OTCache: Optimal Transport for Geometry-Aware Caching in Diffusion Models
Pith reviewed 2026-07-01 06:18 UTC · model grok-4.3
The pith
Optimal transport models caching schedules as smooth policy evolution to accelerate diffusion sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
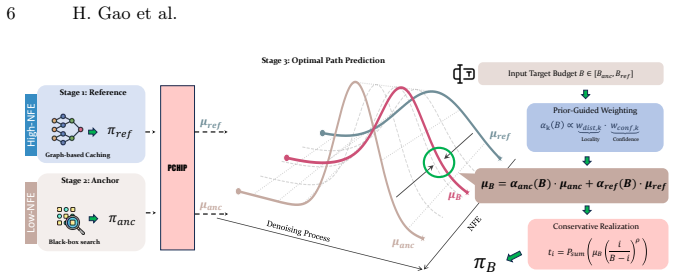
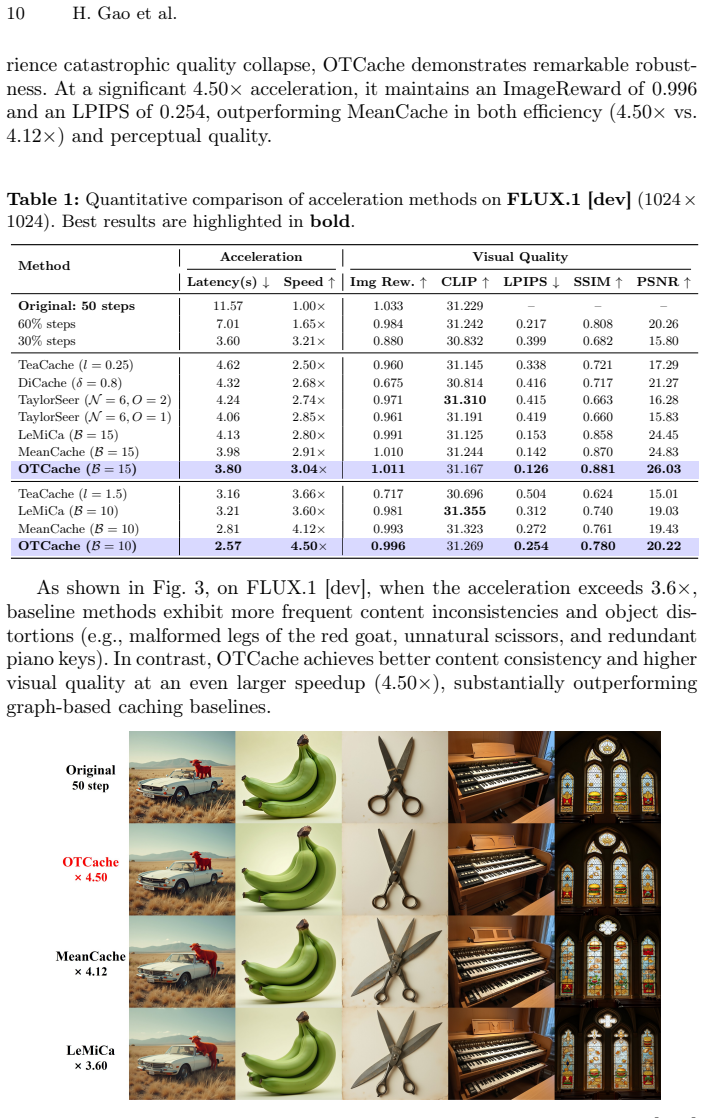
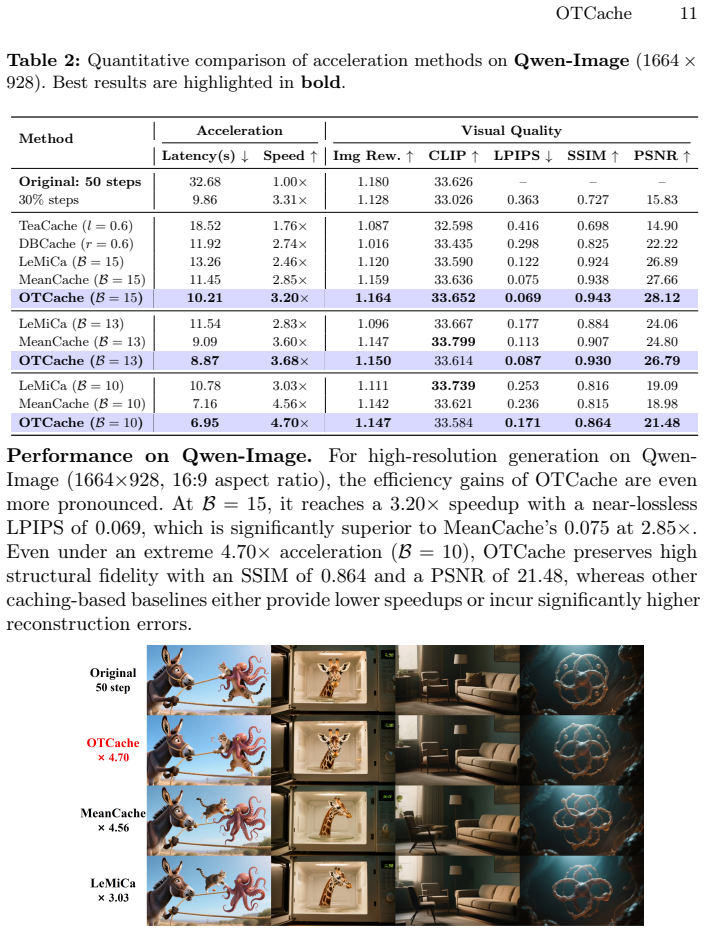
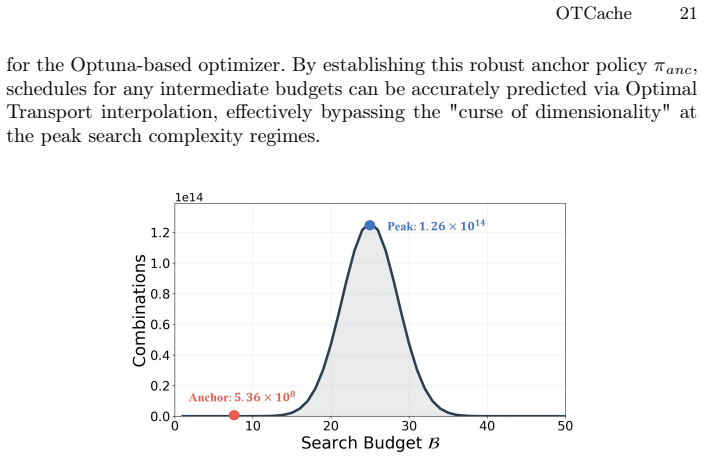
OTCache obtains a reference schedule with a graph-based method under a conservative budget, searches for an anchor schedule at extreme low budget with Optuna under a perceptual objective, and predicts intermediate schedules by quantile interpolation between the reference and anchor policies under continuous warping representations derived from optimal transport. On FLUX.1 [dev], Qwen-Image, and HunyuanVideo this yields 4.5x, 4.7x, and 3.66x acceleration respectively while raising generation fidelity over prior caching baselines.
What carries the argument
Continuous warping representations from optimal transport that turn discrete caching policies into points along a smooth path in policy space for quantile interpolation.
If this is right
- Schedules for any budget between the reference and anchor can be generated without re-running graph search or optimization.
- The framework applies to multiple diffusion backbones without model-specific retraining.
- Fidelity gains appear because the transport model better respects the geometry of low-NFE regimes than additive shortest-path objectives.
- The three-stage pipeline separates expensive reference computation from cheap per-budget interpolation.
Where Pith is reading between the lines
- If the policy-space geometry is approximately Euclidean under OT distance, similar interpolation could be tried on other discrete optimization schedules such as pruning masks or quantization levels.
- The method suggests that caching decisions are not independent across timesteps but lie on low-dimensional manifolds that optimal transport can exploit.
- Extending the anchor search to multiple perceptual objectives might further tighten the fidelity-speed trade-off at the lowest budgets.
Load-bearing premise
Caching schedules across different inference budgets form a smooth evolution in policy space that quantile interpolation under optimal-transport warping can capture accurately.
What would settle it
Directly optimized schedules for an intermediate budget that differ markedly in perceptual score or actual speedup from the OT-interpolated schedule for the same budget.
Figures
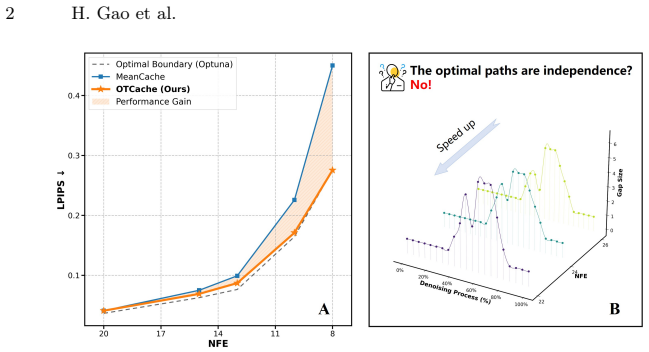







read the original abstract
We propose OTCache, a training-free framework for accelerating diffusion sampling via caching schedule prediction. Existing graph-based caching methods reduce redundant computation by optimizing shortest-path objectives, but rely on an additive independence assumption, which often breaks down in the low NFE regime. To address this issue, OTCache models caching schedules across inference budgets as a smooth evolution in policy space, inspired by Optimal Transport (OT). The framework consists of three stages: (1) obtaining a high-fidelity \textbf{reference schedule} using a graph-based caching method under a conservative budget; (2) performing a lightweight anchor search under an extreme low-budget setting via Optuna optimization with an end-to-end perceptual objective; and (3) predicting schedules for target budgets via quantile interpolation between the reference and anchor policies using continuous warping representations. Experiments on FLUX.1 [dev], Qwen-Image, and HunyuanVideo show that OTCache achieves 4.5x, 4.7x, and 3.66x acceleration, respectively, while consistently improving generation fidelity over state-of-the-art caching baselines. This work provides a new perspective on accelerating diffusion models through Optimal-Transport-inspired schedule modeling. Code:https://github.com/UnicomAI/OTCache
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OTCache, a training-free framework for accelerating diffusion sampling via caching schedule prediction. It models caching schedules across inference budgets as a smooth evolution in policy space using optimal transport. The three-stage pipeline obtains a high-fidelity reference schedule via graph-based methods under conservative budget, performs Optuna-based anchor search under extreme low-budget with perceptual objective, and predicts target schedules via quantile interpolation with continuous warping representations. Experiments claim 4.5x/4.7x/3.66x acceleration on FLUX.1 [dev], Qwen-Image, and HunyuanVideo with improved fidelity over SOTA caching baselines.
Significance. If the empirical claims hold under rigorous controls, the work provides a geometry-aware alternative to additive-independence assumptions in graph-based caching, potentially enabling more reliable schedule transfer across NFE budgets. The code release supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central empirical claim (4.5x/4.7x/3.66x acceleration plus fidelity gains) is stated without any quantitative details on baselines, metrics, statistical significance, number of runs, or controls, preventing assessment of the result.
- [Method] Method (anchor-search stage): the anchor schedule is obtained by Optuna optimization against an end-to-end perceptual objective; the subsequent OT interpolation therefore inherits dependence on this fitted anchor rather than deriving from a parameter-free or closed-form construction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate where revisions to the manuscript will be made to enhance clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (4.5x/4.7x/3.66x acceleration plus fidelity gains) is stated without any quantitative details on baselines, metrics, statistical significance, number of runs, or controls, preventing assessment of the result.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to assess the claims. In the revised manuscript, we will expand the abstract to note that speedups are measured as wall-clock time reductions relative to standard DDIM sampling, fidelity improvements are quantified via FID and LPIPS, results are averaged over five independent runs with different seeds, and comparisons are performed against state-of-the-art caching baselines including graph-based and token-merging methods. These additions will be incorporated without changing the reported numerical results. revision: yes
-
Referee: [Method] Method (anchor-search stage): the anchor schedule is obtained by Optuna optimization against an end-to-end perceptual objective; the subsequent OT interpolation therefore inherits dependence on this fitted anchor rather than deriving from a parameter-free or closed-form construction.
Authors: The observation is accurate: the anchor is obtained via Optuna optimization with a perceptual objective. This is an intentional design element of the three-stage pipeline. The graph-based reference supplies a high-fidelity policy under conservative budgets, while the optimized anchor supplies a perceptually strong endpoint under extreme low budgets where additive independence assumptions break down. The OT interpolation then models the geometry-aware evolution between these two points in policy space. The overall framework remains training-free because no diffusion-model parameters are updated; the anchor search is a lightweight, one-time offline procedure. The manuscript does not claim a parameter-free or closed-form derivation for the entire pipeline, and the OT component specifically addresses the geometry that prior additive methods lack. No revision to the method itself is required, though we can add a short clarifying sentence if the editor deems it helpful. revision: no
Circularity Check
No significant circularity identified
full rationale
The described pipeline obtains a reference schedule from an external graph-based method, fits an anchor via Optuna on a perceptual objective, and applies OT quantile interpolation for other budgets. No equations, definitions, or steps in the provided text reduce by construction to their own inputs, rename fitted quantities as predictions, or depend on self-citations for core claims. The approach is a composite heuristic whose validity rests on external benchmarks rather than internal definitional closure.
Axiom & Free-Parameter Ledger
free parameters (1)
- anchor schedule via Optuna
axioms (1)
- domain assumption Caching schedules across budgets evolve smoothly in policy space under continuous warping representations from optimal transport.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.15682 (2025)
Aggarwal, A., Shrivastava, A., Gwilliam, M.: Evolutionary caching to accelerate your off-the-shelf diffusion model. arXiv preprint arXiv:2506.15682 (2025)
-
[2]
Building Normalizing Flows with Stochastic Interpolants
Albergo, M.S., Vanden-Eijnden, E.: Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
arXiv preprint arXiv:2508.17356 (2025)
Bu, J., Ling, P., Zhou, Y., Wang, Y., Zang, Y., Wu, T., Lin, D., Wang, J.: Dicache: Let diffusion model determine its own cache. arXiv preprint arXiv:2508.17356 (2025)
-
[4]
arXiv preprint arXiv:2406.01125 (2024)
Chen, P., Shen, M., Ye, P., Cao, J., Tu, C., Bouganis, C.S., Zhao, Y., Chen, T.: Delta dit: A training-free acceleration method tailored for diffusion transformers. arXiv preprint arXiv:2406.01125 (2024)
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Chen, P., Zhang, X., Liu, Z., Hu, H., Liu, X., Wang, K., Wang, M., Qian, Y., Lian, S.: Optimizing for the shortest path in denoising diffusion model. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[6]
arXiv preprint arXiv:2406.06911 (2024)
Chen, Z., Ma, X., Fang, G., Tan, Z., Wang, X.: Asyncdiff: Parallelizing diffusion models by asynchronous denoising. arXiv preprint arXiv:2406.06911 (2024)
-
[7]
Advances in Neural Information Pro- cessing Systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in Neural Information Pro- cessing Systems35, 16344–16359 (2022)
2022
-
[8]
arXiv preprint arXiv:2511.00090 (2025)
Gao, H., Chen, P., Shi, F., Tan, C., Liu, Z., Zhao, F., Wang, K., Lian, S.: Lemica: Lexicographic minimax path caching for efficient diffusion-based video generation. arXiv preprint arXiv:2511.00090 (2025)
-
[9]
arXiv preprint arXiv:2601.19961 (2026)
Gao, H., Chen, P., Shi, F., Wu, R., YanTao, L., Hui, Q., You, Y., Lu, T., Tan, C., Zhao, S., et al.: Meancache: From instantaneous to average velocity for accelerating flow matching inference. arXiv preprint arXiv:2601.19961 (2026)
-
[10]
Mean Flows for One-step Generative Modeling
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. arXiv preprint arXiv:2505.13447 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Han, S., Mao, H., Dally, W.J.: Deep compression: Compressing deep neural net- works with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- freeevaluationmetricforimagecaptioning.arXivpreprintarXiv:2104.08718(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
- [15]
-
[16]
arXiv preprint arXiv:2105.14080 , year=
Jolicoeur-Martineau, A., Li, K., Piché-Taillefer, R., Kachman, T., Mitliagkas, I.: Gotta go fast when generating data with score-based models. arXiv preprint arXiv:2105.14080 (2021)
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kahatapitiya, K., Liu, H., He, S., Liu, D., Jia, M., Zhang, C., Ryoo, M.S., Xie, T.: Adaptive caching for faster video generation with diffusion transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15240–15252 (2025) OTCache 17
2025
-
[18]
Advances in neural information processing systems35, 26565–26577 (2022)
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. Advances in neural information processing systems35, 26565–26577 (2022)
2022
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[21]
Advances in neural information processing systems36, 76680– 76691 (2023)
Li, Y., Xu, S., Cao, X., Sun, X., Zhang, B.: Q-dm: An efficient low-bit quantized diffusion model. Advances in neural information processing systems36, 76680– 76691 (2023)
2023
-
[22]
In: ICLR (2023)
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023)
2023
-
[23]
Liu, F., Zhang, S., Wang, X., Wei, Y., Qiu, H., Zhao, Y., Zhang, Y., Ye, Q., Wan, F.: Timestep embedding tells: It’s time to cache for video diffusion model. CoRRabs/2411.19108(2024).https://doi.org/10.48550/ARXIV.2411.19108, https://doi.org/10.48550/arXiv.2411.19108
-
[24]
arXiv preprint arXiv:2510.08669 (2025) SyncCache 17
Liu, J., Cai, P., Zhou, Q., Lin, Y., Kong, D., Huang, B., Pan, Y., Xu, H., Zou, C., Tang, J., et al.: Freqca: Accelerating diffusion models via frequency-aware caching. arXiv preprint arXiv:2510.08669 (2025)
-
[25]
arXiv preprint arXiv:2503.06923 (2025)
Liu, J., Zou, C., Lyu, Y., Chen, J., Zhang, L.: From reusing to forecasting: Accel- erating diffusion models with taylorseers. arXiv preprint arXiv:2503.06923 (2025)
-
[26]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Liu, J., Zou, C., Lyu, Y., Ren, F., Wang, S., Li, K., Zhang, L.: Speca: Accelerating diffusion transformers with speculative feature caching. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10024–10033 (2025)
2025
-
[27]
In: ICLR (2023)
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: ICLR (2023)
2023
-
[28]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Advances in Neural Information Processing Systems 37, 133282–133304 (2024)
Ma, X., Fang, G., Bi Mi, M., Wang, X.: Learning-to-cache: Accelerating diffusion transformer via layer caching. Advances in Neural Information Processing Systems 37, 133282–133304 (2024)
2024
-
[30]
arXiv preprint arXiv:2312.00858 (2023)
Ma, X., Fang, G., Wang, X.: Deepcache: Accelerating diffusion models for free. arXiv preprint arXiv:2312.00858 (2023)
-
[31]
Advances in neural information processing systems36, 21702–21720 (2023)
Ma, X., Fang, G., Wang, X.: Llm-pruner: On the structural pruning of large lan- guage models. Advances in neural information processing systems36, 21702–21720 (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ma, X., Liu, Y., Liu, Y., Wu, X., Zheng, M., Wang, Z., Lim, S.N., Yang, H.: Model reveals what to cache: Profiling-based feature reuse for video diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17150–17159 (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4195–4205 (2023)
2023
-
[34]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[35]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022) 18 H. Gao et al
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
In: European Conference on Computer Vision
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distilla- tion. In: European Conference on Computer Vision. pp. 87–103. Springer (2024)
2024
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shang, Y., Yuan, Z., Xie, B., Wu, B., Yan, Y.: Post-training quantization on dif- fusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1972–1981 (2023)
1972
-
[38]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[39]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models (2023)
2023
-
[40]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[41]
arXiv preprint arXiv:2407.14505 (2024)
Sun,K.,Huang,K.,Liu,X.,Wu,Y.,Xu,Z.,Li,Z.,Liu,X.:T2v-compbench:Acom- prehensive benchmark for compositional text-to-video generation. arXiv preprint arXiv:2407.14505 (2024)
-
[42]
vipshop.com: cache-dit: A unified and training-free cache acceleration toolbox for diffusion transformers (2025),https://github.com/vipshop/cache-dit.git, open-source software available at https://github.com/vipshop/cache-dit.git
2025
-
[43]
7619–7627 (2025)
Wang, C., Guo, Z., Duan, Y., Li, H., Chen, N., Tang, X., Hu, Y.: Target-driven distillation: Consistency distillation with target timestep selection and decoupled guidance.In:ProceedingsoftheAAAIConferenceonArtificialIntelligence.vol.39, pp. 7619–7627 (2025)
2025
-
[44]
IEEE signal processing letters9(3), 81–84 (2002)
Wang, Z., Bovik, A.C.: A universal image quality index. IEEE signal processing letters9(3), 81–84 (2002)
2002
-
[45]
arXiv preprint arXiv:2312.03209 (2023)
Wimbauer, F., Wu, B., Schoenfeld, E., Dai, X., Hou, J., He, Z., Sanakoyeu, A., Zhang, P., Tsai, S., Kohler, J., et al.: Cache me if you can: Accelerating diffusion models through block caching. arXiv preprint arXiv:2312.03209 (2023)
-
[46]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[48]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[49]
arXiv preprint arXiv:2404.02747 (2024)
Zhang, W., Liu, H., Xie, J., Faccio, F., Shou, M.Z., Schmidhuber, J.: Cross- attention makes inference cumbersome in text-to-image diffusion models. arXiv preprint arXiv:2404.02747 (2024)
-
[50]
arXiv preprint arXiv:2403.10266 (2024)
Zhao, X., Cheng, S., Chen, C., Zheng, Z., Liu, Z., Yang, Z., You, Y.: Dsp: Dy- namic sequence parallelism for multi-dimensional transformers. arXiv preprint arXiv:2403.10266 (2024)
-
[51]
arXiv preprint arXiv:2408.12588 (2024)
Zhao, X., Jin, X., Wang, K., You, Y.: Real-time video generation with pyramid attention broadcast. arXiv preprint arXiv:2408.12588 (2024)
-
[52]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all (2024), https://github.com/hpcaitech/Open-Sora
2024
-
[53]
arXiv preprint arXiv:2410.05317 (2024) OTCache 19
Zou, C., Liu, X., Liu, T., Huang, S., Zhang, L.: Accelerating diffusion transformers with token-wise feature caching. arXiv preprint arXiv:2410.05317 (2024) OTCache 19
-
[54]
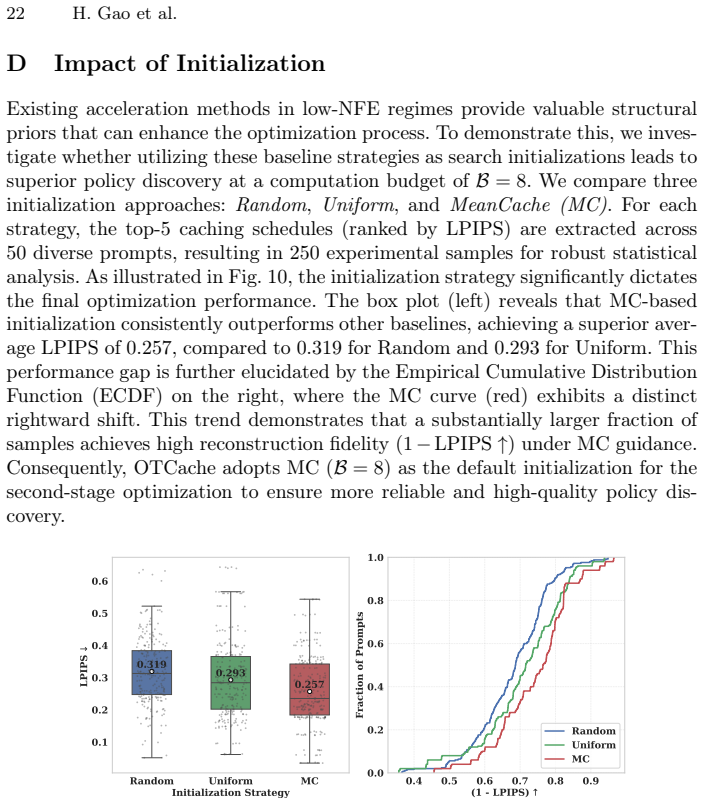
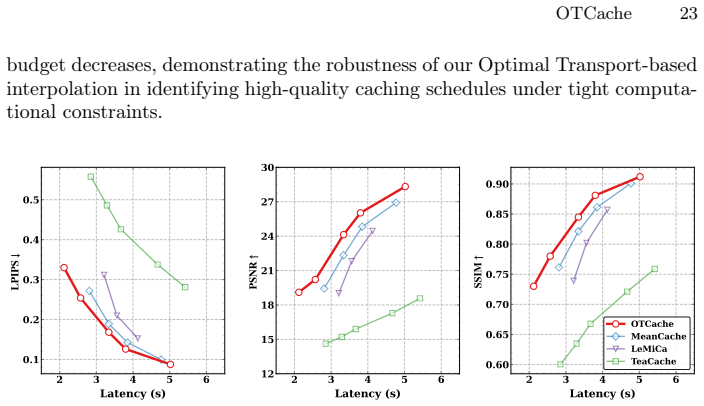
Zou, C., Zhang, E., Guo, R., Xu, H., He, C., Hu, X., Zhang, L.: Accelerating diffusion transformers with dual feature caching. arXiv preprint arXiv:2412.18911 (2024) 20 H. Gao et al. OTCache: Optimal Transport for Geometry-Aware Caching in Diffusion Models Appendix A Baselines and Experimental Settings We evaluate OTCache across text-to-image and text-to-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.