MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
Pith reviewed 2026-06-30 06:23 UTC · model grok-4.3
The pith
MuseBench reveals that top multimodal models reach only 48.29 percent accuracy on questions about artistic intent, compared to 87.18 percent for human experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
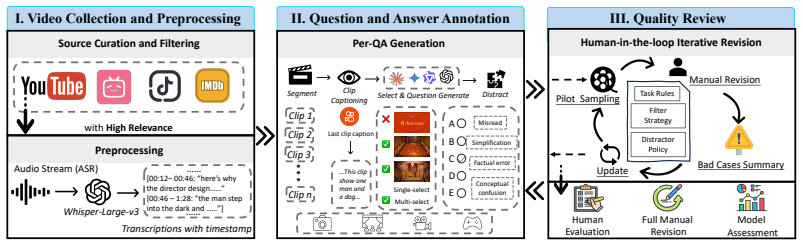
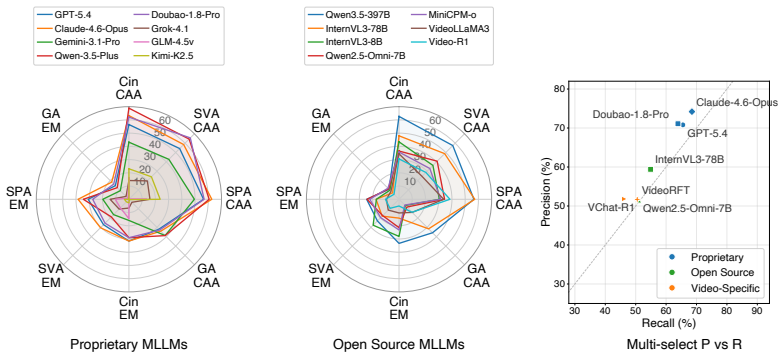
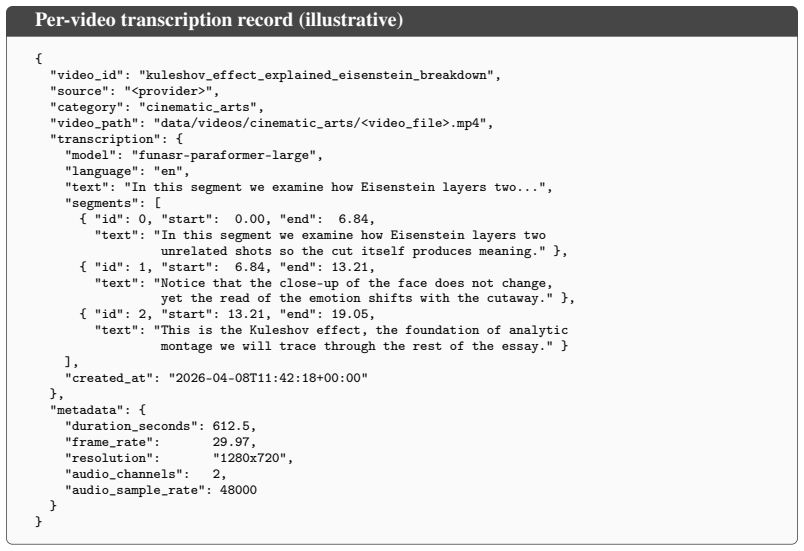
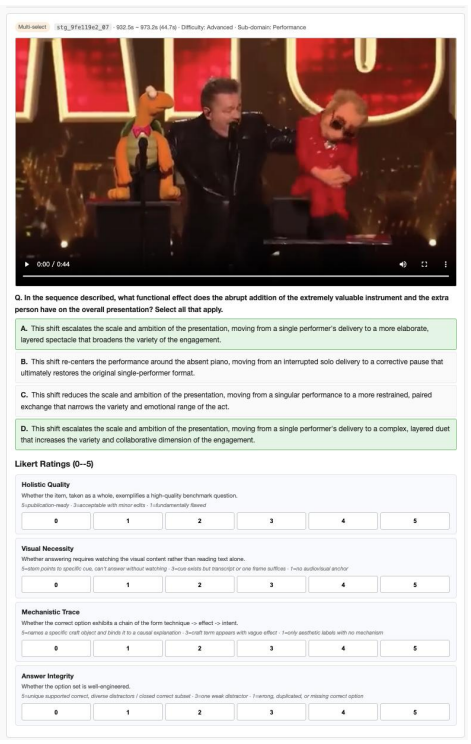
MuseBench comprises 4,016 questions spanning cinematic arts, static visual arts, stage performing arts, and game arts, generated from over 10K candidate video essays that pair professional commentary with visual demonstration. Questions are refined through a four-phase iterative pipeline that applies shortcut filtering, adversarial distractors, and expert validation to focus on reasoning about why artistic elements are combined in particular ways rather than on surface recognition. Comprehensive zero-shot evaluation of 28 state-of-the-art MLLMs shows a best accuracy of 48.29 percent against 87.18 percent for human experts.
What carries the argument
MuseBench benchmark, built by distilling single-select and variable-option multi-select questions from professional video essays through shortcut filtering, adversarial distractors, and expert validation.
If this is right
- Current MLLM benchmarks measure perceptual recognition but miss reasoning about creative intent.
- Models must improve at linking visual and auditory choices to specific narrative or emotional outcomes.
- The documented gap indicates deficiencies in creative domain expertise across leading multimodal systems.
- Development of new training approaches focused on artistic analysis would be required to close the observed difference.
Where Pith is reading between the lines
- Training corpora for MLLMs likely under-represent examples that require explicit reasoning about artistic technique.
- Performance on this benchmark may correlate with success on other tasks that demand causal explanation of multimodal signals.
- The question format could be adapted to test intent reasoning in non-art domains such as scientific visualization or instructional media.
Load-bearing premise
The four-phase pipeline produces questions that capture nuanced artistic understanding without introducing biases or permitting shortcut solutions.
What would settle it
A model that scores above 75 percent on MuseBench while its accuracy on existing perceptual benchmarks remains unchanged, or a re-run of the expert validation showing human performance below 70 percent.
Figures















read the original abstract
Audiovisual arts encompass diverse creative disciplines, including cinema, visual arts, stage performance, and game design, where artistic meaning arises from deliberate combinations of visual, auditory, and narrative elements (e.g., fear amplified through claustrophobic framing, or grief conveyed through silence and lingering close-ups). True artistic understanding extends beyond recognizing what is depicted to reasoning about why it is expressed through particular creative choices. Despite the strong progress of multimodal large language models (MLLMs), this critical aspect of artistic understanding remains underexplored, as existing benchmarks largely measure perceptual recognition while overlooking reasoning about creative intent. To address this gap, we introduce Musebench, a comprehensive benchmark designed to evaluate MLLMs on nuanced artistic understanding. It comprises 4,016 questions spanning cinematic arts, static visual arts, stage performing arts, and game arts, distilled from over 10K candidate video essays that pair professional commentary with visual demonstration. To capture the open-ended nature of artistic analysis at scale, the benchmark combines single-select and variable-option multi-select questions. All questions are generated and refined through a four-phase iterative pipeline combining shortcut filtering, adversarial distractors, and expert validation. Comprehensive zero-shot evaluation of 28 state-of-the-art MLLMs reveals that even the best-performing model achieves only 48.29% accuracy, substantially below human expert performance of 87.18%, exposing a significant gap in current models' creative domain expertise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MuseBench, a benchmark with 4,016 questions across cinematic arts, static visual arts, stage performing arts, and game arts to evaluate MLLMs on intent-level audiovisual arts understanding. Questions are derived from over 10K video essays via a four-phase iterative pipeline of shortcut filtering, adversarial distractors, and expert validation. Zero-shot evaluations of 28 MLLMs show the top model achieving 48.29% accuracy, compared to 87.18% for human experts, indicating a substantial gap in models' creative domain expertise.
Significance. If the benchmark questions validly assess nuanced artistic intent reasoning without artifacts, the results would highlight important limitations in current MLLMs for creative multimodal tasks. The benchmark's scale and multi-domain coverage could serve as a valuable resource for future model development in artistic understanding.
major comments (1)
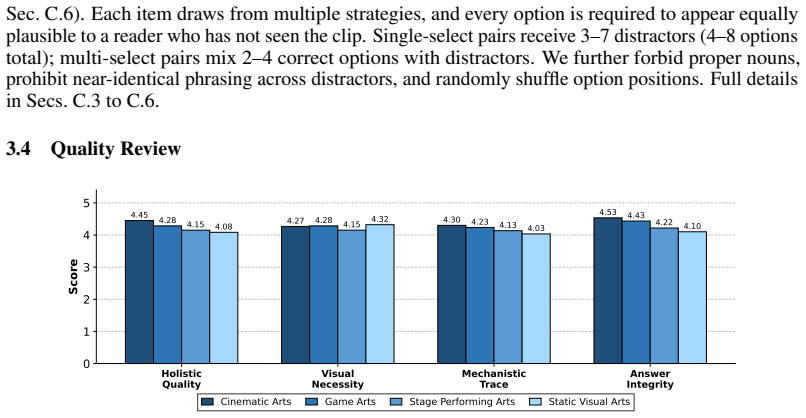
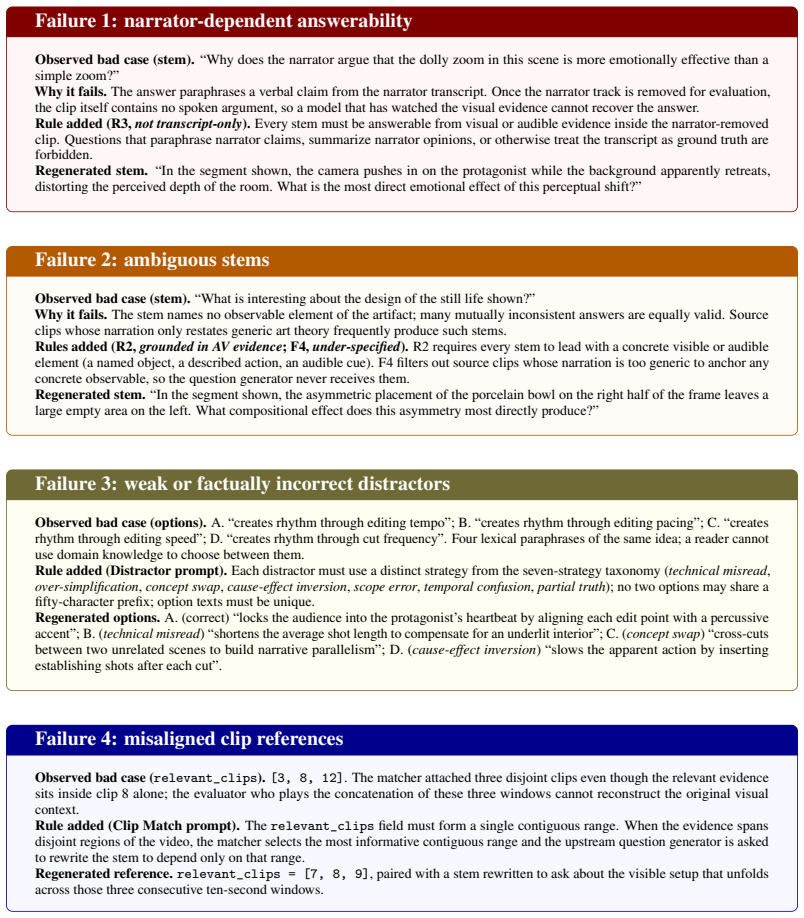
- [four-phase iterative pipeline description] The central claim of a significant gap in creative domain expertise (48.29% model vs. 87.18% human) depends on the four-phase pipeline producing questions that probe intent-level reasoning rather than perceptual shortcuts or biases. The manuscript describes the pipeline but reports no ablation results, shortcut filtering success rates, inter-annotator agreement on intent capture, or control experiments (e.g., accuracy on versions without adversarial distractors). This is load-bearing for the headline result.
minor comments (2)
- [evaluation results] Reported accuracies lack error bars, confidence intervals, or details on evaluation variance across multiple runs or question subsets.
- [abstract] The abstract states 'comprehensive zero-shot evaluation of 28 state-of-the-art MLLMs' but does not reference a specific table or section listing all models and their per-category scores.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating that our four-phase pipeline produces questions targeting intent-level reasoning. We address this point directly below.
read point-by-point responses
-
Referee: [four-phase iterative pipeline description] The central claim of a significant gap in creative domain expertise (48.29% model vs. 87.18% human) depends on the four-phase pipeline producing questions that probe intent-level reasoning rather than perceptual shortcuts or biases. The manuscript describes the pipeline but reports no ablation results, shortcut filtering success rates, inter-annotator agreement on intent capture, or control experiments (e.g., accuracy on versions without adversarial distractors). This is load-bearing for the headline result.
Authors: We agree that the current manuscript lacks the requested quantitative validation of the pipeline and that this weakens support for the headline gap. The description alone does not demonstrate that shortcut filtering succeeded or that questions require intent reasoning. In the revised version we will add: (1) shortcut filtering success rates (percentage of candidates removed at each stage), (2) inter-annotator agreement (Cohen’s kappa) on expert validation of intent capture, and (3) a control experiment reporting model accuracy on a subset of questions before versus after adversarial distractor insertion. These additions will be placed in a new subsection under Section 3. We note that full end-to-end ablations on all 4,016 questions would require substantial additional annotation; we will therefore report results on a representative 500-question subset while making the full pipeline logs available. revision: yes
Circularity Check
No circularity: empirical benchmark evaluated on external models
full rationale
The paper introduces MuseBench via a four-phase pipeline for question generation and reports zero-shot accuracies on 28 external MLLMs (max 48.29%) vs. human experts (87.18%). No equations, fitted parameters, self-citations, or derivations appear in the provided text. The performance gap is measured directly against independent models and human annotators; the pipeline description does not reduce any claimed result to a self-defined input or tautology. This matches the default expectation for a self-contained empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The benchmark questions faithfully measure intent-level artistic understanding
Reference graph
Works this paper leans on
-
[1]
Introducing claude sonnet 4.5.https://www.anthropic.com/news/claude-sonnet-4-5, 2025
Anthropic. Introducing claude sonnet 4.5.https://www.anthropic.com/news/claude-sonnet-4-5, 2025
2025
-
[2]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
S. Barber. Understanding online audio-visual content: a european initiative, media literacy and the user. Medijske studije, 3(06):28–41, 2012
2012
-
[4]
Bresland
J. Bresland. On the origin of the video essay.Blackbird: an online journal of literature and the arts, 9(1), 2010
2010
-
[5]
Carvalho and C
A. Carvalho and C. Lund.The audiovisual breakthrough. Collin & Maierski Print GbR, 2015
2015
-
[6]
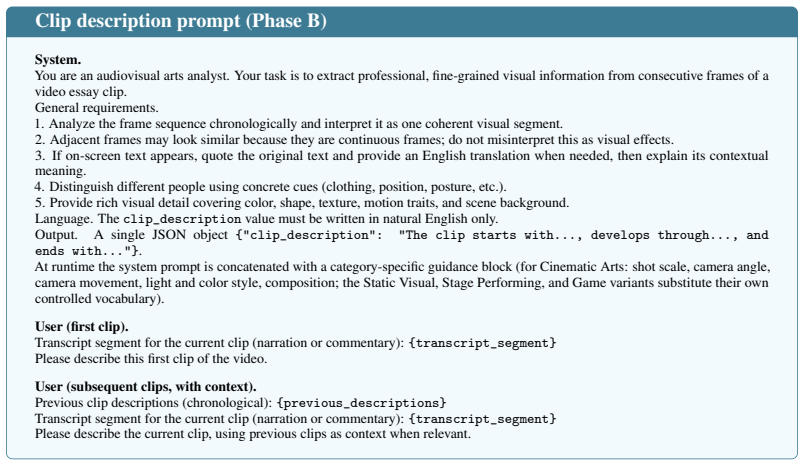
B. Chen, Z. Yue, S. Chen, Z. Wang, Y . Liu, P. Li, and Y . Wang. Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20237–20246, 2025
2025
-
[7]
X. Chen, Y . Lin, Y . Zhang, and W. Huang. Autoeval-video: An automatic benchmark for assessing large vision language models in open-ended video question answering. InEuropean Conference on Computer Vision, pages 179–195. Springer, 2024
2024
-
[8]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Z. Cheng, S. Leng, H. Zhang, Y . Xin, X. Li, G. Chen, Y . Zhu, W. Zhang, Z. Luo, D. Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
M. I. H. Chowdhury, K. Nguyen, S. Sridharan, and C. Fookes. Hierarchical relational attention for video question answering. In2018 25th IEEE International Conference on Image Processing (ICIP), pages 599–603. IEEE, 2018
2018
- [11]
-
[12]
K. Feng, K. Gong, B. Li, Z. Guo, Y . Wang, T. Peng, J. Wu, X. Zhang, B. Wang, and X. Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
C. Fu, Y . Dai, Y . Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y . Shen, M. Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025. 10
2025
- [14]
-
[15]
H. Han, S. Li, J. Chen, Y . Yuan, Y . Wu, Y . Deng, C. T. Leong, H. Du, J. Fu, Y . Li, et al. Video- bench: Human-aligned video generation benchmark. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18858–18868, 2025
2025
-
[16]
Y . He, C. Boo, and J. Yoon. Are video reasoning models ready to go outside?arXiv preprint arXiv:2603.10652, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
K. Hu, P. Wu, F. Pu, W. Xiao, Y . Zhang, X. Yue, B. Li, and Z. Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos.ArXiv, abs/2501.13826, 2025. URL https: //api.semanticscholar.org/CorpusID:275820371
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Huang, Y
Q. Huang, Y . Xiong, A. Rao, J. Wang, and D. Lin. Movienet: A holistic dataset for movie understanding. InEuropean conference on computer vision, pages 709–727. Springer, 2020
2020
-
[20]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
Y . Jang, Y . Song, Y . Yu, Y . Kim, and G. Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2758–2766, 2017
2017
-
[23]
Järvinen
A. Järvinen. Gran stylissimo: The audiovisual elements and styles in computer and video games. In Computer games and digital cultures conference proceedings, 2002
2002
-
[24]
H. M. Kot, O. G. Levchenko, T. O. Kravchenko, and O. S. M. K. V . Hrubych. Problems of intertextuality in audio-visual arts.Rupkatha Journal on Interdisciplinary Studies in Humanities, 13(1), 2021
2021
-
[25]
Krupskyy, N
I. Krupskyy, N. Zykun, A. Ovchynnikova, S. Gorevalov, and O. Mitchuk. Determinants and modern genres of audio-visual art.Journal of the Balkan Tribological Association, 27(4), 2021
2021
-
[26]
E. Lavik. The video essay: The future of academic film and television criticism?Frames Cinema Journal, 1(1):19, 2012
2012
-
[27]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
K. Li, Y . Wang, Y . He, Y . Li, Y . Wang, Y . Liu, Z. Wang, J. Xu, G. Chen, P. Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[29]
X. Li, Z. Yan, D. Meng, L. Dong, X. Zeng, Y . He, Y . Wang, Y . Qiao, Y . Wang, and L. Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning.arXiv preprint arXiv:2504.06958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Y . Liu, S. Li, Y . Liu, Y . Wang, S. Ren, L. Li, S. Chen, X. Sun, and L. Hou. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
2024
-
[31]
Lokki, J
T. Lokki, J. Hiipakka, R. Hänninen, T. Ilmonen, L. Savioja, and T. Takala. Realtime audiovisual rendering and contemporary audiovisual art.Organised Sound, 3(3):219–233, 1998
1998
-
[32]
Mangalam, R
K. Mangalam, R. Akshulakov, and J. Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
2023
-
[33]
M. R. Naphade and T. S. Huang. Extracting semantics from audio-visual content: the final frontier in multimedia retrieval.IEEE Transactions on Neural Networks, 13(4):793–810, 2002. 11
2002
-
[34]
Popplewell, J
M. Popplewell, J. Reizes, and C. Zaslawski. Appropriate statistics for determining chance-removed interpractitioner agreement.The Journal of Alternative and Complementary Medicine: Paradigm, Practice, and Policy Advancing Integrative Health, 25(11):1115–1120, 2019
2019
-
[35]
Radford, J
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[36]
S. Ren, L. Yao, S. Li, X. Sun, and L. Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14313–14323, 2024
2024
-
[37]
X. Shen, Y . Xiong, C. Zhao, L. Wu, J. Chen, C. Zhu, Z. Liu, F. Xiao, B. Varadarajan, F. Bordes, et al. Longvu: Spatiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Y . Shu, P. Zhang, Z. Liu, M. Qin, J. Zhou, T. Huang, and B. Zhao. Video-xl: Extra-long vision lan- guage model for hour-scale video understanding.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26160–26169, 2024. URL https://api.semanticscholar.org/ CorpusID:272827076
2025
-
[39]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Sławek-Czochra and J
M. Sławek-Czochra and J. Sosnowska. Perspective of the audiovisual arts: On ways and tools of studying emotions in the current visuals.Roczniki Kulturoznawcze, 14(1):153–167, 2023
2023
-
[41]
E. Song, W. Chai, G. Wang, Y . Zhang, H. Zhou, F. Wu, X. Guo, T. Ye, Y . Lu, J.-N. Hwang, and G. Wang. Moviechat: From dense token to sparse memory for long video understanding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18221–18232, 2023. URL https://api.semanticscholar.org/CorpusID:260333927
2024
-
[42]
E. Song, W. Chai, W. Xu, J. Xie, Y . Liu, and G. Wang. Video-mmlu: A massive multi-discipline lecture understanding benchmark.2025 IEEE/CVF International Conference on Computer Vision Workshops (IC- CVW), pages 6158–6172, 2025. URLhttps://api.semanticscholar.org/CorpusID:277955206
2025
- [43]
-
[44]
X. Tan, Y . Luo, Y . Ye, F. Liu, and Z. Cai. Allvb: All-in-one long video understanding benchmark. InAAAI Conference on Artificial Intelligence, 2025. URL https://api.semanticscholar.org/CorpusID: 276928535
2025
-
[45]
X. Tang, J. Qiu, L. Xie, Y . Tian, J. Jiao, and Q. Ye. Adaptive keyframe sampling for long video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29118–29128, 2025
2025
- [46]
-
[47]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivière, M. S. Kale, J. Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
K. Team, T. Bai, Y . Bai, Y . Bao, S. Cai, Y . Cao, Y . Charles, H. Che, C. Chen, G. Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [50]
- [51]
-
[52]
W. Wang, Z. He, W. Hong, Y . Cheng, X. Zhang, J. Qi, M. Ding, X. Gu, S. Huang, B. Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025
2025
-
[53]
Z. Wang, J. Yoon, S. Yu, M. M. Islam, G. Bertasius, and M. Bansal. Video-rts: Rethinking reinforcement learning and test-time scaling for efficient and enhanced video reasoning. InConference on Empirical Meth- ods in Natural Language Processing, 2025. URL https://api.semanticscholar.org/CorpusID: 280149603
2025
- [54]
-
[55]
Grok 4.https://x.ai/news/grok-4, 2025
xAI. Grok 4.https://x.ai/news/grok-4, 2025
2025
-
[56]
J. Xiao, X. Shang, A. Yao, and T.-S. Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
2021
-
[57]
D. Xu, Z. Zhao, J. Xiao, F. Wu, H. Zhang, X. He, and Y . Zhuang. Video question answering via gradually refined attention over appearance and motion. InProceedings of the 25th ACM international conference on Multimedia, pages 1645–1653, 2017
2017
-
[58]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [59]
- [60]
-
[61]
LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling
Z. Yang, S. Wang, K. Zhang, K. Wu, S. Leng, Y . Zhang, B. Li, C. Qin, S. Lu, X. Li, et al. Longvt: Incentivizing" thinking with long videos" via native tool calling.arXiv preprint arXiv:2511.20785, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
T. Yu, Z. Wang, C. Wang, F. Huang, W. Ma, Z. He, T. Cai, W. Chen, Y . Huang, R. Zhao, et al. Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11704–11715, 2026
2026
-
[63]
Z. Yu, D. Xu, J. Yu, T. Yu, Z. Zhao, Y . Zhuang, and D. Tao. Activitynet-qa: A dataset for under- standing complex web videos via question answering.ArXiv, abs/1906.02467, 2019. URL https: //api.semanticscholar.org/CorpusID:69645185
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[64]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
B. Zhang, K. Li, Z. Cheng, Z. Hu, Y . Yuan, G. Chen, S. Leng, Y . Jiang, H. Zhang, X. Li, et al. Vide- ollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Zhang, J
S. Zhang, J. Yang, J. Yin, Z. Luo, and J. Luan. Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22056–22065, 2025
2025
-
[66]
Domain Expert
O. Zohar, X. Wang, Y . Dubois, N. Mehta, T. Xiao, P. Hansen-Estruch, L. Yu, X. Wang, F. Juefei-Xu, N. Zhang, et al. Apollo: An exploration of video understanding in large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18891–18901, 2025. 13 Appendices A Limitation and Future Work 15 B Benchmark Details 15 ...
2025
-
[67]
Cinematography. Shot size (long shot, extreme close-up), camera angle (Dutch angle, bird’s eye), movement (dolly zoom, tracking), lighting (high key, low key), composition (rule of thirds, leading lines)
-
[68]
Montage, long take, jump cut, parallel cut, flashback, transitions (match cut, smash cut), Kuleshov effect
Editing. Montage, long take, jump cut, parallel cut, flashback, transitions (match cut, smash cut), Kuleshov effect
-
[69]
Set and prop symbolism, blocking, costume
Mise-en-scène. Set and prop symbolism, blocking, costume
-
[70]
is_relevant
Sound design. Sound-to-image relation, diegetic vs. non-diegetic, sound bridge, ambient sound, silence. Examples may anchor on a director or auteur case. Figure 8: Keyword generation prompt for Cinematic Arts. The Static Visual, Stage Performing, and Game Arts variants share the same envelope, with the four numbered focal points replaced by the correspond...
2026
-
[71]
Analyze the frame sequence chronologically and interpret it as one coherent visual segment
-
[72]
Adjacent frames may look similar because they are continuous frames; do not misinterpret this as visual effects
-
[73]
If on-screen text appears, quote the original text and provide an English translation when needed, then explain its contextual meaning
-
[74]
Distinguish different people using concrete cues (clothing, position, posture, etc.)
-
[75]
clip_description
Provide rich visual detail covering color, shape, texture, motion traits, and scene background. Language. Theclip_descriptionvalue must be written in natural English only. Output. A single JSON object {"clip_description": "The clip starts with..., develops through..., and ends with..."}. At runtime the system prompt is concatenated with a category-specifi...
-
[76]
Each question must require understanding visual evidence in the video; transcript text alone should be insufficient
Video-dependent. Each question must require understanding visual evidence in the video; transcript text alone should be insufficient
-
[77]
Provide an accurate, professional, and well-reasoned correct answer
Generate the correct answer first. Provide an accurate, professional, and well-reasoned correct answer
-
[78]
Usebasic,intermediate, oradvanced
Difficulty labels. Usebasic,intermediate, oradvanced
-
[79]
Assign a sub-domain from the category’s controlled list
Sub-domain labels. Assign a sub-domain from the category’s controlled list
-
[80]
Question type. Approximately 30% of questions are multi_select (2 to 4 independent correct answer points returned in correct_answers); the rest aresingle_select(onecorrect_answer). Quantity. Generate 3 to 5 questions per video. Language. All textual fields must be in English only. Output. A single JSON object {"questions":[ ... ]} with each entry listing ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.