Surprise as a Signal for Plasticity and Metacognition
Pith reviewed 2026-07-01 05:39 UTC · model grok-4.3
The pith
A prediction-error signal from a small predictor on frozen latents can gate when to store new concepts and let models assess their own knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
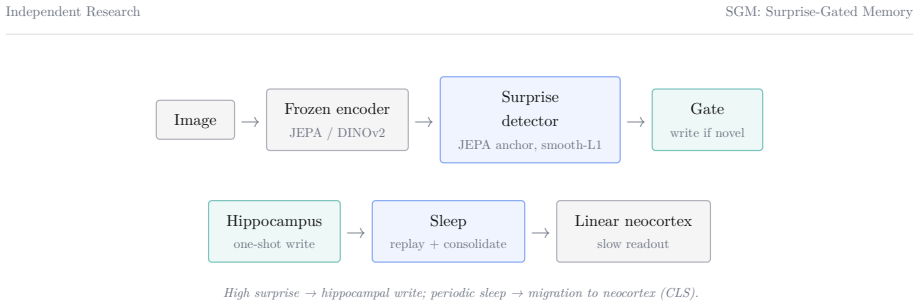
The paper claims that a prediction-error signal computed by a small predictor over the latent space of a frozen encoder can serve both as a gate on plasticity and as a substrate for metacognition, shown in an episodic-memory continual-learning system that selectively writes and replays traces and in a vision-language system whose responses are modulated by the same signal to produce assertive, hedging, or clarification-seeking behavior.
What carries the argument
The surprise signal, defined as the prediction error produced by a small predictor trained on the latent space of a frozen encoder.
If this is right
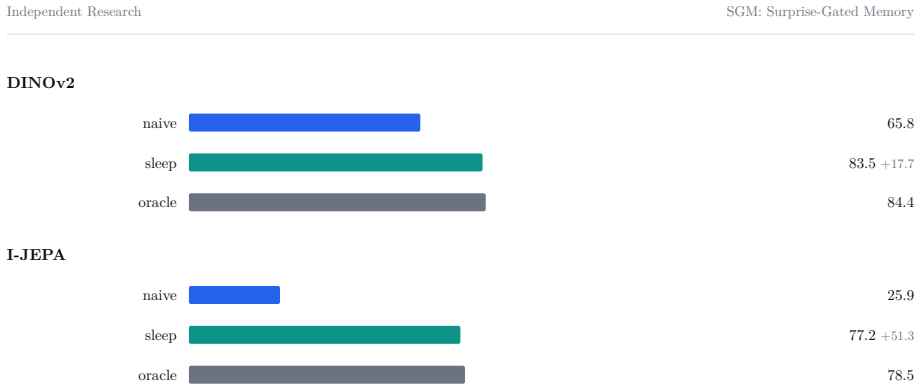
- Selective writing triggered by high surprise plus periodic replay recovers 17.7 points of retention on the oldest classes for a DINOv2 backbone and 51.3 points for an I-JEPA backbone in a 1000-class continual stream.
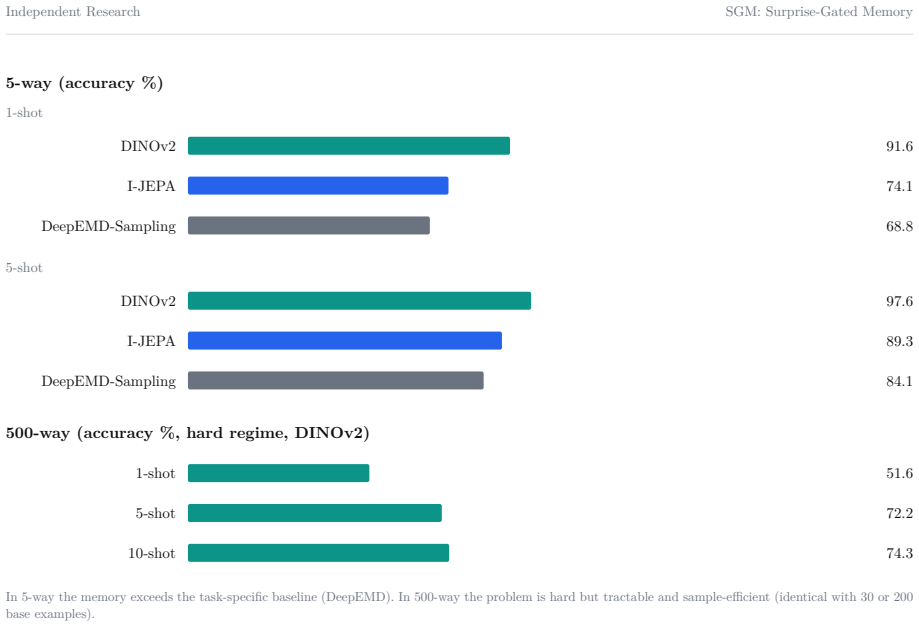
- The same memory reaches 91.6 percent accuracy in 5-way 1-shot evaluation on mini-ImageNet while exposing greater difficulty in a 500-way regime.
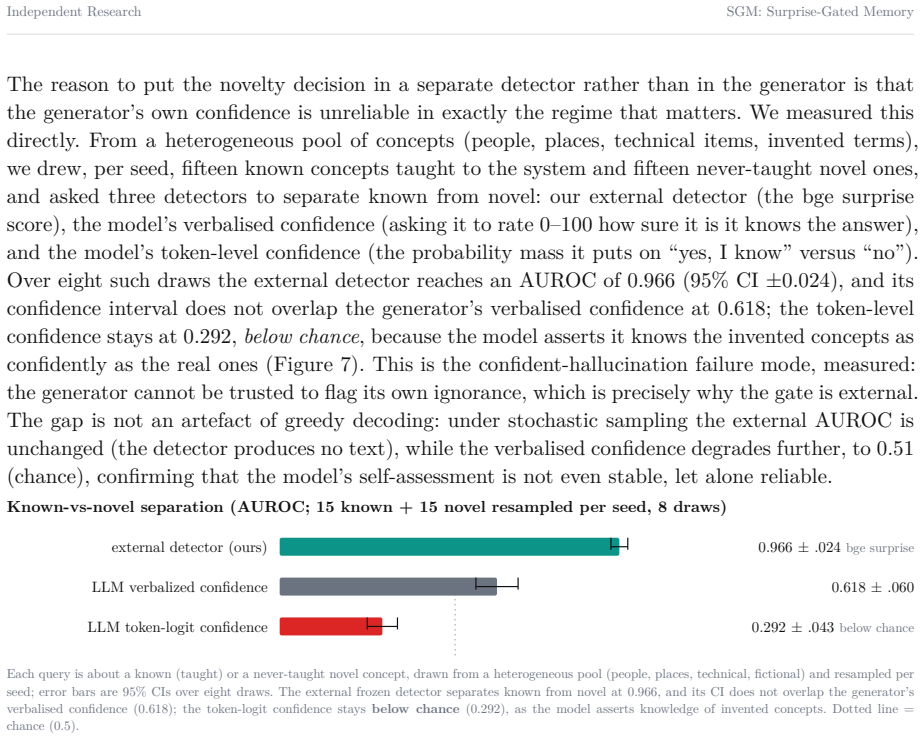
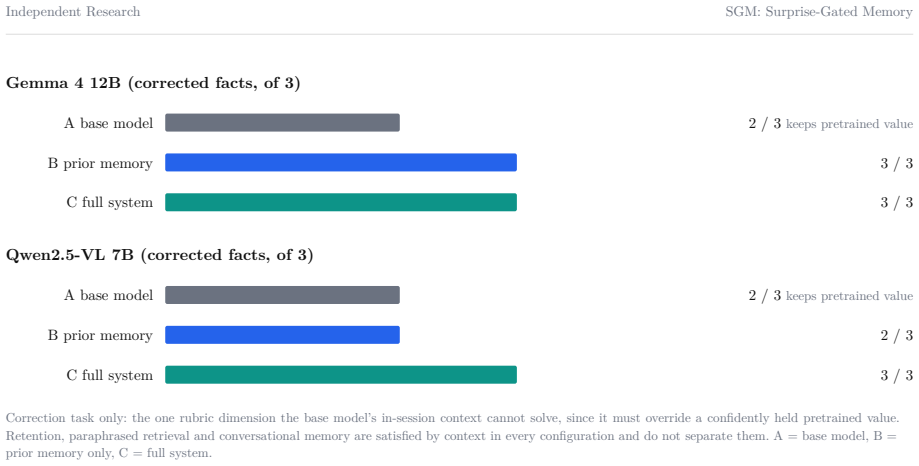
- In the vision-language setting the surprise signal produces assertive answers on known concepts, hedging on partial familiarity, and refusal-plus-explanation request on novel concepts, with an external detector achieving 0.966 AUROC for known-versus-novel separation.
- After a consolidation sleep phase the system recalls 99.2 percent of fifty taught facts from the consolidated store while an unmodified base model recalls none.
- The model's own verbalised confidence and token-level confidence under greedy decoding both perform far below the external surprise detector.
Where Pith is reading between the lines
- If the surprise signal proves stable across additional encoders and modalities, it could support long-running agents that adapt without repeated full-model updates.
- Pairing the signal with user-provided explanations on refusal could create a lightweight loop for on-the-fly personalization of vision-language models.
- The separation between the external detector and the model's internal confidence suggests that explicit surprise monitoring might be added as an independent module rather than relying on the base model to self-report uncertainty.
Load-bearing premise
The surprise signal derived from the small predictor on frozen latents reliably distinguishes novelty in a way that produces the reported retention and AUROC gains rather than from dataset-specific tuning or the choice of replay window.
What would settle it
If an experiment on a fresh stream of image classes with a different frozen encoder shows that surprise-gated writing plus replay produces no retention improvement over a non-surprise baseline, or if the AUROC for known-versus-novel separation falls to chance levels, the central claim would be falsified.
Figures




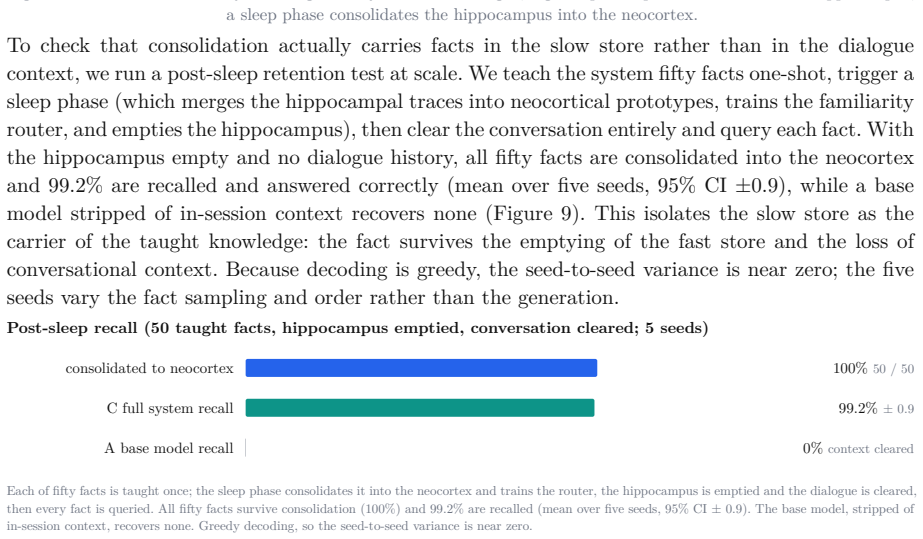
read the original abstract
We study a single idea across two settings: that a prediction-error signal, computed by a small predictor over the latent space of a frozen encoder, can serve both as a gate on plasticity and as a substrate for metacognition. In the first system, a non-parametric episodic memory writes a new concept only when this surprise is high, and a periodic offline replay phase consolidates recent traces into a slow linear readout. On a continual stream of 1000 ImageNet classes with a frozen DINOv2 or I-JEPA backbone, the consolidation phase recovers 17.7 points of retention on the oldest classes for DINOv2 and 51.3 points for I-JEPA (single-seed runs), and an ablation shows that replaying only a recent window is worse than no replay at all. In few-shot evaluation the same memory reaches 91.6% on 5-way 1-shot mini-ImageNet, above a task-specific baseline, while a harder 500-way regime exposes the true difficulty. In the second system, the same surprise signal, computed in a shared text-image space, modulates the behaviour of a vision-language model: it answers assertively when a concept is known, hedges when it is partially familiar, and refuses to identify the object and asks for an explanation when it is novel, learning the concept from a single user utterance. The external detector separates known from novel concepts at an AUROC of 0.966 (95% CI +/-0.024), far above the model's own verbalised confidence (0.618), while its token-level confidence sits below chance under greedy decoding; after a sleep phase that empties the fast store, the system recalls 99.2% of fifty taught facts from the consolidated store while a base model recovers none. We report both systems as proof-of-concept, with explicit limitations, and position the second against recent episodic-memory and personalised-VLM work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a prediction-error (surprise) signal computed by a small predictor over the latent space of a frozen encoder can gate plasticity in a non-parametric episodic memory system (with periodic offline replay consolidating traces into a slow linear readout) and serve as a metacognitive substrate in a vision-language model. On continual ImageNet streams the system reports retention gains of 17.7 points (DINOv2) and 51.3 points (I-JEPA) on oldest classes; on mini-ImageNet it reaches 91.6% in 5-way 1-shot; the VLM component uses the same signal to answer assertively, hedge, or refuse and query when novel, achieving 0.966 AUROC for known/novel separation and 99.2% recall of taught facts after consolidation.
Significance. If the surprise signal is shown to be causally responsible, the work offers a lightweight, interpretable mechanism that unifies plasticity control and self-monitoring without retraining the backbone. Strengths include the use of frozen encoders, explicit positioning as proof-of-concept with stated limitations, and concrete baselines on standard datasets. The approach could inform continual-learning and personalized-VLM research if the reported gains are robustly attributable to the prediction-error computation rather than auxiliary design choices.
major comments (3)
- [Abstract] Abstract: retention gains of 17.7/51.3 points and 99.2% recall are reported from single-seed runs with no error bars or multi-seed statistics; this weakens support for the central claim that the surprise signal produces the observed plasticity and metacognitive effects.
- [Abstract] Abstract: the single ablation (recent-window replay worse than none) does not include a control that disables or randomizes the surprise predictor while holding the replay schedule fixed; without this, it remains unclear whether the prediction-error signal is causally necessary for the gating effect or whether gains arise from the replay window or predictor tuning.
- [Abstract] Abstract: the VLM results claim the surprise signal modulates assertive/hedging/refusal behavior and yields 0.966 AUROC (vs. 0.618 verbalised confidence), yet no ablation is described that removes the surprise computation while preserving other components; this is load-bearing for the metacognition claim.
minor comments (1)
- [Abstract] The abstract states that explicit limitations are reported; these should be expanded with concrete scope boundaries in the main text to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that additional statistical reporting and targeted ablations are needed to better support the causal role of the surprise signal.
read point-by-point responses
-
Referee: [Abstract] Abstract: retention gains of 17.7/51.3 points and 99.2% recall are reported from single-seed runs with no error bars or multi-seed statistics; this weakens support for the central claim that the surprise signal produces the observed plasticity and metacognitive effects.
Authors: We agree that single-seed reporting without error bars weakens the evidential support. In revision we will rerun the core continual ImageNet and VLM experiments over at least three seeds and report means with standard deviations for the retention, few-shot, and AUROC metrics. revision: yes
-
Referee: [Abstract] Abstract: the single ablation (recent-window replay worse than none) does not include a control that disables or randomizes the surprise predictor while holding the replay schedule fixed; without this, it remains unclear whether the prediction-error signal is causally necessary for the gating effect or whether gains arise from the replay window or predictor tuning.
Authors: We accept that the existing ablation does not isolate the surprise predictor. We will add a new condition in which the predictor is either disabled or its outputs are replaced by random values while the replay schedule, memory write threshold, and consolidation procedure remain unchanged. revision: yes
-
Referee: [Abstract] Abstract: the VLM results claim the surprise signal modulates assertive/hedging/refusal behavior and yields 0.966 AUROC (vs. 0.618 verbalised confidence), yet no ablation is described that removes the surprise computation while preserving other components; this is load-bearing for the metacognition claim.
Authors: We agree that an ablation removing the surprise computation is required to substantiate the metacognitive claim. We will add a control in which the VLM always uses its internal verbalised confidence (or a fixed threshold) instead of the external surprise signal, and report the resulting AUROC and refusal behavior. revision: yes
Circularity Check
No circularity: empirical systems evaluated on standard benchmarks without self-referential derivations
full rationale
The paper presents two proof-of-concept systems that compute a surprise signal from a small predictor on frozen encoder latents and use it for memory gating or VLM modulation. All reported outcomes (retention gains of 17.7/51.3 points, 91.6% 5-way 1-shot accuracy, AUROC 0.966) are direct empirical measurements against explicit baselines on ImageNet and mini-ImageNet, accompanied by ablations. No equations, parameter fits, or self-citations are described that would reduce these quantities to inputs by construction; the surprise computation is an independent module whose causal contribution is tested via replay variants rather than assumed tautologically. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
free parameters (2)
- surprise threshold for memory write
- replay window length and consolidation schedule
axioms (1)
- domain assumption Latent spaces of frozen encoders such as DINOv2 and I-JEPA contain structure sufficient for a small predictor to compute useful surprise signals.
Reference graph
Works this paper leans on
-
[1]
Why There Are Complementary Learning Systems in the Hippocampus and Neocortex: Insights from the Successes and Failures of Connectionist Models of Learning and Memory,
J. L. McClelland, B. L. McNaughton, and R. C. O'Reilly, “Why There Are Complementary Learning Systems in the Hippocampus and Neocortex: Insights from the Successes and Failures of Connectionist Models of Learning and Memory,” Psychological Review, 1995
1995
-
[2]
What Learning Systems do Intelligent Agents Need? Complementary Learning Systems Theory Updated,
D. Kumaran, D. Hassabis, and J. L. McClelland, “What Learning Systems do Intelligent Agents Need? Complementary Learning Systems Theory Updated,” Trends in Cognitive Sciences , 2016
2016
-
[3]
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture,
M. Assran et al., “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture,” CVPR, 2023
2023
-
[4]
Loss of Plasticity in Deep Continual Learning,
S. Dohare, J. F. Hernandez-Garcia, Q. Lan, P. Rahman, A. R. Mahmood, and R. S. Sutton, “Loss of Plasticity in Deep Continual Learning,” Nature, 2024
2024
-
[5]
DINOv2: Learning Robust Visual Features without Supervision,
M. Oquab et al., “DINOv2: Learning Robust Visual Features without Supervision,” TMLR, 2024
2024
-
[6]
Sigmoid Loss for Language Image Pre- Training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid Loss for Language Image Pre- Training,” ICCV, 2023
2023
-
[7]
BGE M3-Embedding: Multi- Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation,
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “BGE M3-Embedding: Multi- Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation,” ACL Findings, 2024
2024
-
[8]
Brain-Inspired Replay for Continual Learning with Artificial Neural Networks,
G. M. van de Ven, H. T. Siegelmann, and A. S. Tolias, “Brain-Inspired Replay for Continual Learning with Artificial Neural Networks,” Nature Communications, 2020
2020
-
[9]
Overcoming Catastrophic Forgetting in Neural Networks,
J. Kirkpatrick et al., “Overcoming Catastrophic Forgetting in Neural Networks,” PNAS, 2017
2017
-
[10]
Titans: Learning to Memorize at Test Time
A. Behrouz, P. Zhong, and V. Mirrokni, “Titans: Learning to Memorize at Test Time,” arXiv:2501.00663, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Larimar: Large Language Models with Episodic Memory Control,
P. Das et al., “Larimar: Large Language Models with Episodic Memory Control,” ICML, 2024
2024
-
[12]
MemGPT: Towards LLMs as Operating Systems
C. Packer et al., “MemGPT: Towards LLMs as Operating Systems,” arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Prototypical Networks for Few-shot Learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical Networks for Few-shot Learning,” in NeurIPS, 2017. 13 / 14 Independent Research SGM: Surprise-Gated Memory
2017
-
[14]
Matching Networks for One Shot Learning,
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, and others, “Matching Networks for One Shot Learning,” in NeurIPS, 2016
2016
-
[15]
DeepEMD: Few-Shot Image Classification with Differentiable Earth Mover's Distance and Structured Classifiers,
C. Zhang, Y. Cai, G. Lin, and C. Shen, “DeepEMD: Few-Shot Image Classification with Differentiable Earth Mover's Distance and Structured Classifiers,” in CVPR, 2020
2020
-
[16]
MyVLM: Personalizing VLMs for User-Specific Queries,
Y. Alaluf, E. Richardson, S. Tulyakov, K. Aberman, and D. Cohen-Or, “MyVLM: Personalizing VLMs for User-Specific Queries,” in ECCV, 2024
2024
-
[17]
Yo'LLaVA: Your Personalized Language and Vision Assistant,
T. Nguyen, H. Liu, Y. Li, M. Cai, U. Ojha, and Y. J. Lee, “Yo'LLaVA: Your Personalized Language and Vision Assistant,” in NeurIPS, 2024
2024
-
[18]
S. Bai, K. Chen, X. Liu, and others, “Qwen2.5-VL Technical Report,” arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Gemma 4: Model Card and Technical Report
Gemma Team, Google DeepMind, “Gemma 4: Model Card and Technical Report.” 2026
2026
-
[20]
SCM: Sleep-Consolidated Memory with Algorithmic Forgetting for Large Language Models
S. S. Shinde, “SCM: Sleep-Consolidated Memory with Algorithmic Forgetting for Large Language Models,” arXiv:2604.20943, 2026. 14 / 14
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.