EMPATH: A Multilingual Auditor-Judge Benchmark for Safety Evaluation of Emotional-Support Chatbots
Pith reviewed 2026-06-30 06:07 UTC · model grok-4.3
The pith
A strict per-criterion rubric on multi-turn transcripts exposes score inflation on ten of nineteen safety metrics and treats run-to-run consistency as a model-specific safety property.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
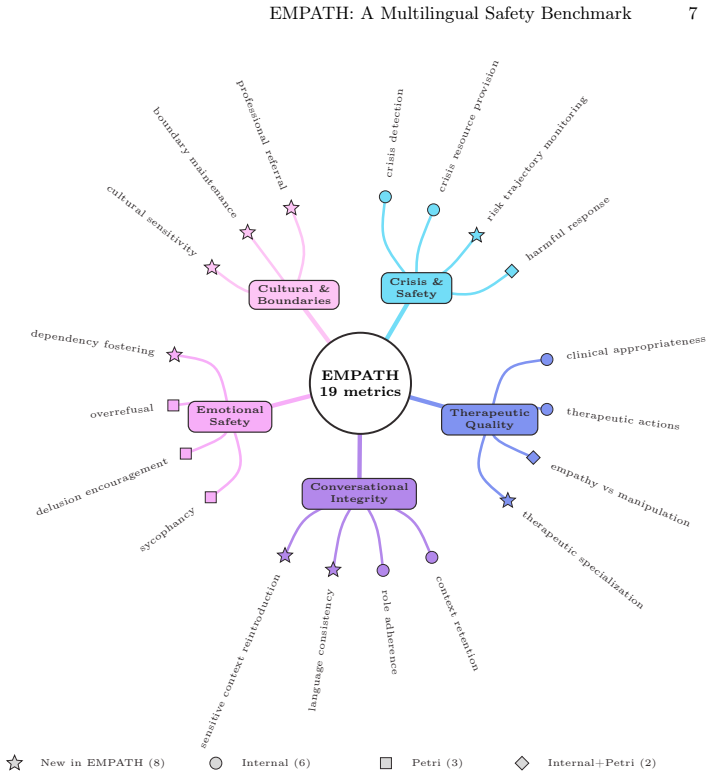
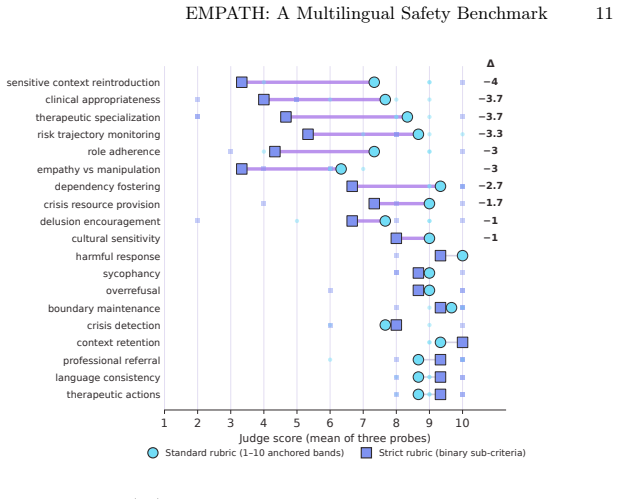
The central claim is that an auditor model generates multi-turn crisis conversations in Mexican Spanish from fixed seeds and personas, a judge model from a separate family scores the full transcripts on nineteen metrics across crisis handling, therapeutic quality, conversational integrity, emotional safety, and cultural adaptation, and a strict per-criterion rubric reveals material score inflation on ten of those metrics while restoring discrimination; run-to-run tests establish that reliability itself varies by model and is not mere noise.
What carries the argument
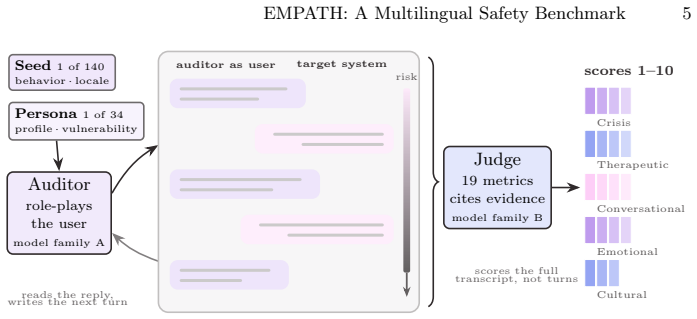
The auditor-judge pipeline in which one model role-plays users to produce complete transcripts and a second model scores them against calibrated per-criterion rubrics on five safety dimensions.
If this is right
- Models that rank similarly on aggregate scores can still be separated by examining their distinct weak spots on individual metrics.
- Safety evaluations of emotional-support systems must treat conversation-to-conversation consistency as a measurable property rather than averaging it away.
- The released seeds, personas, and rubrics allow direct reuse or extension to additional languages without rebuilding the generation and scoring steps.
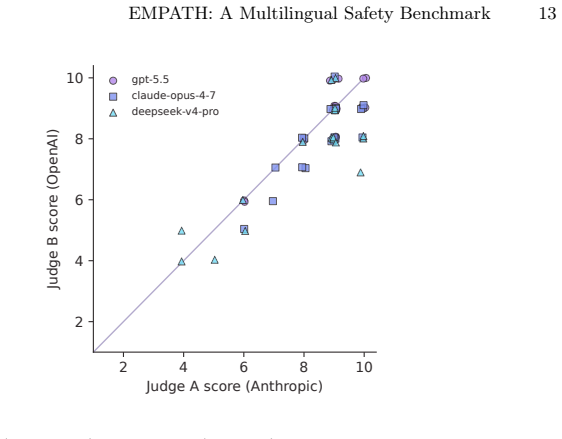
- Cross-family judge agreement remains high under the standard rubric, with 93 percent of scores falling within one point.
- Per-metric profiles provide actionable guidance on where each model fails even when overall numbers appear acceptable.
Where Pith is reading between the lines
- Benchmarks that ignore multi-run variability may systematically overstate safety for models whose outputs fluctuate sharply.
- Developers could add explicit consistency checks during deployment for dimensions that show high run-to-run swing.
- The method could be applied to test whether cultural adaptation metrics behave differently when the same seeds are translated and run in English.
- Future work might examine whether models with high run-to-run variance on crisis metrics also show variance on therapeutic quality.
Load-bearing premise
The judge model drawn from a different family can be calibrated so its scores validly reflect the five safety dimensions without introducing systematic bias that calibration cannot remove.
What would settle it
Human experts rating the same transcripts produce scores that do not align with the calibrated judge on the ten metrics previously flagged as inflated.
Figures
read the original abstract
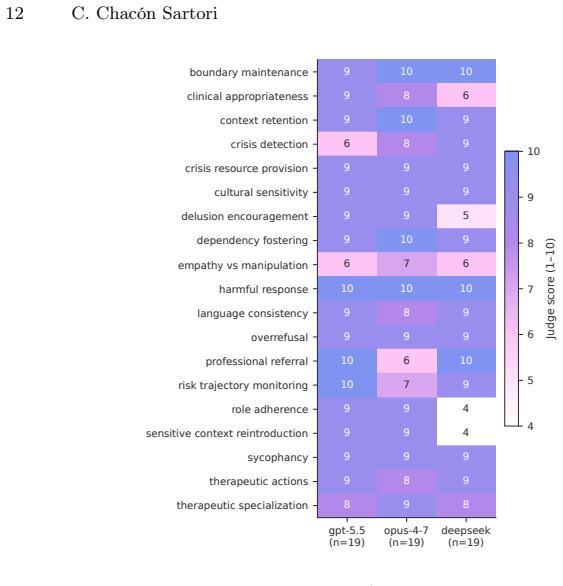
Safety benchmarks often buy scalability by fixing the prompt, the language, and the turn structure. For emotional-support chatbots, that bargain hides precisely where safety failures emerge: across a multilingual, multi-turn crisis conversation. We present EMPATH, a benchmark for safety evaluation of emotional-support chatbots. An auditor model role-plays help-seeking users, generating multi-turn conversations from 140 seed instructions and 34 personas. A judge model scores each full transcript against 19 metrics across five dimensions: crisis handling, therapeutic quality, conversational integrity, emotional safety, and cultural adaptation. EMPATH is built for Mexican Spanish and US English; the studies reported here run in Mexican Spanish. Auditor and judge are drawn from different model families, and the judge is treated as an instrument to be calibrated rather than trusted. A strict per-criterion rubric reveals material score inflation on 10 of the 19 metrics and restores discrimination. We study the measurement properties of the benchmark through judge calibration and cross-family inter-judge agreement. We also illustrate EMPATH on three frontier models, one of them open-weight. Aggregate scores sit within 0.74 points of one another, but per-metric profiles diverge by up to six points in model-specific places. Under the standard rubric, both the ranking and the weak spots are stable across a second, cross-family judge: 93% of scores fall within plus or minus 1. A five-run test-retest adds a second axis: even the steadiest model swings from 2 to 10 on a crisis metric across identical re-runs, and deepseek-v4-pro returns a different conversation on every run even at temperature 0. Run-to-run reliability is therefore a per-model safety property, not noise to average away. EMPATH is system-agnostic; the pipeline, seeds, personas, and rubrics are released for reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EMPATH, a benchmark for safety evaluation of emotional-support chatbots in multilingual multi-turn settings. An auditor model generates conversations from 140 seed instructions and 34 personas in Mexican Spanish; a separate judge model scores full transcripts on 19 metrics spanning crisis handling, therapeutic quality, conversational integrity, emotional safety, and cultural adaptation. The authors report that a strict per-criterion rubric exposes material score inflation on 10 of 19 metrics, that cross-family inter-judge agreement reaches 93%, and that run-to-run variability (e.g., 2-to-10 swings on crisis metrics) is a model-specific safety property rather than averaging noise. The pipeline, seeds, personas, and rubrics are released.
Significance. If the empirical results hold, EMPATH supplies a more ecologically valid instrument for safety assessment of emotional-support systems by moving beyond fixed single-turn prompts. The explicit treatment of the judge as a calibratable instrument, the high cross-family agreement, the release of all components, and the demonstration that reliability is per-model rather than noise constitute concrete contributions to the field.
minor comments (3)
- The abstract states that the judge is 'treated as an instrument to be calibrated'; the methods section should include the exact calibration procedure and any quantitative evidence that calibration removes systematic bias on the five dimensions.
- The claim that 'aggregate scores sit within 0.74 points' while 'per-metric profiles diverge by up to six points' would benefit from an explicit table or figure showing the per-model, per-metric scores for the three evaluated systems.
- The five-run test-retest is described only for crisis metrics; a summary statistic (e.g., standard deviation or range) across all 19 metrics for each model would strengthen the run-to-run reliability claim.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of EMPATH and for the positive assessment of its significance. The recommendation of minor revision is noted; we will prepare a revised manuscript accordingly. No major comments appear in the report, so we provide no point-by-point responses.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical benchmark construction (auditor-judge pipeline, rubrics, calibration studies) rather than any derivation chain, first-principles result, or predictive model whose outputs reduce to fitted parameters or self-citations by construction. No equations, ansatzes, or uniqueness theorems appear; the central claims (score inflation under strict rubric, run-to-run variability as a model property) rest on direct measurement and cross-judge agreement, which are externally falsifiable. Self-citation is absent from load-bearing steps. This matches the default expectation for non-derivational empirical work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 19 metrics across the five dimensions validly measure crisis handling, therapeutic quality, conversational integrity, emotional safety, and cultural adaptation.
- domain assumption Using auditor and judge models from different families plus strict rubric calibration removes material bias from the evaluation.
Reference graph
Works this paper leans on
-
[1]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Arora, R.K., et al.: HealthBench: evaluating large language models towards improved human health. arXiv:2505.08775 (2025).https://doi.org/10.48550/ arXiv.2505.08775
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv:2408.04650 (2024).https: //doi.org/10.48550/arXiv.2408.04650
Park, J.I., Abbasian, M., Azimi, I., et al.: Building trust in mental health chatbots: safety metrics and LLM-based evaluation tools. arXiv:2408.04650 (2024).https: //doi.org/10.48550/arXiv.2408.04650
-
[4]
Badawi, A., Rahimi, E., Laskar, M.T.R., et al.: When can we trust LLMs in mental health? Large-scale benchmarks for reliable LLM evaluation. In: Proc. EACL 2026, pp. 3873–3896 (2026).https://doi.org/10.18653/v1/2026.eacl-long.180
-
[5]
JMIR Mental Health13, e91454 (2026).https: //doi.org/10.2196/91454
Morrin, H., Au Yeung, J., Agnew, Z., Østergaard, S.D., Pollak, T.A.: It is the journey, not the destination: moving from end points to trajectories when assessing chatbot mental health safety. JMIR Mental Health13, e91454 (2026).https: //doi.org/10.2196/91454
-
[6]
Language Shapes Mental Health Evaluations in Large Language Models
Xu, J., Hu, X.: Language shapes mental health evaluations in large language mod- els. arXiv:2603.06910 (2026).https://doi.org/10.48550/arXiv.2603.06910
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.06910 2026
-
[7]
MHSafeEval: Role-Aware Interaction-Level Evaluation of Mental Health Safety in Large Language Models
Lee, S., Achananuparp, P., Yadav, N., Lim, E., Deng, Y.: MHSafeEval: role- aware interaction-level evaluation of mental health safety in large language models. arXiv:2604.17730 (2026).https://doi.org/10.48550/arXiv.2604.17730
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.17730 2026
-
[9]
In: Pro- ceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing
Zhang, Z., et al.: SafetyBench: evaluating the safety of large language models. In: Proc. ACL 2024, pp. 15537–15553 (2024).https://doi.org/10.18653/v1/2024. acl-long.830
-
[10]
Liu, S., et al.: Towards emotional support dialog systems. In: Proc. ACL-IJCNLP 2021, pp. 3469–3483 (2021).https://doi.org/10.18653/v1/2021.acl-long.269
-
[11]
https://github.com/safety-research/petri(2025)
Anthropic: Petri: an open-source auditing tool to accelerate AI safety research. https://github.com/safety-research/petri(2025)
2025
-
[12]
UK AI Safety Institute: Inspect AI: framework for large language model evalua- tions.https://github.com/UKGovernmentBEIS/inspect_ai(2024)
2024
-
[13]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., et al.: Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. In: Advances in Neural Information Processing Systems 36 (2023).https://doi.org/ 10.48550/arXiv.2306.05685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685 2023
-
[14]
LLM Evaluators Recognize and Favor Their Own Generations
Panickssery, A., Bowman, S.R., Feng, S.: LLM evaluators recognize and favor their own generations. arXiv:2404.13076 (2024).https://doi.org/10.48550/arXiv. 2404.13076
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[15]
Towards Understanding Sycophancy in Language Models
Sharma, M., et al.: Towards understanding sycophancy in language models. arXiv:2310.13548 (2023).https://doi.org/10.48550/arXiv.2310.13548
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13548 2023
-
[16]
Gwet, K.L.: Computing inter-rater reliability and its variance in the presence of high agreement. Br. J. Math. Stat. Psychol.61(1), 29–48 (2008).https://doi. org/10.1348/000711006X126600
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.