Stop Hand-Holding Your Coding Agent: Engineering the Loops that Replace Step-by-Step Prompting
Pith reviewed 2026-07-02 20:37 UTC · model grok-4.3
The pith
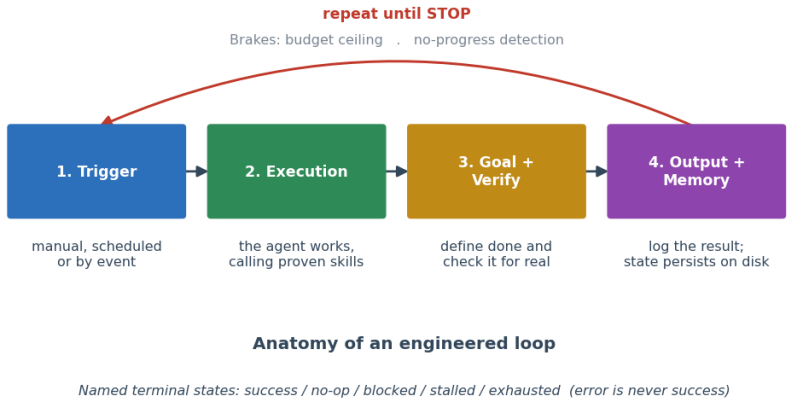
Loop specifications let coding agents pursue goals autonomously via triggers, goals, verification, stopping rules and memory, without retiring prompt engineering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
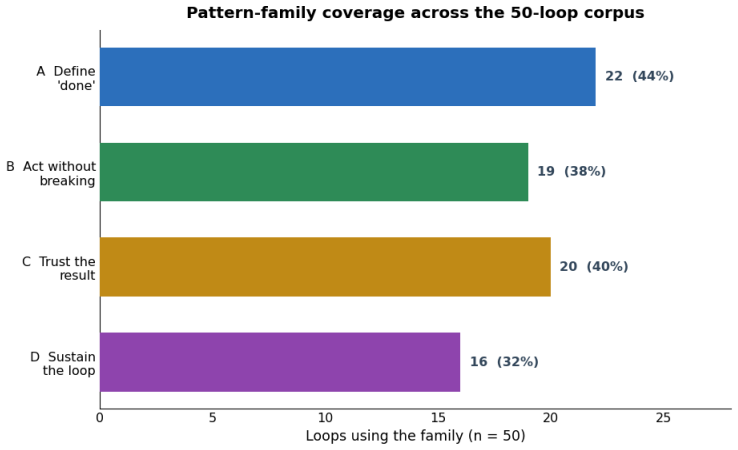
The central claim is that a loop specification is a bounded, reusable object consisting of a trigger, a goal, a verification step, a stopping rule, and memory that a human supplies to a harness so the agent can pursue the goal without step-by-step prompting. This object differs from both ordinary programming loops and the harness's internal perceive-act-observe cycle. Loop engineering therefore forms a distinct new layer after prompt, context, and harness use, yet the paper maintains that prompt engineering continues as a separate practice for tasks that do not fit the loop form. The fifty-loop corpus shows that verification and terminal-state naming are already common while triggering and m
What carries the argument
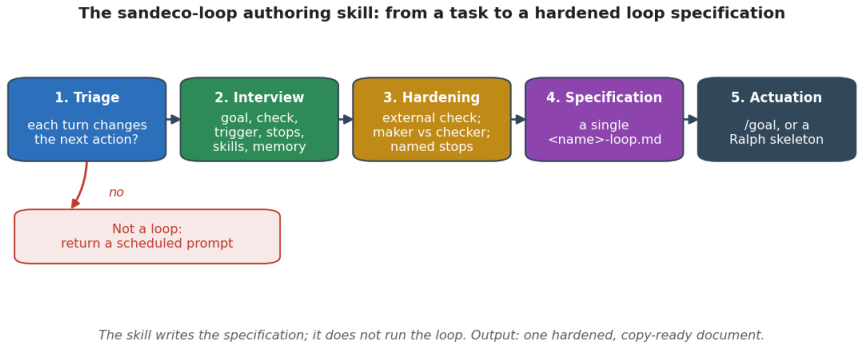
The loop specification, a five-component reusable artifact (trigger, goal, verification step, stopping rule, memory) handed to a harness to enable autonomous goal pursuit.
If this is right
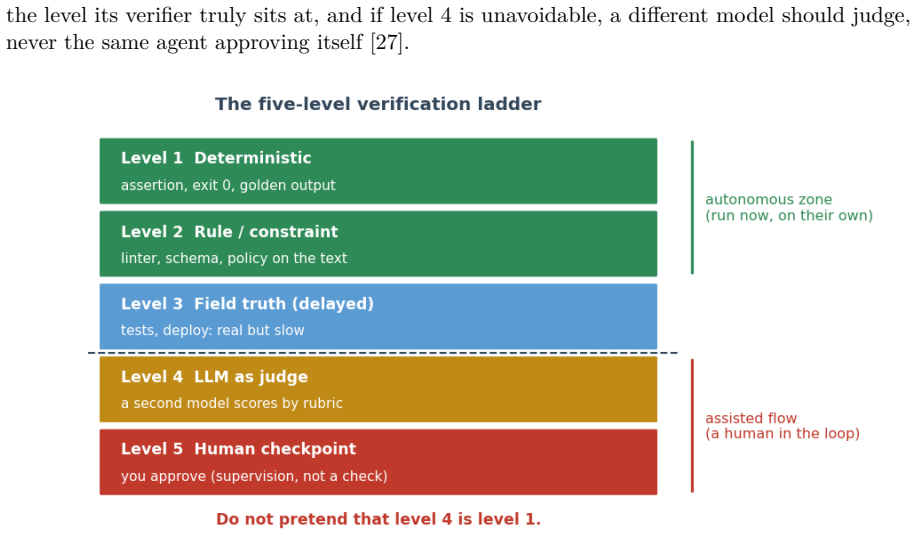
- A five-level verification ladder classifies how much human checking each loop requires.
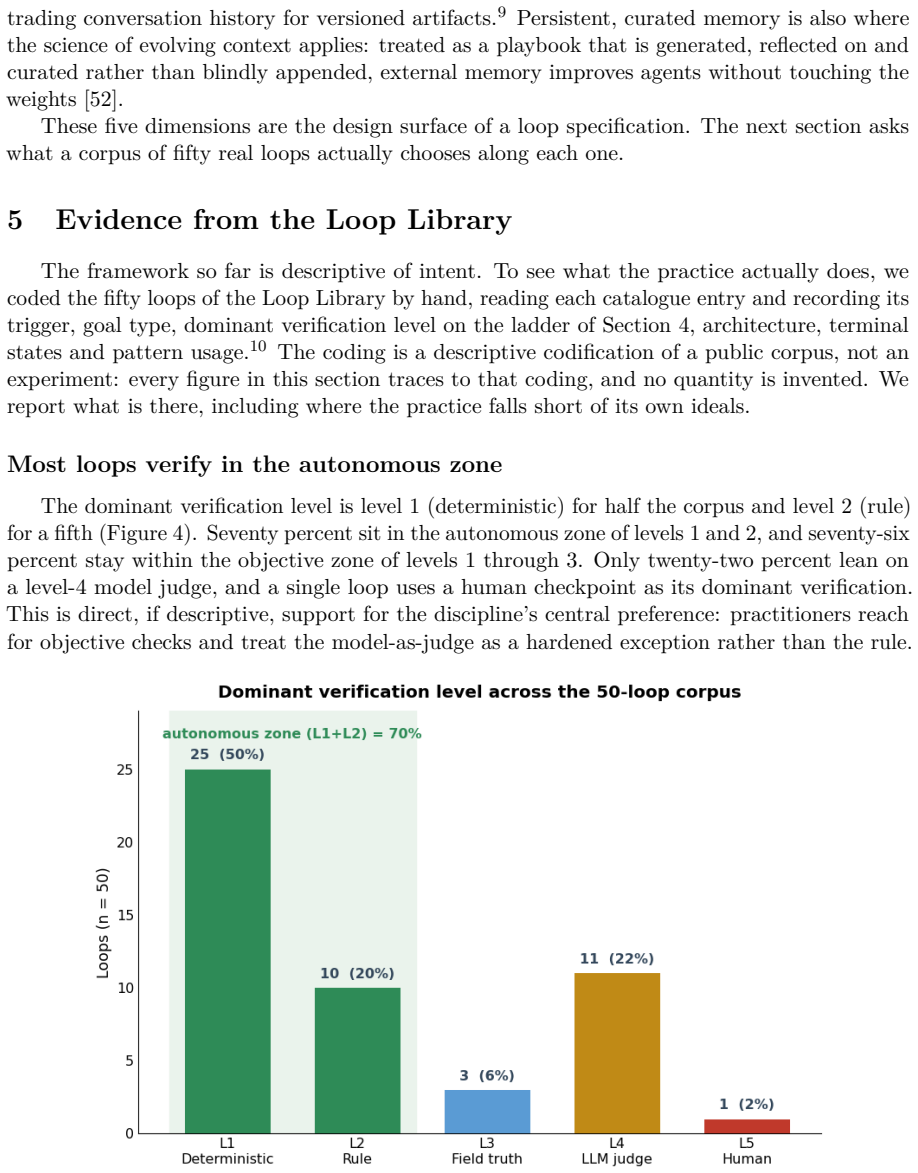
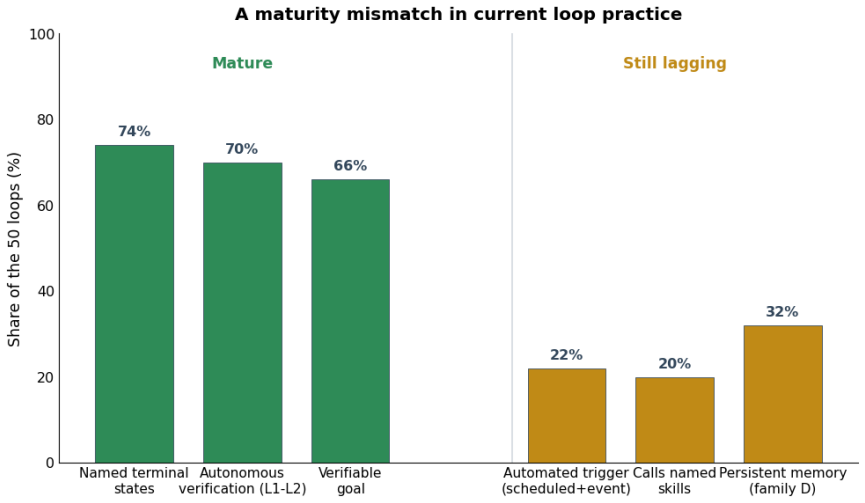
- Seventy percent of the corpus loops already verify inside the autonomous zone of that ladder.
- Seventy-four percent of the loops explicitly name their terminal states.
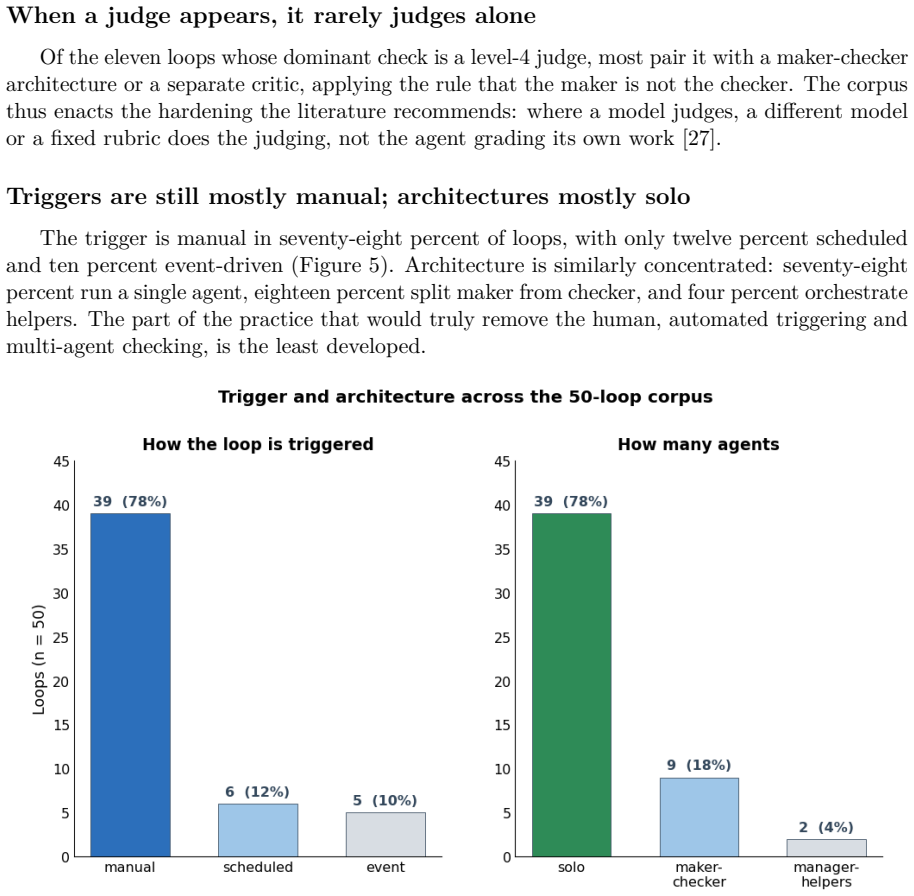
- Automated triggering and durable memory remain comparatively rare in existing loops.
- Design principles address risks such as reward hacking and fragility of model-as-judge checks.
Where Pith is reading between the lines
- Platforms may add native interfaces for loading and running loop specifications directly.
- Shared libraries of common loop patterns could reduce the cost of defining new ones.
- The verification burden may restrict loops to high-value or repeated tasks.
- The same five-part structure could be tested on agents outside coding, such as research or data workflows.
Load-bearing premise
The fifty hand-coded loops represent current practice and the five-component definition plus verification ladder capture the essential distinctions from prompts and harness mechanisms.
What would settle it
A larger survey or set of controlled tests showing that most coding-agent sessions still rely on step-by-step human prompts rather than pre-written loop specifications, or that loop-based runs do not reduce human oversight compared with prompt-based runs.
Figures

read the original abstract
In mid-2026 a slogan reorganized how practitioners talk about coding agents: stop prompting your agent, start designing the loop that prompts it. We take this claim seriously and give it a careful treatment. We call the object of the new practice the loop specification: a bounded, reusable artifact, made of a trigger, a goal, a verification step, a stopping rule and a memory, that a human hands to an agent harness (such as Claude Code or Codex) so the agent pursues a goal on its own, in place of step-by-step prompting. We distinguish this external loop specification from two things it is often confused with: an ordinary programming loop, and the internal perceive-act-observe cycle that the harness already provides as plumbing. We position loop engineering as a new layer in the progression from prompt to context to harness to loop, and we argue, against the stronger headlines, that it does not retire prompt engineering; loop and prompt are distinct tools with distinct uses. We offer four contributions: a definition and scope for the discipline; an anatomy and taxonomy of loop specifications organized around trigger, goal type, a five-level verification ladder, architecture, and named terminal states; a descriptive analysis of the Loop Library, a public corpus of fifty real loops that we code by hand; and a set of design principles and anti-patterns grounded in the scientific literature on self-correction, reward hacking and model-as-judge fragility. The corpus shows that practice has matured most where the discipline says it matters: seventy percent of loops verify in the autonomous zone of the ladder and seventy-four percent name their terminal states, while automated triggering and durable memory remain comparatively underdeveloped. We close with the limits the practice must respect, including the verification burden, comprehension debt and the risk of cognitive surrender.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that loop engineering represents a distinct new layer beyond prompt engineering and harness plumbing for coding agents. It defines a loop specification as a bounded, reusable five-component artifact (trigger, goal, verification step, stopping rule, memory) handed to an agent harness. The work contributes a taxonomy organized around these components plus a five-level verification ladder, architecture, and named terminal states; a hand-coded analysis of a public corpus of fifty real loops showing 70% autonomous verification and 74% named terminals; and design principles drawn from self-correction and model-as-judge literature. It positions the practice as complementary to, rather than replacing, prompt engineering.
Significance. If the taxonomy and distinctions hold, the paper could usefully organize an emerging practitioner practice by identifying underdeveloped areas such as automated triggering and durable memory, while supplying concrete design principles. The descriptive corpus snapshot and explicit separation of external loop specifications from internal harness cycles are potentially helpful for software engineering audiences working with agent harnesses. Strengths include the public corpus and grounding in existing literature on reward hacking; however, the small author-curated sample limits generalizability.
major comments (2)
- [Corpus analysis / Loop Library] Corpus construction and analysis section: The reported statistics (70% autonomous verification, 74% named terminal states) rest on the authors' hand-coding of fifty loops, yet the manuscript supplies no details on selection criteria, exclusion rules, inter-rater reliability, or annotation protocol. This directly affects the claim that the five-component definition and verification ladder capture essential, non-arbitrary distinctions rather than post-hoc categories.
- [Anatomy and taxonomy] Taxonomy and definition section: The five-component anatomy and five-level verification ladder are presented as capturing distinctions from prompts and harness plumbing, but no systematic comparison against existing prompt-engineering or agent-taxonomy literature is supplied to demonstrate that the categories are reproducible or load-bearing rather than author-interpreted.
minor comments (1)
- [Abstract / Discussion] The abstract states the corpus shows practice has 'matured most where the discipline says it matters,' but the manuscript does not clarify whether this alignment was assessed before or after defining the ladder.
Simulated Author's Rebuttal
We thank the referee for the constructive and precise feedback. We agree that the manuscript would benefit from greater methodological transparency on the corpus and a more explicit positioning of the taxonomy against prior literature. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Corpus analysis / Loop Library] Corpus construction and analysis section: The reported statistics (70% autonomous verification, 74% named terminal states) rest on the authors' hand-coding of fifty loops, yet the manuscript supplies no details on selection criteria, exclusion rules, inter-rater reliability, or annotation protocol. This directly affects the claim that the five-component definition and verification ladder capture essential, non-arbitrary distinctions rather than post-hoc categories.
Authors: We agree that the current manuscript omits critical details on corpus construction. The fifty loops were drawn from publicly available practitioner examples and open-source agent repositories. In revision we will add a dedicated subsection 'Corpus Construction and Annotation Protocol' that states: the collection sources and cutoff date; explicit inclusion criteria (a loop must specify at least trigger, goal, and verification to qualify); exclusion criteria (incomplete or non-reusable fragments discarded); and the single-author primary coding process with co-author spot checks. We will explicitly note the absence of formal inter-rater reliability metrics as a limitation and the risk of author bias, while stressing that the full annotated corpus is released publicly so others can replicate or extend the coding. These additions will allow readers to evaluate whether the five-component distinctions and verification ladder are load-bearing rather than post-hoc. revision: yes
-
Referee: [Anatomy and taxonomy] Taxonomy and definition section: The five-component anatomy and five-level verification ladder are presented as capturing distinctions from prompts and harness plumbing, but no systematic comparison against existing prompt-engineering or agent-taxonomy literature is supplied to demonstrate that the categories are reproducible or load-bearing rather than author-interpreted.
Authors: The taxonomy is derived from the operational definition of an external, reusable loop specification that sits outside both natural-language prompts and the harness's internal perceive-act cycle. We acknowledge, however, that the manuscript does not supply a systematic side-by-side mapping to prior work. In revision we will add a concise comparative subsection (or table) that situates the five components and verification ladder against representative prompt-engineering taxonomies (e.g., CoT, ToT, ReAct-style prompting) and agent-framework categorizations (e.g., memory and tool-use patterns in LangChain/AutoGen). The comparison will highlight that our contribution centers on the bounded, externally specified nature of the loop artifact and the autonomous-verification ladder, thereby clarifying both overlap and differentiation without overstating novelty. We will also tie the existing design-principles section more explicitly to this taxonomy. revision: yes
Circularity Check
No circularity: definitional framework and descriptive corpus analysis
full rationale
The paper advances a conceptual framework by defining loop specifications (trigger, goal, verification step, stopping rule, memory) and a five-level verification ladder, then applies this taxonomy descriptively to a hand-coded corpus of 50 loops. No equations, fitted parameters, predictions, or derivations appear. The central claims rest on explicit definitional distinctions and observed statistics (e.g., 70% autonomous verification) rather than any reduction of outputs to inputs by construction. The corpus is presented as illustrative data selected by the authors, but the paper makes no claim that the taxonomy is derived from or validated against external benchmarks in a way that creates self-referential fitting. Self-citation is absent. This is a standard non-circular proposal of new terminology and taxonomy.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.01691 2022
-
[2]
ReST meets ReAct: Self-improvement for multi-step reasoning llm agent.arXiv preprint, 2023
Renat Aksitov, Sobhan Miryoosefi, Zonglin Li, Daliang Li, Sheila Babayan, Kavya Kop- parapu, Zachary Fisher, Ruiqi Guo, Sushant Prakash, Pranesh Srinivasan, Manzil Zaheer, Felix Yu, and Sanjiv Kumar. ReST meets ReAct: Self-improvement for multi-step reasoning llm agent.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2312.10003. 17
-
[3]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to retrieve, generate, and critique through self-reflection.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2310.11511
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.11511 2023
-
[4]
Stay Focused: Problem Drift in Multi-Agent Debate
Jonas Becker, Lars Benedikt Kaesberg, Andreas Stephan, Jan Philip Wahle, Terry Ruas, and Bela Gipp. Stay focused: Problem drift in multi-agent debate.arXiv preprint, 2025. Preprint, arXiv. doi:10.48550/arXiv.2502.19559
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.19559 2025
-
[5]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690. AAA...
-
[6]
Demonstrat- ing specification gaming in reasoning models.arXiv preprint, 2025
Alexander Bondarenko, Denis Volk, Dmitrii Volkov, and Jeffrey Ladish. Demonstrat- ing specification gaming in reasoning models.arXiv preprint, 2025. Preprint, arXiv. doi:10.48550/arXiv.2502.13295
-
[7]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. AgentVerse: Facilitating multi-agent col- laboration and exploring emergent behaviors.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.10848
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10848 2023
-
[8]
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, Buck Shlegeris, Jacob Steinhardt, Ethan Perez, and Evan Hubinger. Sycophancy to subterfuge: Investi- gating reward-tampering in large language models.arXiv preprint, 2024. Preprint, arXiv. doi:10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.10162 2024
-
[9]
Chain-of-Verification Reduces Hallucination in Large Language Models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celiky- ilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2309.11495
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.11495 2023
-
[10]
Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective. arXiv preprint, 2019. Preprint, arXiv. doi:10.48550/arXiv.1908.04734
-
[11]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, et al. A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial super intelligence.arXiv preprint, 2025. Preprint, arXiv. doi:10.48550/arXiv.2507.21046
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21046 2025
-
[12]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on LLM-as-a-judge.arXiv preprint, 2024. Preprint, arXiv. doi:10.48550/arXiv.2411.15594
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594 2024
-
[13]
Reasoning with language model is planning with world model.arXiv preprint,
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model.arXiv preprint,
-
[14]
Reasoning with Language Model is Planning with World Model
Preprint, arXiv. doi:10.48550/arXiv.2305.14992
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.14992
-
[15]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant.arXiv preprint, 2025. Preprint, arXiv. doi:10.48550/arXiv.2502.01390. 18
-
[16]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta program- ming for a multi-agent collaborative framework.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.00352
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.00352 2023
-
[17]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2310.01798
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01798 2023
-
[18]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint, 2022. Preprint, arXiv. doi:1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.05608 2022
-
[19]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023. doi:10.1145/3571730
-
[20]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. MRKL systems: A modular, neuro-symbolic architecture that combines large language models, external knowledg...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.00445 2022
-
[21]
J. O. Kephart and D. M. Chess. The vision of autonomic computing.Computer, 36(1):41–50,
-
[22]
doi:10.1109/MC.2003.1160055
-
[23]
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks.arXiv preprint, 2022. Preprint, arXiv. doi:10.48550/arXiv.2210.02406
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.02406 2022
-
[24]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. Encouraging divergent thinking in large lan- guage models through multi-agent debate.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.19118
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.19118 2023
-
[25]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. LLM+P: Empowering large language models with optimal planning proficiency. arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2304.11477
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.11477 2023
-
[26]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long con- texts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi:10.1162/tacl_a_00638
-
[27]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating llms as agents.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.03688 2023
-
[28]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegr- effe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bod- hisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback.arXiv preprint, 2023. Preprint, arXiv. doi:1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17651 2023
-
[29]
Jane Pan, He He, Samuel R. Bowman, and Shi Feng. Spontaneous reward hacking in iterative self-refinement.arXiv preprint, 2024. Preprint, arXiv. doi:10.48550/arXiv.2407.04549
-
[30]
ART: Automatic multi-step reasoning and tool-use for large language models
Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. ART: Automatic multi-step reasoning and tool-use for large language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2303.09014
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.09014 2023
-
[31]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22. ACM, 2023. doi:10.1145/3586183.3606763
-
[32]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.15334
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.15334 2023
-
[33]
Smith, and Mike Lewis
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models.arXiv preprint,
-
[34]
Measuring and Narrowing the Compositionality Gap in Language Models
Preprint, arXiv. doi:10.48550/arXiv.2210.03350
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03350
-
[35]
ChatDev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2307.07924
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.07924 2023
-
[36]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world apis.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.16789 2023
-
[37]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2302.04761
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761 2023
-
[38]
HuggingGPT: Solving ai tasks with chatgpt and its friends in hugging face.arXiv preprint,
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving ai tasks with chatgpt and its friends in hugging face.arXiv preprint,
-
[39]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Preprint, arXiv. doi:10.48550/arXiv.2303.17580
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17580
-
[40]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2303.11366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366 2023
-
[41]
Cognitive Architectures for Language Agents
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths. Cognitive architectures for language agents.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2309.02427
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.02427 2023
-
[42]
AdaPlanner: Adaptive planning from feedback with language models.arXiv preprint, 2023
Haotian Sun, Yuchen Zhuang, Lingkai Kong, Bo Dai, and Chao Zhang. AdaPlanner: Adaptive planning from feedback with language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.16653. 20
-
[43]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.16291
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.16291 2023
-
[44]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024. doi:10.1007/s11704-024-40231-1
-
[45]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.04091
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.04091 2023
-
[46]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint, 2022. Preprint, arXiv. doi:10.48550/arXiv.2203.11171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2022
-
[47]
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, and Yitao Liang. Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2302.01560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.01560 2023
-
[48]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.arXiv preprint, 2022. Preprint, arXiv. doi:10.48550/arXiv.2201.11903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2022
-
[49]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen llm applications via multi-agent conversation.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2308.08155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[50]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Jun- zhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2309.07864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.07864 2023
-
[51]
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, and Dongkuan Xu. ReWOO: Decoupling reasoning from observations for efficient augmented language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.18323
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.18323 2023
-
[52]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering.arXiv preprint, 2024. Preprint, arXiv. doi:10.48550/arXiv.2405.15793
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.15793 2024
-
[53]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2305.10601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601 2023
-
[54]
ReAct: Synergizing reasoning and acting in language models.arXiv preprint,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint,
-
[55]
ReAct: Synergizing Reasoning and Acting in Language Models
Preprint, arXiv. doi:10.48550/arXiv.2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629
-
[56]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, et al. The landscape of agentic reinforcement learning for LLMs: A survey.arXiv preprint, 2025. Preprint, arXiv. doi:10.48550/arXiv.2509.02547. 21
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.02547 2025
-
[57]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint, 2025. Preprint, arXiv. doi:10.48550/arXiv.2510.04618
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.04618 2025
-
[58]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. arXiv preprint, 2023. Preprint, arXiv. doi:10.48550/arXiv.2310.04406
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.04406 2023
-
[59]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint, 2022. Preprint, arXiv. doi:10.48550/arXiv.2205.10625
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.10625 2022
-
[60]
Pei Zhou, Jay Pujara, Xiang Ren, Xinyun Chen, Heng-Tze Cheng, Quoc V. Le, Ed H. Chi, Denny Zhou, Swaroop Mishra, and Huaixiu Steven Zheng. Self-Discover: Large language models self-compose reasoning structures.arXiv preprint, 2024. Preprint, arXiv. doi:10.48550/arXiv.2402.03620. 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.