InstanceControl: Controllable Complex Image Generation without Instance Labeling
Pith reviewed 2026-07-01 05:35 UTC · model grok-4.3
The pith
A vision-language model can automatically match text instance descriptions to regions in visual conditions, enabling precise multi-object image control without manual labeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
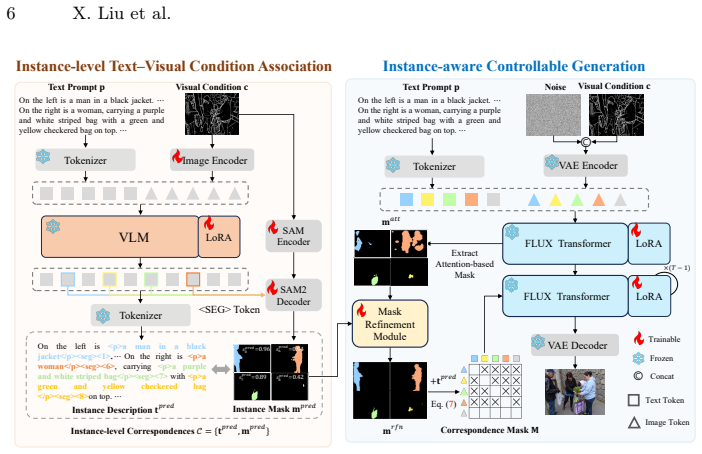
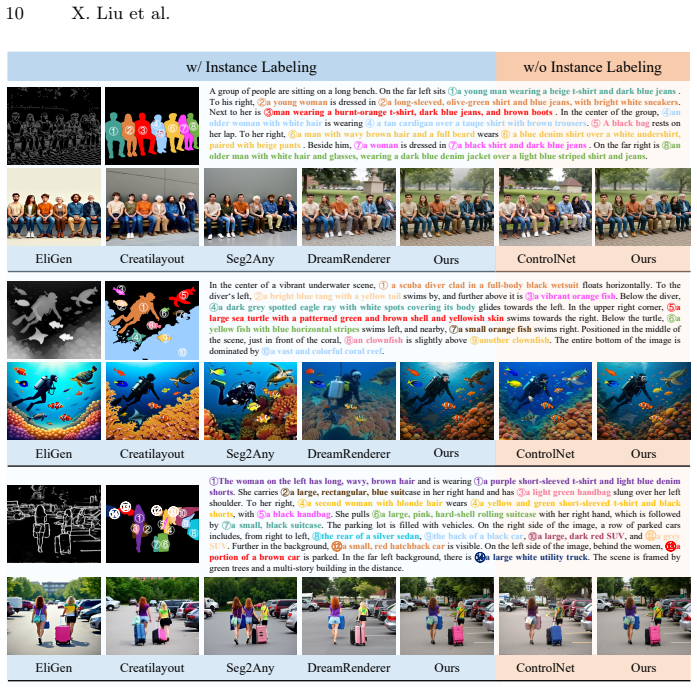
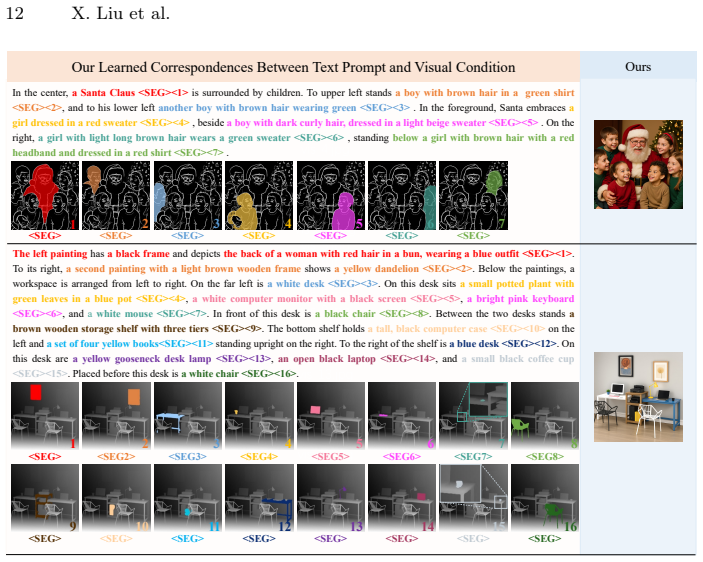
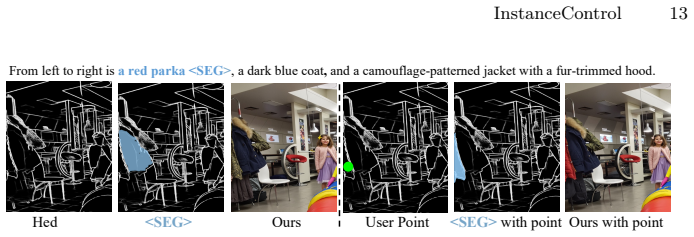
InstanceControl establishes instance-level correspondences by having the VLM parse descriptions from the text prompt and predict instance masks from the visual conditions, then applies adaptive mask refinement during the diffusion process to handle prediction noise, resulting in accurate control over multiple instances in generated images.
What carries the argument
VLM-driven automatic parsing of instance descriptions paired with mask prediction from visual conditions, followed by adaptive refinement of those masks inside the generation loop.
If this is right
- Multi-instance scenes can be generated from standard text prompts and visual conditions without any instance-level annotation step.
- Attribute confusion between objects decreases relative to prior controllable diffusion methods that lack explicit instance association.
- The same visual condition inputs used by ControlNet-style models become sufficient for precise per-object control once VLM parsing is added.
- Generation quality measured by fidelity and instance accuracy improves over current state-of-the-art approaches on complex scenes.
Where Pith is reading between the lines
- The same parsing-plus-refinement pattern could be tested on video or 3D generation tasks that also require region-text alignment.
- If future VLMs produce cleaner masks, the adaptive refinement module might be simplified or removed while retaining performance.
- Downstream applications such as interactive scene editing could adopt the method to let users specify object properties via text alone.
Load-bearing premise
The VLM can reliably parse instance descriptions from prompts and predict accurate instance masks from visual conditions, with the adaptive refinement sufficient to handle any noise in those predictions.
What would settle it
Run the method on a collection of prompts describing scenes with many similar or overlapping objects; if attribute swaps such as color or identity between instances remain frequent in the outputs, the central claim does not hold.
Figures

read the original abstract
Controllable image generation methods, such as ControlNet, have demonstrated a remarkable capacity to introduce visual conditions(e.g., depth maps) to guide image generation. However, these methods often struggle with complex multi-instance scenes, frequently leading to attribute confusion among instances. While recent approaches attempt to mitigate this via manual instance labeling, such requirements are labor-intensive. In this paper, we propose InstanceControl, a novel multi-instance controllable generation method that eliminates the need for instance labeling. We identify the primary bottleneck in existing methods as the inability to accurately associate instance descriptions with their corresponding regions within visual conditions. To address this, we leverage the Vision-Language Model (VLM) to establish instance-level correspondences between text prompts and visual conditions. Specifically, the VLM automatically parses instance descriptions from the text prompts and simultaneously predicts instance masks based on the visual conditions. Furthermore, since the predicted masks may contain noise, we introduce an adaptive mask refinement strategy that dynamically refines these instance masks during the generation process. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods, achieving superior fidelity and precise instance-level control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes InstanceControl, a method for multi-instance controllable image generation (e.g., using depth or Canny conditions) that avoids manual instance labeling. It relies on a VLM to automatically parse instance descriptions from text prompts and predict corresponding instance masks directly from the visual conditions, followed by an adaptive mask refinement step during the diffusion process. The authors claim this yields superior fidelity and precise instance-level control compared to prior state-of-the-art methods.
Significance. If the core technical claims are substantiated, the work would address a practical limitation in controllable generation for complex scenes by removing labor-intensive labeling. The use of VLMs to establish text-to-condition correspondences is a conceptually interesting direction, and the adaptive refinement is a reasonable engineering response to prediction noise. However, the absence of supporting validation for the VLM step on non-RGB inputs substantially reduces the assessed significance.
major comments (2)
- [Abstract] Abstract: The central claim that the VLM 'simultaneously predicts instance masks based on the visual conditions' (depth maps, edges, etc.) is load-bearing for the no-labeling contribution, yet the manuscript provides no quantitative mask-quality metrics, ablation studies, or fine-tuning details demonstrating reliable performance on inputs outside standard VLM RGB training distributions.
- [Method] Method description: The adaptive mask refinement strategy is presented as sufficient to correct noise in VLM predictions, but without concrete implementation details, equations, or ablation results quantifying its effect on final instance control accuracy, it is impossible to verify whether misalignment in the initial masks is actually resolved.
minor comments (1)
- [Abstract] Abstract: Typo/missing space in 'conditions(e.g., depth maps)'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional evidence and detail would strengthen the presentation of our claims. We address each point below and will revise the manuscript to incorporate the requested validation and implementation specifics.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the VLM 'simultaneously predicts instance masks based on the visual conditions' (depth maps, edges, etc.) is load-bearing for the no-labeling contribution, yet the manuscript provides no quantitative mask-quality metrics, ablation studies, or fine-tuning details demonstrating reliable performance on inputs outside standard VLM RGB training distributions.
Authors: We agree that the manuscript lacks direct quantitative support for VLM mask prediction on non-RGB inputs. The current evaluation focuses on end-to-end generation quality rather than isolated mask metrics. In the revision we will add a dedicated evaluation subsection reporting mask-quality metrics (e.g., mean IoU against human-annotated references) for depth and Canny conditions on a held-out set, plus an ablation that measures the impact of removing the VLM correspondence step. We will also explicitly state that the VLM is used zero-shot without fine-tuning. These additions will directly substantiate the load-bearing claim. revision: yes
-
Referee: [Method] Method description: The adaptive mask refinement strategy is presented as sufficient to correct noise in VLM predictions, but without concrete implementation details, equations, or ablation results quantifying its effect on final instance control accuracy, it is impossible to verify whether misalignment in the initial masks is actually resolved.
Authors: We concur that the current description of adaptive mask refinement is insufficiently detailed. The revision will expand the method section with the exact algorithmic procedure, including the mathematical formulation for timestep-dependent mask updating (the probability adjustment rule and the stopping criterion), pseudocode, and a new ablation table that isolates the refinement module's contribution to instance-level metrics such as attribute-binding accuracy and mask alignment error. This will enable verification that initial misalignments are resolved. revision: yes
Circularity Check
No circularity; empirical method with external VLM component
full rationale
The paper describes an empirical pipeline that invokes an off-the-shelf VLM to parse instance descriptions and predict masks from control signals, then applies adaptive refinement. No equations, fitted parameters, or derivations are present. No self-citations are invoked as load-bearing uniqueness theorems, and no input is renamed as a prediction. The central claim therefore rests on the (unverified here) performance of the external VLM rather than reducing to a self-referential definition or fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2312.03079 (2023)
Bhat, S.F., Mitra, N.J., Wonka, P.: Loosecontrol: Lifting controlnet for generalized depth conditioning. arXiv preprint arXiv:2312.03079 (2023)
-
[4]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24185–24198 (2024) 16 X. Liu et al
2024
-
[6]
Advances in neural information processing systems37, 128886–128910 (2024)
Cheng, B., Ma, Y., Wu, L., Liu, S., Ma, A., Wu, X., Leng, D., Yin, Y.: Hico: Hierarchical controllable diffusion model for layout-to-image generation. Advances in neural information processing systems37, 128886–128910 (2024)
2024
-
[7]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Choi, H., Kasahara, I., Engin, S., Graule, M.A., Chavan-Dafle, N., Isler, V.: Finecontrolnet: Fine-level text control for image generation with spatially aligned text control injection. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 3975–3984. IEEE (2025)
2025
-
[8]
arXiv preprint arXiv:2502.10451 (2025)
Fang, Z., Xiang, L., Cai, X., Zhou, K., Wen, H.: Flexcontrol: Computation-aware controlnet with differentiable router for text-to-image generation. arXiv preprint arXiv:2502.10451 (2025)
-
[9]
Google: Nano banana.https://gemini.google/overview/image- generation (2025)
2025
-
[10]
Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents
Gou, B., Wang, R., Zheng, B., Xie, Y., Chang, C., Shu, Y., Sun, H., Su, Y.: Navigating the digital world as humans do: Universal visual grounding for gui agents. arXiv preprint arXiv:2410.05243 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8153–8163 (2024)
2024
-
[13]
arXiv preprint arXiv:2306.00964 (2023)
Hu, M., Zheng, J., Liu, D., Zheng, C., Wang, C., Tao, D., Cham, T.J.: Cock- tail: Mixing multi-modality controls for text-conditional image generation. arXiv preprint arXiv:2306.00964 (2023)
-
[14]
co / InstantX / Qwen-Image-ControlNet-Union(2025)
InstantX: Qwen-image-controlnet-union.https : / / huggingface . co / InstantX / Qwen-Image-ControlNet-Union(2025)
2025
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[16]
Advances in neural information processing systems36, 36652–36663 (2023)
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023)
2023
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Koley, S., Bhunia, A.K., Sekhri, D., Sain, A., Chowdhury, P.N., Xiang, T., Song, Y.Z.: It’s all about your sketch: Democratising sketch control in diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7204–7214 (2024)
2024
-
[18]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning seg- mentation via large language model. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9579–9589 (2024)
2024
-
[20]
arXiv preprint arXiv:2509.19282 (2025)
Li, B., Wang, C.Y., Xu, H., Zhang, X., Armand, E., Srivastava, D., Shan, X., Chen, Z., Xie, J., Tu, Z.: Overlaybench: A benchmark for layout-to-image generation with dense overlaps. arXiv preprint arXiv:2509.19282 (2025)
-
[21]
arXiv preprint arXiv:2506.00596 (2025)
Li, D., Zhang, H., Wang, S., Li, J., Wu, Z.: Seg2any: Open-set segmentation- mask-to-image generation with precise shape and semantic control. arXiv preprint arXiv:2506.00596 (2025)
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Z., Yang, B., Liu, Q., Zhang, S., Ma, Z., Yin, L., Deng, L., Sun, Y., Liu, Y., Bai, X.: Lira: Inferring segmentation in large multi-modal models with local interleaved region assistance. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24056–24067 (2025) InstanceControl 17
2025
-
[23]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Lin, B., Li, Z., Cheng, X., Niu, Y., Ye, Y., He, X., Yuan, S., Yu, W., Wang, S., Ge, Y., et al.: Uniworld-v1: High-resolution semantic encoders for unified visual understanding and generation. arXiv preprint arXiv:2506.03147 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
In: Proceedings of the 2025 CHI Conference on Human Factors in Com- puting Systems
Lin, D.C.E., Kang, H.B., Martelaro, N., Kittur, A., Chen, Y.Y., Hong, M.K.: Inkspire: supporting design exploration with generative ai through analogical sketching. In: Proceedings of the 2025 CHI Conference on Human Factors in Com- puting Systems. pp. 1–18 (2025)
2025
-
[25]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Lin, K.Q., Li, L., Gao, D., Yang, Z., Wu, S., Bai, Z., Lei, S.W., Wang, L., Shou, M.Z.: Showui: One vision-language-action model for gui visual agent. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 19498–19508 (2025)
2025
-
[26]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[27]
In: NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
2023
-
[28]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[29]
In: European Conference on Computer Vision
Liu, X., Wei, Y., Liu, M., Lin, X., Ren, P., Xie, X., Zuo, W.: Smartcontrol: En- hancing controlnet for handling rough visual conditions. In: European Conference on Computer Vision. pp. 1–17. Springer (2024)
2024
-
[30]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Liu, Y., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., Jia, J.: Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Peng, B., Wang, J., Zhang, Y., Li, W., Yang, M.C., Jia, J.: Controlnext: Powerful and efficient control for image and video generation. arXiv preprint arXiv:2408.06070 (2024)
-
[33]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos- 2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Pi, R., Gao, J., Diao, S., Pan, R., Dong, H., Zhang, J., Yao, L., Han, J., Xu, H., Kong, L., et al.: Detgpt: Detect what you need via reasoning. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 14172–14189 (2023)
2023
-
[35]
In: The Twelfth International Conference on Learning Representations
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: The Twelfth International Conference on Learning Representations
-
[36]
arXiv preprint arXiv:2305.11147 (2023)
Qin, C., Zhang, S., Yu, N., Feng, Y., Yang, X., Zhou, Y., Wang, H., Niebles, J.C., Xiong, C., Savarese, S., et al.: Unicontrol: A unified diffusion model for controllable visual generation in the wild. arXiv preprint arXiv:2305.11147 (2023)
-
[37]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13009–13018 (2024) 18 X. Liu et al
2024
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren, Z., Huang, Z., Wei, Y., Zhao, Y., Fu, D., Feng, J., Jin, X.: Pixellm: Pixel rea- soning with large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26374–26383 (2024)
2024
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[41]
arXiv preprint arXiv:2511.18333 (2025)
Shi, X., Li, B., Han, X., Cai, Z., Yang, L., Lin, D., Wang, Q.: Consistcom- pose: Unified multimodal layout control for image composition. arXiv preprint arXiv:2511.18333 (2025)
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Shin, C., Choi, J., Kim, H., Yoon, S.: Large-scale text-to-image model with inpaint- ing is a zero-shot subject-driven image generator. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7986–7996 (2025)
2025
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tan, Z., Liu, S., Yang, X., Xue, Q., Wang, X.: Ominicontrol: Minimal and universal control for diffusion transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14940–14950 (2025)
2025
-
[44]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, T., Cheng, C., Wang, L., Chen, S., Zhao, W.: Himtok: Learning hierarchical mask tokens for image segmentation with large multimodal model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23267–23278 (2025)
2025
-
[46]
arXiv preprint arXiv:2404.08506 (2024)
Wei, C., Tan, H., Zhong, Y., Yang, Y., Ma, L.: Lasagna: Language-based segmen- tation assistant for complex queries. arXiv preprint arXiv:2404.08506 (2024)
-
[47]
arXiv preprint arXiv:2411.17606 (2024)
Wei, C., Zhong, Y., Tan, H., Liu, Y., Zhao, Z., Hu, J., Yang, Y.: Hyperseg: To- wards universal visual segmentation with large language model. arXiv preprint arXiv:2411.17606 (2024)
-
[48]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Wu,Z.,Chen,X.,Pan,Z.,Liu,X.,Liu,W.,Dai,D.,Gao,H.,Ma,Y.,Wu,C.,Wang, B., et al.: Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xia, Z., Han, D., Han, Y., Pan, X., Song, S., Huang, G.: Gsva: Generalized segmen- tation via multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3858–3869 (2024)
2024
-
[51]
arXiv preprint arXiv:2505.05071 (2025)
Xie, C., Wang, B., Kong, F., Li, J., Liang, D., Zhang, G., Leng, D., Yin, Y.: Fg-clip: Fine-grained visual and textual alignment. arXiv preprint arXiv:2505.05071 (2025)
-
[52]
In: Proceedings of the IEEE international conference on computer vision
Xie, S., Tu, Z.: Holistically-nested edge detection. In: Proceedings of the IEEE international conference on computer vision. pp. 1395–1403 (2015)
2015
-
[53]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[54]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 10632– 10643 (2025)
2025
-
[55]
Lisa++: An improved baseline for reasoning segmentation with large language model,
Yang, S., Qu, T., Lai, X., Tian, Z., Peng, B., Liu, S., Jia, J.: Lisa++: An improved baseline for reasoning segmentation with large language model. arXiv preprint arXiv:2312.17240 (2023) InstanceControl 19
-
[56]
Yang, Y., He, X., Pan, H., Jiang, X., Deng, Y., Yang, X., Lu, H., Yin, D., Rao, F., Zhu, M., et al.: R1-onevision: Advancing generalized multimodal reasoning throughcross-modalformalization.In:ProceedingsoftheIEEE/CVFInternational Conference on Computer Vision. pp. 2376–2385 (2025)
2025
-
[57]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
You, H., Zhang, H., Gan, Z., Du, X., Zhang, B., Wang, Z., Cao, L., Chang, S.F., Yang, Y.: Ferret: Refer and ground anything anywhere at any granularity. arXiv preprint arXiv:2310.07704 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
arXiv preprint arXiv:2506.22624 (2025)
You, Z., Wu, Z.: Seg-r1: Segmentation can be surprisingly simple with reinforce- ment learning. arXiv preprint arXiv:2506.22624 (2025)
-
[59]
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Yuan, H., Li, X., Zhang, T., Sun, Y., Huang, Z., Xu, S., Ji, S., Tong, Y., Qi, L., Feng, J., et al.: Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos. arXiv preprint arXiv:2501.04001 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
arXiv preprint arXiv:2312.06573 (2023)
Zavadski, D., Feiden, J.F., Rother, C.: Controlnet-xs: Designing an efficient and effective architecture for controlling text-to-image diffusion models. arXiv preprint arXiv:2312.06573 (2023)
-
[61]
In: Proceedings of the 7th ACM International Conference on Multimedia in Asia
Zhang, H., Duan, Z., Wang, X., Chen, Y., Zhang, Y.: Eligen: Entity-level con- trolled image generation with regional attention. In: Proceedings of the 7th ACM International Conference on Multimedia in Asia. pp. 1–7 (2025)
2025
-
[62]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang,H.,Hong,D.,Wang,Y.,Shao,J.,Wu,X.,Wu,Z.,Jiang,Y.G.:Creatilayout: Siamese multimodal diffusion transformer for creative layout-to-image generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18487–18497 (2025)
2025
-
[63]
arXiv preprint arXiv:2505.19114 (2025)
Zhang, H., Hong, D., Yang, M., Cheng, Y., Zhang, Z., Shao, J., Wu, X., Wu, Z., Jiang, Y.G.: Creatidesign: A unified multi-conditional diffusion transformer for creative graphic design. arXiv preprint arXiv:2505.19114 (2025)
-
[64]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[65]
Advances in neural information processing systems37, 71737–71767 (2024)
Zhang, T., Li, X., Fei, H., Yuan, H., Wu, S., Ji, S., Loy, C.C., Yan, S.: Omg- llava: Bridging image-level, object-level, pixel-level reasoning and understanding. Advances in neural information processing systems37, 71737–71767 (2024)
2024
-
[66]
In: European Conference on Computer Vision
Zhang, Z., Ma, Y., Zhang, E., Bai, X.: Psalm: Pixelwise segmentation with large multi-modal model. In: European Conference on Computer Vision. pp. 74–91. Springer (2024)
2024
-
[67]
arXiv preprint arXiv:2503.12885 (2025)
Zhou, D., Li, M., Yang, Z., Yang, Y.: Dreamrenderer: Taming multi- instance attribute control in large-scale text-to-image models. arXiv preprint arXiv:2503.12885 (2025)
-
[68]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
In: European Conference on Computer Vision (ECCV) (2024)
Zhu, S., Chen, J.L., Dai, Z., Xu, Y., Cao, X., Yao, Y., Zhu, H., Zhu, S.: Champ: Controllable and consistent human image animation with 3d parametric guidance. In: European Conference on Computer Vision (ECCV) (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.