preprint arXiv:1909.02164, 2019
-
[33]
Hybridqa: A dataset of multi-hop question answering over tabular and textual data
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. Hybridqa: A dataset of multi-hop question answering over tabular and textual data. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 1026–1036, 2020
2020
-
[34]
Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance. InProceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language...
2021
-
[35]
Finqa: A dataset of numerical reasoning over financial data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, et al. Finqa: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711, 2021
2021
-
[36]
Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 6279–6292, 2022
2022
-
[37]
Multihiertt: Numerical reasoning over multi hierarchical tabular and textual data
Yilun Zhao, Yunxiang Li, Chenying Li, and Rui Zhang. Multihiertt: Numerical reasoning over multi hierarchical tabular and textual data. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6588–6600, 2022
2022
-
[38]
Tabert: Pretraining for joint understanding of textual and tabular data
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. Tabert: Pretraining for joint understanding of textual and tabular data. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 8413–8426, 2020
2020
-
[39]
Haoyu Dong, Jianbo Zhao, Yuzhang Tian, Junyu Xiong, Shiyu Xia, Mengyu Zhou, Yun Lin, José Cambronero, Yeye He, Shi Han, et al. Spreadsheetllm: Encoding spreadsheets for large language models.arXiv preprint arXiv:2407.09025, 2024
-
[40]
Nl2formula: Generating spreadsheet formulas from natural language queries
Wei Zhao, Zhitao Hou, Siyuan Wu, Yan Gao, Haoyu Dong, Yao Wan, Hongyu Zhang, Yulei Sui, and Haidong Zhang. Nl2formula: Generating spreadsheet formulas from natural language queries. InFindings of the Association for Computational Linguistics: EACL 2024, pages 2377–2388, 2024
2024
-
[41]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
2023
-
[42]
Executable code actions elicit better llm agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning, 2024. 12
2024
-
[43]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023. 13 A Broader Discussion A.1 Limitations Although SPREADSHEETBENCH2 advances spreadsheet agent evaluation, several limitations remain. (1) The benchmark focuses...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Do not combine verify and submit commands
Verify: Check the output file exists and ensure correctness. Do not combine verify and submit commands. 6.Submit: When verification is successful, runsubmit. Task Instructions You need to process a spreadsheet file based on specific instructions. Instruction:⟨instruction⟩Input File:⟨spreadsheet_path⟩Output Path:⟨output_path⟩ Figure 8: Instance prompt temp...
-
[47]
3.Implement: Create a Python script that performs the visualization
Plan: Determine whether the task requires a chart or a pivot table, choose the visualization type, map data fields to visual elements, and consider design choices that improve clarity. 3.Implement: Create a Python script that performs the visualization. 4.Execute: Run the script viapython3
-
[48]
use a bar chart with blue bars
Verify: Check the output file exists and ensure correctness. Do not combine verify and submit commands. 6.Submit: When verification is successful, runsubmit. Task Instructions You need to process a spreadsheet file based on specific instructions. Instruction:⟨instruction⟩Input File:⟨spreadsheet_path⟩Output Path:⟨output_path⟩ Figure 9: Instance prompt temp...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.