A Modular Vision-Language-Action Robotics Framework for Indoor Environments
Pith reviewed 2026-07-01 05:39 UTC · model grok-4.3
The pith
A modular system builds semantic maps and grounds language queries to produce robot actions from instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
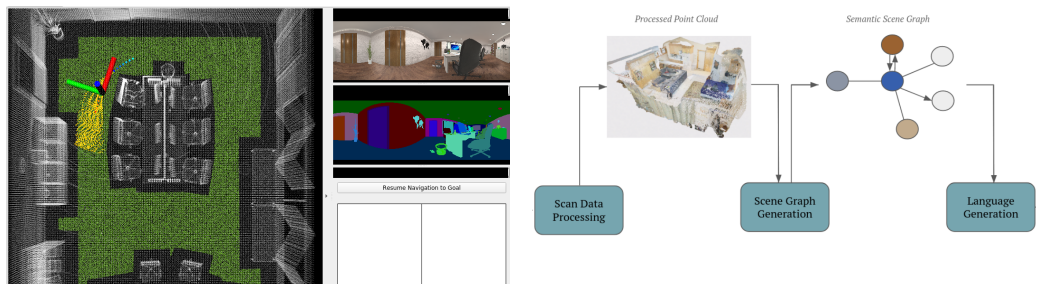
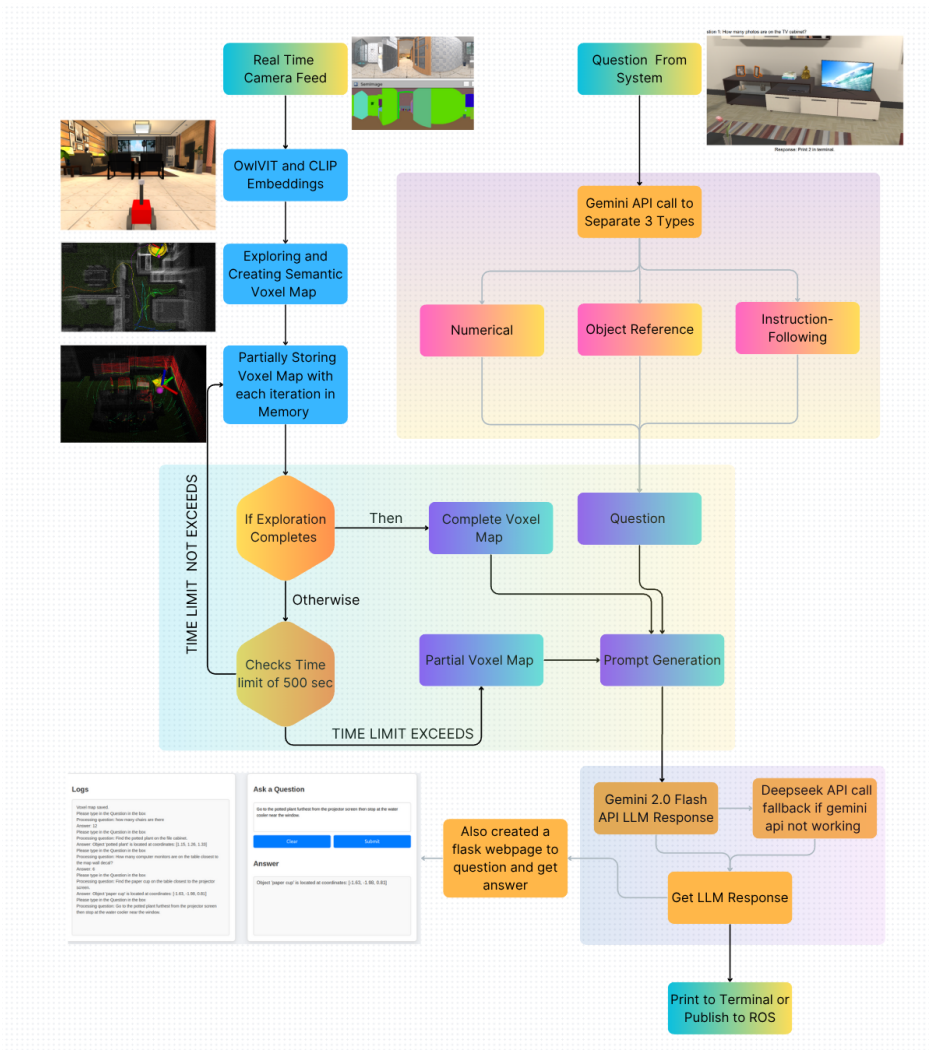
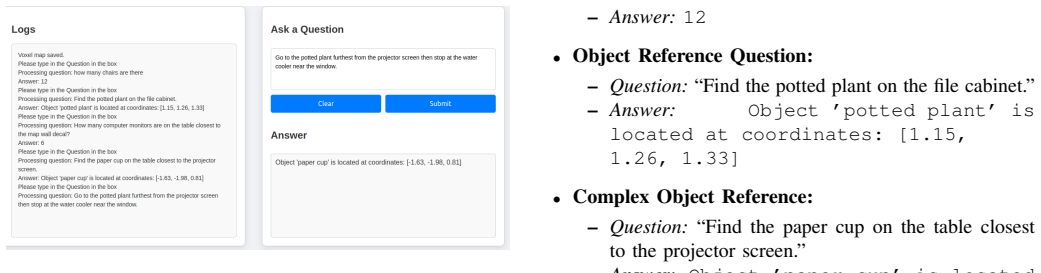
The framework combines a perception pipeline that constructs a semantic voxel map from real-time camera feeds using OwlViT embeddings with a language pipeline that classifies user commands with a Vision-Language Model. The classified query is grounded in the geometric and semantic context of the map to generate a detailed prompt for the VLM. This process yields an actionable output even when the map remains partial after the 500-second exploration limit.
What carries the argument
The modular architecture with parallel perception and language pipelines that grounds classified commands in a (possibly partial) semantic voxel map to produce VLM prompts.
If this is right
- The system can still generate robot actions when exploration time ends before a full map is complete.
- Semantic embeddings from camera feeds enable the map to support language grounding for navigation tasks.
- The two-stream design separates mapping from command processing so each can run on its own schedule.
- The output of the VLM after grounding serves as the direct link from instruction to robot motion.
Where Pith is reading between the lines
- Replacing the VLM with a different model could change action quality without altering the mapping side.
- The same grounding step might extend to tasks that require object manipulation beyond navigation.
- Partial maps could still suffice for simple instructions that refer only to visible nearby features.
Load-bearing premise
Grounding the classified query in the geometric and semantic context of the map will reliably produce correct actionable outputs from the VLM.
What would settle it
A test run in a known indoor layout where the map is built correctly yet the final robot action deviates from the intended response to the language instruction.
Figures
read the original abstract
This paper presents an integrated system for the CMU Vision-Language-Action (VLA) Challenge, designed to enable an autonomous agent to perform complex tasks based on natural language instructions. Our framework employs a modular architecture that orchestrates environment mapping, question processing, and navigation. The system operates in two parallel streams: a perception pipeline that constructs a semantic voxel map from real-time camera feeds using OwlViT embeddings, and a language pipeline that classifies user commands with a Vision-Language Model. The mapping is time-constrained; the system proceeds with a partial map if a 500-second exploration limit is reached. The classified query is then grounded in the geometric and semantic context of the map to generate a detailed prompt for the VLM. This yields an actionable output, demonstrating a capable solution for bridging the gap between human language and robotic action.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a modular VLA framework for the CMU Vision-Language-Action Challenge. It consists of a perception stream that builds a semantic voxel map using OwlViT embeddings from camera feeds (with a 500 s time limit, after which a partial map is used) and a language stream that classifies commands via VLM; the classified query is then grounded in the map's geometric and semantic context to construct a prompt that produces an actionable output.
Significance. A working implementation of this modular pipeline could provide a practical way to bridge natural language instructions to robot actions under partial observability. However, because the manuscript contains no quantitative results, success rates, failure analysis, or baselines, its significance cannot be assessed from the current text.
major comments (1)
- [Abstract] Abstract (final paragraph): the assertion that the system 'yields an actionable output, demonstrating a capable solution' is unsupported. The manuscript reports no task success rates, error modes, baselines, or any evaluation on the CMU VLA Challenge, leaving the load-bearing claim of capability unverified.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript. We address the single major comment below and agree that revisions are required.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the assertion that the system 'yields an actionable output, demonstrating a capable solution' is unsupported. The manuscript reports no task success rates, error modes, baselines, or any evaluation on the CMU VLA Challenge, leaving the load-bearing claim of capability unverified.
Authors: We agree that the final sentence of the abstract makes an unsupported claim. The manuscript describes the modular VLA framework, including the perception stream with OwlViT-based semantic voxel mapping and the language stream for command classification and grounding, but contains no quantitative evaluations, success rates, or results from the CMU VLA Challenge. We will revise the abstract to remove the phrase 'demonstrating a capable solution' and rephrase the closing sentence to describe the framework as producing an actionable output from the grounded prompt without asserting verified capability. revision: yes
Circularity Check
No circularity; high-level system description with no derivations or fitted parameters
full rationale
The manuscript is a modular architecture description for the CMU VLA Challenge. It details perception (OwlViT semantic voxel mapping), language classification via VLM, map-grounded prompt construction, and an assertion that the pipeline 'yields an actionable output.' No equations, parameters, predictions, or first-principles derivations appear anywhere in the provided text. The central claim is an unsubstantiated assertion of capability rather than a reduction of any output to its own inputs by construction. Absence of evaluation metrics is an evidence gap, not a circularity issue. The derivation chain is empty, so no load-bearing steps reduce to self-definition or self-citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CMU Vision-Language-Action (VLA) Chal- lenge,
AI-Meets-Autonomy, “CMU Vision-Language-Action (VLA) Chal- lenge,” 2025. Available: https://www.ai-meets-autonomy.com/cmu-vla- challenge
2025
-
[2]
N. Zantout, et al., “SORT3D: Spatial Object-centric Reason- ing Toolbox for Zero-Shot 3D Grounding Using Large Lan- guage Models,”arXiv preprint arXiv:2504.18684, 2025. Available: https://github.com/nzantout/SORT3D
-
[3]
arXiv preprint arXiv:2411.03540 , year=
H. Zhang, et al., “VLA-3D: A Dataset for 3D Semantic Scene Under- standing and Navigation,”arXiv preprint arXiv:2411.03540, 2024
-
[4]
Learning Transferable Visual Models From Natu- ral Language Supervision,
A. Radford, et al., “Learning Transferable Visual Models From Natu- ral Language Supervision,” inProc. Int. Conf. on Machine Learning (ICML), 2021
2021
-
[5]
Gemini: A Family of Highly Capable Multimodal Models,
Google, “Gemini: A Family of Highly Capable Multimodal Models,” Technical Report, 2023
2023
-
[6]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, et al., “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,
J. Yang, et al., “Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,” inProc. IEEE Int. Conf. on Robotics and Automation (ICRA), 2024, pp. 7694–7701
2024
-
[8]
Autonomous Navigation and Collision Avoidance for Ground Robots,
J. Zhang, “Autonomous Navigation and Collision Avoidance for Ground Robots,”GitHub repository, 2020. Available: https://github.com/ jizhang-cmu/ground based autonomy basic
2020
-
[9]
Simple open-vocabulary object detection with vision transformers,
M. Minderer, et al., “Simple open-vocabulary object detection with vision transformers,” inProc. European Conf. on Computer Vision (ECCV), 2022
2022
-
[10]
ROS: an open-source Robot Operating System,
M. Quigley, et al., “ROS: an open-source Robot Operating System,” in ICRA workshop on open source software, 2009
2009
-
[11]
Habitat: A platform for embodied AI research,
M. Savva, et al., “Habitat: A platform for embodied AI research,” in Proc. IEEE/CVF Int. Conf. on Computer Vision (ICCV), 2019
2019
-
[12]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, et al., “BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inProc. Int. Conf. on Machine Learning (ICML), 2023
2023
-
[13]
Referit3d: Neural listeners for multilateral speaker instructions in 3d scenes,
A. Acharya, et al., “Referit3d: Neural listeners for multilateral speaker instructions in 3d scenes,” inProc. Asian Conf. on Computer Vision (ACCV), 2020
2020
-
[14]
M. Tschannen, et al., “SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Fea- tures,”arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Ns3d: Neuro-symbolic grounding of 3d objects and relations,
J. Hsu, J. Mao, and J. Wu, “Ns3d: Neuro-symbolic grounding of 3d objects and relations,” in Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition.arXiv preprint arXiv:2303.13483, 2023
-
[16]
Q. Gu, et al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,”arXiv preprint arXiv:2309.16650, 2023
-
[17]
VLM: Task-agnostic Video-Language Model Pre-training for Video Understanding,
H. Xu, et al., “VLM: Task-agnostic Video-Language Model Pre-training for Video Understanding,”arXiv preprint arXiv:2105.09996, 2021
-
[18]
Embodied Visual Active Learning,
A. Shrivastava, et al., “Embodied Visual Active Learning,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 11467-11476
2021
-
[19]
Using occupancy grids for mobile robot perception and navigation,
A. Elfes, “Using occupancy grids for mobile robot perception and navigation,” indoi: 10.1109/2.30720., vol. 22, no. 6, pp. 46-57, 1989
-
[20]
V oxel map for visual SLAM,
Muglikar, M., Zhang, Z., Scaramuzza, D, “V oxel map for visual SLAM,” inProc. IEEE Int. Conf. on Robotics and Automation (ICRA), 2020, pp. 4181–4187
2020
-
[21]
Rviz: a toolkit for real domain data visualization,
Kam, H. R., Lee, S. H., et al., “Rviz: a toolkit for real domain data visualization,”Telecommunication Systems, vol. 60, no. 2, pp. 337-345, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.