Poller: Are LLMs Suitable for Evaluating the Poetry Understanding Task?
Pith reviewed 2026-06-30 05:57 UTC · model grok-4.3
The pith
Making LLMs role-play as the poem's author cuts their evaluation error against humans by up to 94 percent on key poetry dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
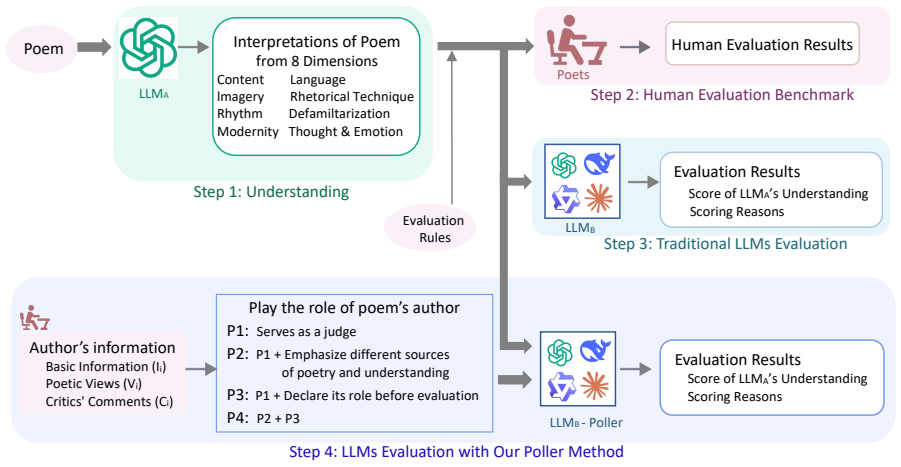
Poller requires LLMs to play the role of a poem's author with detailed information, thereby emulating human evaluation and judgment by adopting the poet's perspective. When used to score poem interpretations across eight specialized dimensions, Poller-based LLMs reduce evaluation error relative to humans compared with conventional methods, reaching 94.55 percent error reduction for rhetorical techniques and 89.53 percent for defamiliarization. These gains hold across multiple LLMs and are not achieved by direct prompting alone.
What carries the argument
The Poller method, in which an LLM is instructed to adopt the perspective and detailed knowledge of the poem's author before judging interpretations.
If this is right
- Automated scoring of poetry understanding becomes reliable enough for large-scale use without constant human oversight.
- Error reductions are largest on dimensions such as rhetorical techniques and defamiliarization that are hard for standard LLM prompts.
- The same role-play technique produces consistent gains when applied to different underlying LLMs.
- The method supplies a practical route to automated evaluation for other poetry-related tasks.
- It narrows the gap between fast machine scoring and the reliability previously available only from human experts.
Where Pith is reading between the lines
- Similar author-perspective prompting could be tested on evaluation of other creative or subjective domains such as fiction or visual art.
- If the gains come from the added context and persona, the technique might also improve LLM performance on tasks that require expert viewpoint alignment.
- The eight-dimension breakdown offers a template that could be reused to diagnose where other automated evaluators still diverge from humans.
Load-bearing premise
That requiring an LLM to pretend it is the poem's author with added details will make its judgments match how humans evaluate poetry.
What would settle it
Human raters scoring the same set of poem interpretations find that Poller LLM outputs agree with them no more often than outputs from ordinary direct-prompt LLMs.
Figures

read the original abstract
Traditional automatic evaluation methods have been shown to be unsuitable for modern Chinese poetry because of the distinct nature of this literary genre. Human evaluation remains reliable, but is expensive and not applicable to large-scale data. In this paper, we propose Poller (Poetry LLM Evaluator), a novel method leveraging large language models (LLMs) to evaluate the poetry understanding task. Specifically, our method requires LLMs to play the role of a poem's author with detailed information, thereby emulating human evaluation and judgment by adopting the poet's perspective. We conducted comprehensive experiments on multiple LLMs, evaluating the interpretations of poems across eight specialized dimensions. Experimental results demonstrate that our method effectively reduces the evaluation error between LLMs and humans. Especially for specific dimension evaluation, Poller-based LLMs achieve a 94.55% and 89.53% error reduction for rhetorical techniques and defamiliarization, respectively, compared to baseline methods. These performances are unattainable by conventional LLM evaluation methods. Experimental results from multiple LLMs across various dimensions validate the efficacy of our method. This work bridges the gap between automated efficiency and human expertise, establishing a foundation for automated evaluation in poetry-related tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Poller, a prompting method in which LLMs are instructed to role-play as the author of a modern Chinese poem (with detailed information supplied) in order to evaluate poetry understanding across eight dimensions. It claims that this perspective-adoption technique emulates human judgment and produces large reductions in evaluation error relative to baseline LLM prompting methods, with headline figures of 94.55% error reduction on rhetorical techniques and 89.53% on defamiliarization.
Significance. If the quantitative claims can be substantiated with full experimental details, ablations, and statistical controls, the work would provide a practical route to scalable, automated evaluation of poetry that narrows the gap with human expertise. The absence of those details in the current manuscript, however, prevents any assessment of whether the reported gains are robust or reproducible.
major comments (2)
- [Abstract] Abstract: the headline error-reduction figures (94.55% for rhetorical techniques, 89.53% for defamiliarization) are stated without any definition of the error metric, description of the baseline methods, dataset size or selection criteria, statistical tests, or inter-annotator agreement. These omissions make the central quantitative claim impossible to evaluate.
- [Method / Experiments] Method description: the paper attributes performance gains to the explicit instruction that the LLM “play the role of a poem’s author,” yet no ablation is reported that holds the detailed information and output format fixed while removing only the author-role framing. Without this control, it is impossible to determine whether the claimed emulation of human perspective is the operative mechanism or whether any richer prompt would suffice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that will make the experimental claims fully evaluable while preserving the core contribution of the perspective-adoption technique.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline error-reduction figures (94.55% for rhetorical techniques, 89.53% for defamiliarization) are stated without any definition of the error metric, description of the baseline methods, dataset size or selection criteria, statistical tests, or inter-annotator agreement. These omissions make the central quantitative claim impossible to evaluate.
Authors: The abstract is written for brevity and therefore omits these supporting details. The full definitions (error as mean absolute deviation from human scores, baselines as standard zero-shot and few-shot prompting, dataset of 50 poems selected for stylistic diversity, paired t-tests, and inter-annotator kappa) appear in Section 4 and the appendix. To resolve the evaluability concern we will revise the abstract to include concise definitions of the error metric and baseline together with explicit pointers to the experimental section. revision: yes
-
Referee: [Method / Experiments] Method description: the paper attributes performance gains to the explicit instruction that the LLM “play the role of a poem’s author,” yet no ablation is reported that holds the detailed information and output format fixed while removing only the author-role framing. Without this control, it is impossible to determine whether the claimed emulation of human perspective is the operative mechanism or whether any richer prompt would suffice.
Authors: We agree that the current experiments compare Poller against standard prompting baselines but do not isolate the author-role instruction while holding poem information and output format constant. This specific ablation is necessary to substantiate the mechanism. We will run the control experiment on the same models and dataset and report the results in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical evaluation against external human judgments
full rationale
The paper introduces Poller as a prompting technique requiring LLMs to role-play as poem authors with provided details, then reports error reductions versus baselines on eight dimensions when scored against independent human annotations. No equations, fitted parameters, self-definitional quantities, or load-bearing self-citations appear in the derivation. The central performance claims (e.g., 94.55% and 89.53% error reductions) are computed directly from comparisons to external human data rather than reducing to the method's own inputs by construction. The prompting assumption is stated explicitly but does not create a circular reduction; it is tested empirically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can emulate human poetic judgment by role-playing as the poem's author when supplied with detailed information
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Manex Agirrezabal and Hugo Gon c alo Oliveira. 2024. https://computationalcreativity.net/iccc24/papers/ICCC24_paper_164.pdf Zero-shot metrical poetry generation with open language models: a quantitative analysis
2024
-
[3]
Manex Agirrezabal, Hugo Gon c alo Oliveira, and Aitor Ormazabal. 2023. https://link.springer.com/chapter/10.1007/978-3-031-49011-8_1 Erato: Automatizing poetry evaluation . In EPIA Conference on Artificial Intelligence, pages 3--14. Springer
-
[4]
D Antar. 2023. https://www.naturalspublishing.com/files/published/4i2xq2xki6j949.pdf The effectiveness of using chatgpt4 in creative writing in arabic: Poetry and short story as a model
2023
-
[5]
Anthropic. 2024. Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet
2024
- [6]
-
[7]
Yonatan Bitton, Hritik Bansal, Jack Hessel, Rulin Shao, Wanrong Zhu, Anas Awadalla, Josh Gardner, Rohan Taori, and Ludwig Schmidt. 2023. https://arxiv.org/abs/2308.06595 Visit-bench: A benchmark for vision-language instruction following inspired by real-world use . arXiv preprint arXiv:2308.06595
-
[8]
J. Brodsky. 1999. https://xueshu.baidu.com/usercenter/paper/show?paperid=6016a252f9b81af0ff0066c8705b4b04&site=xueshu_se Witness and Pleasure . witness and pleasure
1999
- [9]
-
[10]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. https://arxiv.org/abs/2308.07201 Chateval: Towards better llm-based evaluators through multi-agent debate . arXiv preprint arXiv:2308.07201
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Yina Chang. 2012. https://xueshu.baidu.com/usercenter/paper/show?paperid=844eaeb5006889b6ccf1ad1e0f190d2a&site=xueshu_se&hitarticle=1 A brief discussion on cutting-edge issues in contemporary poetry research . Northern Literature Monthly
2012
-
[12]
Bo Cheng. 2005. https://xueshu.baidu.com/usercenter/paper/show?paperid=ee939646fe123175a9e8593425ea0a59&site=xueshu_se The special ecology of modernity in new poetry--a study on the poets of southwest associated university . Journal of the School of Liberal Arts of Nanjing Normal University, (4):69--76
2005
-
[13]
Cheng-Han Chiang and Hung-Yi Lee. 2023 a . https://aclanthology.org/2023.acl-long.870/ Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607--15631
2023
-
[14]
Cheng-Han Chiang and Hung-yi Lee. 2023 b . https://aclanthology.org/2023.findings-emnlp.599/ A closer look into using large language models for automatic evaluation . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 8928--8942. Association for Computational Linguistics
2023
- [15]
-
[16]
John Crowe Ransom. 1938. The world’s body (baton rouge)
1938
- [17]
- [18]
-
[19]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning . arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
James Hutson and Ana Schnellmann. 2023. https://digitalcommons.lindenwood.edu/faculty-research-papers/462/ The poetry of prompts: the collaborative role of generative artificial intelligence in the creation of poetry and the anxiety of machine influence . Global Journal of Computer Science and Technology, 23(D1):1--14
2023
-
[21]
unspeakable
Yongjun Jiang. 2012. https://xueshu.baidu.com/usercenter/paper/show?paperid=5ddd72446ed8c39a437c97269e42c242&site=xueshu_se&hitarticle=1 The "unspeakable" in the perceptual effect of poetry - an analysis of the "unspeakable" meaning of feeling . foreign language, 28(1):4
2012
- [22]
-
[23]
Tian Lan, Jiang Li, Yemin Wang, Xu Liu, Xiangdong Su, and Guanglai Gao. 2025 a . https://aclanthology.org/2025.emnlp-main.105/ F B ench: An open-ended fairness evaluation benchmark for LLM s with factuality considerations . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2031--2046. Association for Computat...
2025
-
[24]
Tian Lan, Xiangdong Su, Xu Liu, Ruirui Wang, Ke Chang, Jiang Li, and Guanglai Gao. 2025 b . https://aclanthology.org/2025.findings-acl.313/ M c BE : A multi-task C hinese bias evaluation benchmark for large language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 6033--6056
2025
-
[25]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. https://arxiv.org/abs/2412.05579 Llms-as-judges: a comprehensive survey on llm-based evaluation methods . arXiv preprint arXiv:2412.05579
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Jiang Li, Tian Lan, Shanshan Wang, Dongxing Zhang, Dianqing Lin, Guanglai Gao, Derek F Wong, and Xiangdong Su. 2026. https://arxiv.org/abs/2604.10101 Who wrote this line? evaluating the detection of llm-generated classical chinese poetry . arXiv preprint arXiv:2604.10101
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Dianqing Lin, Aruukhan, Hongxu Hou, Shuo Sun, Wei Chen, Yichen Yang, and Guodong Shi. 2025. https://aclanthology.org/2025.emnlp-main.1179/ Can large language models translate unseen languages in underrepresented scripts? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23137--23150. Association for Computati...
2025
- [28]
-
[29]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. https://aclanthology.org/2023.emnlp-main.153/ G -eval: NLG evaluation using gpt-4 with better human alignment . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511--2522. Association for Computational Linguistics
2023
-
[30]
Yiqi Liu, Nafise Sadat Moosavi, and Chenghua Lin. 2024. https://aclanthology.org/2024.findings-acl.753.pdf Llms as narcissistic evaluators: When ego inflates evaluation scores . In Findings of the Association for Computational Linguistics: ACL 2024, pages 12688--12701
2024
-
[31]
Ruli Manurung, Graeme Ritchie, and Henry Thompson. 2012. Using genetic algorithms to create meaningful poetic text. Journal of Experimental & Theoretical Artificial Intelligence, 24(1):43--64
2012
-
[32]
Brian McGrath. 2018. https://muse.jhu.edu/pub/1/article/707577/summary Understating poetry . New Literary History, 49(3):289--308
2018
-
[33]
Jekaterina Novikova, Ond r ej Du s ek, Amanda Cercas Curry, and Verena Rieser. 2017. https://aclanthology.org/D17-1238/ Why we need new evaluation metrics for NLG . In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2241--2252. Association for Computational Linguistics
2017
-
[34]
Arjun Panickssery, Samuel R Bowman, and Shi Feng. 2024. https://arxiv.org/abs/2404.13076 Llm evaluators recognize and favor their own generations . arXiv preprint arXiv:2404.13076
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://aclanthology.org/P02-1040/ B leu: a method for automatic evaluation of machine translation . In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311--318. Association for Computational Linguistics
2002
-
[36]
Robert B Pierce. 2003. https://muse.jhu.edu/pub/1/article/45263/summary Defining" poetry" . Philosophy and Literature, 27(1):151--163
2003
-
[37]
Maurilio De Araujo Possi, Alcione De Paiva Oliveira, Alexandra Moreira, and Lucas Mucida Costa. 2023. https://ieeexplore.ieee.org/document/10236873 Carmen: A method for automatic evaluation of poems . In 2023 5th International Conference on Natural Language Processing (ICNLP), pages 244--247. IEEE
-
[38]
Eshrag Ali Refaee. 2023. https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10273934 Okaz: A deep-learning-based system for automatic arabic poem generation . In 2023 3rd International Conference on Computing and Information Technology (ICCIT), pages 396--403. IEEE
2023
- [39]
-
[40]
Hanwen Shen, Ting Ying, Jiajie Lu, and Shanshan Wang. 2026. https://arxiv.org/abs/2603.13683 Preconditioned test-time adaptation for out-of-distribution debiasing in narrative generation . arXiv preprint arXiv:2603.13683
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Brian Phillips Skerratt. 2013. https://dash.harvard.edu/handle/1/11181112 Form and Transformation in Modern Chinese Poetry and Poetics . Ph.D. thesis
2013
-
[42]
Hwanjun Song, Hang Su, Igor Shalyminov, Jason Cai, and Saab Mansour. 2024. https://aclanthology.org/2024.acl-long.51.pdf Finesure: Fine-grained summarization evaluation using llms . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 906--922
2024
-
[43]
Wong, Runzhe Zhan, Lidia S
Wai Lei Song, Haoyun Xu, Derek F. Wong, Runzhe Zhan, Lidia S. Chao, and Shanshan Wang. 2023. https://aclanthology.org/2023.mtsummit-research.27/ Towards zero-shot multilingual poetry translation . In Proceedings of Machine Translation Summit XIX, Vol. 1: Research Track, pages 324--335. Asia-Pacific Association for Machine Translation
2023
-
[44]
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. 2019. http://cips-cl.org/static/anthology/CCL-2019/CCL-19-141.pdf How to fine-tune bert for text classification? In Chinese computational linguistics: 18th China national conference, CCL 2019, Kunming, China, October 18--20, 2019, proceedings 18, pages 194--206. Springer
2019
-
[45]
Allen Tate. 1940. https://www.jstor.org/stable/805931 Understanding modern poetry . The English Journal, 29(4):263--274
1940
-
[46]
Maria Virvou, George A Tsihrintzis, Dionisios N Sotiropouloss, Konstantina Chrysafiadi, Evangelos Sakkopoulos, and Evangelia-Aikaterini Tsichrintzi. 2023. https://ieeexplore.ieee.org/abstract/document/10345878 Chatgpt in artificial intelligence-empowered e-learning for cultural heritage: The case of lyrics and poems . In 2023 14th International Conference...
-
[47]
Melanie Walsh, Anna Preus, and Maria Antoniak. 2024. https://aclanthology.org/2024.findings-emnlp.914.pdf Sonnet or not, bot? poetry evaluation for large models and datasets . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 15568--15603
2024
-
[48]
Guangming Wang. 1998. https://xueshu.baidu.com/usercenter/paper/show?paperid=0c37602f4dfd6cfa4ce725d2ef5207b3&site=xueshu_se Reflections on the ontology of new chinese poetry . Chinese Social Sciences, (4):16
1998
-
[49]
Jiaan Wang, Yunlong Liang, Fandong Meng, Zengkui Sun, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023 a . https://aclanthology.org/2023.newsum-1.1/ Is C hat GPT a good NLG evaluator? a preliminary study . In Proceedings of the 4th New Frontiers in Summarization Workshop, pages 1--11. Association for Computational Linguistics
2023
-
[50]
Mi Wang. 2019. https://xueshu.baidu.com/usercenter/paper/show?paperid=147n0pc0yu7m0030622r04t0xx370763&site=xueshu_se&hitarticle=1 Study on the relationship between external form and internal emotion in the rhythm of new poetry (1917-1949) . Ph.D. thesis, Sichuan Academy of Social Sciences
2019
-
[51]
Shanshan Wang, Derek Wong, Jingming Yao, and Lidia Chao. 2024. https://aclanthology.org/2024.acl-long.756/ What is the best way for chatgpt to translate poetry? In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14025--14043
2024
-
[52]
Wong, Jingming Yao, and Lidia S
Shanshan Wang, Derek F. Wong, Jingming Yao, and Lidia S. Chao. 2026. https://aclanthology.org/2026.findings-eacl.216/ Can C hat GPT really understand M odern C hinese poetry? In Findings of the A ssociation for C omputational L inguistics: EACL 2026 , pages 4152--4162. Association for Computational Linguistics
2026
-
[53]
Wong, Jingming Yao, and Lidia S
Shanshan Wang, Junchao Wu, Fengying Ye, Derek F. Wong, Jingming Yao, and Lidia S. Chao. 2025. https://aclanthology.org/2025.findings-emnlp.507/ Benchmarking the detection of LLM s-generated M odern C hinese poetry . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 9533--9552. Association for Computational Linguistics
2025
-
[54]
Shuting Wang. 2006 a . https://xueshu.baidu.com/usercenter/paper/show?paperid=1a5b02v0s6520mr0as4d0pn0u2589500&site=xueshu_se&hitarticle=1 Giving shape to emotion: The theory and practice of rhythm and imagery in new poetry (1917-1937) . World Literature Review
2006
-
[55]
Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, and 1 others. 2023 b . https://arxiv.org/abs/2306.05087 Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization . arXiv preprint arXiv:2306.05087
-
[56]
Yuchun Wang. 2006 b . https://xueshu.baidu.com/usercenter/paper/show?paperid=a157d4f289f3f209d5f03f94d90315c8 Moruo guo's view on literary translation . Moruo Guo Journal, page 5
2006
-
[57]
Yunshu Xi. 2019. https://xueshu.baidu.com/usercenter/paper/show?paperid=1s640tu0es6r0xh0q03k08t007679271&site=xueshu_se&hitarticle=1 Two characteristics of new poetry language—talking about the creation of new poetry part three . Masterpiece Appreciation: Appreciation Edition (First Decade), (8):6
2019
- [58]
-
[59]
Rui Yan. 2016. https://www.ijcai.org/Proceedings/16/Papers/319.pdf I, poet:automatic poetry composition through recurrent neural networks with iterative polishing schema . In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, page 2238–2244
2016
-
[60]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, and 1 others. 2024. https://doi.org/10.48550/arXiv.2412.15115 Qwen2. 5 technical report . arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[61]
Fengying Ye, Shanshan Wang, Lidia S Chao, and Derek F Wong. 2025. https://arxiv.org/abs/2510.04120 Unveiling llms' metaphorical understanding: Exploring conceptual irrelevance, context leveraging and syntactic influence . arXiv preprint arXiv:2510.04120
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Xiaoyuan Yi, Maosong Sun, Ruoyu Li, and Wenhao Li. 2018. https://aclanthology.org/D18-1353.pdf Automatic poetry generation with mutual reinforcement learning . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3143--3153. Association for Computational Linguistics
2018
-
[63]
Haizhang Yu. 2001. https://xueshu.baidu.com/usercenter/paper/show?paperid=e92a00351f386630fb0579dc99c4f352&site=xueshu_se About the changes and analysis of new poetry expressions . writing, 000(011):3--5
2001
-
[64]
poetic" - on the traces and limits of
Di Zang. 2007. The literary politics of "poetic" - on the traces and limits of "poetic" in the practice of chinese new poetry. Comments on New Poetry, pages 13, 15–16, 19, 30
2007
-
[65]
interpretation of poetics
Taozhou Zhang. 2022. https://xueshu.baidu.com/usercenter/paper/show?paperid=1s5k0xh0ku4t00a0n6630c30ff693375&site=xueshu_se&hitarticle=1 Problems in reading new poetry from the perspective of "interpretation of poetics" . literary research, (3):13
2022
-
[66]
Xingxing Zhang and Mirella Lapata. 2014. https://aclanthology.org/D14-1074/ Chinese poetry generation with recurrent neural networks . In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 670--680
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.