Can LLMs Rank? A Tale of Triads and Triage
Pith reviewed 2026-06-30 04:01 UTC · model grok-4.3
The pith
LLM rankings from pairwise comparisons are reliable only when both internal circular consistency and cross-run stability are checked.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
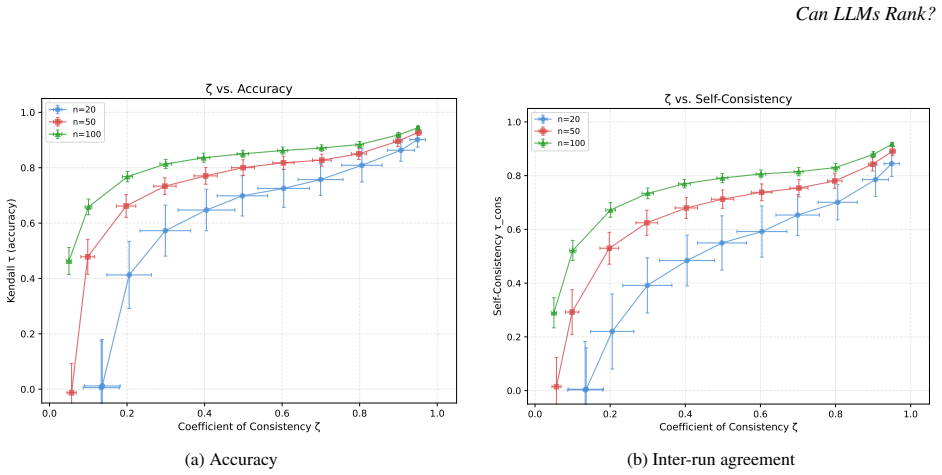
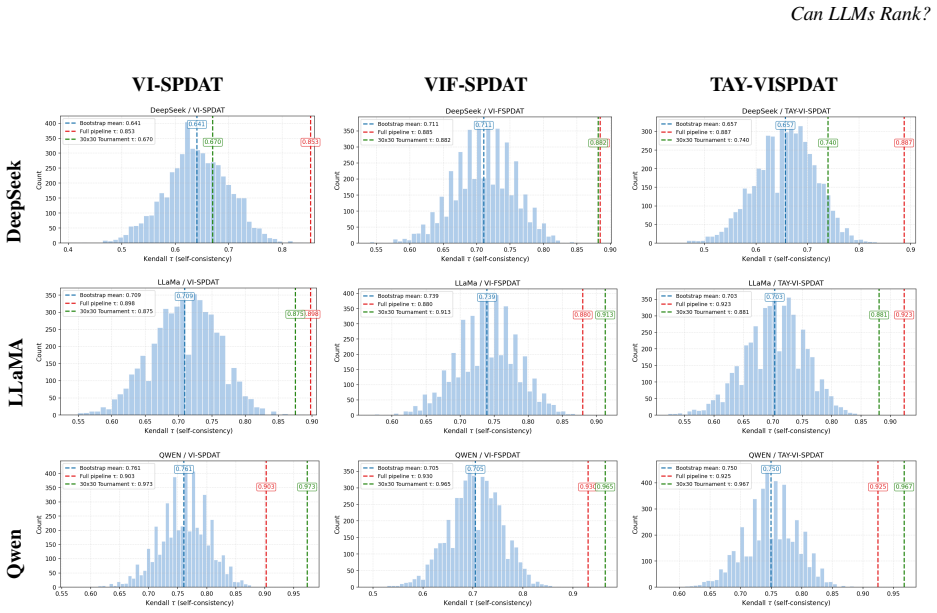
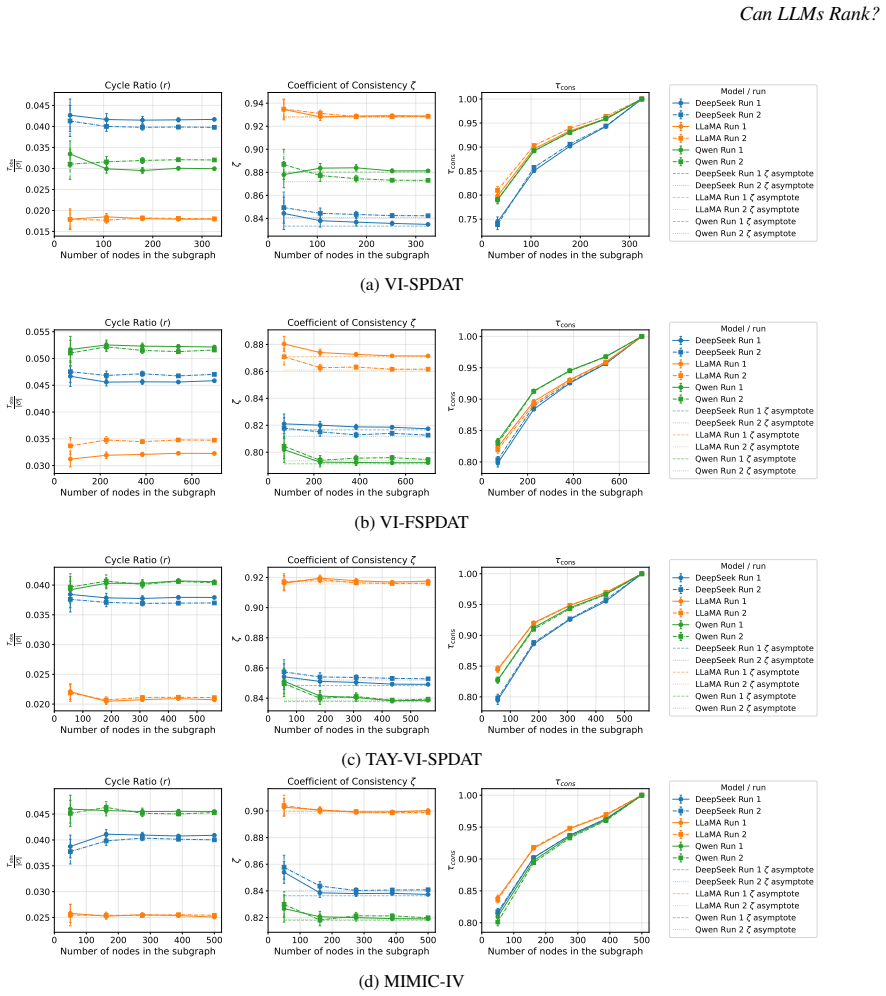
When an LLM serves as the judge in a tournament of pairwise comparisons, the coefficient of consistency ζ detects circular triads within one run while Kendall's τ measures variation across runs; these two diagnostics are independently informative, and different models exhibit different reliability profiles on the two axes.
What carries the argument
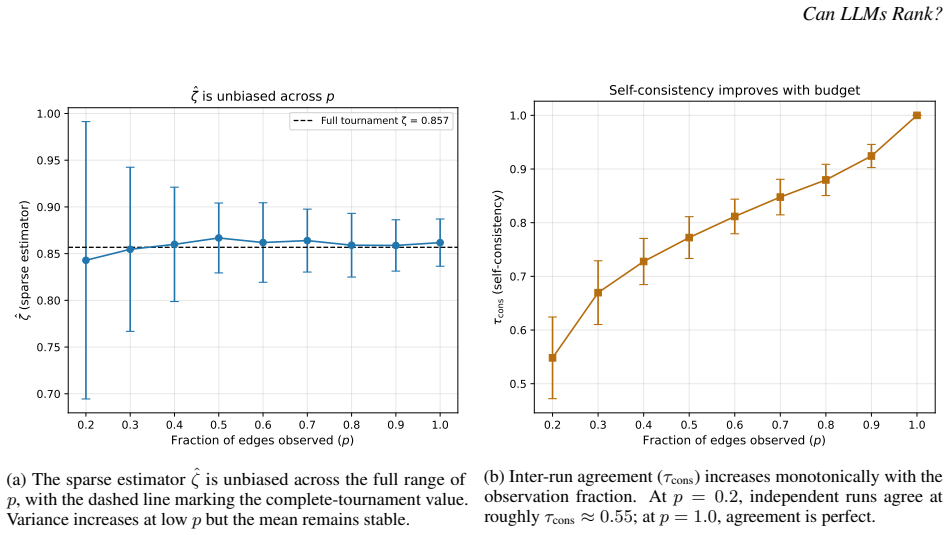
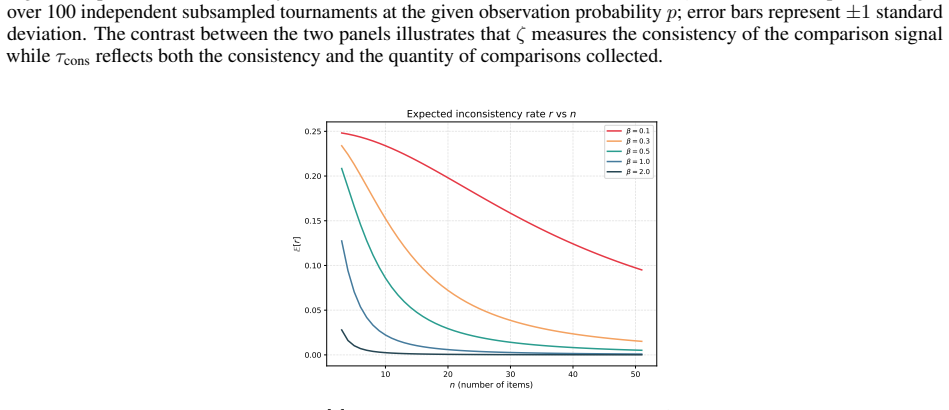
Coefficient of consistency ζ, which counts circular triads in the tournament graph of pairwise judgments, used together with inter-run Kendall's τ distance between produced rankings.
If this is right
- A model can score well on one measure while failing the other, so relying on only one leaves reliability gaps.
- Model choice for ranking tasks must be evaluated separately on each axis rather than by a single aggregate score.
- Both measures can be obtained from the same set of pairwise queries at negligible extra cost.
- Practitioners receive explicit thresholds and reporting practices before committing an LLM to prioritization.
Where Pith is reading between the lines
- Even when both consistency measures are satisfied, the ranking may still diverge from expert human judgments or produce unintended fairness effects.
- The same dual-check approach could be applied to other social-choice aggregation rules beyond simple tournament methods.
- Testing consistency on larger item sets would show whether the two measures remain independent at scale.
- A natural next measurement is whether high-consistency rankings actually improve downstream outcomes such as reduced homelessness recidivism or faster ED throughput.
Load-bearing premise
High scores on these two consistency measures are enough to decide that the resulting ranking can be trusted for real allocation decisions.
What would settle it
Deploy rankings that pass both high ζ and low τ thresholds in a controlled pilot and measure whether they produce measurably better or fairer outcomes than rankings that fail one or both thresholds.
Figures



read the original abstract
From housing allocation for households experiencing homelessness to triage in emergency departments, LLMs are increasingly being considered as judges of consequential decisions that require ranking people for scarce resources. Ranking large groups simultaneously is cognitively demanding and error-prone. A natural solution, drawing on decades of social choice theory, elicits pairwise comparisons and aggregates them into a total order. However, a fundamental question remains when LLMs serve as the pairwise judge: how can a practitioner tell, before committing to a ranking, whether the LLM's judgments are sufficiently consistent to trust the result? We discuss two different ways of identifying consistency. A classical diagnostic, the coefficient of consistency $\zeta$, originally developed to measure judge reliability by counting circular triads in tournament graphs, provides a cheap, model-free measure of intra-run consistency. Various standard measures of distance between rankings, for example Kendall's $\tau$, can measure inter-run variability. We show, in both theory and practice, that these measures are independently valuable, and advocate for using both to assess reliability of rankings. We demonstrate the practical importance of our results across two high-stakes prioritization tasks: homelessness service allocation and emergency department triage. Three different leading LLMs have considerably different performance profiles across these two axes of consistency. We provide guidelines for how practitioners could think about measuring and assessing consistency before committing to a model for ranking or prioritization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two diagnostics for assessing the reliability of LLM-generated rankings derived from pairwise comparisons: the coefficient of consistency ζ (counting circular triads within a run) for intra-run consistency and Kendall's τ (or similar distances) for inter-run variability. It claims to demonstrate both theoretically and empirically that these measures are independently valuable, applies them to two high-stakes tasks (homelessness service allocation and ED triage), finds that three leading LLMs show distinct profiles across the two axes, and offers practitioner guidelines for deciding when to trust an LLM ranking.
Significance. If the independence of the two measures and their link to ranking reliability hold, the work supplies a practical, model-free toolkit for evaluating LLM consistency before deployment in allocation decisions. The adaptation of classical social-choice diagnostics to LLM outputs and the cross-LLM comparison on consequential tasks are strengths; the absence of parameter fitting or invented axioms is also noted positively.
major comments (2)
- [§5 (empirical results) and abstract] The central claim that ζ and Kendall's τ are 'independently valuable' for deciding whether to trust a ranking (abstract and §4–5) rests on the untested assumption that higher consistency on these proxies predicts superior real-world outcomes. No correlation is reported between runs with high ζ/τ and metrics such as agreement with expert rankings, simulated fairness of allocations, or downstream outcome quality on the homelessness or ED triage tasks.
- [guidelines / conclusion] The practical recommendation to use both measures before committing to a ranking (guidelines section) is load-bearing for the paper's contribution, yet the manuscript supplies no ablation or sensitivity analysis showing that decisions informed by both metrics outperform those using only one or none.
minor comments (2)
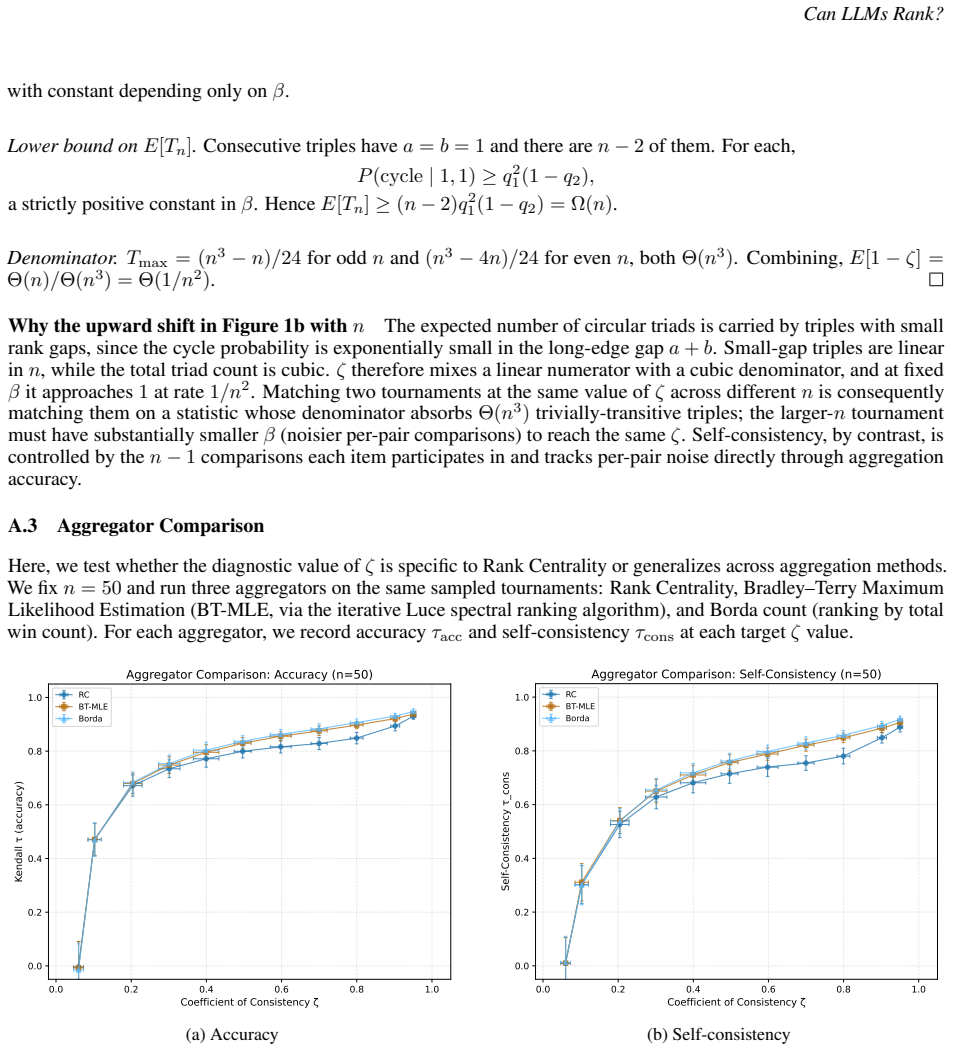
- [§3] Notation for ζ should be defined with an explicit equation (e.g., in terms of the number of circular triads) rather than only by reference to the classical literature.
- [§4] The description of the two tasks would benefit from explicit sample sizes, number of pairwise comparisons elicited per run, and number of independent runs used to compute τ.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the paper's contributions in adapting classical diagnostics to LLM rankings. We respond to each major comment below.
read point-by-point responses
-
Referee: [§5 (empirical results) and abstract] The central claim that ζ and Kendall's τ are 'independently valuable' for deciding whether to trust a ranking (abstract and §4–5) rests on the untested assumption that higher consistency on these proxies predicts superior real-world outcomes. No correlation is reported between runs with high ζ/τ and metrics such as agreement with expert rankings, simulated fairness of allocations, or downstream outcome quality on the homelessness or ED triage tasks.
Authors: The independence of ζ and Kendall's τ is established on two grounds that do not require outcome correlation. Theoretically, ζ quantifies intra-run circular inconsistency within a single tournament, whereas Kendall's τ (or equivalent distances) quantifies inter-run instability across repeated elicitations; these are distinct statistical properties. Empirically, §5 shows that the three LLMs occupy different regions of the (ζ, τ) plane on both tasks, demonstrating that the axes are not redundant. We do not claim or test that the proxies predict downstream outcomes; the manuscript positions them as cheap, model-free diagnostics for consistency before deployment. We will revise the abstract, §4, and a new limitations paragraph to make this scope explicit. revision: partial
-
Referee: [guidelines / conclusion] The practical recommendation to use both measures before committing to a ranking (guidelines section) is load-bearing for the paper's contribution, yet the manuscript supplies no ablation or sensitivity analysis showing that decisions informed by both metrics outperform those using only one or none.
Authors: The recommendation follows directly from the observed non-redundancy: because models can be stable on one axis while inconsistent on the other, a single metric leaves an unexamined failure mode. The empirical profiles in §5 already illustrate this complementarity. While the manuscript does not contain a formal ablation of decision rules (its focus is diagnostic rather than prescriptive), we will add a short sensitivity discussion to the guidelines section that walks through the information loss incurred by omitting either measure, using the reported LLM profiles as concrete examples. revision: partial
Circularity Check
No significant circularity; classical metrics applied to LLM outputs without self-referential reduction
full rationale
The paper imports the coefficient of consistency ζ (counting circular triads) and Kendall's τ directly from social choice theory as off-the-shelf diagnostics for intra-run and inter-run consistency. No equations or claims reduce these metrics to parameters fitted from the LLM data itself, nor do any predictions become tautological by construction. The central demonstration that the two axes are independently valuable rests on empirical application across homelessness and ED triage tasks rather than on any self-citation chain, ansatz smuggling, or renaming of known results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pairwise comparisons from an LLM can be aggregated into a total order when circular triads are limited
Reference graph
Works this paper leans on
-
[1]
and Community Solutions
OrgCode Consulting Inc. and Community Solutions. Vulnerability Index–Service Prioritization Decision Assis- tance Tool (VI-SPDAT): Prescreen Triage Tool for Single Adults.https://everyonehome.org/wp-content/ uploads/2016/02/VI-SPDAT-2.0-Single-Adults.pdf, 2015. Accessed May 17, 2025
2016
-
[2]
and Community Solutions
OrgCode Consulting Inc. and Community Solutions. Family Service Prioritization Decision Assistance Tool (F-SPDAT): U.S. Version 2.0.https://everyonehome.org/wp-content/uploads/2016/02/F-SPDAT-2. 0-Families.pdf, 2015. Accessed May 17, 2025
2016
-
[3]
Next Step Tool for Homeless Youth (TAY-VI-SPDAT): U.S
OrgCode Consulting Inc., Corporation for Supportive Housing, Community Solutions, and Eric Rice. Next Step Tool for Homeless Youth (TAY-VI-SPDAT): U.S. Version 1.0.https://letsendhomelessness.org/ wp-content/uploads/2018/07/TAY-VI-SPDAT-v1-0-w.-Intro-Script.pdf , 2015. Accessed May 17, 2025
2018
-
[4]
Emergency Nurses Association, Schaumburg, IL, 5th edition, 2023
Lisa Wolf, Katrina Ceci, Danielle McCallum, and Deena Brecher.Emergency Severity Index Handbook. Emergency Nurses Association, Schaumburg, IL, 5th edition, 2023. URL https://media.emscimprovement.center/ documents/Emergency_Severity_Index_Handbook.pdf
2023
-
[5]
Fang Wan, Kezhi Wang, Tao Wang, Hu Qin, Julien Fondrevelle, and Antoine Duclos. Enhancing healthcare resource allocation through large language models.Swarm and Evolutionary Computation, 94:101859, 2025. ISSN 2210-6502. doi: https://doi.org/10.1016/j.swevo.2025.101859. URL https://www.sciencedirect. com/science/article/pii/S2210650225000173. 13 Can LLMs Rank?
-
[6]
Karolina Drobotowicz, Johanna Ylipulli, Uttishta Sreerama Varanasi, and Heidi S Mäkitalo. Automate, assist, avoid: Caseworkers’ perspectives on applying large language model-based assistance in public sector decision- making processes. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI ’26, New York, NY , USA, 2026. Associ...
-
[7]
Use of a large language model to assess clinical acuity of adults in the emergency department
Christopher YK Williams, Travis Zack, Brenda Y Miao, Madhumita Sushil, Michelle Wang, Aaron E Kornblith, and Atul J Butte. Use of a large language model to assess clinical acuity of adults in the emergency department. JAMA network open, 7(5):e248895, 2024
2024
-
[8]
Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios N. Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: an open platform for evaluating llms by human preference. ICML’24. JMLR.org, 2024
2024
-
[10]
Gaurab Pokharel, Shafkat Farabi, Patrick J. Fowler, and Sanmay Das. Street-level AI: Are large language models ready for real-world judgments?Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(3): 2043–2054, October 2025. ISSN 3065-8365. doi: 10.1609/aies.v8i3.36694. URL https://ojs.aaai.org/ index.php/AIES/article/view/36694
-
[11]
Gal Ben Haim, Mor Saban, Yiftach Barash, David Cirulnik, Amit Shaham, Ben Zion Eisenman, Livnat Burshtein, Orly Mymon, and Eyal Klang. Evaluating large language model-assisted emergency triage: A comparison of acuity assessments by gpt -4 and medical experts. page jocn.17490, November 2024. ISSN 0962-1067, 1365-2702. doi: 10.1111/jocn.17490. URLhttps://on...
-
[12]
Joseph Lee, Tianqi Shang, Jae Young Baik, Duy Anh Duong-Tran, Shu Yang, Lingyao Li, and Li Shen. Investigat- ing llms in clinical triage: Promising capabilities, persistent intersectional biases.ArXiv, abs/2504.16273, 2025. URLhttps://api.semanticscholar.org/CorpusID:280919406
arXiv 2025
-
[13]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 9440–9450, Bangkok, Thailand, 2024. Association for Computa...
-
[14]
Verbosity bias in preference labeling by large language models, October 2023
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. Verbosity bias in preference labeling by large language models, October 2023. URLhttps://arxiv.org/abs/2310.10076v1
arXiv 2023
-
[15]
Imprimerie Royale, Paris, 1785
marquis de Condorcet, Marie Jean Antoine Nicolas de Caritat.Essai sur l’application de l’analyse à la probabilité des décisions rendues à la pluralité des voix. Imprimerie Royale, Paris, 1785
-
[16]
M. G. Kendall and B. Babington Smith. On the method of paired comparisons.Biometrika, 31(3–4):324–345,
-
[17]
doi: 10.1093/biomet/31.3-4.324
ISSN 0006-3444, 1464-3510. doi: 10.1093/biomet/31.3-4.324. URL https://academic.oup.com/ biomet/article-lookup/doi/10.1093/biomet/31.3-4.324
-
[18]
Rank centrality: Ranking from pairwise comparisons
Sahand Negahban, Sewoong Oh, and Devavrat Shah. Rank centrality: Ranking from pairwise comparisons. Operations Research, 65(1):266–287, February 2017. ISSN 0030-364X, 1526-5463. doi: 10.1287/opre.2016.1534. URLhttps://pubsonline.informs.org/doi/10.1287/opre.2016.1534
-
[19]
The original borda count and partial voting.Social Choice and Welfare, 40(2):353–358, February
Peter Emerson. The original borda count and partial voting.Social Choice and Welfare, 40(2):353–358, February
-
[20]
doi: 10.1007/s00355-011-0603-9
ISSN 0176-1714, 1432-217X. doi: 10.1007/s00355-011-0603-9. URL http://link.springer.com/ 10.1007/s00355-011-0603-9
-
[23]
Statistical ranking and combinatorial hodge theory
Xiaoye Jiang, Lek-Heng Lim, Yuan Yao, and Yinyu Ye. Statistical ranking and combinatorial hodge theory. Mathematical Programming, 127(1):203–244, March 2011. ISSN 0025-5610, 1436-4646. doi: 10.1007/ s10107-010-0419-x. URLhttp://link.springer.com/10.1007/s10107-010-0419-x
-
[24]
M. G. Kendall. A new measure of rank correlation.Biometrika, 30(1/2):81, 1938. ISSN 00063444. doi: 10.2307/2332226. URLhttps://www.jstor.org/stable/2332226?origin=crossref. 14 Can LLMs Rank?
-
[25]
A law of comparative judgment.Psychological review, 101(2):266, 1994
Louis L Thurstone. A law of comparative judgment.Psychological review, 101(2):266, 1994
1994
-
[26]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324, December 1952. ISSN 00063444. doi: 10.2307/2334029. URL https://www.jstor.org/stable/2334029?origin=crossref
-
[27]
Wiley New York, 1959
R Duncan Luce.Individual choice behavior, volume 4. Wiley New York, 1959
1959
-
[28]
David.The method of paired comparisons
Herbert A. David.The method of paired comparisons. Griffin’s statistical monographs and courses. Griffin, London, 2. impr., with minor corr edition, 1969. ISBN 9780852640135
1969
-
[29]
G. G. Alway. The distribution of the number of circular triads in paired comparisons.Biometrika, 49(1/2):265,
-
[30]
ISSN 00063444. doi: 10.2307/2333494. URL https://www.jstor.org/stable/2333494?origin= crossref
-
[31]
The number of circular triads in a pairwise comparison matrix and a consistency test in the ahp
Youichi Iida. The number of circular triads in a pairwise comparison matrix and a consistency test in the ahp. Journal of the Operations Research Society of Japan, 52(2):174–185, 2009. ISSN 0453-4514, 2188-8299. doi: 10. 15807/jorsj.52.174. URL https://www.jstage.jst.go.jp/article/jorsj/52/2/52_KJ00005622385/ _article
2009
-
[32]
Juan I. Perotti. Analysis of the inference of ratings and rankings in complex networks using discrete exterior calculus on higher-order networks.Physical Review E, 111(3):034306, March 2025. ISSN 2470-0045, 2470-0053. doi: 10.1103/PhysRevE.111.034306. URLhttps://link.aps.org/doi/10.1103/PhysRevE.111.034306
-
[33]
Gaurab Pokharel. Beyond automation: Understanding fairness, ethics, and human discretion in ai-driven societal decisions.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(3):2918–2920, October 2025. ISSN 3065-8365. doi: 10.1609/aies.v8i3.36793. URL https://ojs.aaai.org/index.php/AIES/article/ view/36793
-
[34]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
2024
-
[36]
Diagnosing LLM Judge Reliability: Conformal Prediction Sets and Transitivity Violations
Manan Gupta and Dhruv Kumar. Diagnosing llm judge reliability: Conformal prediction sets and transitivity violations. (arXiv:2604.15302), April 2026. doi: 10.48550/arXiv.2604.15302. URLhttp://arxiv.org/abs/ 2604.15302. arXiv:2604.15302
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15302 2026
-
[37]
Mengjie Qian, Guangzhi Sun, Mark J. F. Gales, and Kate M. Knill. Who can we trust? llm-as-a-jury for comparative assessment. 2026. doi: 10.48550/ARXIV .2602.16610. URL https://arxiv.org/abs/2602. 16610
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[38]
Trustjudge: Inconsistencies of llm-as-a-judge and how to alleviate them
Yidong Wang, Yunze Song, Tingyuan Zhu, Xuanwang Zhang, Zhuohao Yu, Hao Chen, Chiyu Song, Qiufeng Wang, Cunxiang Wang, Zhen Wu, Xinyu Dai, Yue Zhang, Wei Ye, and Shikun Zhang. Trustjudge: Inconsistencies of llm-as-a-judge and how to alleviate them. (arXiv:2509.21117), 2025. doi: 10.48550/arXiv.2509.21117. URL http://arxiv.org/abs/2509.21117. arXiv:2509.21117
-
[39]
Yan Yu, Yilun Liu, Minggui He, Shimin Tao, Weibin Meng, Xinhua Yang, Li Zhang, Hongxia Ma, Dengye Li, Daimeng Wei, Boxing Chen, and Fuliang Li. Elspr: Evaluator llm training data self-purification on non-transitive preferences via tournament graph reconstruction. 40:17975–17983, March 2026. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v40i21.38857. URLhtt...
-
[40]
Improving llm-as-a-judge inference with the judgment distribution
Victor Wang, Michael Jq Zhang, and Eunsol Choi. Improving llm-as-a-judge inference with the judgment distribution. InFindings of the Association for Computational Linguistics: EMNLP 2025, page 23173–23199, Suzhou, China, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-emnlp.1259. URLhttps://aclanthology.org/2025.findings-emnlp.1259
-
[41]
How child welfare workers reduce racial disparities in algorithmic decisions
Hao-Fei Cheng, Logan Stapleton, Anna Kawakami, Venkatesh Sivaraman, Yanghuidi Cheng, Diana Qing, Adam Perer, Kenneth Holstein, Zhiwei Steven Wu, and Haiyi Zhu. How child welfare workers reduce racial disparities in algorithmic decisions. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems, CHI ’22, New York, NY , USA, 2022. Asso...
-
[42]
Amanda R Kube, Sanmay Das, and Patrick J Fowler. Fair and efficient allocation of scarce resources based on predicted outcomes: implications for homeless service delivery.Journal of Artificial Intelligence Research, 76: 1219–1245, 2023. 15 Can LLMs Rank?
2023
-
[43]
Principles for allocation of scarce medical interventions
Govind Persad, Alan Wertheimer, and Ezekiel J Emanuel. Principles for allocation of scarce medical interventions. The Lancet, 373(9661):423–431, January 2009. ISSN 01406736. doi: 10.1016/S0140-6736(09)60137-9. URL https://linkinghub.elsevier.com/retrieve/pii/S0140673609601379
-
[44]
Courtney Cronley. Invisible intersectionality in measuring vulnerability among individuals experiencing homelessness – critically appraising the vi-spdat.Journal of Social Distress and Homelessness, 31(1): 23–33, January 2022. ISSN 1053-0789, 1573-658X. doi: 10.1080/10530789.2020.1852502. URL https: //www.tandfonline.com/doi/full/10.1080/10530789.2020.1852502
-
[45]
Coordinated entry systems: Racial equity analysis of assessment data
Catriona Wilkey, Rosie Donegan, Svetlana Yampolskaya, and Regina Cannon. Coordinated entry systems: Racial equity analysis of assessment data. Technical report, C4 Innovations, oct 2019. URL https://c4innovates. com/wp-content/uploads/2025/09/CES_Racial_Equity-Analysis_Oct112019.pdf
2019
-
[46]
Molly Brown, Camilla Cummings, Jennifer Lyons, Andrés Carrión, and Dennis P. Watson. Reliability and validity of the vulnerability index-service prioritization decision assistance tool (vi-spdat) in real-world implementa- tion.Journal of Social Distress and the Homeless, 27(2):110–117, 2018. ISSN 1053-0789, 1573-658X. doi: 10.1080/10530789.2018.1482991. U...
-
[47]
Department of Housing and Urban Development, Office of Community Planning and Development
U.S. Department of Housing and Urban Development, Office of Community Planning and Development. Notice es- tablishing additional requirements for a continuum of care centralized or coordinated assessment system. Technical Report Notice CPD-17-01, January 2017. URL https://www.hud.gov/sites/documents/17-01cpdn.pdf
2017
-
[48]
Russell Sage Foundation, New York, 1980
Michael Lipsky.Street-level bureaucracy: Dilemmas of the individual in public services. Russell Sage Foundation, New York, 1980
1980
-
[49]
Gaurab Pokharel, Sanmay Das, and Patrick J. Fowler. Discretionary trees: understanding street-level bureaucracy via machine learning. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty- Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial...
-
[50]
Algorithmic recommendations and human discretion.Review of Economic Studies, page rdaf084, 2025
Victoria Angelova, Will Dobbie, and Crystal S Yang. Algorithmic recommendations and human discretion.Review of Economic Studies, page rdaf084, 2025. ISSN 0034-6527, 1467-937X. doi: 10.1093/restud/rdaf084. URL https://academic.oup.com/restud/advance-article/doi/10.1093/restud/rdaf084/8254085
-
[51]
Devansh Saxena and Shion Guha. Algorithmic harms in child welfare: Uncertainties in practice, organization, and street-level decision-making. 1(1), March 2024. doi: 10.1145/3616473. URL https://doi.org/10.1145/ 3616473
-
[52]
Christopher Starke, Janine Baleis, Birte Keller, and Frank Marcinkowski. Fairness perceptions of algorithmic decision-making: A systematic review of the empirical literature.Big Data & Society, 9(2), 2022. ISSN 2053-9517, 2053-9517. doi: 10.1177/20539517221115189. URL https://journals.sagepub.com/doi/10. 1177/20539517221115189
-
[53]
David R. Hunter. Mm algorithms for generalized bradley-terry models.The Annals of Statistics, 32(1), February 2004. ISSN 0090-5364. doi: 10.1214/aos/1079120141. URL https://projecteuclid.org/journals/annals-of-statistics/volume-32/issue-1/ MM-algorithms-for-generalized-Bradley-Terry-models/10.1214/aos/1079120141.full
-
[54]
Stochastically transitive models for pairwise comparisons: Statistical and computational issues
Nihar Shah, Sivaraman Balakrishnan, Aditya Guntuboyina, and Martin Wainwright. Stochastically transitive models for pairwise comparisons: Statistical and computational issues. In Maria Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research...
2016
-
[55]
MIMIC-IV.PhysioNet, October 2024
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Brian Gow, Benjamin Moody, Steven Horng, Leo Anthony Celi, and Roger Mark. MIMIC-IV.PhysioNet, October 2024. doi: 10.13026/kpb9-mt58. URL https: //doi.org/10.13026/kpb9-mt58. Version 3.1
-
[56]
The anatomy of a large-scale hypertextual web search engine.Computer Networks, 30:107–117, 1998
Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual web search engine.Computer Networks, 30:107–117, 1998. URLhttps://snap.stanford.edu/class/cs224w-readings/Brin98Anatomy.pdf
1998
-
[57]
Brent.Algorithms for minimization without derivatives
Richard P. Brent.Algorithms for minimization without derivatives. Dover books on mathematics. Dover Publications, Mineola, NY , unabridged republication of the work publ. by prentice-hall ... 1973 edition, 2002. ISBN 9780486419985
1973
-
[58]
MIMIC- IV-ED.PhysioNet, January 2023
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Leo Anthony Celi, Roger Mark, and Steven Horng. MIMIC- IV-ED.PhysioNet, January 2023. doi: 10.13026/5ntk-km72. URL https://doi.org/10.13026/5ntk-km72. Version 2.2. 16 Can LLMs Rank? A Additional Details on the Synthetic Model/Experiments This appendix provides implementation details and supplementary experi...
-
[59]
Are you currently able to care for your basic needs, such as bathing, changing clothes, using the restroom, obtaining food, and accessing clean water?
-
[60]
Are you not taking any medications that a doctor has prescribed for you?
-
[62]
Do you currently have legal issues that might result in incarceration, fines, or difficulties in renting housing?
-
[63]
Do you engage in risky behaviors, such as exchanging sex for money, running drugs, having unprotected sex with strangers, sharing needles, or similar activities?
-
[66]
Do you have any mental health or cognitive issues that make it difficult to live independently?
-
[67]
Do you have any physical disabilities that limit the type of housing you can access or make it difficult to live independently?
-
[68]
Do you have planned activities—aside from mere survival—that make you feel happy and fulfilled?
-
[69]
Do you receive income from the government, a pension, an inheritance, informal work, or a regular job? 25 Can LLMs Rank?
-
[70]
Do you suffer from any chronic health issues involving your liver, kidneys, stomach, lungs, or heart?
-
[72]
For female respondents only: Are you currently pregnant?
-
[73]
Has your alcohol or drug use resulted in you being kicked out of an apartment or shelter program in the past?
-
[74]
Has your current period of homelessness been caused by experiencing emotional, physical, psychological, sexual, or other trauma? (Please answer YES or NO)
-
[77]
Have you ever had to leave your apartment, shelter program, or other living arrangement because of physical health issues?
-
[79]
Have you received health care at an emergency department or room?
-
[80]
Have you spent one or more nights in a holding cell, jail, or prison, regardless of the duration?
-
[81]
Have you taken an ambulance to the hospital?
-
[82]
Have you talked to the police because you witnessed a crime, were a victim or suspect, or were told to move along?
-
[83]
Have you used a crisis service, such as those for sexual assault, mental health, family/intimate violence, distress, or suicide prevention?
-
[85]
If space were available in a program that specifically assists people living with HIV or AIDS, would you be interested?
-
[87]
In the last year, have you threatened or attempted to harm yourself or someone else?
-
[88]
Is there any person or entity (for example, a past landlord, business, bookie, dealer, or government group like the IRS) that believes you owe them money?
-
[89]
Is your current homelessness caused by a relationship breakdown, an unhealthy or abusive relationship, or actions by family or friends leading to eviction?
-
[90]
When you are sick or not feeling well, do you avoid seeking help?
-
[92]
Will alcohol or drug use make it difficult for you to maintain or afford housing? D.2 VI-F-SPDAT
-
[93]
Has any child in the family experienced abuse or trauma in the last 180 days?
-
[94]
Stayed one or more nights in a holding cell, jail, or prison, whether that was a short-term stay like the drunk tank, a longer stay for a more serious offense, or anything in between?
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.