REAR: Test-time Preference Realignment through Reward Decomposition
Pith reviewed 2026-06-30 06:18 UTC · model grok-4.3
The pith
Decomposing the reward into question and preference parts yields an efficient test-time realignment method for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
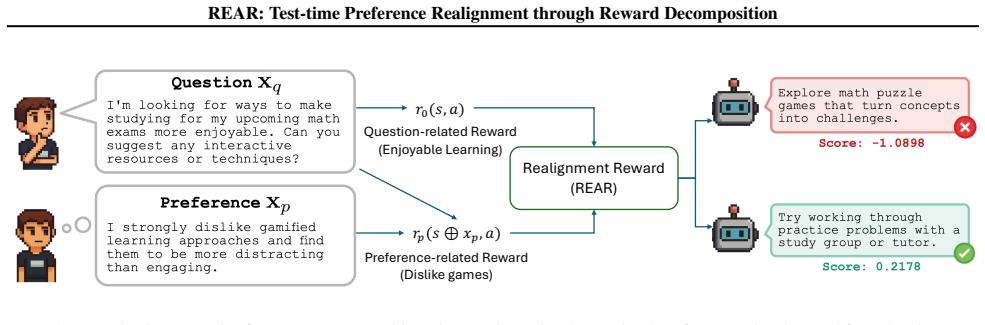
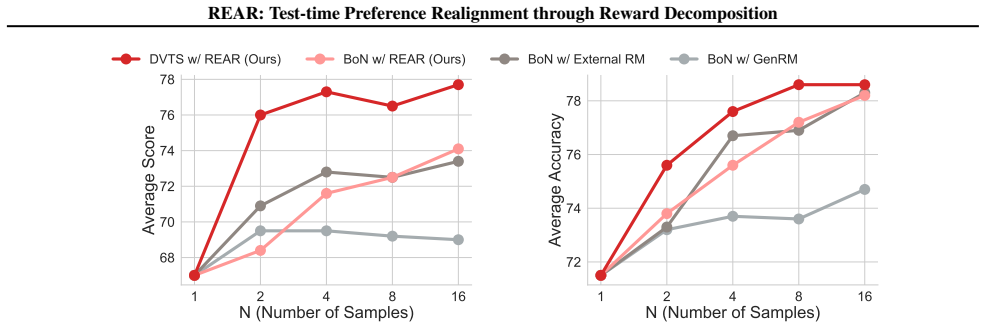
The REAlignment Reward (REAR) is obtained by decomposing the underlying reward into independent question and preference terms and selectively rescaling their proportions. This reward can be formulated as a linear combination of token-level policy log-probabilities, allowing integration with test-time scaling methods such as best-of-N sampling and tree search for preference alignment.
What carries the argument
The reward decomposition into question-related and preference-related components, which enables selective rescaling to derive the REAR.
If this is right
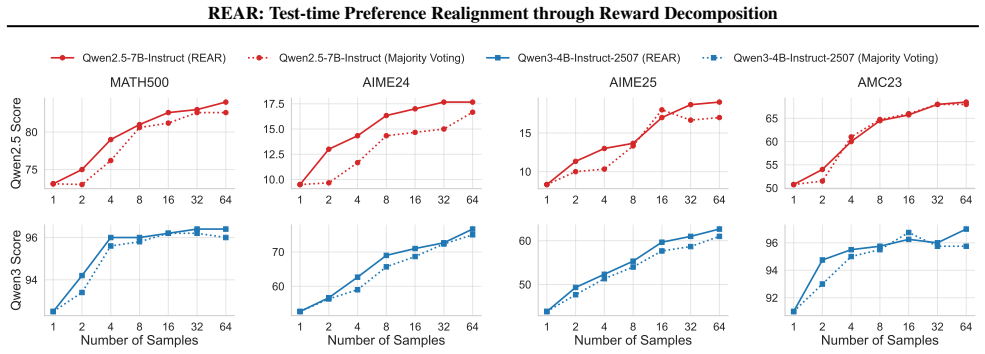
- REAR enables scalable test-time realignment for diverse user preferences without additional training.
- It integrates directly with best-of-N sampling and tree search algorithms.
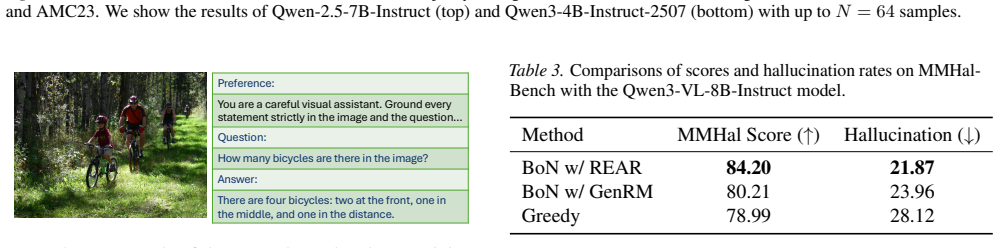
- It generalizes to mathematical and visual tasks when suitable preference settings are used.
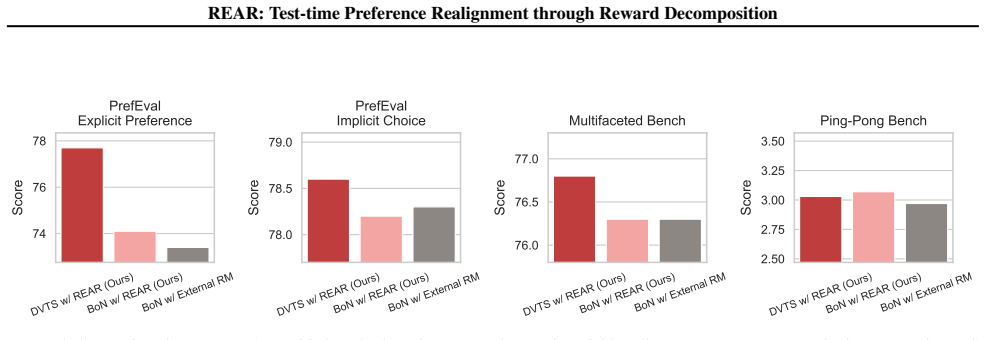
- Compared to other test-time baselines, it improves performance on preference alignment tasks.
Where Pith is reading between the lines
- If the decomposition holds, similar reward splits could allow test-time control over other model behaviors like safety or style.
- This suggests that preference alignment can be treated as a realignment problem rather than requiring full retraining.
- Production systems could use this to adapt to user preferences on the fly during inference.
Load-bearing premise
The reward function decomposes into independent question-related and preference-related parts whose relative weights can be adjusted without changing the overall objective.
What would settle it
Running REAR-augmented best-of-N sampling on a preference dataset and finding no improvement in win rates over standard best-of-N or random sampling would falsify the utility of the rescaling.
Figures

read the original abstract
Aligning large language models (LLMs) with diverse user preferences is a critical yet challenging task. While post-training methods can adapt models to specific needs, they often require costly data curation and additional training. Test-time scaling (TTS) presents an efficient, training-free alternative, but its application has been largely limited to verifiable domains like mathematics and coding, where response correctness is easily judged. To extend TTS to preference alignment, we introduce a novel framework that models the task as a realignment problem, since the base model often fails to sufficiently align with the stated preference. Our key insight is to decompose the underlying reward function into two components: one related to the question and the other to preference information. This allows us to derive a REAlignment Reward (REAR) that selectively rescales the proportions of these two reward terms. We then show that REAR can be formulated as a linear combination of token-level policy log-probabilities, making it computationally efficient and easy to integrate with various TTS algorithms such as best-of-$N$ sampling and tree search. Experiments show that compared to other test-time baselines, REAR not only enables scalable test-time realignment for preference alignment tasks under diverse user requirements, but also generalizes to mathematical and visual tasks under appropriate preference settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REAR, a test-time framework for realigning LLMs to diverse user preferences via reward decomposition into question-related and preference-related components. This decomposition is used to derive a rescaled reward (REAR) that is shown to be expressible as a linear combination of token-level policy log-probabilities, enabling efficient integration with TTS methods such as best-of-N sampling and tree search without additional training. Experiments claim superior performance over baselines on preference alignment tasks and generalization to mathematical and visual reasoning under suitable preferences.
Significance. If the decomposition and linear formulation are rigorously established, the work would offer a training-free, computationally lightweight extension of test-time scaling to non-verifiable preference alignment, addressing a key limitation of current TTS methods. The explicit linear form and compatibility with existing TTS algorithms are practical strengths that could facilitate adoption.
major comments (3)
- [Abstract, §3] Abstract and §3 (derivation of REAR): The claim that the reward decomposition 'allows us to derive' a linear combination of token-level log-probabilities is stated without explicit steps, conditions on independence of components, or a proof that selective rescaling preserves the original preference ordering. This derivation is load-bearing for the central efficiency and TTS-integration claims.
- [§3.1] §3.1 (reward decomposition): The assumption that the underlying reward r can be additively split into independent r_question and r_preference terms such that rescaling their relative proportions yields an exact linear form in the base policy's log-probabilities is not justified or tested against cases where question and preference signals are entangled in the reward model or policy.
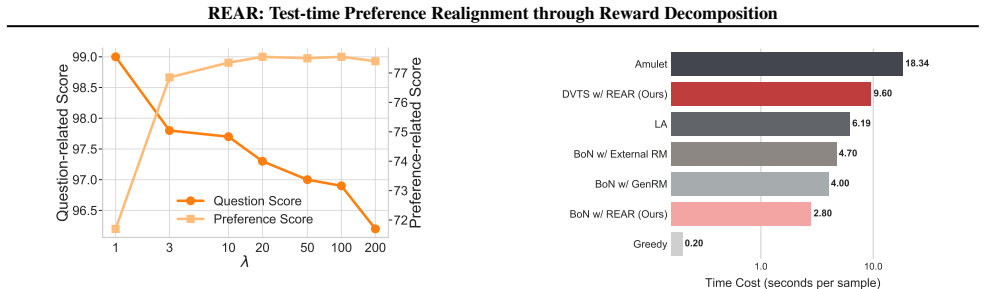
- [§4] §4 (experiments): No ablation or sensitivity analysis is reported on the choice of decomposition weights or on whether the linear equivalence holds under the specific TTS algorithms used; the reported gains therefore cannot be attributed unambiguously to the claimed linear form versus other factors.
minor comments (2)
- [§3] Notation for the decomposed reward terms and the rescaling parameter should be introduced with explicit definitions before the linear-combination claim.
- [Abstract] The abstract's phrasing that REAR 'generalizes to mathematical and visual tasks under appropriate preference settings' should be qualified with the specific preference settings used in those experiments.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We agree that the derivation of the linear form and experimental validation require greater rigor and will revise accordingly to address each point. Our responses follow.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (derivation of REAR): The claim that the reward decomposition 'allows us to derive' a linear combination of token-level log-probabilities is stated without explicit steps, conditions on independence of components, or a proof that selective rescaling preserves the original preference ordering. This derivation is load-bearing for the central efficiency and TTS-integration claims.
Authors: We acknowledge that the steps in §3 would benefit from explicit expansion. In the revision we will insert a self-contained derivation subsection that (i) states the additive decomposition assumption with its independence condition, (ii) shows the algebraic reduction to a linear combination of token log-probabilities, and (iii) proves that the rescaling factor preserves the original preference ordering (the argmax over responses remains unchanged and relative rankings are maintained). This will make the load-bearing claim fully rigorous. revision: yes
-
Referee: [§3.1] §3.1 (reward decomposition): The assumption that the underlying reward r can be additively split into independent r_question and r_preference terms such that rescaling their relative proportions yields an exact linear form in the base policy's log-probabilities is not justified or tested against cases where question and preference signals are entangled in the reward model or policy.
Authors: The additive split is introduced as a modeling approximation that enables the subsequent linearization; it is not claimed to hold universally. In revision we will add an explicit limitations paragraph discussing when entanglement may violate the assumption and the resulting approximation error. We will also note that the linear equivalence is exact under the stated additive model, which is the regime in which REAR is applied. revision: yes
-
Referee: [§4] §4 (experiments): No ablation or sensitivity analysis is reported on the choice of decomposition weights or on whether the linear equivalence holds under the specific TTS algorithms used; the reported gains therefore cannot be attributed unambiguously to the claimed linear form versus other factors.
Authors: We will add a new sensitivity subsection in §4 that varies the rescaling hyper-parameter across a range and reports performance curves, plus a verification experiment confirming that the linear combination is the quantity actually optimized inside best-of-N and tree-search. These additions will allow readers to attribute gains more directly to the linear formulation. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The abstract presents the decomposition of the reward into question-related and preference-related components as an insight, followed by a derivation of REAR and a subsequent showing that REAR can be expressed as a linear combination of token-level log-probabilities. No equations are provided in the given text that reduce the linear-combination claim to the decomposition by definition or construction. The steps are described as sequential derivations rather than tautological redefinitions or fitted inputs renamed as predictions. Without explicit self-referential equations or load-bearing self-citations that collapse the central result, the chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Puterman , title =
Martin L. Puterman , title =
-
[2]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[3]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
2025
-
[4]
Zhehao Zhang and Ryan A. Rossi and Branislav Kveton and Yijia Shao and Diyi Yang and Hamed Zamani and Franck Dernoncourt and Joe Barrow and Tong Yu and Sungchul Kim and Ruiyi Zhang and Jiuxiang Gu and Tyler Derr and Hongjie Chen and Junda Wu and Xiang Chen and Zichao Wang and Subrata Mitra and Nedim Lipka and Nesreen K. Ahmed and Yu Wang , title =. Transa...
-
[5]
Transactions on Machine Learning Research , volume =
Jiangjie Chen and Xintao Wang and Rui Xu and Siyu Yuan and Yikai Zhang and Wei Shi and Jian Xie and Shuang Li and Ruihan Yang and Tinghui Zhu and Aili Chen and Nianqi Li and Lida Chen and Caiyu Hu and Siye Wu and Scott Ren and Ziquan Fu and Yanghua Xiao , title =. Transactions on Machine Learning Research , volume =
-
[6]
World Wide Web
Likang Wu and Zhi Zheng and Zhaopeng Qiu and Hao Wang and Hongchao Gu and Tingjia Shen and Chuan Qin and Chen Zhu and Hengshu Zhu and Qi Liu and Hui Xiong and Enhong Chen , title =. World Wide Web
-
[7]
Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization , booktitle =
Rajkumar Ramamurthy and Prithviraj Ammanabrolu and Kiant. Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization , booktitle =
-
[8]
Findings of the Association for Computational Linguistics , pages =
Xuemiao Zhang and Liangyu Xu and Feiyu Duan and Yongwei Zhou and Sirui Wang and Rongxiang Weng and Jingang Wang and Xunliang Cai , title =. Findings of the Association for Computational Linguistics , pages =
-
[9]
Q-Adapter: Customizing Pre-trained
Yi. Q-Adapter: Customizing Pre-trained. International Conference on Learning Representations , year =
-
[10]
International Conference on Machine Learning , year =
Ganqu Cui and Lifan Yuan and Ning Ding and Guanming Yao and Bingxiang He and Wei Zhu and Yuan Ni and Guotong Xie and Ruobing Xie and Yankai Lin and Zhiyuan Liu and Maosong Sun , title =. International Conference on Machine Learning , year =
-
[11]
Proceedings of
Wanqi Xue and Qingpeng Cai and Zhenghai Xue and Shuo Sun and Shuchang Liu and Dong Zheng and Peng Jiang and Kun Gai and Bo An , title =. Proceedings of
-
[12]
Manning and Stefano Ermon and Chelsea Finn , title =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , title =. Advances in Neural Information Processing Systems , year =
-
[13]
International Conference on Learning Representations , year =
Zhaowei Zhang and Fengshuo Bai and Qizhi Chen and Chengdong Ma and Mingzhi Wang and Haoran Sun and Zilong Zheng and Yaodong Yang , title =. International Conference on Learning Representations , year =
-
[14]
International Conference on Machine Learning , year =
Songyang Gao and Qiming Ge and Wei Shen and Shihan Dou and Junjie Ye and Xiao Wang and Rui Zheng and Yicheng Zou and Zhi Chen and Hang Yan and Qi Zhang and Dahua Lin , title =. International Conference on Machine Learning , year =
-
[15]
Advances in Neural Information Processing Systems Track on Datasets and Benchmarks , year =
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title =. Advances in Neural Information Processing Systems Track on Datasets and Benchmarks , year =
-
[16]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. International Conference on Learning Representations , year =
-
[18]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , title =....
-
[19]
International Conference on Machine Learning , year =
Harrison Lee and Samrat Phatale and Hassan Mansoor and Thomas Mesnard and Johan Ferret and Kellie Lu and Colton Bishop and Ethan Hall and Victor Carbune and Abhinav Rastogi and Sushant Prakash , title =. International Conference on Machine Learning , year =
-
[20]
Jordan and Philipp Moritz , title =
John Schulman and Sergey Levine and Pieter Abbeel and Michael I. Jordan and Philipp Moritz , title =. International Conference on Machine Learning , pages =
-
[21]
CoRR , volume =
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =
-
[22]
Jordan and Pieter Abbeel , editor =
John Schulman and Philipp Moritz and Sergey Levine and Michael I. Jordan and Pieter Abbeel , editor =. High-Dimensional Continuous Control Using Generalized Advantage Estimation , booktitle =
-
[23]
Lianmin Zheng and Wei. Judging. Advances in Neural Information Processing Systems , year =
-
[24]
Findings of the Association for Computational Linguistics , pages =
Yunxiang Zhang and Muhammad Khalifa and Lajanugen Logeswaran and Jaekyeom Kim and Moontae Lee and Honglak Lee and Lu Wang , title =. Findings of the Association for Computational Linguistics , pages =
-
[25]
Advances in Neural Information Processing Systems , year =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , title =. Advances in Neural Information Processing Systems , year =
-
[26]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , title =. Advances in Neural Information Processing Systems , year =
-
[27]
Advances in Neural Information Processing Systems , year =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , title =. Advances in Neural Information Processing Systems , year =
-
[28]
Advances in Neural Information Processing Systems , year =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Tom Griffiths and Yuan Cao and Karthik Narasimhan , title =. Advances in Neural Information Processing Systems , year =
-
[29]
European Conference on Computer Systems , pages =
Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu , title =. European Conference on Computer Systems , pages =
-
[30]
Annual Meeting of the Association for Computational Linguistics , pages =
Chaoqun He and Renjie Luo and Yuzhuo Bai and Shengding Hu and Zhen Leng Thai and Junhao Shen and Jinyi Hu and Xu Han and Yujie Huang and Yuxiang Zhang and Jie Liu and Lei Qi and Zhiyuan Liu and Maosong Sun , editor =. Annual Meeting of the Association for Computational Linguistics , pages =
-
[31]
Aviral Kumar and Vincent Zhuang and Rishabh Agarwal and Yi Su and John D. Co. Training Language Models to. International Conference on Learning Representations , year =
-
[32]
Gonzalez and Clark W
Lianmin Zheng and Liangsheng Yin and Zhiqiang Xie and Chuyue Sun and Jeff Huang and Cody Hao Yu and Shiyi Cao and Christos Kozyrakis and Ion Stoica and Joseph E. Gonzalez and Clark W. Barrett and Ying Sheng , title =. Advances in Neural Information Processing Systems , year =
-
[33]
Symposium on Operating Systems Principles , pages =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , title =. Symposium on Operating Systems Principles , pages =
-
[34]
Annual Meeting of the Association for Computational Linguistics , pages =
Peiyi Wang and Lei Li and Zhihong Shao and Runxin Xu and Damai Dai and Yifei Li and Deli Chen and Yu Wu and Zhifang Sui , title =. Annual Meeting of the Association for Computational Linguistics , pages =
-
[35]
Advances in Neural Information Processing Systems , pages=
Self-evaluation guided beam search for reasoning , author=. Advances in Neural Information Processing Systems , pages=
-
[36]
NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training , author=. NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
2023
-
[37]
Miranda and Bill Yuchen Lin and Khyathi Raghavi Chandu and Nouha Dziri and Sachin Kumar and Tom Zick and Yejin Choi and Noah A
Nathan Lambert and Valentina Pyatkin and Jacob Morrison and Lester James V. Miranda and Bill Yuchen Lin and Khyathi Raghavi Chandu and Nouha Dziri and Sachin Kumar and Tom Zick and Yejin Choi and Noah A. Smith and Hannaneh Hajishirzi , title =. Findings of the Association for Computational Linguistics: NAACL 2025 , pages =
2025
-
[38]
Advances in Neural Information Processing Systems , year =
Seongyun Lee and Sue Hyun Park and Seungone Kim and Minjoon Seo , title =. Advances in Neural Information Processing Systems , year =
-
[39]
International Conference on Learning Representations , year =
Siyan Zhao and Mingyi Hong and Yang Liu and Devamanyu Hazarika and Kaixiang Lin , title =. International Conference on Learning Representations , year =
-
[40]
Advances in Neural Information Processing Systems , year =
Chenran Li and Chen Tang and Haruki Nishimura and Jean Mercat and Masayoshi Tomizuka and Wei Zhan , title =. Advances in Neural Information Processing Systems , year =
-
[41]
CoRR , volume =
Pengcheng Wang and Xinghao Zhu and Yuxin Chen and Chenfeng Xu and Masayoshi Tomizuka and Chenran Li , title =. CoRR , volume =
-
[42]
Advances in Neural Information Processing Systems , year =
Fuxiang Zhang and Jiacheng Xu and Chaojie Wang and Ce Cui and Yang Liu and Bo An , title =. Advances in Neural Information Processing Systems , year =
-
[43]
CoRR , volume =
Chaojie Wang and Yanchen Deng and Zhiyi Lv and Zeng Liang and Jujie He and Shuicheng Yan and Bo An , title =. CoRR , volume =
-
[44]
Yang , title =
Yichen Huang and Lin F. Yang , title =. CoRR , volume =
-
[45]
Gheorghe Comanici and Eric Bieber and Mike Schaekermann and Ice Pasupat and Noveen Sachdeva and Inderjit S. Dhillon and Marcel Blistein and Ori Ram and Dan Zhang and Evan Rosen and Luke Marris and Sam Petulla and Colin Gaffney and Asaf Aharoni and Nathan Lintz and Tiago Cardal Pais and Henrik Jacobsson and Idan Szpektor and Nan. Gemini 2.5: Pushing the Fr...
-
[46]
Generalist Reward Models: Found Inside Large Language Models , journal =
Yi. Generalist Reward Models: Found Inside Large Language Models , journal =
-
[47]
CoRR , volume =
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Keqin Bao and Kexin Yang and Le Yu and...
-
[48]
CoRR , volume =
Ilya Gusev , title =. CoRR , volume =
-
[49]
CoRR , volume =
Chris Yuhao Liu and Liang Zeng and Jiacai Liu and Rui Yan and Jujie He and Chaojie Wang and Shuicheng Yan and Yang Liu and Yahui Zhou , title =. CoRR , volume =
-
[50]
Ziegler and Ryan Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul F
Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul F. Christiano , title =. Advances in Neural Information Processing Systems , year =
-
[51]
CoRR , volume =
Tuomas Haarnoja and Aurick Zhou and Kristian Hartikainen and George Tucker and Sehoon Ha and Jie Tan and Vikash Kumar and Henry Zhu and Abhishek Gupta and Pieter Abbeel and Sergey Levine , title =. CoRR , volume =
-
[52]
CoRR , volume =
Yafu Li and Xuyang Hu and Xiaoye Qu and Linjie Li and Yu Cheng , title =. CoRR , volume =
-
[53]
CoRR , volume =
Baijiong Lin and Weisen Jiang and Yuancheng Xu and Hao Chen and Ying. CoRR , volume =
-
[54]
CoRR , volume =
Chi. CoRR , volume =
-
[55]
CoRR , volume =
Joel Jang and Seungone Kim and Bill Yuchen Lin and Yizhong Wang and Jack Hessel and Luke Zettlemoyer and Hannaneh Hajishirzi and Yejin Choi and Prithviraj Ammanabrolu , title =. CoRR , volume =
-
[56]
Constitutional
Yuntao Bai and Saurav Kadavath and Sandipan Kundu and Amanda Askell and Jackson Kernion and Andy Jones and Anna Chen and Anna Goldie and Azalia Mirhoseini and Cameron McKinnon and Carol Chen and Catherine Olsson and Christopher Olah and Danny Hernandez and Dawn Drain and Deep Ganguli and Dustin Li and Eli Tran. Constitutional. CoRR , volume =
-
[57]
CoRR , volume =
Tian Xie and Zitian Gao and Qingnan Ren and Haoming Luo and Yuqian Hong and Bryan Dai and Joey Zhou and Kai Qiu and Zhirong Wu and Chong Luo , title =. CoRR , volume =
-
[58]
Transactions on Machine Learning Research , year =
Junyou Li and Qin Zhang and Yangbin Yu and Qiang Fu and Deheng Ye , title =. Transactions on Machine Learning Research , year =
-
[59]
Francis Song and Noah Y
Jonathan Uesato and Nate Kushman and Ramana Kumar and H. Francis Song and Noah Y. Siegel and Lisa Wang and Antonia Creswell and Geoffrey Irving and Irina Higgins , title =. CoRR , volume =
-
[60]
CoRR , volume =
Seungone Kim and Ian Wu and Jinu Lee and Xiang Yue and Seongyun Lee and Mingyeong Moon and Kiril Gashteovski and Carolin Lawrence and Julia Hockenmaier and Graham Neubig and Sean Welleck , title =. CoRR , volume =
-
[61]
CoRR , volume =
Dakota Mahan and Duy Phung and Rafael Rafailov and Chase Blagden and Nathan Lile and Louis Castricato and Jan. CoRR , volume =
-
[62]
International Conference on Learning Representations , year =
Lunjun Zhang and Arian Hosseini and Hritik Bansal and Mehran Kazemi and Aviral Kumar and Rishabh Agarwal , title =. International Conference on Learning Representations , year =
-
[63]
CoRR , volume =
Zijun Liu and Peiyi Wang and Runxin Xu and Shirong Ma and Chong Ruan and Peng Li and Yang Liu and Yu Wu , title =. CoRR , volume =
-
[64]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =
-
[65]
CoRR , volume =
Haipeng Luo and Qingfeng Sun and Can Xu and Pu Zhao and Jianguang Lou and Chongyang Tao and Xiubo Geng and Qingwei Lin and Shifeng Chen and Dongmei Zhang , title =. CoRR , volume =
-
[66]
2024 , url =
Learning to Reason with. 2024 , url =
2024
-
[67]
Goodman , title =
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah D. Goodman , title =. Advances in Neural Information Processing Systems , year =
-
[68]
Courville and Alessandro Sordoni and Rishabh Agarwal , title =
Arian Hosseini and Xingdi Yuan and Nikolay Malkin and Aaron C. Courville and Alessandro Sordoni and Rishabh Agarwal , title =. CoRR , volume =
-
[69]
CoRR , volume =
Yilun Zhou and Austin Xu and Peifeng Wang and Caiming Xiong and Shafiq Joty , title =. CoRR , volume =
-
[70]
CoRR , volume =
Amrith Setlur and Chirag Nagpal and Adam Fisch and Xinyang Geng and Jacob Eisenstein and Rishabh Agarwal and Alekh Agarwal and Jonathan Berant and Aviral Kumar , title =. CoRR , volume =
-
[71]
CoRR , volume =
Xiaoyu Tian and Sitong Zhao and Haotian Wang and Shuaiting Chen and Yunjie Ji and Yiping Peng and Han Zhao and Xiangang Li , title =. CoRR , volume =
-
[72]
CoRR , volume =
Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Mark Chen and Heewoo Jun and Lukasz Kaiser and Matthias Plappert and Jerry Tworek and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman , title =. CoRR , volume =
-
[73]
CoRR , volume =
An Yang and Beichen Zhang and Binyuan Hui and Bofei Gao and Bowen Yu and Chengpeng Li and Dayiheng Liu and Jianhong Tu and Jingren Zhou and Junyang Lin and Keming Lu and Mingfeng Xue and Runji Lin and Tianyu Liu and Xingzhang Ren and Zhenru Zhang , title =. CoRR , volume =
-
[74]
CoRR , volume =
Weihao Zeng and Yuzhen Huang and Qian Liu and Wei Liu and Keqing He and Zejun Ma and Junxian He , title =. CoRR , volume =
-
[75]
Goodman , title =
Eric Zelikman and Georges Harik and Yijia Shao and Varuna Jayasiri and Nick Haber and Noah D. Goodman , title =. CoRR , volume =
-
[76]
Hurst, Aaron and Lerer, Adam and Goucher, Adam P and Perelman, Adam and Ramesh, Aditya and Clark, Aidan and Ostrow, AJ and Welihinda, Akila and Hayes, Alan and Radford, Alec and others , journal=
-
[77]
2025 , journal=
Qwen3-VL Technical Report , author=. 2025 , journal=
2025
-
[78]
Zhang and Han Bao and Hanwei Xu and Haocheng Wang and Haowei Zhang and Honghui Ding and Huajian Xin and Huazuo Gao and Hui Li and Hui Qu and J
DeepSeek-AI and Aixin Liu and Bei Feng and Bing Xue and Bingxuan Wang and Bochao Wu and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenyu Zhang and Chong Ruan and Damai Dai and Daya Guo and Dejian Yang and Deli Chen and Dongjie Ji and Erhang Li and Fangyun Lin and Fucong Dai and Fuli Luo and Guangbo Hao and Guanting Chen and Guowei Li and H. Zhang...
-
[79]
CoRR , volume =
Benedikt Stroebl and Sayash Kapoor and Arvind Narayanan , title =. CoRR , volume =
-
[80]
CoRR , volume =
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , title =. CoRR , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.