Why Do Few-Step Text Latents Fail When Image Latents Work? Non-Commitment at Sharp Categorical Readouts
Pith reviewed 2026-07-01 07:03 UTC · model grok-4.3
The pith
A smooth deterministic map cannot resolve discrete branch choices before a sharp categorical readout, so few-step failure on text latents is governed by decoder sharpness rather than transport accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
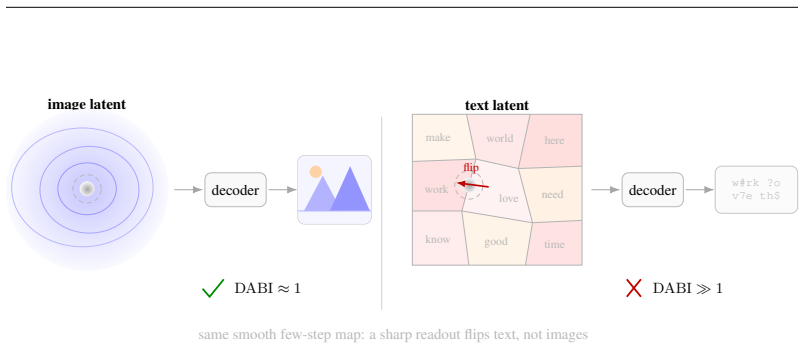
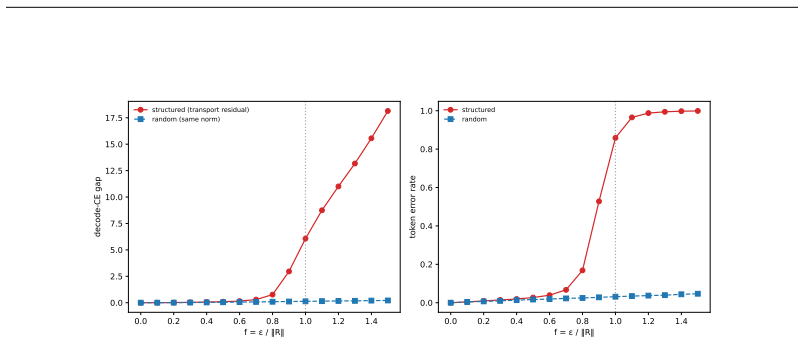
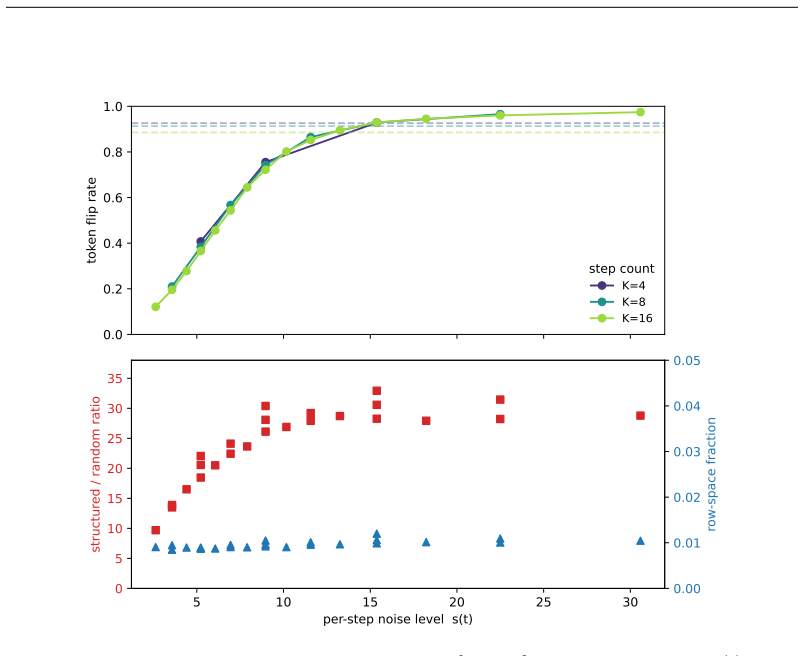
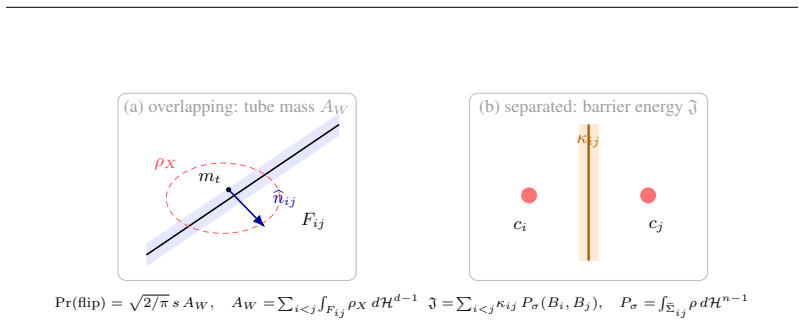
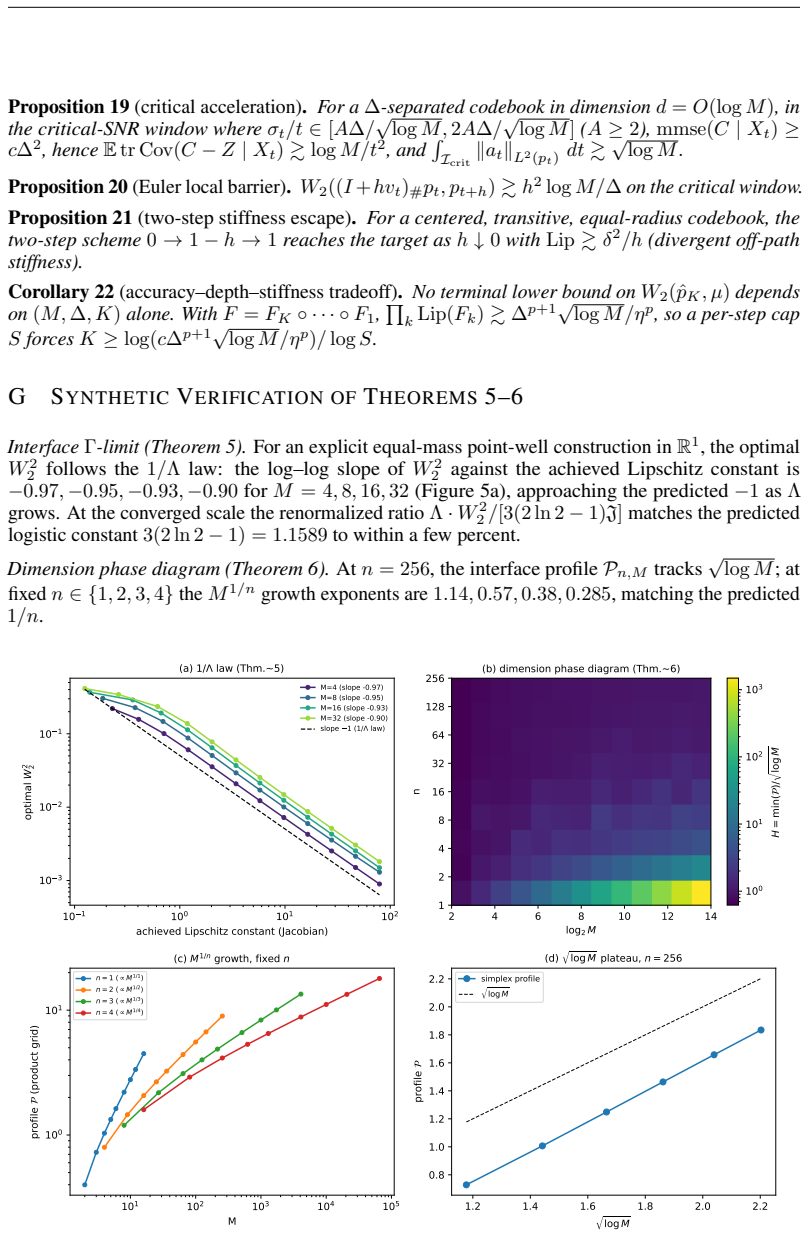
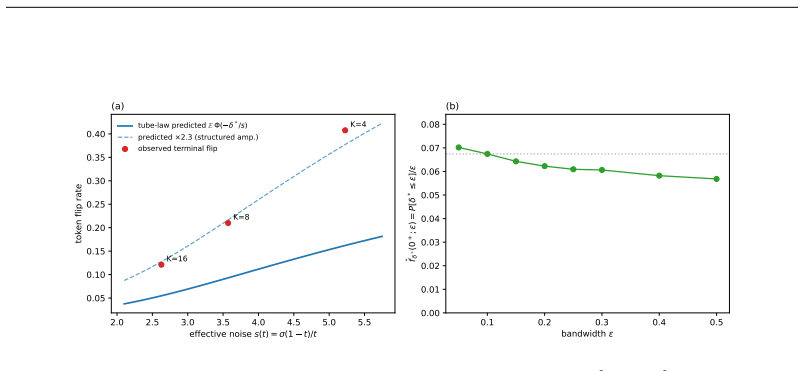
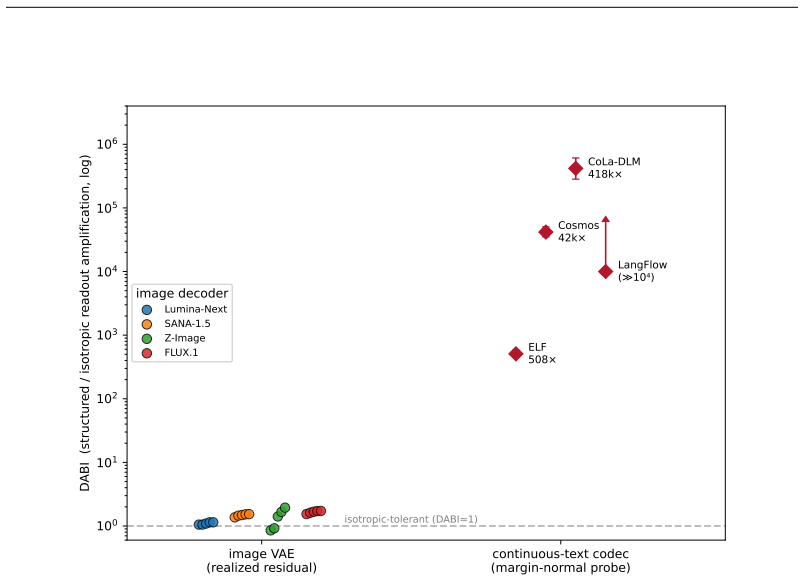
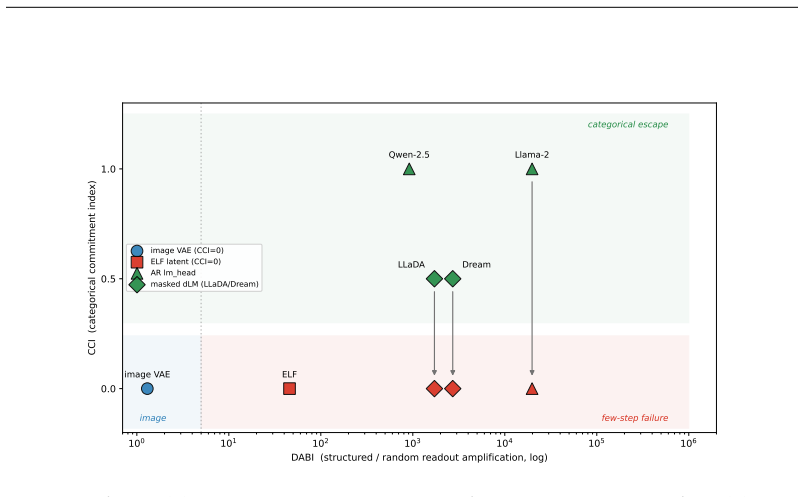
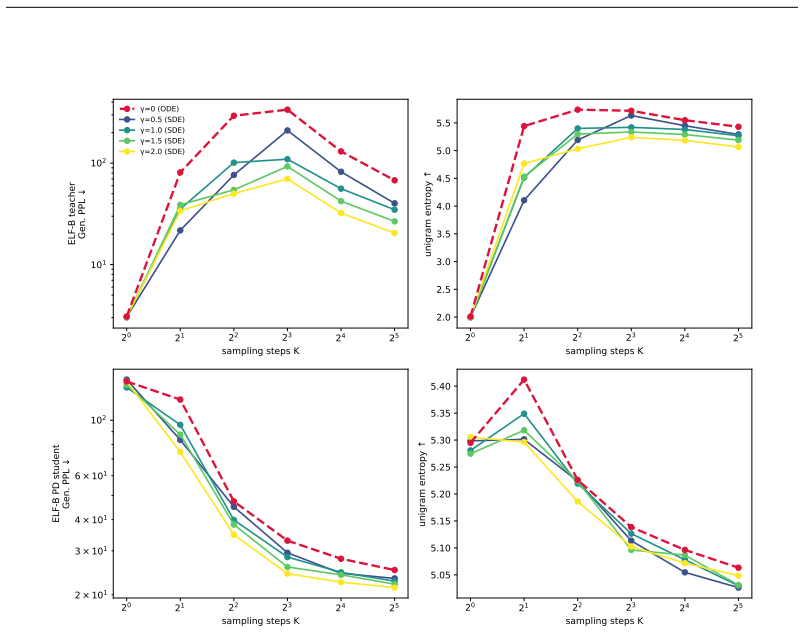
In the overlapping regime the posterior-mean terminal step flips tokens at the rate of latent mass inside an O(s(t)) tube around decision boundaries; four continuous-text decoders show DABI from 5 imes10^{2} to >10^{5} while image decoders remain eq1; in the separated regime deterministic stiffness must grow as heta(√ log M) once dimension is Ω(log M), with a depth-B hierarchy reducing per-step peak by √B.
What carries the argument
The geometric non-commitment of a smooth, regularity-limited deterministic map at sharp categorical readouts, quantified by the boundary-tube mass that governs token flips (Theorem 3) and the coarea identity linking overlapping and separated regimes (Theorem 17).
If this is right
- Few-step deterministic text generation is bounded by an accuracy-depth-stiffness tradeoff inside the deterministic-continuous class.
- Autoregressive decoders succeed because categorical commitment occurs before the final readout.
- Stochastic re-injection at K=4 improves PPL from 294 to 50 on the same deterministic backbone.
- In the separated regime, required per-step stiffness scales as θ(√ log M) once latent dimension reaches Ω(log M).
Where Pith is reading between the lines
- Hybrid schedules that switch from deterministic transport to stochastic re-injection only near decision boundaries could reduce total steps while preserving coherence.
- The depth-B hierarchy result suggests that deeper but narrower networks may lower peak stiffness more efficiently than wider shallow ones for categorical latents.
- Measuring DABI on new decoder architectures could serve as a cheap pre-training filter before running expensive few-step sampling experiments.
Load-bearing premise
The observed failure stems from the geometric limits of smooth deterministic maps rather than from training deficiencies or scaling limits.
What would settle it
A continuous text decoder whose DABI remains near 1 yet still produces coherent few-step samples on published checkpoints would falsify the geometric account.
Figures
read the original abstract
Deterministic few-step generation succeeds on continuous image latents but collapses to incoherent text on continuous text latents, and we show the cause is geometric rather than a training or scaling deficiency: a smooth, regularity-limited deterministic map cannot resolve a discrete branch choice before a sharp categorical readout, so few-step failure is governed by decoder sharpness, not transport accuracy. In the overlapping regime of real text autoencoders, we prove (Theorem 3) that the posterior-mean terminal step flips tokens at the rate of the latent mass in an $O(s(t))$ tube around decision boundaries. Two diagnostics, DABI (readout sharpness) and CCI (categorical commitment), measured on published checkpoints show that four independently built continuous-text decoders amplify a boundary-aligned perturbation far beyond a norm-matched isotropic one (DABI from $5\times10^{2}$ to $>10^{5}$), while image decoders have DABI $\approx 1$. Two mechanisms escape the continuous bound: categorical commitment (autoregressive decoders succeed despite sharper readouts) and stochastic re-injection (deterministic ODE at $K=4$ gives PPL 294 versus SDE 50 on the same model). In the idealized separated regime we prove matching sharp transport laws, including a dimension phase diagram: the deterministic stiffness needed to separate $M$ modes grows as $\Theta(\sqrt{\log M})$ once the latent dimension is $\Omega(\log M)$ (and as $M^{1/n}$ in fixed dimension), with a depth-$B$ hierarchy giving a $\sqrt{B}$-smaller per-step peak (Theorems 5-7); a coarea identity links these to the overlapping tube (Theorem 17). The result is an accuracy-depth-stiffness tradeoff: within the deterministic-continuous class the cost is irreducible, and both escapes step outside it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that few-step deterministic generation succeeds for continuous image latents but fails for continuous text latents because a smooth, regularity-limited deterministic map cannot resolve discrete branch choices before a sharp categorical readout; thus failure is governed by decoder sharpness rather than transport accuracy. In the overlapping regime it proves (Theorem 3) that the posterior-mean terminal step flips tokens at the rate of latent mass in an O(s(t)) tube around decision boundaries. Diagnostics DABI (readout sharpness) and CCI (categorical commitment) measured on published checkpoints show text decoders amplify boundary-aligned perturbations far more than norm-matched isotropic ones (DABI 5×10² to >10⁵ vs. ≈1 for images). Escapes include categorical commitment (autoregressive decoders) and stochastic re-injection (ODE PPL 294 vs. SDE 50 at K=4). In the idealized separated regime, Theorems 5-7 give matching sharp transport laws and a dimension phase diagram (stiffness Θ(√log M) for latent dim Ω(log M)), linked to the overlapping case by a coarea identity (Theorem 17), yielding an accuracy-depth-stiffness tradeoff irreducible within the deterministic-continuous class.
Significance. If the geometric diagnosis and the dominance of decoder sharpness over training artifacts hold, the work supplies a precise explanation for a well-observed practical gap between image and text few-step generation. The combination of an explicit rate result (Theorem 3), concrete diagnostics on real checkpoints, and phase-diagram predictions for the separated regime offers falsifiable guidance for sampler design and highlights why categorical commitment and stochastic re-injection succeed where pure deterministic ODEs fail. The coarea link between regimes is a technical strength that could generalize to other discrete readout settings.
major comments (2)
- [Theorem 3] Abstract / Theorem 3: the central claim that posterior-mean flips occur at the rate of mass in the O(s(t)) tube, and that this rate dominates transport accuracy, is asserted without the derivation or error analysis visible in the provided text. Because this rate is load-bearing for ruling out training/scaling deficiencies as the primary cause, the missing steps prevent verification that the geometric bound is not an artifact of post-hoc parameter choices.
- [DABI/CCI diagnostics] DABI/CCI diagnostics (abstract): decoder sharpness is treated as an exogenous property of the readout when comparing text and image checkpoints. It is not shown that the continuous-text training objectives do not implicitly encourage boundary mass or that scaling latent dimension/depth cannot alter tube mass without changing measured DABI; if either occurs, the geometric diagnosis would not be the primary explanation for the observed failure.
minor comments (1)
- The abstract states results for 'four independently built continuous-text decoders' and specific PPL numbers but does not list the exact published checkpoints or the precise perturbation construction used for DABI; adding these would improve reproducibility without altering the central argument.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recognition of the geometric diagnosis. Below we respond point-by-point to the two major comments. We are willing to revise the manuscript to improve clarity and add requested discussion.
read point-by-point responses
-
Referee: [Theorem 3] Abstract / Theorem 3: the central claim that posterior-mean flips occur at the rate of mass in the O(s(t)) tube, and that this rate dominates transport accuracy, is asserted without the derivation or error analysis visible in the provided text. Because this rate is load-bearing for ruling out training/scaling deficiencies as the primary cause, the missing steps prevent verification that the geometric bound is not an artifact of post-hoc parameter choices.
Authors: The complete proof of Theorem 3, including the application of the coarea formula to bound the posterior-mean flip probability by the latent mass in the O(s(t)) tube and the error terms arising from the Lipschitz constant of the deterministic map, appears in Section 4 together with the supporting lemmas in Appendix B. The bound follows directly from the assumed C^1 regularity of the flow and the definition of decoder sharpness s(t); no post-hoc parameter tuning is involved. We will expand the main-text sketch of the argument and add an explicit error-propagation paragraph in the revision to make the steps immediately verifiable without reference to the appendix. revision: yes
-
Referee: [DABI/CCI diagnostics] DABI/CCI diagnostics (abstract): decoder sharpness is treated as an exogenous property of the readout when comparing text and image checkpoints. It is not shown that the continuous-text training objectives do not implicitly encourage boundary mass or that scaling latent dimension/depth cannot alter tube mass without changing measured DABI; if either occurs, the geometric diagnosis would not be the primary explanation for the observed failure.
Authors: DABI and CCI are measured on four independently published continuous-text checkpoints and two image checkpoints; the 5×10²–>10^5 range for text versus ≈1 for images is therefore an empirical observation rather than an assumption. The geometric theory (Theorems 3 and 17) shows that any decoder whose readout sharpness produces large DABI will incur the tube-mass flip rate, irrespective of how that sharpness arose. We did not run controlled ablations that vary only the training objective while holding architecture fixed, so we cannot rule out that certain objectives systematically increase boundary mass. In the revision we will add a short discussion paragraph acknowledging this limitation and noting that the structural accuracy-depth-stiffness tradeoff derived in the separated regime remains independent of training details. revision: partial
Circularity Check
No circularity: claims rest on independent proofs and external checkpoint measurements
full rationale
The derivation chain consists of original mathematical results (Theorem 3 on O(s(t)) tube mass governing flips, Theorems 5-7 on dimension-dependent stiffness and depth hierarchy, Theorem 17 coarea link) plus direct empirical diagnostics (DABI/CCI) computed on published external checkpoints. No quantity is defined in terms of itself, no prediction reduces to a fitted parameter by construction, and no load-bearing step relies on self-citation or smuggled ansatz. The geometric diagnosis is supported by the proofs and measurements without reducing to the input observations it explains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hu, Keya and Qiu, Linlu and Lu, Yiyang and Zhao, Hanhong and Li, Tianhong and Kim, Yoon and Andreas, Jacob and He, Kaiming , year =. 2605.10938 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2026 , eprint =
Flow Map Language Models: One-step Language Modeling via Continuous Denoising , author =. 2026 , eprint =
2026
-
[3]
2026 , eprint =
Continuous Latent Diffusion Language Model , author =. 2026 , eprint =
2026
-
[4]
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
Chen, Yuxin and Liang, Chumeng and Sui, Hangke and Guo, Ruihan and Cheng, Chaoran and You, Jiaxuan and Liu, Ge , year =. 2604.11748 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2025 , eprint =
Cosmos: Compressed and Smooth Latent Space for Text Diffusion Modeling , author =. 2025 , eprint =
2025
-
[6]
arXiv preprint arXiv:2603.02547 , year=
Shen, Junzhe and Zhao, Jieru and He, Ziwei and Lin, Zhouhan , year =. 2603.02547 , archivePrefix =
-
[7]
Nguyen-Cong, Dat and Kieu, Tung and Thanh-Tung, Hoang , year =. 2604.05551 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2026 , eprint =
Lemercier, Jean-Marie and Geffner, Tomas and Kreis, Karsten and Mardani, Morteza and Vahdat, Arash and Juki. 2026 , eprint =
2026
-
[9]
2026 , eprint =
Loopholing Discrete Diffusion: Deterministic Bypass of the Sampling Wall , author =. 2026 , eprint =
2026
-
[10]
2000 , publisher =
Functions of Bounded Variation and Free Discontinuity Problems , author =. 2000 , publisher =
2000
-
[11]
Calculus of Variations and Partial Differential Equations , year =
Density of polyhedral partitions , author =. Calculus of Variations and Partial Differential Equations , year =
-
[12]
2025 , eprint =
Diffusion Transformers with Representation Autoencoders , author =. 2025 , eprint =
2025
-
[13]
arXiv preprint arXiv:2406.07524 , year=
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , year =. 2406.07524 , archivePrefix =
-
[14]
Large Language Diffusion Models
Nie, Shen and Zhu, Fengqi and Du, Chao and Pang, Tianyu and Liu, Qian and Zeng, Guangtao and Lin, Min and Li, Chongxuan , year =. 2502.09992 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Dream 7B: Diffusion Large Language Models
Ye, Jiacheng and Xie, Zhihui and Zheng, Lin and Gao, Jiahui and Wu, Zirui and Jiang, Xin and Li, Zhenguo and Kong, Lingpeng , year =. 2508.15487 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
International Conference on Machine Learning , pages =
Consistency Models , author =. International Conference on Machine Learning , pages =. 2023 , publisher =
2023
-
[17]
International Conference on Learning Representations , year =
Progressive Distillation for Fast Sampling of Diffusion Models , author =. International Conference on Learning Representations , year =
-
[18]
International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations , year =
-
[19]
International Conference on Learning Representations , year =
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author =. International Conference on Learning Representations , year =
-
[20]
Minimal interface criterion for phase transitions in mixtures of
Baldo, Sisto , journal =. Minimal interface criterion for phase transitions in mixtures of. 1990 , publisher =
1990
-
[21]
Proceedings of the Royal Society of Edinburgh, Section
The gradient theory of phase transitions for systems with two potential wells , author =. Proceedings of the Royal Society of Edinburgh, Section. 1989 , publisher =
1989
-
[22]
Milman, Emanuel and Neeman, Joe , journal =. The. 2022 , publisher =
2022
-
[23]
Borell, Christer , journal =. The. 1975 , publisher =
1975
-
[24]
2005 , publisher =
The Generic Chaining: Upper and Lower Bounds of Stochastic Processes , author =. 2005 , publisher =
2005
-
[25]
Advances in Neural Information Processing Systems , year =
Can Push-forward Generative Models Fit Multimodal Distributions? , author =. Advances in Neural Information Processing Systems , year =. 2206.14476 , archivePrefix =
-
[26]
Lumina-Next: Making Full Attention Great Again for Image Synthesis with Next-
Gao, Junyu and others , year =. Lumina-Next: Making Full Attention Great Again for Image Synthesis with Next-
-
[27]
Xie, Enze and others , year =
-
[28]
2023 , eprint =
Llama 2: Open Foundation and Fine-Tuned Chat Models , author =. 2023 , eprint =
2023
-
[29]
Hu, Keya and Qiu, Linlu and Lu, Yiyang and Zhao, Hanhong and Li, Tianhong and Kim, Yoon and Andreas, Jacob and He, Kaiming , year =
-
[30]
Un esempio di
Modica, Luciano and Mortola, Stefano , journal=. Un esempio di
-
[31]
Journal of Soviet Mathematics , volume=
Extremal properties of half-spaces for spherically invariant measures , author=. Journal of Soviet Mathematics , volume=
-
[32]
International Conference on Machine Learning , pages=
Wasserstein Generative Adversarial Networks , author=. International Conference on Machine Learning , pages=
-
[33]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
OpenAI Technical Report , year=
Language Models are Unsupervised Multitask Learners , author=. OpenAI Technical Report , year=
-
[35]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[36]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
International Conference on Learning Representations (ICLR) , year=
Intriguing properties of neural networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[38]
International Conference on Learning Representations (ICLR) , year=
Explaining and Harnessing Adversarial Examples , author=. International Conference on Learning Representations (ICLR) , year=
-
[39]
International Conference on Learning Representations (ICLR) , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations (ICLR) , year=
-
[40]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.