Seeing Is Not Sharing: Some Vision-Language Models Overestimate Common Ground in Asymmetric Dialogue
Pith reviewed 2026-07-01 05:16 UTC · model grok-4.3
The pith
Vision-language models treat map content as evidence of mutual understanding even without dialogue establishing it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
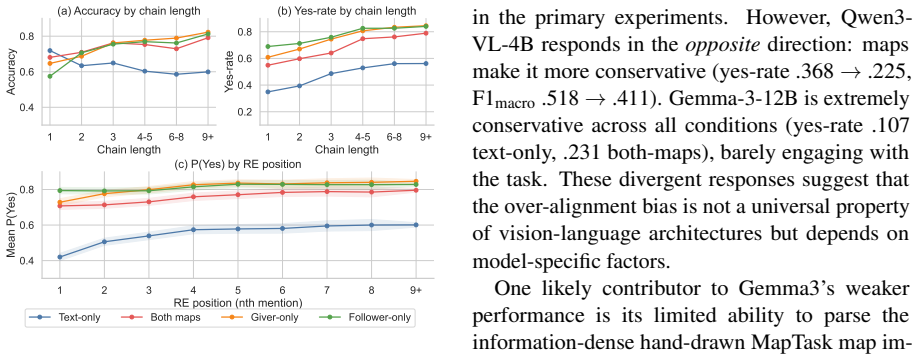
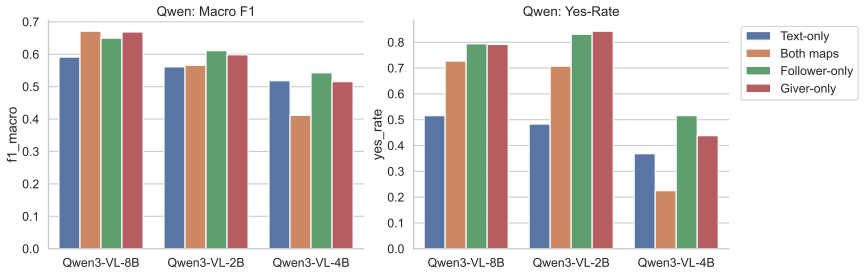
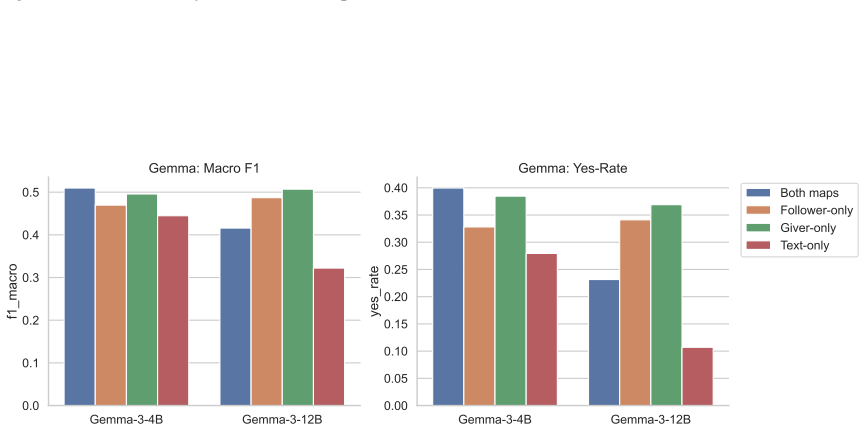
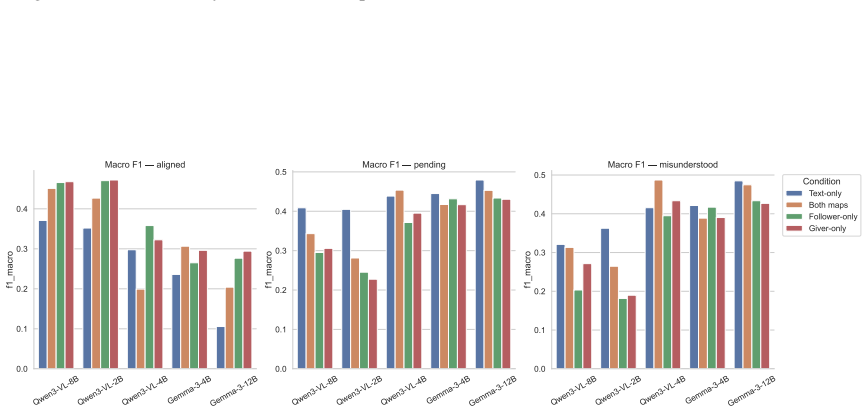
In the interpretation-matching task, authentic map images or textual descriptions of the same content cause models to over-predict that dialogue participants share an interpretation, even when the dialogue history shows no such grounding has occurred. This bias degrades accuracy specifically on non-aligned references. Non-informative images remove the over-prediction entirely, showing the effect is driven by task-relevant map content rather than the visual modality. Calibration and reference-chain analyses indicate models draw on static referential cues visible on the maps instead of following the incremental establishment of common ground through dialogue turns. The pattern appears most str
What carries the argument
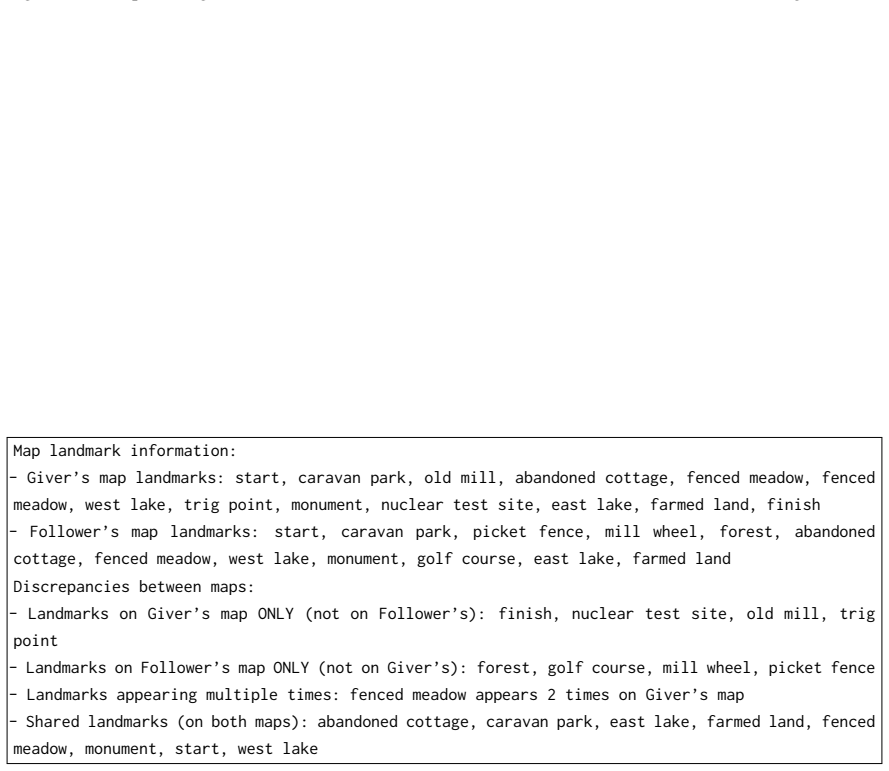
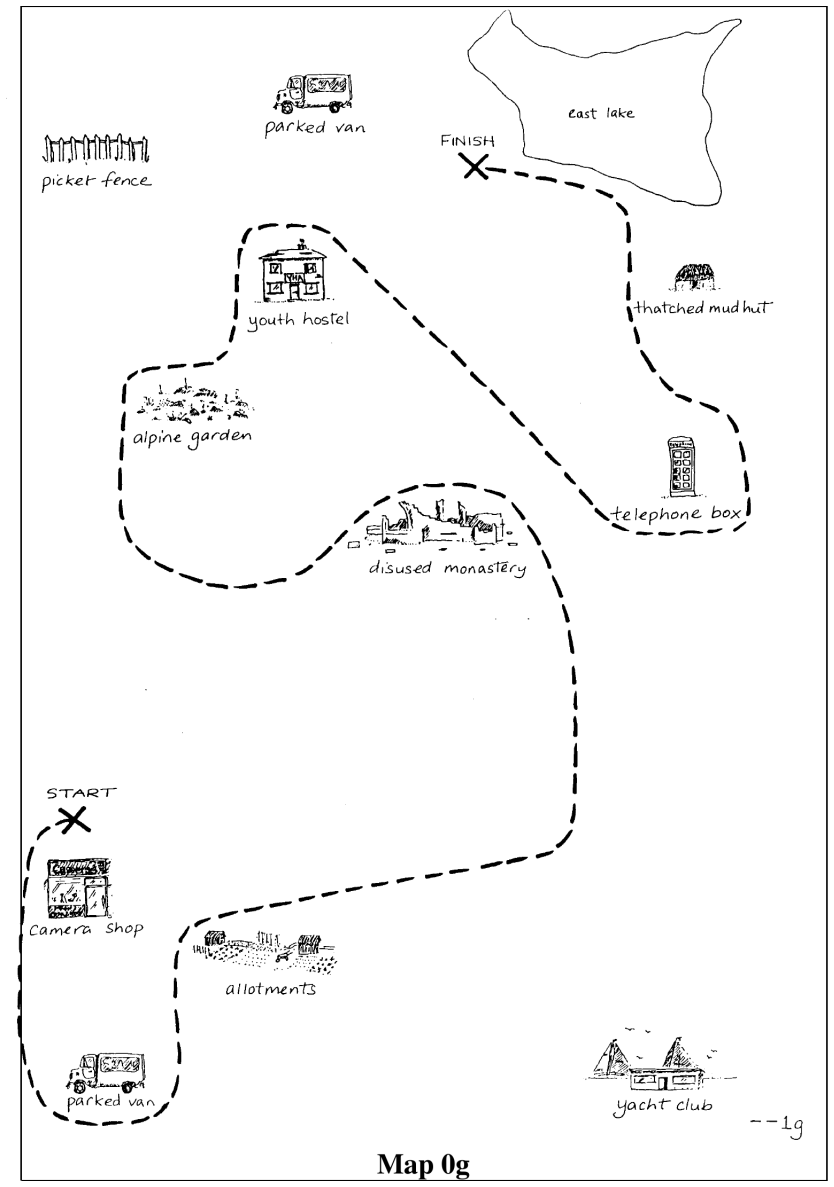
The controlled interpretation-matching task on HCRC MapTask reference expressions that varies dialogue context and map-information access to measure over-prediction of alignment.
If this is right
- Providing informative map content, whether visual or textual, increases over-prediction of alignment while lowering accuracy on non-aligned cases.
- The bias is triggered by task-relevant map content rather than the presence of any image.
- Models rely on static referential cues instead of tracking incremental grounding across dialogue history.
- The overestimation pattern occurs across multiple vision-language model families.
Where Pith is reading between the lines
- Models exhibiting this bias would likely misjudge mutual knowledge in real asymmetric settings where one participant lacks visual access entirely.
- The static-cue reliance suggests current architectures may need explicit mechanisms for logging what has versus has not been verbally confirmed.
- The result raises the possibility that similar conflations occur in other multimodal tasks involving potential versus realized shared knowledge.
- Testing the same manipulation on additional dialogue corpora with different visual domains could show whether the bias is specific to spatial map tasks.
Load-bearing premise
The controlled manipulations of dialogue context and map-information access in the interpretation-matching task accurately isolate the contribution of visual or textual map content to alignment predictions without confounding effects from annotation quality or task formulation.
What would settle it
A follow-up run in which models receive both the map and explicit dialogue turns stating that a reference has not been grounded; if over-prediction of alignment persists at the same rate, the claim that models treat map content as established common ground would be supported.
Figures


read the original abstract
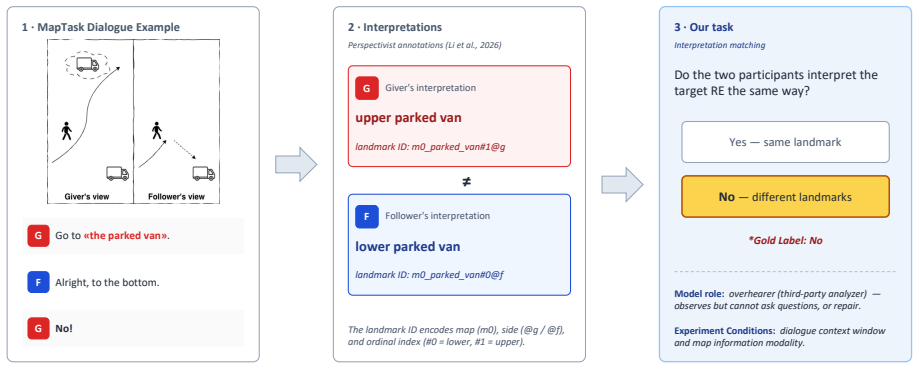
In collaborative dialogue, shared perception does not guarantee shared interpretation. Mutual understanding must be established through interaction. We investigate whether vision-language models (VLMs) can distinguish what could be shared from what has been shared between dialogue participants through grounding. We formulate this as an interpretation-matching task on 13,077 annotated reference expressions from HCRC MapTask dialogues, and evaluate VLMs under systematically controlled manipulations of dialogue context and map-information access. Our results show that providing authentic map images improves overall performance but shifts models toward over-predicting alignment. Textual descriptions of the same map content reproduce this bias, while non-informative images suppress alignment predictions entirely, indicating that the bias is driven by task-relevant map content, not the visual channel. This improvement comes at the cost of degraded accuracy on non-aligned cases. Calibration analysis and reference-chain tracking further suggest that models rely on static referential cues on the maps rather than tracking how grounding unfolds through dialogue history. We observe these patterns most clearly in Qwen3-VL-8B-Instruct and, to varying degrees, in four additional models from two architecture families. In models that exhibit the bias, map content, whether presented visually or textually, is treated as evidence of mutual understanding, conflating potential with established common ground.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that some vision-language models overestimate common ground in asymmetric dialogue by treating map content (whether visual or textual) as evidence of mutual understanding rather than tracking how grounding unfolds through dialogue history. This is demonstrated via an interpretation-matching task on 13,077 annotated reference expressions from the HCRC MapTask corpus, with systematic manipulations of dialogue context and map-information access across multiple VLMs; results show improved overall performance but degraded accuracy on non-aligned cases when map content is provided, with the bias replicated textually and suppressed by non-informative images.
Significance. If the result holds, the work identifies a concrete limitation in VLMs' handling of dynamic common ground, with implications for collaborative dialogue systems. Credit is due for the use of an established public dataset, controlled experimental manipulations, evaluation across five models from two architecture families, and additional analyses such as calibration and reference-chain tracking that go beyond aggregate accuracy.
major comments (1)
- [Methods (interpretation-matching task)] Methods (interpretation-matching task description): The central claim that map content drives the bias (rather than task artifacts) rests on the assumption that the 13,077-reference task cleanly isolates map-access effects. The manuscript provides no quantitative checks on inter-annotator agreement for alignment labels or prompt ablations, so it remains possible that annotation reliability or prompt formulation confounds contribute to the reported over-prediction on non-aligned cases and the textual-map replication.
minor comments (2)
- [Abstract] Abstract: The abstract refers to 'four additional models from two architecture families' without naming them; listing the specific models (e.g., in a footnote or parenthetical) would improve immediate clarity for readers.
- [Results] Results section: The description of 'reference-chain tracking' is mentioned as supporting evidence but lacks a concrete example or figure illustrating how static referential cues are distinguished from dialogue-history tracking; adding one would strengthen the interpretation.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the single major comment below and will incorporate revisions to strengthen the methodological transparency of the interpretation-matching task.
read point-by-point responses
-
Referee: The central claim that map content drives the bias (rather than task artifacts) rests on the assumption that the 13,077-reference task cleanly isolates map-access effects. The manuscript provides no quantitative checks on inter-annotator agreement for alignment labels or prompt ablations, so it remains possible that annotation reliability or prompt formulation confounds contribute to the reported over-prediction on non-aligned cases and the textual-map replication.
Authors: We agree that the absence of reported inter-annotator agreement (IAA) metrics for the alignment labels and the lack of explicit prompt ablations represent a methodological gap that could affect interpretation of the results. The alignment labels were produced by extending the original HCRC MapTask annotations through a multi-stage verification process involving multiple annotators; we will add Cohen's kappa (or equivalent) statistics computed on a held-out subset in the revised manuscript. For prompt formulation, we performed limited sensitivity checks during development but did not report them systematically. We will include an appendix with prompt-ablation results (varying instruction phrasing and few-shot examples) to demonstrate that the core bias pattern is robust. These changes directly address the concern that annotation reliability or prompt artifacts may confound the map-content effect. revision: yes
Circularity Check
No significant circularity: empirical evaluation on public dataset
full rationale
The paper reports an empirical study that formulates an interpretation-matching task on the existing public HCRC MapTask annotations (13,077 references) and evaluates off-the-shelf VLMs under controlled input manipulations. No equations, parameter fitting, derivations, or self-citation chains are used to generate the central claims; performance differences are measured directly against the fixed annotations. The analysis is therefore self-contained against external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The HCRC MapTask dialogues and reference-expression annotations faithfully capture asymmetric dialogue and the process of establishing common ground.
Reference graph
Works this paper leans on
-
[1]
Anderson, Anne H. and Bader, Miles and Bard, Ellen Gurman and Boyle, Elizabeth and Doherty, Gwyneth and Garrod, Simon and Isard, Stephen and Kowtko, Jacqueline and McAllister, Jan and Miller, Jim and Sotillo, Catherine and Thompson, Henry S. and Weinert, Regina , journal=. The. 1991 , publisher=. doi:10.1177/002383099103400404 , url=
-
[2]
Grounded Misunderstandings in Asymmetric Dialogue: A Perspectivist Annotation Scheme for
Li, Nan and Gatt, Albert and Poesio, Massimo , booktitle=. Grounded Misunderstandings in Asymmetric Dialogue: A Perspectivist Annotation Scheme for. 2026 , month=may, address=. doi:10.63317/59anbt78wyj7 , url=
-
[3]
Shuai Bai and Yuxuan Cai and Ruizhe Chen and Keqin Chen and Xionghui Chen and Zesen Cheng and Lianghao Deng and Wei Ding and Chang Gao and Chunjiang Ge and Wenbin Ge and Zhifang Guo and Qidong Huang and Jie Huang and Fei Huang and Binyuan Hui and Shutong Jiang and Zhaohai Li and Mingsheng Li and Mei Li and Kaixin Li and Zicheng Lin and Junyang Lin and Xue...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , booktitle=. Efficient Memory Management for Large Language Model Serving with. 2023 , month=oct, publisher=. doi:10.1145/3600006.3613165 , url=
-
[5]
Obtaining Well Calibrated Probabilities Using
Pakdaman Naeini, Mahdi and Cooper, Gregory and Hauskrecht, Milos , booktitle=. Obtaining Well Calibrated Probabilities Using. 2015 , publisher=. doi:10.1609/aaai.v29i1.9602 , url=
-
[6]
Proceedings of the 34th International Conference on Machine Learning , pages=
On Calibration of Modern Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning , pages=. 2017 , publisher=
2017
-
[7]
Cross-modal Information Flow in Multimodal Large Language Models , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2025 , month=jun, publisher=. doi:10.1109/CVPR52734.2025.01842 , url=
-
[8]
Referring as a Collaborative Process , author =. 1986 , journal =. doi:10.1016/0010-0277(86)90010-7 , url =
-
[9]
Contributing to Discourse , author =. 1989 , journal =. doi:10.1207/s15516709cog1302_7 , url =
-
[10]
Clark, Herbert H. and Brennan, Susan E. , editor =. Grounding in Communication. , booktitle =. 1991 , pages =. doi:10.1037/10096-006 , url =
-
[11]
Toward a Mechanistic Psychology of Dialogue , author =. 2004 , journal =. doi:10.1017/S0140525X04000056 , url =
-
[12]
Controlling the Intelligibility of Referring Expressions in Dialogue , author =. 2000 , journal =. doi:10.1006/jmla.1999.2667 , url =
-
[13]
re-use , author=
Generating subsequent reference in shared visual scenes: Computation vs. re-use , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLG) Edinburgh, Scotland , pages=. 2011 , organization=
2011
-
[14]
The Impact of Visual Context on the Content of Referring Expressions , booktitle =
Viethen, Henriette and Dale, Robert and Guhe, Markus , editor =. The Impact of Visual Context on the Content of Referring Expressions , booktitle =. 2011 , pages =
2011
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A Natural Language Corpus of Common Grounding under Continuous and Partially-Observable Context , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2019 , publisher=. doi:10.1609/aaai.v33i01.33017120 , url=
-
[16]
Understanding by Addressees and Overhearers , author =. 1989 , journal =. doi:10.1016/0010-0285(89)90008-X , url =
-
[17]
Haber, Janosch and Baumg. The. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=. 2019 , month=jul, address=. doi:10.18653/v1/P19-1184 , url=
-
[18]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[19]
Madureira, Brielen and Schlangen, David. It Couldn ' t Help but Overhear: On the Limits of Modelling Meta-Communicative Grounding Acts with Supervised Learning. Proceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2024. doi:10.18653/v1/2024.sigdial-1.13
-
[20]
LVLM s are Bad at Overhearing Human Referential Communication
Wang, Zhengxiang and Li, Weiling and Kaliosis, Panagiotis and Rambow, Owen and Brennan, Susan. LVLM s are Bad at Overhearing Human Referential Communication. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.849
-
[21]
LVLMs and Humans Ground Differently in Referential Communication
Zeng, Peter and Li, Weiling and Paige, Amie J. and Wang, Zhengxiang and Kaliosis, Panagiotis and Samaras, Dimitris and Zelinsky, Gregory and Brennan, Susan E. and Rambow, Owen , year=. 2601.19792 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Navigating Rifts in Human- LLM Grounding: Study and Benchmark
Shaikh, Omar and Mozannar, Hussein and Bansal, Gagan and Fourney, Adam and Horvitz, Eric. Navigating Rifts in Human- LLM Grounding: Study and Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1016
-
[23]
Chiyah-Garcia, Javier and Suglia, Alessandro and Eshghi, Arash and Hastie, Helen. ` W hat are you referring to?' E valuating the Ability of Multi-Modal Dialogue Models to Process Clarificational Exchanges. Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2023. doi:10.18653/v1/2023.sigdial-1.16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.