Behavior Prompting Policy: Demonstrations as Prompts for Manipulation
Pith reviewed 2026-06-30 05:18 UTC · model grok-4.3
The pith
Behavior prompting lets robots perform new manipulation tasks from one human demonstration without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an in-context visuomotor policy, trained on a diverse set of manipulation tasks, can translate a behavior prompt demonstration together with the current visual observation into robot actions for tasks that were never seen during training, thereby removing the requirement for task-specific fine-tuning.
What carries the argument
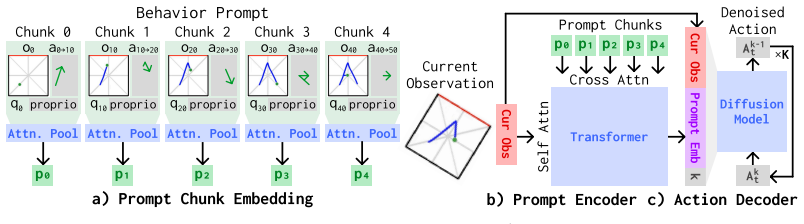
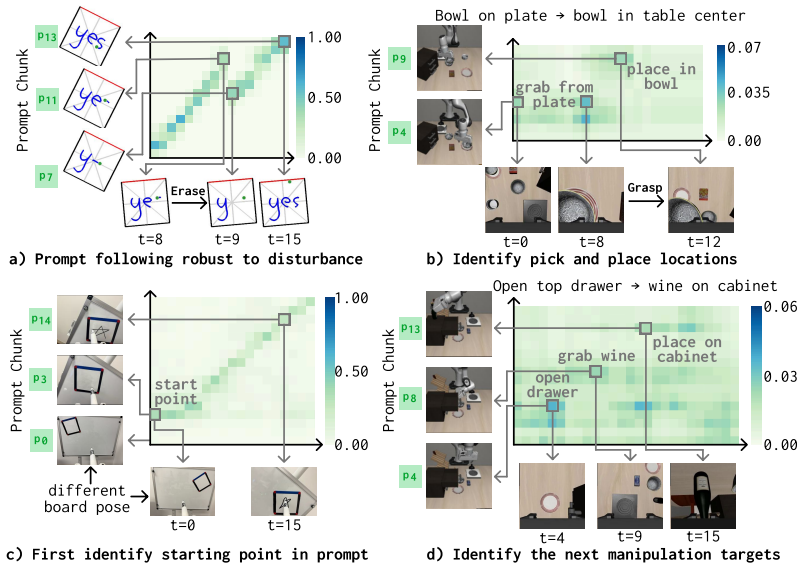
Behavior Prompting Policy (BPP), an in-context visuomotor architecture that conditions actions on a single behavior prompt demonstration.
If this is right
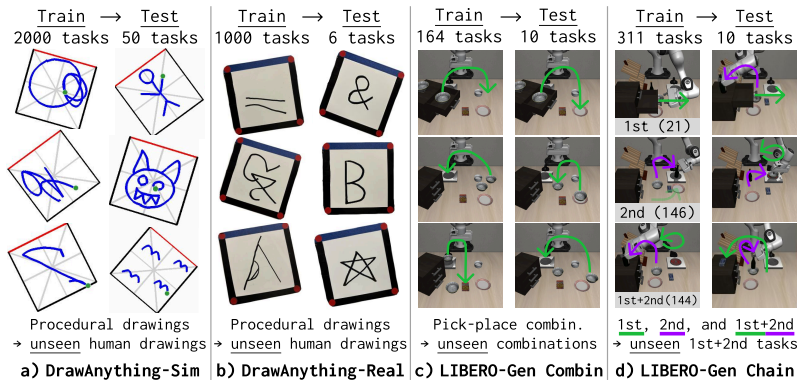
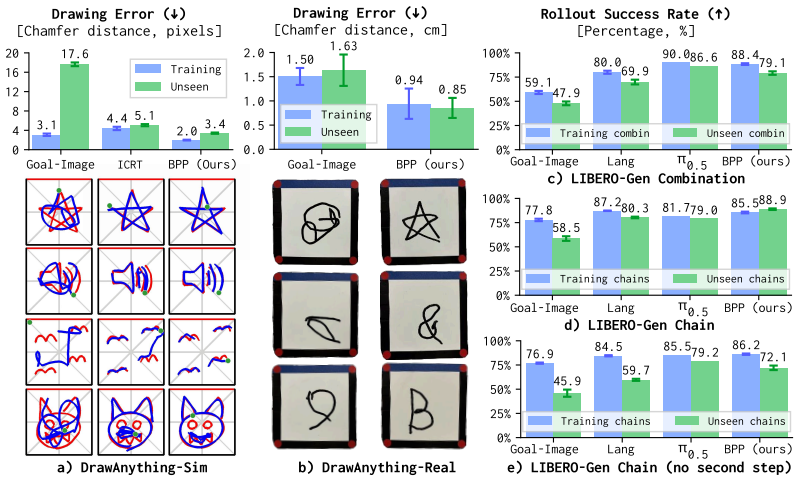
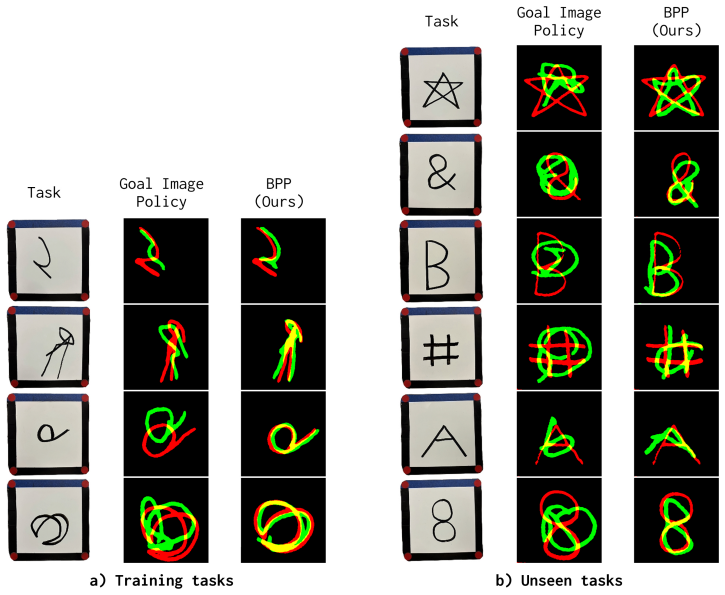
- Robots can complete novel drawing tasks using DrawAnything without additional training.
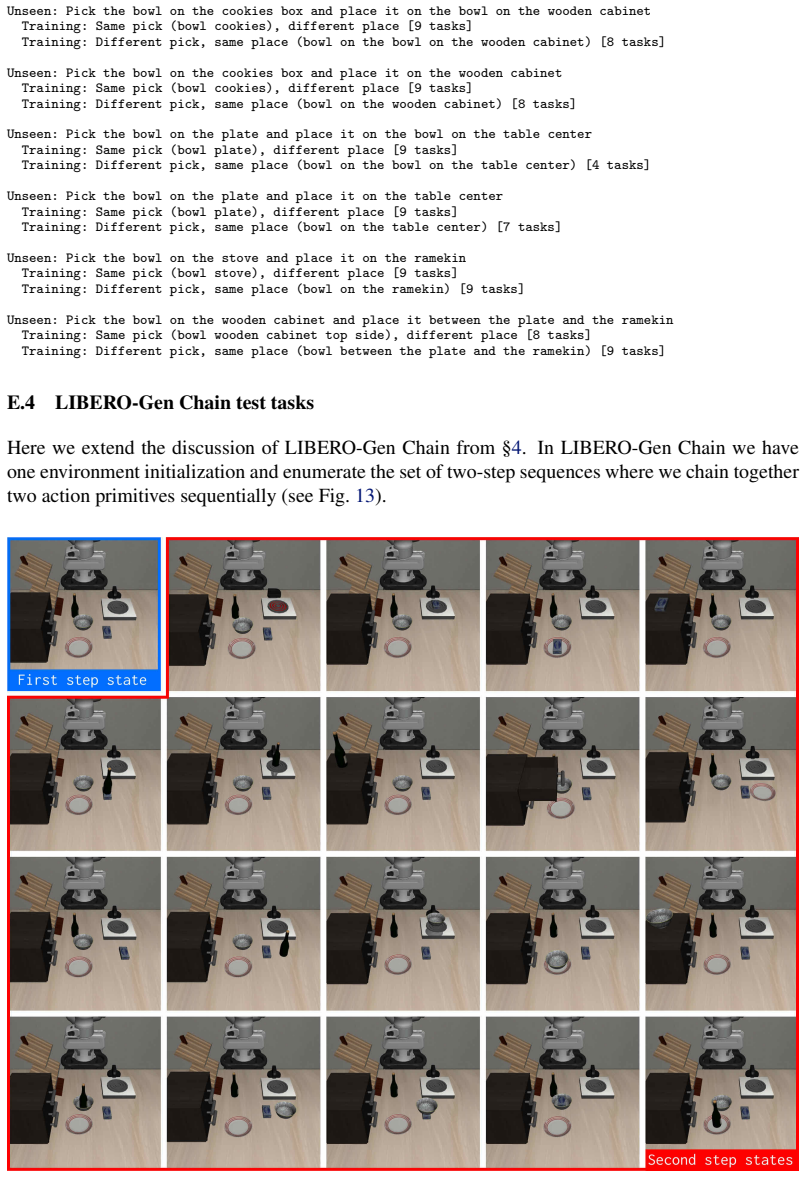
- Robots can handle unseen tabletop manipulation scenarios in LIBERO-Gen from a single prompt.
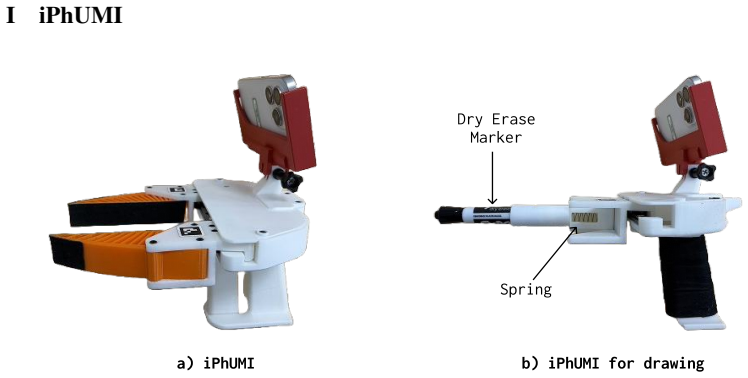
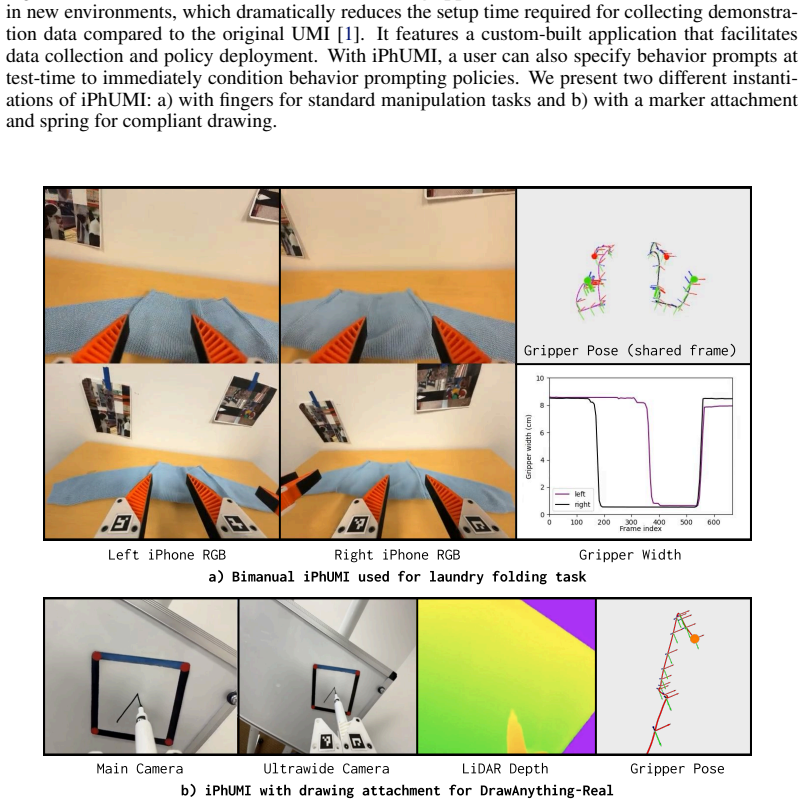
- Humans can define new robot capabilities at test time by providing one demonstration through iPhUMI.
- Task diversity during training is the dominant factor enabling prompting over other architectural choices.
Where Pith is reading between the lines
- The method could support iterative teaching loops where a human corrects or extends robot behavior through additional single demonstrations.
- Scaling the diversity of training tasks may allow the same policy to cover broader classes of manipulation without changes to the architecture.
- The interface could be adapted to let non-expert users program robots for household or industrial tasks in real time.
Load-bearing premise
Training on tasks collected via iPhUMI supplies enough variety for the in-context model to generalize correctly from one new prompt to an unseen task.
What would settle it
A controlled test in which the trained policy is given a behavior prompt for a held-out task and produces actions that fail to reproduce the demonstrated behavior on that task.
Figures






read the original abstract
We study behavior prompting, a paradigm that enables robots to perform new tasks at inference time given a single human demonstration, which we call a behavior prompt. To enable this capability, we present contributions in algorithm, data, and evaluation. For algorithm, we introduce Behavior Prompting Policy (BPP), an in-context visuomotor architecture that translates the behavior prompt and the current observation into robot actions. For data, we identify that task diversity is the primary driver of the prompting capability and introduce iPhUMI, a handheld manipulation interface for collecting diverse training data. For evaluation, we introduce DrawAnything and LIBERO-Gen to evaluate test-time adaptation to unseen drawing and tabletop manipulation tasks. We also demonstrate that iPhUMI serves as a practical interface for specifying behavior prompts at test time, enabling a human to command a robot via a single demonstration to complete known tasks or to define new robot capabilities. Altogether, behavior prompting provides a flexible and scalable way to teach robots new skills without the need for expensive fine-tuning. Our project website is located at https://behavior-prompting.github.io/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Behavior Prompting Policy (BPP), an in-context visuomotor architecture that maps a single human demonstration (behavior prompt) plus current observation to robot actions for test-time adaptation. It identifies task diversity as the primary driver of this capability and introduces iPhUMI, a handheld interface for collecting diverse manipulation data. New benchmarks DrawAnything and LIBERO-Gen are proposed to evaluate generalization to unseen drawing and tabletop tasks, with the claim that this enables flexible skill teaching without fine-tuning.
Significance. If the empirical results establish that iPhUMI task diversity is sufficient for in-context generalization on the new benchmarks, the work would offer a scalable alternative to fine-tuning in robot learning, with potential impact on imitation learning paradigms.
major comments (2)
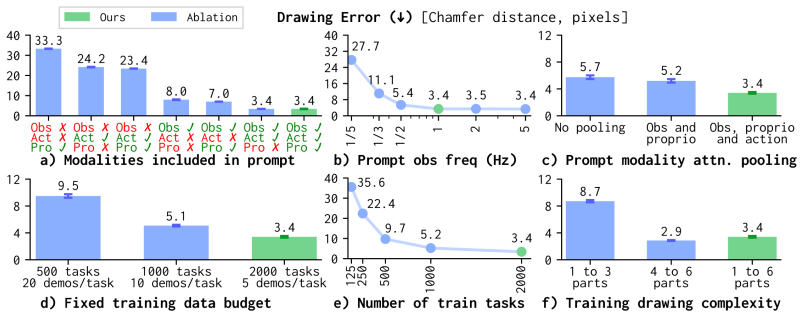
- [Abstract] Abstract: the assertion that 'task diversity is the primary driver of the prompting capability' is central to the contribution yet unsupported by any ablation (e.g., fixed model with varying task count or coverage) or quantitative comparison to data quality or model capacity; without such evidence the 'scalable without fine-tuning' claim does not follow.
- [Evaluation] Evaluation section (DrawAnything and LIBERO-Gen): no details on prompt encoding, attention mechanism, or error bars are referenced, making it impossible to verify whether observed generalization on unseen prompts is driven by the stated data diversity rather than other factors.
minor comments (1)
- [Abstract] Abstract: the phrase 'known tasks or to define new robot capabilities' is used without clarifying the distinction or providing separate metrics for each case.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript introducing Behavior Prompting Policy. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'task diversity is the primary driver of the prompting capability' is central to the contribution yet unsupported by any ablation (e.g., fixed model with varying task count or coverage) or quantitative comparison to data quality or model capacity; without such evidence the 'scalable without fine-tuning' claim does not follow.
Authors: We appreciate this point. Our identification of task diversity as the primary driver is based on comparative experiments in the paper, where training on the diverse iPhUMI dataset enables stronger in-context generalization than less diverse alternatives. However, we agree that dedicated ablations (e.g., varying task count with fixed model and data volume) would provide more direct evidence. In the revised manuscript we will add such an ablation study along with quantitative comparisons to data quality and model capacity to better support the claim. revision: yes
-
Referee: [Evaluation] Evaluation section (DrawAnything and LIBERO-Gen): no details on prompt encoding, attention mechanism, or error bars are referenced, making it impossible to verify whether observed generalization on unseen prompts is driven by the stated data diversity rather than other factors.
Authors: Thank you for highlighting this. The BPP architecture, including prompt encoding via the visuomotor backbone and the cross-attention mechanism for conditioning on the behavior prompt, is detailed in Section 3. To address the concern, we will expand the evaluation section to explicitly reference these components when discussing results and will include error bars (standard deviation across seeds) for all metrics on DrawAnything and LIBERO-Gen. revision: yes
Circularity Check
No circularity; claims rest on empirical evaluation of BPP and iPhUMI
full rationale
The paper introduces BPP as an in-context architecture, identifies task diversity via iPhUMI data collection, and evaluates on new benchmarks DrawAnything and LIBERO-Gen. The central claim that diversity enables test-time adaptation without fine-tuning is asserted as an empirical finding from the data and evaluations rather than derived from equations or self-referential definitions. No load-bearing self-citations, fitted inputs renamed as predictions, or reductions of outputs to inputs by construction appear in the provided text. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task diversity during training is the primary driver of prompting capability for unseen tasks.
invented entities (2)
-
Behavior Prompting Policy (BPP)
no independent evidence
-
iPhUMI
no independent evidence
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceed- ings of Robotics: Science and Systems (RSS), 2024. URLhttps://arxiv.org/abs/2402. 10329
2024
-
[2]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[3]
T. L. Team, J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, N. Kuppuswamy, K.-H. Lee, K. Liu, D. McConachie, I. McMahon, H. Nishimura, C. Phillips-Grafflin, C. Richter, P. Shah, K. Srinivasan, B. Wulfe, C. Xu, M. Zhang, A. Alspach, M. Angeles, K. Arora, V . C. Guizilini, A. Castro, D. C...
-
[4]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. BC-Z: Zero-shot task generalization with robotic imitation learning. In5th Annual Conference on Robot Learning, 2021. URLhttps://openreview.net/forum?id=8kbp23tSGYv
2021
-
[5]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
2025
-
[6]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[7]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[10]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
C. Finn, T. Yu, T. Zhang, P. Abbeel, and S. Levine. One-shot visual imitation learning via meta-learning. InConference on Robot Learning, pages 357–368. PMLR, 2017
2017
-
[12]
S. Calinon. A tutorial on task-parameterized movement learning and retrieval.Intelligent Service Robotics, 9(1):1–29, 2016. ISSN 1861-2776. doi:10.1007/s11370-015-0187-9
-
[13]
X. Zhang and A. Boularias. One-shot imitation learning with invariance matching for robotic manipulation.arXiv preprint arXiv:2405.13178, 2024
-
[14]
Valassakis, G
E. Valassakis, G. Papagiannis, N. D. Palo, and E. Johns. Demonstrate once, imitate immedi- ately (DOME): Learning visual servoing for one-shot imitation learning. InIEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), 2022
2022
-
[15]
Y . Duan, M. Andrychowicz, B. Stadie, O. Jonathan Ho, J. Schneider, I. Sutskever, P. Abbeel, and W. Zaremba. One-shot imitation learning.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[16]
Papagiannis, N
G. Papagiannis, N. D. Palo, P. Vitiello, and E. Johns. R+x: Retrieval and execution from ev- eryday human videos. InIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[17]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. VIMA: General robot manipulation with multimodal prompts. InFortieth Inter- national Conference on Machine Learning, 2023
2023
-
[18]
V . Jain, M. Attarian, N. J. Joshi, A. Wahid, D. Driess, Q. Vuong, P. R. Sanketi, P. Sermanet, S. Welker, C. Chan, I. Gilitschenski, Y . Bisk, and D. Dwibedi. Vid2Robot: End-to-end video-conditioned policy learning with cross-attention transformers. InProceedings of (RSS) Robotics Science and Systems. Proceedings of Robotics: Science and Systems, May 2024
2024
-
[19]
Z. Mandi, F. Liu, K. Lee, and P. Abbeel. Towards more generalizable one-shot visual imitation learning. In2022 International Conference on Robotics and Automation (ICRA), pages 2434– 2444, 2022. doi:10.1109/ICRA46639.2022.9812450. 10
-
[20]
M. Xu, Y . Shen, S. Zhang, Y . Lu, D. Zhao, B. J. Tenenbaum, and C. Gan. Prompting decision transformer for few-shot policy generalization. InThirty-ninth International Conference on Machine Learning, 2022
2022
-
[21]
R. Shah, S. Liu, Q. Wang, Z. Jiang, S. Kumar, M. Seo, R. Mart ´ın-Mart´ın, and Y . Zhu. Mim- icDroid: In-context learning for humanoid manipulation from human play videos.2026 IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[22]
K. Dreczkowski, P. Vitiello, V . V osylius, and E. Johns. Learning a thousand tasks in a day. Science Robotics, 10(108):eadv7594, 2025. doi:10.1126/scirobotics.adv7594. URLhttps: //www.science.org/doi/abs/10.1126/scirobotics.adv7594
- [23]
-
[24]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. FiLM: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[25]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion Policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[26]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. LIBERO-Plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. LIBERO-PRO: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. LoRA: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[29]
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations, volume 2024, pages 21875–21895, 2024
2024
-
[30]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
2021
-
[31]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021
2021
-
[32]
Torne, A
M. Torne, A. Tang, Y . Liu, and C. Finn. Learning long-context diffusion policies via past-token prediction. In9th Annual Conference on Robot Learning, 2025
2025
- [33]
-
[34]
Etukuru, N
H. Etukuru, N. Naka, Z. Hu, S. Lee, J. Mehu, A. Edsinger, C. Paxton, S. Chintala, L. Pinto, and N. M. M. Shafiullah. Robot utility models: General policies for zero-shot deployment in new environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8275–8283. IEEE, 2025. 11
2025
-
[35]
X. Xu, J. Park, H. Zhang, E. Cousineau, A. Bhat, J. Barreiros, D. Wang, J. Bohg, and S. Song. HoMMI: Learning whole-body mobile manipulation from human demonstrations. arXiv preprint arXiv:2603.03243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Z. Liu, C. Chi, E. Cousineau, N. Kuppuswamy, B. Burchfiel, and S. Song. Maniwav: Learning robot manipulation from in-the-wild audio-visual data. InConference on Robot Learning, pages 947–962. PMLR, 2025
2025
-
[38]
URLhttps://arxiv.org/abs/2604.18933. 12 Appendix A Case Study: Laundry Folding Behavior prompts are a substantially more complex task representation than fixed-length language embeddings, and we want to understand whether this complexity poses challenges when we have lowtask diversity. To study this, we perform a case study with three sweater folding task...
work page internal anchor Pith review Pith/arXiv arXiv 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.