SHOVIR: A Benchmark for Evaluating Vision Shortcut Learning in Radiology Report Generation
Pith reviewed 2026-06-30 06:20 UTC · model grok-4.3
The pith
A benchmark using occlusion tests shows radiology report models can generate fluent text while ignoring the image regions for the described pathologies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
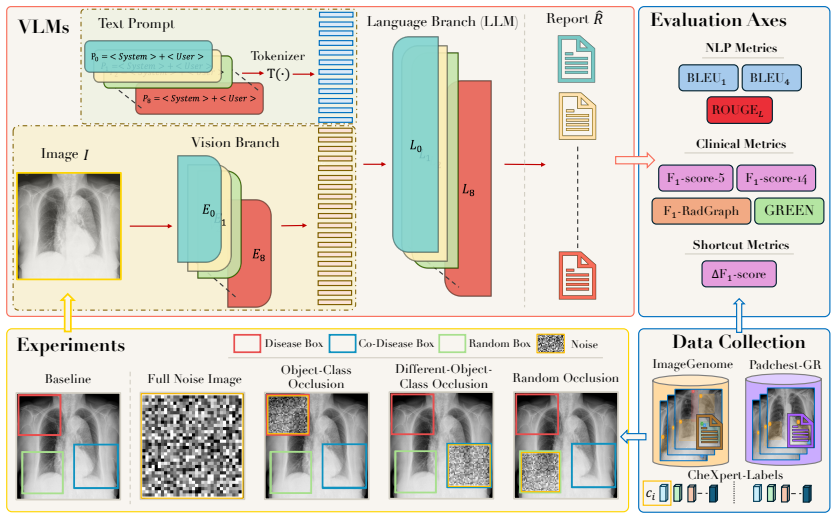
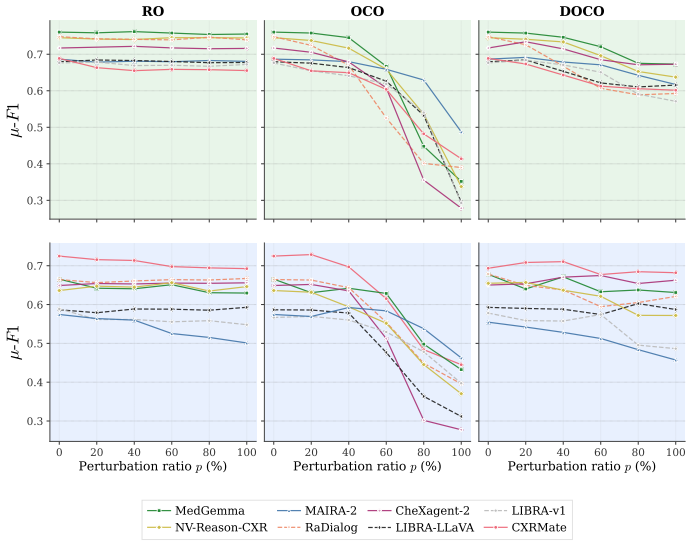
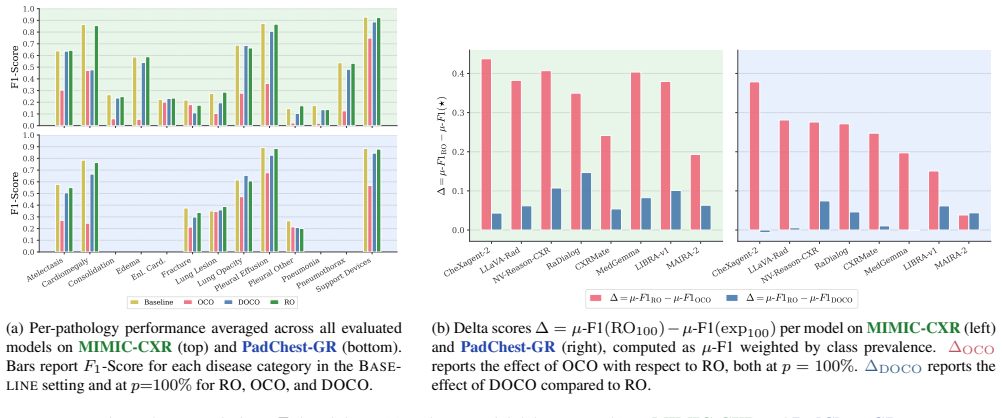
SHOVIR isolates two failure modes at the disease-class level through image-level and disease-level occlusion on spatially annotated datasets: direct shortcuts, where a finding persists after its visual evidence is removed, and contextual shortcuts, where detection degrades once co-occurring pathologies are occluded despite the target region remaining intact. Benchmarking eight state-of-the-art VLMs shows shortcut behavior varies substantially across architectures and datasets, with models achieving highest baseline report quality not necessarily ranking highest in spatial grounding.
What carries the argument
SHOVIR benchmark with per-box CheXpert labels enabling occlusion experiments that contrast baseline performance against localized region-specific perturbations.
If this is right
- Current report-level metrics alone cannot confirm that diagnostic statements derive from visible image evidence.
- Clinically fluent generation can coexist with shallow reliance on visual evidence.
- Shortcut behavior differs enough across models that architecture choice affects spatial grounding reliability.
- Region-aware assessment protocols become necessary to close the blind spot in RRG evaluation.
Where Pith is reading between the lines
- Similar occlusion-based tests could be adapted to other vision-language medical tasks beyond chest X-rays.
- Training methods that penalize persistence after targeted occlusion might reduce shortcut reliance.
- Deployment pipelines may need to incorporate spatial verification steps before accepting generated reports.
Load-bearing premise
The per-box CheXpert labels accurately mark the precise image regions containing each pathology so that occluding a box removes exactly the visual evidence without creating artifacts or affecting unrelated regions.
What would settle it
Running the occlusion experiments and finding that model predictions for a finding remain unchanged even when its annotated box is removed, or change due to occlusion artifacts rather than evidence removal.
Figures
read the original abstract
Current evaluation protocols for Vision-Language Models (VLMs) in Radiology Report Generation (RRG) rely on report-level metrics that measure lexical overlap or aggregate clinical correctness. However, such metrics do not test whether individual diagnostic statements stem from the actual pathological evidence visible in the image. This allows models to achieve competitive scores by exploiting learned priors or spurious correlations, a failure mode we refer to as vision shortcut. We introduce SHOVIR, a benchmark for evaluating vision shortcut behavior in RRG. SHOVIR extends two spatially annotated chest X-ray datasets, MIMIC-CXR and PadChest-GR, with per-box CheXpert labels, and defines image-level and disease-level occlusion experiments that contrast baseline performance on clean images against localized, region-specific perturbations. Comparing predictions across these conditions isolates two failure modes at the disease-class level: direct shortcuts, where a finding persists after its visual evidence is removed, and contextual shortcuts, where detection degrades once co-occurring pathologies are occluded despite the target region remaining intact. Benchmarking eight state-of-the-art VLMs, we find that shortcut behavior varies substantially across architectures and datasets. Models achieving the highest baseline report quality do not necessarily rank highest in spatial grounding, revealing that clinically fluent generation can coexist with shallow reliance on visual evidence. These findings expose a blind spot in current RRG evaluation and motivate region-aware assessment protocols.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SHOVIR, a benchmark for vision shortcut learning in radiology report generation. It augments the spatially annotated MIMIC-CXR and PadChest-GR datasets with per-box CheXpert labels and defines image-level and disease-level occlusion experiments. These contrast baseline performance against localized perturbations to isolate direct shortcuts (findings persist after their visual evidence is occluded) and contextual shortcuts (detection of a target finding degrades when co-occurring pathologies are occluded). Benchmarking eight state-of-the-art VLMs shows substantial variation in shortcut behavior across architectures and datasets, with models achieving highest baseline report quality not necessarily ranking highest in spatial grounding.
Significance. If the occlusion experiments validly isolate visual evidence, the work identifies a clear limitation in existing RRG evaluation protocols that rely on report-level lexical or clinical metrics without testing visual grounding. The empirical comparisons across models and datasets provide concrete evidence that clinically fluent generation can coexist with shallow visual reliance. The benchmark construction is parameter-free and falsifiable via the defined occlusion conditions, which are strengths. However, the central findings rest on an unvalidated assumption about label precision, limiting immediate impact until addressed.
major comments (3)
- [Abstract and dataset extension] Abstract and dataset extension description: the central claim that occlusion experiments isolate direct vs. contextual shortcuts requires that per-box CheXpert labels accurately mark the precise image regions containing each pathology so that occluding a box removes exactly the visual evidence without artifacts or spillover. The manuscript provides no independent validation, inter-annotator agreement, or precision metrics for these added labels, so persistence or degradation after occlusion could reflect annotation error rather than model behavior.
- [Occlusion experiments] Occlusion experiments section: the methods do not specify data exclusion rules, occlusion implementation details, or controls for unintended visual changes to co-occurring findings. Without these, it is not possible to confirm that the experiments cleanly separate the two shortcut types, directly undermining the disease-class level distinctions reported in the results.
- [Results] Results section: the claim of 'substantial variation' across architectures and datasets is presented without statistical tests (e.g., significance of rank differences or correlation between baseline quality and grounding scores). This weakens the cross-model comparison that high report quality does not imply spatial grounding.
minor comments (2)
- [Introduction] The terms 'direct shortcut' and 'contextual shortcut' are introduced without a formal definition or pseudocode for how they are computed from the occlusion outcomes; a small clarifying paragraph or algorithm box would improve reproducibility.
- [Figures] Figure captions for the occlusion examples should explicitly state the exact CheXpert label and bounding box used for each perturbation to allow readers to assess visual isolation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and indicate the revisions we will make to improve the clarity and rigor of the work.
read point-by-point responses
-
Referee: [Abstract and dataset extension] Abstract and dataset extension description: the central claim that occlusion experiments isolate direct vs. contextual shortcuts requires that per-box CheXpert labels accurately mark the precise image regions containing each pathology so that occluding a box removes exactly the visual evidence without artifacts or spillover. The manuscript provides no independent validation, inter-annotator agreement, or precision metrics for these added labels, so persistence or degradation after occlusion could reflect annotation error rather than model behavior.
Authors: We agree that the precision of the per-box labels is critical to the validity of the occlusion experiments. The labels were obtained by applying the CheXpert labeler to the image regions defined by the bounding boxes from the original datasets. While CheXpert has been extensively validated in prior work for full-image labeling, its application to cropped regions has not been independently validated here. This is a valid concern. In the revised manuscript, we will expand the dataset extension section to detail the labeling procedure, include any available metrics from CheXpert's original validation that may apply, and add a dedicated limitations section discussing the assumption of label accuracy and its potential impact on results. We will also consider releasing the per-box labels for community validation. revision: yes
-
Referee: [Occlusion experiments] Occlusion experiments section: the methods do not specify data exclusion rules, occlusion implementation details, or controls for unintended visual changes to co-occurring findings. Without these, it is not possible to confirm that the experiments cleanly separate the two shortcut types, directly undermining the disease-class level distinctions reported in the results.
Authors: We appreciate this point on methodological transparency. The original manuscript describes the occlusion as region-specific perturbations using the bounding boxes, but we acknowledge that details on data exclusion (e.g., cases where boxes overlap or multiple findings in one box), exact occlusion method (e.g., blacking out, blurring), and controls for spillover effects are insufficiently specified. In the revision, we will add a subsection detailing these aspects: exclusion criteria for ambiguous cases, the precise occlusion technique used (with parameters), and any post-occlusion checks or controls implemented to ensure co-occurring findings are not inadvertently affected. This will allow readers to better assess the separation of shortcut types. revision: yes
-
Referee: [Results] Results section: the claim of 'substantial variation' across architectures and datasets is presented without statistical tests (e.g., significance of rank differences or correlation between baseline quality and grounding scores). This weakens the cross-model comparison that high report quality does not imply spatial grounding.
Authors: The results present numerical comparisons across models showing variation in shortcut behavior and that top baseline performers do not always lead in grounding metrics. While the differences are evident from the reported scores, we agree that formal statistical tests would strengthen the claims. In the revised version, we will include appropriate statistical analyses, such as paired t-tests or Wilcoxon tests for rank differences where applicable, and compute correlations with significance levels between baseline quality and grounding scores. This will provide quantitative support for the observed variations. revision: yes
Circularity Check
Empirical benchmark construction with no derivations or fitted parameters
full rationale
The paper introduces SHOVIR as an empirical benchmark that extends existing datasets (MIMIC-CXR, PadChest-GR) with per-box CheXpert labels and runs occlusion experiments to compare VLM outputs before/after perturbations. No equations, parameter fitting, or derivation chains appear; findings are direct comparisons of model behavior across conditions. No self-citation load-bearing steps or reductions by construction are present. The analysis is self-contained against external model evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-box CheXpert labels accurately identify the image regions containing each pathology
invented entities (2)
-
direct shortcut
no independent evidence
-
contextual shortcut
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Don’t just assume; look and answer: Over- coming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Anirud- dha Kembhavi. Don’t just assume; look and answer: Over- coming priors for visual question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 4971–4980, 2018. 2
2018
-
[2]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai et al. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Maira-2: Grounded radiology report generation
Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Anja Thieme, et al. Maira-2: Grounded radi- ology report generation.arXiv preprint arXiv:2406.04449,
-
[4]
Detecting shortcut learning for fair medical ai using shortcut testing
Alexander Brown, Natasa Tomasev, Jan Freyberg, Yuan Liu, Alan Karthikesalingam, and Jessica Schrouff. Detecting shortcut learning for fair medical ai using shortcut testing. Nature Communications, 14(1):4314, 2023. 2
2023
-
[5]
To- wards a clinically accessible radiology foundation model: Open-access and lightweight, with automated evaluation
Jo ˜ao Maria Janeiro Chaves, Louis Blankemeier, et al. To- wards a clinically accessible radiology foundation model: Open-access and lightweight, with automated evaluation. Nature Communications, 16(1):3206, 2025. 1, 2, 5
2025
-
[6]
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, and Lihua Zhang. Detecting and evaluating medical hallu- cinations in large vision language models.arXiv preprint arXiv:2406.10185, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Generating radiology reports via memory-driven trans- former
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven trans- former. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1439–1449, 2020. 2
2020
-
[8]
Chexagent: Towards a foun- dation model for chest x-ray interpretation
Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Mag- dalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, et al. Chexagent: Towards a foun- dation model for chest x-ray interpretation. InAAAI 2024 Spring Symposium on Clinical Foundation Models, 2024. 1, 2, 5
2024
-
[9]
Chimera: Diag- nosing shortcut learning in visual-language understanding
Ziheng Chi, Yifan Hou, Chenxi Pang, Shaobo Cui, Mubashara Akhtar, and Mrinmaya Sachan. Chimera: Diag- nosing shortcut learning in visual-language understanding. arXiv preprint arXiv:2509.22437, 2025. 1, 2
-
[10]
Padchest-gr: A bilingual chest x-ray dataset for grounded radiology report generation.NEJM AI, 2(7):AIdbp2401120,
Daniel Coelho de Castro, Aurelia Bustos, Shruthi Ban- nur, Stephanie L Hyland, Kenza Bouzid, Maria Teodora Wetscherek, Maria Dolores S´anchez-Valverde, Lara Jaques- P´erez, Lourdes P ´erez-Rodr´ıguez, Kenji Takeda, et al. Padchest-gr: A bilingual chest x-ray dataset for grounded radiology report generation.NEJM AI, 2(7):AIdbp2401120,
-
[11]
Ai for radiographic COVID-19 detection selects shortcuts over sig- nal.Nature Machine Intelligence, 3(7):610–619, 2021
Alex J DeGrave, Joseph D Janizek, and Su-In Lee. Ai for radiographic COVID-19 detection selects shortcuts over sig- nal.Nature Machine Intelligence, 3(7):610–619, 2021. 2
2021
-
[12]
Nicolas Deperrois, Hidetoshi Matsuo, Samuel Ruip ´erez- Campillo, Moritz Vandenhirtz, Sonia Laguna, Alain Ryser, Koji Fujimoto, Mizuho Nishio, Thomas M Sutter, Ju- lia E V ogt, et al. Radvlm: a multitask conversa- tional vision-language model for radiology.arXiv preprint arXiv:2502.03333, 2025. 8
-
[13]
Shortcut learning in deep neural networks
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 1, 2
2020
-
[14]
shortcuts
Judy Wawira Gichoya, Kaesha Thomas, Nabile Gichoya, et al. “shortcuts” causing bias in radiology artificial intel- ligence: Causes, evaluation, and mitigation.Journal of the American College of Radiology, 20(11):1060–1068, 2023. 2
2023
-
[15]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 6325– 6334, 2017. 2
2017
-
[16]
Medvh: Toward systematic evaluation of hal- lucination for large vision language models in the medical context.Advanced Intelligent Systems, page 2500255, 2025
Zishan Gu, Jiayuan Chen, Fenglin Liu, Changchang Yin, and Ping Zhang. Medvh: Toward systematic evaluation of hal- lucination for large vision language models in the medical context.Advanced Intelligent Systems, page 2500255, 2025. 1, 2
2025
-
[17]
The origins and prevalence of texture bias in convolutional neural networks.Advances in neural information processing sys- tems, 33:19000–19015, 2020
Katherine Hermann, Ting Chen, and Simon Kornblith. The origins and prevalence of texture bias in convolutional neural networks.Advances in neural information processing sys- tems, 33:19000–19015, 2020. 2
2020
-
[18]
A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems, 43(2):1–55, 2025. 2
2025
-
[19]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Sil- viana Ciurea-Ilcus, Chris Chute, Henrik Marklund, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceedings of the AAAI Conference on Artificial Intelligence, pages 590–597, 2019. 3, 8
2019
-
[20]
Radgraph: Extracting clinical entities and relations from radiology reports.Advances in Neural Information Pro- cessing Systems, 34, 2021
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven QH Truong, Du Nguyen Duber, Tristan Bui, Pierre Chambon, et al. Radgraph: Extracting clinical entities and relations from radiology reports.Advances in Neural Information Pro- cessing Systems, 34, 2021. 1, 2, 5
2021
-
[21]
Detecting shortcuts in medical images – a case study in chest x-rays
Amelia Jim ´enez-S´anchez, Dovile Juodelyte, Bethany Cham- berlain, and Bernhard Kainz. Detecting shortcuts in medical images – a case study in chest x-rays. InIEEE International 9 Symposium on Biomedical Imaging (ISBI), pages 1–5, 2023. 2
2023
-
[22]
On the automatic generation of medical imaging reports
Baoyu Jing, Pengtao Xie, and Eric Xing. On the automatic generation of medical imaging reports. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), pages 2577–2586, 2018. 2
2018
-
[23]
Mimic- cxr-jpg-chest radiographs with structured labels.PhysioNet, 101(215-220):1, 2019
Alistair Johnson, Matt Lungren, Yifan Peng, Zhiyong Lu, Roger Mark, Seth Berkowitz, and Steven Horng. Mimic- cxr-jpg-chest radiographs with structured labels.PhysioNet, 101(215-220):1, 2019. 3
2019
-
[24]
Vlind-bench: Measuring language priors in large vision- language models
Kang-il Lee, Minbeom Kim, Seunghyun Yoon, Minsung Kim, Dongryeol Lee, Hyukhun Koh, and Kyomin Jung. Vlind-bench: Measuring language priors in large vision- language models. InFindings of the Association for Compu- tational Linguistics: NAACL 2025, pages 4129–4144, 2025. 1, 2
2025
-
[25]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36, 2024
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36, 2024. 2
2024
-
[26]
A whac-a-mole dilemma: Shortcuts come in multiples where mitigating one amplifies others
Zhiheng Li, Ivan Evtimov, Albert Gordo, Caner Hazirbas, Tal Hassner, Cristian Canton Ferrer, Chenliang Xu, and Mark Ibrahim. A whac-a-mole dilemma: Shortcuts come in multiples where mitigating one amplifies others. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20071–20082, 2023. 2
2023
-
[27]
A survey of state of the art large vision language models: Benchmark evaluations and challenges
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. A survey of state of the art large vision language models: Benchmark evaluations and challenges. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 1587–1606, 2025. 1
2025
-
[28]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, 2004. 1, 2, 5
2004
-
[29]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiu- tian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
The effects of changes in utilization and technological advancements of cross-sectional imaging on radiologist workload.Academic radiology, 22(9):1191–1198, 2015
Robert J McDonald, Kara M Schwartz, Laurence J Eckel, Felix E Diehn, Christopher H Hunt, Brian J Bartholmai, Bradley J Erickson, and David F Kallmes. The effects of changes in utilization and technological advancements of cross-sectional imaging on radiologist workload.Academic radiology, 22(9):1191–1198, 2015. 1
2015
-
[31]
Reasoning vi- sual language model for chest x-ray analysis.arXiv preprint arXiv:2510.23968, 2025
Andriy Myronenko, Dong Yang, Baris Turkbey, Mariam Aboian, Sena Azamat, Esra Akcicek, Hongxu Yin, Pavlo Molchanov, Marc Edgar, Yufan He, et al. Reasoning vi- sual language model for chest x-ray analysis.arXiv preprint arXiv:2510.23968, 2025. 5
-
[32]
Localizing before answering: A benchmark for grounded medical visual ques- tion answering
Dung Nguyen, Minh Khoi Ho, Huy Ta, Thanh Tam Nguyen, Qi Chen, Kumar Rav, Quy Duong Dang, Satwik Ramchan- dre, Son Lam Phung, Zhibin Liao, et al. Localizing before answering: A benchmark for grounded medical visual ques- tion answering. InThirty-Fourth International Joint Confer- ence on Artificial Intelligence (IJCAI-25). International Joint Conferences o...
2025
-
[33]
e-health csiro at rrg24: entropy-augmented self-critical sequence training for radiol- ogy report generation
Aaron Nicolson, Jinghui Liu, Jason Dowling, Anthony Nguyen, and Bevan Koopman. e-health csiro at rrg24: entropy-augmented self-critical sequence training for radiol- ogy report generation. InProceedings of the 23rd workshop on biomedical natural language processing, pages 99–104,
-
[34]
The impact of auxiliary patient data on auto- mated chest x-ray report generation and how to incorporate it
Aaron Nicolson, Shengyao Zhuang, Jason Dowling, and Be- van Koopman. The impact of auxiliary patient data on auto- mated chest x-ray report generation and how to incorporate it. InProceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 177–203, 2025. 2, 6
2025
-
[35]
Luke Oakden-Rayner, Jared Dunnmon, Gustavo Carneiro, and Christopher R ´e. Hidden stratification causes clinically meaningful failures in machine learning for medical imag- ing.Proceedings of the ACM Conference on Health, Infer- ence, and Learning, pages 151–159, 2020. 2
2020
-
[36]
Green: Generative radiology re- port evaluation and error notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Bluethgen, Arne Ed- ward Michalson Md, Michael Moseley, Curtis Langlotz, Ak- shay S Chaudhari, et al. Green: Generative radiology re- port evaluation and error notation. InFindings of the asso- ciation for computational linguistics: EMNLP 2024, pages 374–390, 2024. 1, 2, 5
2024
-
[37]
Bleu: A method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: A method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 311–318, 2002. 1, 2, 5
2002
-
[38]
Chantal Pellegrini, Matthias Keicher, Ege Oezsoy, and Nas- sir Navab. Radialog: A large vision-language model for radi- ology report generation and conversational assistance.arXiv preprint arXiv:2311.18681, 2023. 2, 5
-
[39]
Am ´elie Royer et al. Medhalltune: An instruction-tuning benchmark for mitigating medical hallucination in vision- language models.arXiv preprint arXiv:2502.09996, 2025. 1, 2
-
[40]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroen- sri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C ´ıan Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Y Ng, and Matthew P Lungren. Chexbert: Com- bining automatic labelers and expert annotations for accu- rate radiology report labeling using bert.Proceedings of the Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP), pages 1500–1519, 2020. 1, 2, 4, 5
2020
-
[42]
Tim Tanida, Philip M ¨uller, Georgios Kaissis, and Daniel Rueckert. Interactive and explainable region-guided radiol- ogy report generation.Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 7433–7442, 2023. 2
2023
-
[43]
Chest imagenome dataset.Physio Net,
Joy Wu, Nkechinyere Agu, Ismini Lourentzou, Arjun Sharma, Joseph Paguio, Jasper Seth Yao, Edward Christo- pher Dee, William Mitchell, Satyananda Kashyap, Andrea Giovannini, et al. Chest imagenome dataset.Physio Net,
-
[44]
Cares: A comprehensive benchmark of trustwor- thiness in medical vision language models.Advances in Neu- ral Information Processing Systems, 37:140334–140365,
Peng Xia, Ze Chen, Juanxi Tian, Yangrui Gong, Ruibo Hou, Yue Xu, Zhenbang Wu, Zhiyuan Fan, Yiyang Zhou, Kangyu Zhu, et al. Cares: A comprehensive benchmark of trustwor- thiness in medical vision language models.Advances in Neu- ral Information Processing Systems, 37:140334–140365,
-
[45]
Vari- able generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study.PLoS Medicine, 15(11):e1002683, 2018
John R Zech, Marcus A Badgeley, Manway Liu, Anthony B Costa, Joseph J Titano, and Eric Karl Oermann. Vari- able generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study.PLoS Medicine, 15(11):e1002683, 2018. 2
2018
-
[46]
Libra: Leveraging temporal images for biomedical radiology analysis
Xi Zhang, Zaiqiao Meng, Jake Lever, and Edmond SL Ho. Libra: Leveraging temporal images for biomedical radiology analysis. InFindings of the Association for Computational Linguistics: ACL 2025, pages 17275–17303, 2025. 2, 5
2025
-
[47]
Rexrank: A public leaderboard for ai-powered radiology report generation
Xiaoman Zhang, Hong-Yu Zhou, Xiaoli Yang, Oishi Baner- jee, Juli´an N Acosta, Josh Miller, Ouwen Huang, and Pranav Rajpurkar. Rexrank: A public leaderboard for ai-powered radiology report generation. InAAAI Bridge Program on AI for Medicine and Healthcare, pages 90–99. PMLR, 2025. 1 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.