Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes
Pith reviewed 2026-06-30 06:08 UTC · model grok-4.3
The pith
Argus reconstructs metric 3D indoor scenes from sparse unordered panoramic images by anchoring to an optimal reference view and decomposing pixel-to-world mappings under joint constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
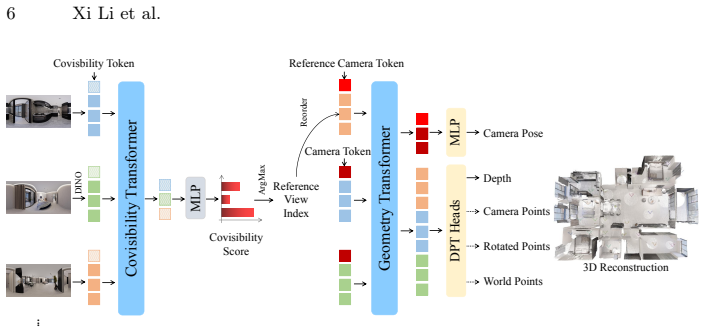
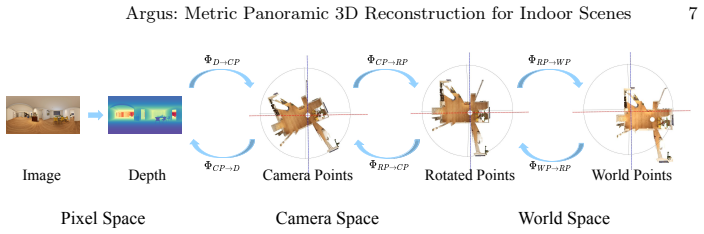
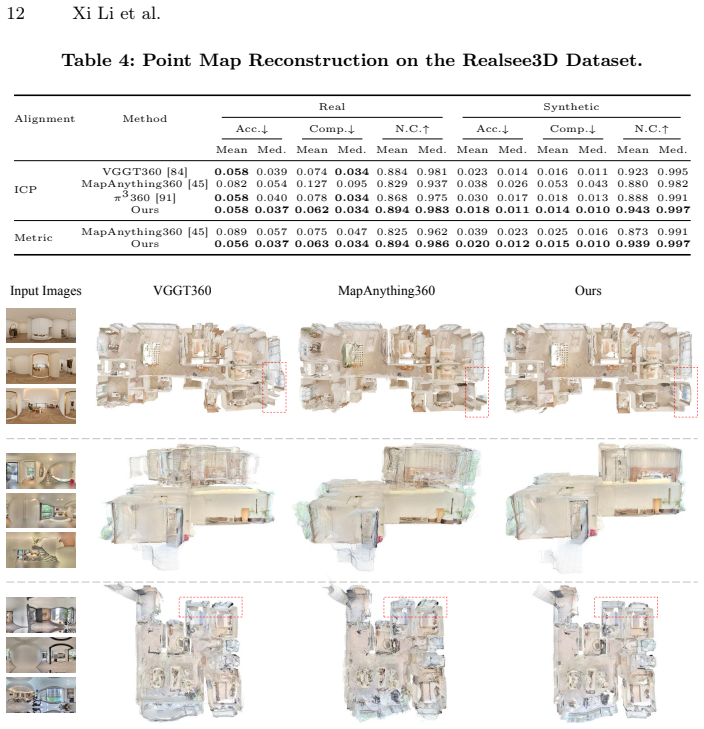
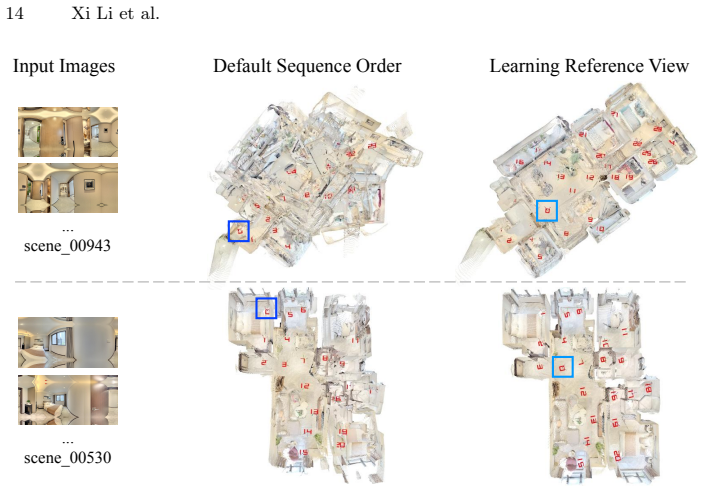
Argus is a feed-forward network for metric panoramic 3D reconstruction trained on the Realsee3D dataset. In the sparse unordered capture setting, a learned covisibility module selects the geometrically optimal reference view to anchor the metric world frame. The bidirectional pixel-to-world mapping is decomposed into interpretable sub-steps that receive per-step supervision and cross-coordinate joint constraints, reinforcing geometric consistency across prediction branches. On the Realsee3D benchmark, Argus achieves state-of-the-art metric performance in camera pose estimation, depth estimation, and point cloud reconstruction.
What carries the argument
The learned covisibility module that selects the geometrically optimal reference view to anchor the metric world frame, together with the decomposition of pixel-to-world mapping into per-step supervised sub-tasks under joint constraints.
If this is right
- Metric camera pose estimation becomes feasible for unordered panoramic sequences without external anchors.
- Depth maps and point clouds inherit improved global consistency from the shared coordinate constraints.
- Feed-forward inference replaces iterative optimization for reconstruction in the sparse panoramic regime.
- Multi-task training benefits from explicit geometric consistency across pose, depth, and reconstruction heads.
Where Pith is reading between the lines
- The covisibility selection mechanism could be tested on other sparse multi-view inputs such as smartphone photo bursts to check transfer beyond panoramas.
- The hybrid real-synthetic construction of Realsee3D points to a scalable route for obtaining metric ground truth when purely real labeled data remains limited.
- If the decomposed mapping generalizes, similar step-wise supervision might stabilize training for other geometric prediction tasks that mix 2D and 3D outputs.
Load-bearing premise
The Realsee3D dataset supplies precise metric annotations that are representative of real-world sparse unordered panoramic captures without systematic bias from its synthetic scenes.
What would settle it
Running Argus without retraining on a fresh collection of real panoramic sequences captured in indoor environments outside the Realsee3D distribution and measuring whether the reported gains in metric pose accuracy and depth error persist.
Figures







read the original abstract
Metric feed-forward 3D reconstruction for panoramic data remains under-explored due to the lack of large-scale panoramic RGB-D training data. We present Realsee3D, a hybrid dataset of 10K indoor scenes (1K real, 9K synthetic) with 299K panoramic viewpoints and precise metric annotations, and Argus, a feed-forward network trained on it for metric panoramic 3D reconstruction. In the sparse unordered capture setting of Realsee3D, a poorly chosen coordinate anchor can cause global pose drift. Argus addresses this with a learned covisibility module that selects the geometrically optimal reference view to anchor the metric world frame. To further improve multi-task learning, we decompose the bidirectional pixel-to-world mapping into interpretable sub-steps with per-step supervision and cross-coordinate joint constraints, reinforcing geometric consistency across prediction branches. On the Realsee3D benchmark, Argus achieves state-of-the-art metric performance in camera pose estimation, depth estimation, and point cloud reconstruction. Project page: https://argus-paper.realsee.ai.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Realsee3D, a hybrid dataset of 10K indoor scenes (9K synthetic + 1K real) containing 299K panoramic viewpoints with precise metric annotations, and proposes Argus, a feed-forward network for metric panoramic 3D reconstruction from sparse unordered captures. Argus uses a learned covisibility module to select an optimal reference view as coordinate anchor and decomposes the pixel-to-world mapping into supervised sub-steps with cross-coordinate constraints. The central claim is that Argus achieves state-of-the-art metric performance in camera pose estimation, depth estimation, and point cloud reconstruction on the Realsee3D benchmark.
Significance. If the empirical claims hold under independent real-only evaluation, the work would provide a useful large-scale hybrid dataset and a practical feed-forward approach to metric reconstruction from unordered panoramas, addressing the noted lack of training data and coordinate drift issues in this setting. The interpretable decomposition and per-step supervision could aid multi-task consistency, though the significance is tempered by the absence of quantitative numbers, error bars, or ablation details in the abstract.
major comments (2)
- [Dataset and Experiments sections] Dataset section (and benchmark evaluation): The Realsee3D dataset uses a 9:1 synthetic-to-real ratio. The SOTA claims for pose, depth, and reconstruction on the full benchmark are load-bearing for the paper's contribution, yet no real-only metrics, balanced test splits, or explicit comparison of synthetic vs. real performance are described. This leaves open whether gains exploit synthetic regularities (perfect geometry, calibration) rather than generalizing to real sparse captures with sensor noise and drift, directly undermining the claim of applicability to real-world unordered panoramic data.
- [Abstract and Experiments] Abstract and Experiments: The abstract states SOTA results without any quantitative numbers, error bars, ablation studies, or baseline comparisons. Without these details, it is impossible to assess whether the reported gains are robust or sensitive to post-hoc choices in the covisibility module or reference-view selection.
minor comments (1)
- [Abstract] The project page URL is given but no quantitative results or supplementary material links are referenced in the abstract; adding these would improve verifiability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of evaluation and presentation. We address each major point below and will revise the manuscript accordingly to strengthen the claims regarding real-world applicability and clarity of results.
read point-by-point responses
-
Referee: [Dataset and Experiments sections] Dataset section (and benchmark evaluation): The Realsee3D dataset uses a 9:1 synthetic-to-real ratio. The SOTA claims for pose, depth, and reconstruction on the full benchmark are load-bearing for the paper's contribution, yet no real-only metrics, balanced test splits, or explicit comparison of synthetic vs. real performance are described. This leaves open whether gains exploit synthetic regularities (perfect geometry, calibration) rather than generalizing to real sparse captures with sensor noise and drift, directly undermining the claim of applicability to real-world unordered panoramic data.
Authors: We agree that explicit real-only evaluation is necessary to substantiate generalization claims for real sparse captures. The hybrid design of Realsee3D prioritizes scale while incorporating 1K real scenes, but the current manuscript reports only aggregate benchmark results. In the revision, we will add a new subsection with real-only metrics on the 1K real scenes (including pose, depth, and reconstruction errors), balanced test splits separating synthetic and real, and direct synthetic-vs-real performance comparisons. This will clarify whether the covisibility module and decomposed supervision generalize beyond synthetic regularities. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments: The abstract states SOTA results without any quantitative numbers, error bars, ablation studies, or baseline comparisons. Without these details, it is impossible to assess whether the reported gains are robust or sensitive to post-hoc choices in the covisibility module or reference-view selection.
Authors: We acknowledge that the abstract's brevity makes it difficult to gauge the magnitude and robustness of the SOTA claims. While full quantitative results, error bars, and ablations appear in the Experiments section, we will revise the abstract to include key numerical results (e.g., relative improvements in camera pose error and depth accuracy on Realsee3D) and a brief note on the covisibility module's contribution. Full ablation tables and sensitivity analysis to reference-view selection will remain in the main text but will be cross-referenced more explicitly from the abstract. revision: yes
Circularity Check
No circularity: empirical SOTA claims on new benchmark are self-contained
full rationale
The paper introduces Realsee3D (hybrid synthetic/real dataset) and trains Argus on it, reporting direct empirical metrics for pose, depth, and reconstruction. No equations, predictions, or first-principles derivations are shown that reduce by construction to fitted parameters or self-citations; the covisibility module and per-step supervision are architectural choices evaluated externally on the benchmark splits. The central claims rest on held-out test performance rather than any self-referential loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICCV (2009)
Agarwal, S., Snavely, N., Simon, I., Seitz, S.M., Szeliski, R.: Building rome in a day. In: ICCV (2009)
2009
-
[2]
ai et al
Ai,H.,Cao,Z.,Wang,L.:Asurveyofrepresentationlearning,optimizationstrate- gies, and applications for omnidirectional vision: H. ai et al. IJCV133(8), 4973– 5012 (2025)
2025
-
[3]
In: IROS
Alama, O., Bhattacharya, A., He, H., Kim, S., Qiu, Y., Wang, W., Ho, C., Keetha, N., Scherer, S.: Rayfronts: Open-set semantic ray frontiers for online scene under- standing and exploration. In: IROS. pp. 5930–5937 (2025)
2025
-
[4]
In: ECCV
Antequera, M.L., Gargallo, P., Hofinger, M., Bulo, S.R., Kuang, Y., Kontschieder, P.: Mapillary planet-scale depth dataset. In: ECCV. pp. 589–604 (2020)
2020
-
[5]
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
Armeni,I.,Sax,S.,Zamir,A.R.,Savarese,S.:Joint2d-3d-semanticdataforindoor scene understanding. arXiv preprint arXiv:1702.01105 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
In: CVPR
Barath, D., Matas, J.: Graph-cut ransac. In: CVPR. pp. 6733–6741 (2018)
2018
-
[7]
In: Sensor fusion IV: control paradigms and data structures
Besl, P.J., McKay, N.D.: Method for registration of 3-d shapes. In: Sensor fusion IV: control paradigms and data structures. vol. 1611, pp. 586–606. Spie (1992)
1992
-
[8]
In: CVPR
Bian, J., Lin, W.Y., Matsushita, Y., Yeung, S.K., Nguyen, T.D., Cheng, M.M.: Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence. In: CVPR. pp. 4181–4190 (2017)
2017
-
[9]
Cabon, Y., Murray, N., Humenberger, M.: Virtual kitti 2. arXiv preprint arXiv:2001.10773 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
IEEE Transactions on Robotics (2021)
Campos, C., Elvira, R., Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: Orb- slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Transactions on Robotics (2021)
2021
-
[11]
In: CVPR (2025)
Cao, Z., Zhu, J., Zhang, W., Ai, H., Bai, H., Zhao, H., Wang, L.: Panda: To- wards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation. In: CVPR (2025)
2025
-
[12]
In: 3DV (2017)
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niebner, M., Savva, M., Song, S., Zeng, A., Zhang, Y.: Matterport3d: Learning from rgb-d data in indoor envi- ronments. In: 3DV (2017)
2017
-
[13]
TTT3R: 3D Reconstruction as Test-Time Training
Chen, X., Chen, Y., Xiu, Y., Geiger, A., Chen, A.: Ttt3r: 3d reconstruction as test-time training. arXiv preprint arXiv:2509.26645 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: CVPR
Cruz, S., Hutchcroft, W., Li, Y., Khosravan, N., Boyadzhiev, I., Kang, S.B.: Zil- low indoor dataset: Annotated floor plans with 360deg panoramas and 3d room layouts. In: CVPR. pp. 2133–2143 (2021)
2021
-
[15]
In: CVPR (2017)
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scan- net: Richly-annotated 3d reconstructions of indoor scenes. In: CVPR (2017)
2017
-
[16]
ToG36(4), 1 (2017)
Dai, A., Nießner, M., Zollhöfer, M., Izadi, S., Theobalt, C.: Bundlefusion: Real- time globally consistent 3d reconstruction using on-the-fly surface reintegration. ToG36(4), 1 (2017)
2017
-
[17]
In: NeurIPS (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. In: NeurIPS (2022)
2022
-
[18]
Vision Transformers Need Registers
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. arXiv preprint arXiv:2309.16588 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
In: CVPR
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: CVPR. pp. 13142–13153 (2023)
2023
-
[20]
Deng, J., Li, H., Xie, T., Ren, W., Zhang, Q., Tan, P., Guo, X.: Sail-recon: Large sfm by augmenting scene regression with localization. arXiv preprint arXiv:2508.17972 (2025) Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes 17
-
[21]
In: CVPRW (2018)
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: CVPRW (2018)
2018
-
[22]
Numerische Math- ematik1(1), 269–271 (1959)
Dijkstra, E.: A note on two problems in connexion with graphs. Numerische Math- ematik1(1), 269–271 (1959)
1959
-
[23]
In: 2025 International Conference on 3D Vision (3DV)
Duisterhof, B.P., Zust, L., Weinzaepfel, P., Leroy, V., Cabon, Y., Revaud, J.: Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In: 2025 International Conference on 3D Vision (3DV). pp. 1–10 (2025)
2025
-
[24]
In: CVPR (2023)
Edstedt,J.,Athanasiadis,I.,Wadenbäck,M.,Felsberg,M.:Dkm:Densekernelized feature matching for geometry estimation. In: CVPR (2023)
2023
-
[25]
In: CVPR (2024)
Edstedt, J., Sun, Q., Bökman, G., Wadenbäck, M., Felsberg, M.: Roma: Robust dense feature matching. In: CVPR (2024)
2024
-
[26]
Fei, X., Zheng, W., Duan, Y., Zhan, W., Tomizuka, M., Keutzer, K., Lu, J.: Driv3r: Learning dense 4d reconstruction for autonomous driving. arXiv preprint arXiv:2412.06777 (2024)
-
[27]
arXiv preprint arXiv:2509.21302 (2025)
Feng, W., Qin, H., Wu, M., Yang, C., Li, Y., Li, X., An, Z., Huang, L., Zhang, Y., Magno, M., et al.: Quantized visual geometry grounded transformer. arXiv preprint arXiv:2509.21302 (2025)
-
[28]
Foundations and Trends in Computer Graphics and Vision9(1-2), 1–148 (2015)
Furukawa, Y., Hernández, C.: Multi-view stereo: A tutorial. Foundations and Trends in Computer Graphics and Vision9(1-2), 1–148 (2015)
2015
-
[29]
2402–2409 (2006)
Goesele,M.,Curless,B.,Seitz,S.M.:Multi-viewstereorevisited.In:CVPR.vol.2, pp. 2402–2409 (2006)
2006
-
[30]
In: CVPR
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., et al.: Kubric: A scalable dataset generator. In: CVPR. pp. 3749–3761 (2022)
2022
-
[31]
In: CVPR (2025)
Guo, Y., Garg, S., Miangoleh, S.M.H., Huang, X., Ren, L.: Depth any camera: Zero-shot metric depth estimation from any camera. In: CVPR (2025)
2025
-
[32]
Hartley,R.,Zisserman,A.:Multipleviewgeometryincomputervision.Cambridge university press (2003)
2003
-
[33]
In: CVPR (2021)
Hausler, S., Garg, S., Xu, M., Milford, M., Fischer, T.: Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition. In: CVPR (2021)
2021
-
[34]
In: CVPR (2024)
He, X., Sun, J., Wang, Y., Peng, S., Huang, Q., Bao, H., Zhou, X.: Detector-free structure from motion. In: CVPR (2024)
2024
-
[35]
arXiv preprint arXiv:2312.08782 (2023)
Hu, Y., Xie, Q., Jain, V., Francis, J., Patrikar, J., Keetha, N., Kim, S., Xie, Y., Zhang, T., Fang, H.S., et al.: Toward general-purpose robots via foundation models: A survey and meta-analysis. arXiv preprint arXiv:2312.08782 (2023)
-
[36]
In: CVPR
Huang, P.H., Matzen, K., Kopf, J., Ahuja, N., Huang, J.B.: Deepmvs: Learning multi-view stereopsis. In: CVPR. pp. 2821–2830 (2018)
2018
-
[37]
In: CVPR
Jang, W., Weinzaepfel, P., Leroy, V., Agapito, L., Revaud, J.: Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors. In: CVPR. pp. 1071–1081 (2025)
2025
-
[38]
arXiv preprint arXiv:2512.22819 (2025)
Jiang, H., Song, Z., Lou, Z., Xu, R., Tan, M.: Depth anything in360circ: Towards scale invariance in the wild. arXiv preprint arXiv:2512.22819 (2025)
-
[39]
TOG44(6), 1–16 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. TOG44(6), 1–16 (2025)
2025
-
[40]
In: ACM SIGGRAPH (2024)
Jiang, Y., Yu, C., Xie, T., Li, X., Feng, Y., Wang, H., Li, M., Lau, H., Gao, F., Yang, Y., Jiang, C.: Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality. In: ACM SIGGRAPH (2024)
2024
-
[41]
In: ICCV (2025) 18 Xi Li et al
Jung, D., Choi, J., Lee, Y., Manocha, D.: Im360: Large-scale indoor mapping with 360 cameras. In: ICCV (2025) 18 Xi Li et al
2025
-
[42]
In: ICCV
Karaev, N., Makarov, Y., Wang, J., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In: ICCV. pp. 6013–6022 (2025)
2025
-
[43]
In: ECCV
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker: It is better to track together. In: ECCV. pp. 18–35 (2024)
2024
-
[44]
In: CVPR
Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J.: Splatam: Splat track & map 3d gaussians for dense rgb-d slam. In: CVPR. pp. 21357–21366 (2024)
2024
-
[45]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Mapanything: Universal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
TOG (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. TOG (2023)
2023
-
[47]
In: NeurIPS
Kümmerle, C., Verdun, C.M., Stöger, D.: Iteratively reweighted least squares for basis pursuit with global linear convergence rate. In: NeurIPS. pp. 2873–2886 (2021)
2021
-
[48]
arXiv preprint arXiv:2509.26618 (2025)
Li, H., Zheng, W., He, J., Liu, Y., Lin, X., Yang, X., Chen, Y.C., Guo, C.: Da2: Depth anything in any direction. arXiv preprint arXiv:2509.26618 (2025)
-
[49]
In: ECCV
Li, X.: Multi-view canonical pose 3d human body reconstruction based on volu- metric tsdf. In: ECCV. pp. 392–397 (2022)
2022
-
[50]
In: ICCV
Li, X., Rao, T., Pan, C.: Edm: Efficient deep feature matching. In: ICCV. pp. 26198–26208 (2025)
2025
-
[51]
In: CVPR (2018)
Li, Z., Snavely, N.: Megadepth: Learning single-view depth prediction from inter- net photos. In: CVPR (2018)
2018
-
[52]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
arXiv preprint arXiv:2512.16913 (2025)
Lin, X., Song, M., Zhang, D., Lu, W., Li, H., Du, B., Yang, M.H., Nguyen, T., Qi, L.: Depth any panoramas: A foundation model for panoramic depth estimation. arXiv preprint arXiv:2512.16913 (2025)
-
[54]
In: ICCV (2023)
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Lightglue: Local feature matching at light speed. In: ICCV (2023)
2023
-
[55]
In: CVPR
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: CVPR. pp. 22160–22169 (2024)
2024
-
[56]
arXiv preprint arXiv:2510.10726 (2025)
Liu, Y., Min, Z., Wang, Z., Wu, J., Wang, T., Yuan, Y., Luo, Y., Guo, C.: Worldmirror: Universal 3d world reconstruction with any-prior prompting. arXiv preprint arXiv:2510.10726 (2025)
-
[57]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
IJCV (2004)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. IJCV (2004)
2004
-
[59]
In: ICCV
Ma, X., Wang, Z., Li, H., Zhang, P., Ouyang, W., Fan, X.: Accurate monocular 3d object detection via color-embedded 3d reconstruction for autonomous driving. In: ICCV. pp. 6851–6860 (2019)
2019
-
[60]
Com- munications of the ACM65(1), 99–106 (2021) Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes 19
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Com- munications of the ACM65(1), 99–106 (2021) Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes 19
2021
-
[61]
In: International Workshop on Reproducible Research in Pattern Recog- nition
Moulon,P.,Monasse,P.,Perrot,R.,Marlet,R.: Openmvg: Openmultipleviewge- ometry. In: International Workshop on Reproducible Research in Pattern Recog- nition. pp. 60–74. Springer (2016)
2016
-
[62]
IEEE Transactions on Robotics (2015)
Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: Orb-slam: a versatile and accurate monocular slam system. IEEE Transactions on Robotics (2015)
2015
-
[63]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,etal.:Dinov2:Learningrobust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
In: ICCV
Pan, X., Charron, N., Yang, Y., Peters, S., Whelan, T., Kong, C., Parkhi, O., Newcombe, R., Ren, Y.C.: Aria digital twin: A new benchmark dataset for ego- centric 3d machine perception. In: ICCV. pp. 20133–20143 (2023)
2023
-
[65]
In: CVPR (2025)
Piccinelli, L., Sakaridis, C., Segu, M., Yang, Y.H., Li, S., Abbeloos, W., Van Gool, L.: Unik3d: Universal camera monocular 3d estimation. In: CVPR (2025)
2025
-
[66]
In: ICCV (2021)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: ICCV (2021)
2021
-
[67]
In: ICCV
Reizenstein, J., Shapovalov, R., Henzler, P., Sbordone, L., Labatut, P., Novotny, D.: Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In: ICCV. pp. 10901–10911 (2021)
2021
-
[68]
In: ICCV
Roberts, M., Ramapuram, J., Ranjan, A., Kumar, A., Bautista, M.A., Paczan, N., Webb, R., Susskind, J.M.: Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In: ICCV. pp. 10912–10922 (2021)
2021
-
[69]
In: ICCV (2011)
Rublee, E., Rabaud, V., Konolige, K., Bradski, G.: Orb: An efficient alternative to sift or surf. In: ICCV (2011)
2011
-
[70]
In: CVPR (2020)
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: CVPR (2020)
2020
-
[71]
In: CVPR (2016)
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR (2016)
2016
-
[72]
In: ECCV
Schönberger, J.L., Zheng, E., Frahm, J.M., Pollefeys, M.: Pixelwise view selection for unstructured multi-view stereo. In: ECCV. pp. 501–518 (2016)
2016
-
[73]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation. arXiv preprint arXiv:2509.20427 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
In: CVPR
Seitz, S.M., Curless, B., Diebel, J., Scharstein, D., Szeliski, R.: A comparison and evaluation of multi-view stereo reconstruction algorithms. In: CVPR. vol. 1, pp. 519–528 (2006)
2006
-
[75]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
Shen, Y., Zhang, Z., Qu, Y., Cao, L.: Fastvggt: Training-free acceleration of visual geometry transformer. arXiv preprint arXiv:2509.02560 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[77]
In: CVPR (2021)
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: Loftr: Detector-free local feature matching with transformers. In: CVPR (2021)
2021
-
[78]
In: CVPR
Sun, W., Jiang, W., Trulls, E., Tagliasacchi, A., Yi, K.M.: Acne: Attentive context normalization for robust permutation-equivariant learning. In: CVPR. pp. 11286– 11295 (2020)
2020
-
[79]
NeurIPS34, 251–266 (2021)
Szot, A., Clegg, A., Undersander, E., Wijmans, E., Zhao, Y., Turner, J., Maestre, N., Mukadam, M., Chaplot, D.S., Maksymets, O., et al.: Habitat 2.0: Training home assistants to rearrange their habitat. NeurIPS34, 251–266 (2021)
2021
-
[80]
In: CVPR (2018) 20 Xi Li et al
Taira, H., Okutomi, M., Sattler, T., Cimpoi, M., Pollefeys, M., Sivic, J., Pajdla, T., Torii, A.: Inloc: Indoor visual localization with dense matching and view synthesis. In: CVPR (2018) 20 Xi Li et al
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.