BaRA: Budget-constrained and Reliable Web Data Collection Agent
Pith reviewed 2026-07-04 01:55 UTC · model grok-4.3
The pith
BaRA improves valid link discovery and multimodal artifact extraction for budget-limited web data collection using BFS search and rule-based checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
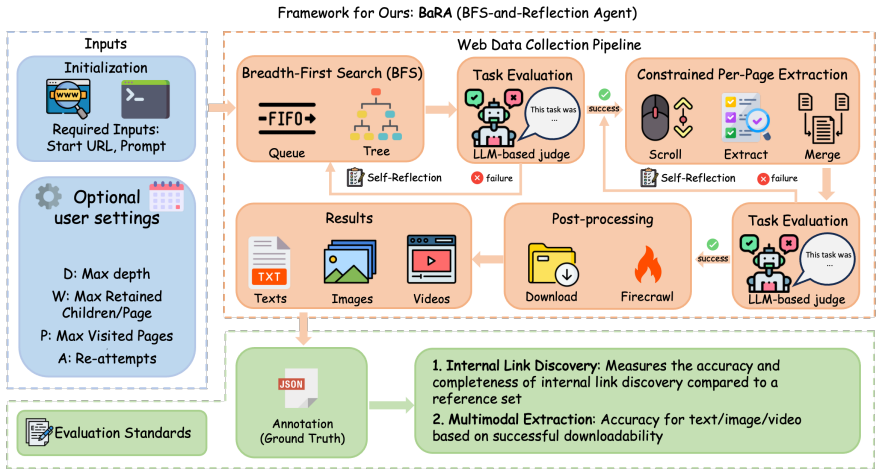
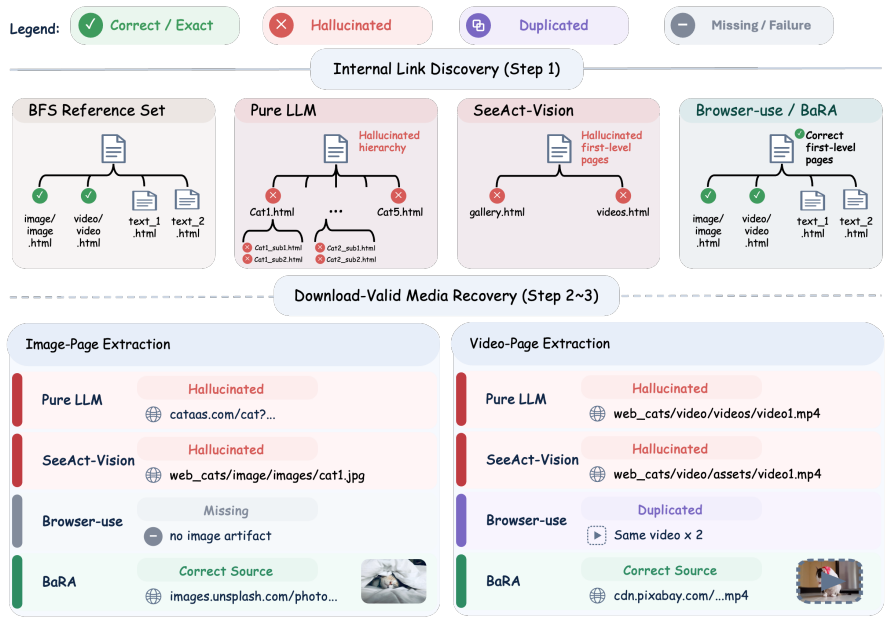
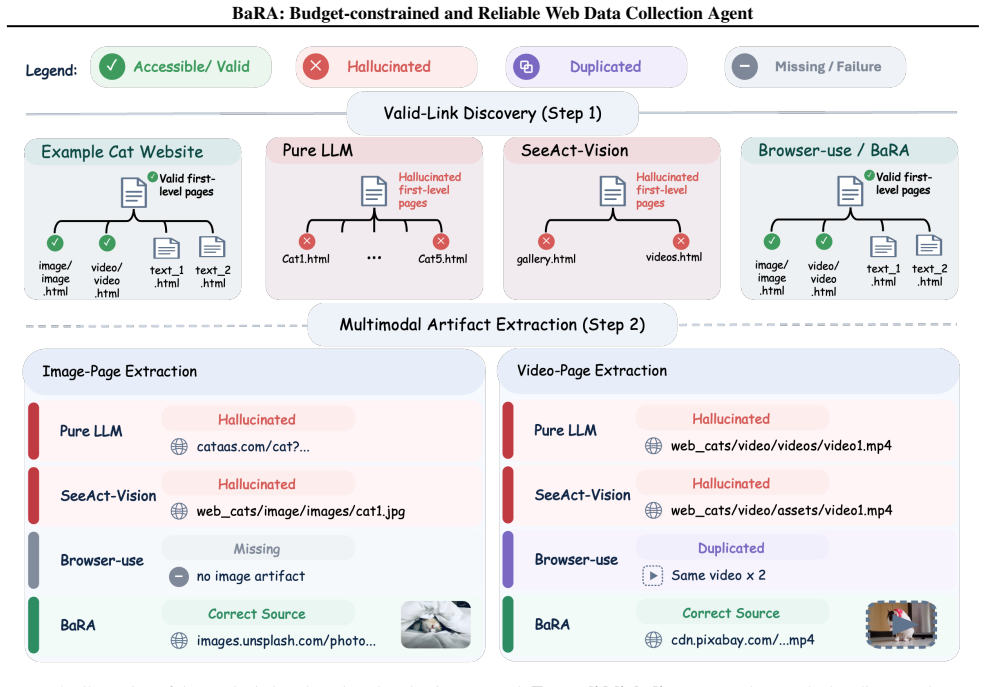
BaRA performs budget-constrained site-level multimodal web data collection by combining BFS-based link discovery with liveness verification to filter hallucinated and dead links, rule-based provenance and accessibility checks to validate extracted text, image, and video artifacts, and a history-based self-reflection module to recover from execution failures, delivering higher rates of valid-link discovery and download-valid multimodal extraction than existing agents on controlled synthetic and real-world websites.
What carries the argument
BFS-based link discovery with liveness verification, rule-based provenance and accessibility checks, and history-based self-reflection module.
If this is right
- More usable multimodal data can be gathered from a given website before the interaction budget is exhausted.
- The fraction of hallucinated or dead links reaching the final dataset drops compared with agents that lack explicit verification steps.
- Self-reflection allows recovery from partial navigation failures without restarting the entire site crawl.
- The same agent architecture can be applied across both synthetic test environments and live production websites with consistent relative gains.
Where Pith is reading between the lines
- The verification steps could be ported to other agent tasks such as API scraping or form filling where output validity must be checked under cost limits.
- Pairing the rule-based checks with learned validators might reduce the risk that the rules themselves reject useful but non-standard content.
- Extending the BFS traversal to respect site-specific crawl-delay rules would make the method more deployable on production web infrastructure.
- The history-based reflection could be tested on multi-site collection tasks where context must be carried across domain boundaries.
Load-bearing premise
The rule-based provenance and accessibility checks plus liveness verification correctly identify valid artifacts and links without creating new false negatives that lower overall collection yield.
What would settle it
Measure the fraction of valid multimodal downloads produced by BaRA versus baselines on a collection of sites engineered so that standard metadata and accessibility signals are deliberately misleading or incomplete.
Figures
read the original abstract
Large language model (LLM)-based web agents automate web navigation and data collection. However, live web data collection demands capabilities beyond task completion: agents must discover site-internal pages and retrieve text, image, and video artifacts in an accessible form within a fixed interaction budget. We formulate this setting as budget-constrained, site-level multimodal web data collection and propose Budget-constrained and Reliable Agent (BaRA). BaRA performs breadth-first search (BFS)-based link discovery with liveness verification to filter hallucinated and dead links, then validates extracted multimodal artifacts using rule-based provenance and accessibility checks. A history-based self-reflection module recovers from execution failures and incomplete outputs. On controlled synthetic and real-world websites, BaRA consistently improves valid-link discovery and download-valid multimodal extraction over existing agents. Our code is available at https://github.com/MLAI-Yonsei/BaRA-Agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BaRA, an LLM-based agent for budget-constrained site-level multimodal web data collection. It performs BFS link discovery with liveness verification to filter hallucinations and dead links, applies rule-based provenance and accessibility checks to validate extracted text/image/video artifacts, and uses history-based self-reflection to recover from failures. The central empirical claim is that BaRA improves valid-link discovery and download-valid multimodal extraction over existing agents on controlled synthetic and real-world websites.
Significance. If the performance gains are robustly supported, the work could contribute to more reliable web agents for data collection tasks under interaction budgets, particularly for multimodal content. The open-source code release supports reproducibility. The significance is tempered by the absence of quantitative metrics, baseline details, and validation of the rule-based components in the provided abstract and evaluation description.
major comments (2)
- [Evaluation / Experiments (implied by abstract claims)] The rule-based provenance, accessibility, and liveness checks (described in the method and used to define 'download-valid' extraction) are load-bearing for the central claim of improved reliability, yet the evaluation provides no inter-rater agreement, held-out human ground truth, precision/recall metrics, or ablation studies on the synthetic or real-world test sites. Without this, it is impossible to rule out systematic false negatives (e.g., on dynamically generated artifacts) that could artifactually inflate the reported gains.
- [Abstract and Evaluation sections] The abstract states that BaRA 'consistently improves' valid-link discovery and multimodal extraction but reports no quantitative numbers, budget definitions, baseline agent descriptions, statistical tests, or effect sizes. This prevents assessment of whether the central empirical claim is supported.
minor comments (1)
- [Abstract] The abstract mentions 'controlled synthetic and real-world websites' but does not specify the sites, number of trials, or budget values used; these details should be added for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the evaluation and presentation of results. We respond to each major comment below and will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: The rule-based provenance, accessibility, and liveness checks (described in the method and used to define 'download-valid' extraction) are load-bearing for the central claim of improved reliability, yet the evaluation provides no inter-rater agreement, held-out human ground truth, precision/recall metrics, or ablation studies on the synthetic or real-world test sites. Without this, it is impossible to rule out systematic false negatives (e.g., on dynamically generated artifacts) that could artifactually inflate the reported gains.
Authors: We agree that additional validation of the rule-based components is needed to robustly support the reliability claims. These checks are deterministic and based on standard web protocols (HTTP status codes for liveness, MIME-type and accessibility attributes for artifacts), but we acknowledge the value of empirical assessment. In the revised manuscript, we will add ablation studies quantifying the impact of each check on valid-link discovery and extraction rates. We will also include a human evaluation on sampled artifacts to report precision/recall and inter-rater agreement where applicable. revision: yes
-
Referee: The abstract states that BaRA 'consistently improves' valid-link discovery and multimodal extraction but reports no quantitative numbers, budget definitions, baseline agent descriptions, statistical tests, or effect sizes. This prevents assessment of whether the central empirical claim is supported.
Authors: The full manuscript presents quantitative results, including specific improvement metrics, budget constraints, baseline agent details, and statistical comparisons, in the Experiments section. To improve the abstract's standalone informativeness, we will revise it to incorporate key quantitative findings, effect sizes, and brief baseline descriptions while maintaining conciseness. revision: yes
Circularity Check
No circularity: empirical agent design evaluated on external benchmarks
full rationale
The paper describes an agent architecture (BFS link discovery, rule-based provenance/accessibility/liveness checks, history-based self-reflection) and reports empirical improvements on controlled synthetic and real-world websites. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. All performance claims rest on direct measurement against external sites rather than any reduction to the method's own definitions or prior self-citations, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Advances in Neural Information Processing Systems , volume=
Mind2web: Towards a generalist agent for the web , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Webvoyager: Building an end-to-end web agent with large multimodal models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
GPT-4V(ision) is a Generalist Web Agent, if Grounded
Gpt-4v (ision) is a generalist web agent, if grounded , author=. arXiv preprint arXiv:2401.01614 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[7]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[8]
WebCanvas: Benchmarking Web Agents in Online Environments
Webcanvas: Benchmarking web agents in online environments , author=. arXiv preprint arXiv:2406.12373 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2504.01382 , year=
An illusion of progress? assessing the current state of web agents , author=. arXiv preprint arXiv:2504.01382 , year=
-
[10]
Browser-use: Open-source browser agent runtime for LLM-based web interaction , year =
-
[11]
International Conference on Machine Learning , pages=
World of bits: An open-domain platform for web-based agents , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[12]
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
Reinforcement learning on web interfaces using workflow-guided exploration , author=. arXiv preprint arXiv:1802.08802 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Workarena: How capable are web agents at solving common knowledge work tasks? , author=. arXiv preprint arXiv:2403.07718 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Advances in Neural Information Processing Systems , volume=
Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2402.05930 , year=
Weblinx: Real-world website navigation with multi-turn dialogue , author=. arXiv preprint arXiv:2402.05930 , year=
-
[18]
arXiv preprint arXiv:2305.11854 , year=
Multimodal web navigation with instruction-finetuned foundation models , author=. arXiv preprint arXiv:2305.11854 , year=
-
[19]
arXiv preprint arXiv:2306.07863 , year=
Synapse: Trajectory-as-exemplar prompting with memory for computer control , author=. arXiv preprint arXiv:2306.07863 , year=
-
[20]
arXiv preprint arXiv:2410.13825 , year=
Agentoccam: A simple yet strong baseline for llm-based web agents , author=. arXiv preprint arXiv:2410.13825 , year=
-
[21]
arXiv preprint arXiv:2412.05467 , year=
The browsergym ecosystem for web agent research , author=. arXiv preprint arXiv:2412.05467 , year=
-
[22]
, howpublished =
n.d. , howpublished =
-
[23]
Unsplash , title =. n.d. , howpublished =
-
[24]
Pixabay , title =. n.d. , howpublished =
-
[25]
yt-dlp , title =. n.d. , howpublished =
-
[26]
2026 , url =
Gemini 3 Flash Preview , organization =. 2026 , url =
2026
-
[27]
2025 , howpublished =
2025
-
[28]
Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation
Tranco: A research-oriented top sites ranking hardened against manipulation , author=. arXiv preprint arXiv:1806.01156 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.