AlgoBench: Benchmarking Algorithmic Adaptation in Code Generation
Pith reviewed 2026-07-02 18:06 UTC · model grok-4.3
The pith
AlgoBench generates novel algorithmic problems by shifting constraints so original solutions fail, showing models struggle to adapt beyond functional correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
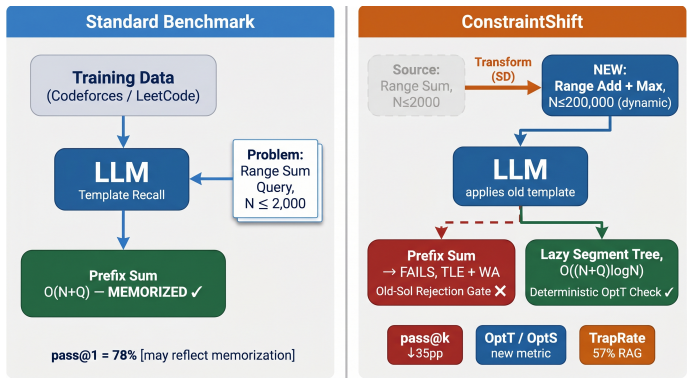
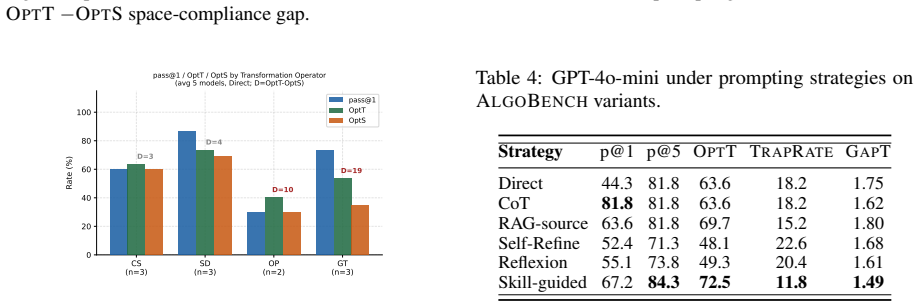
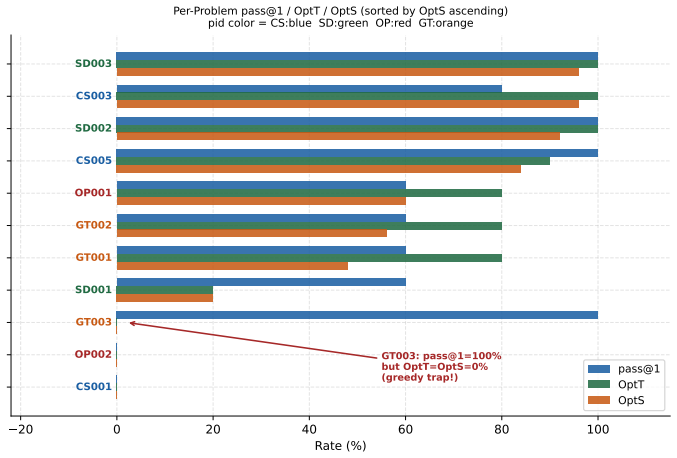
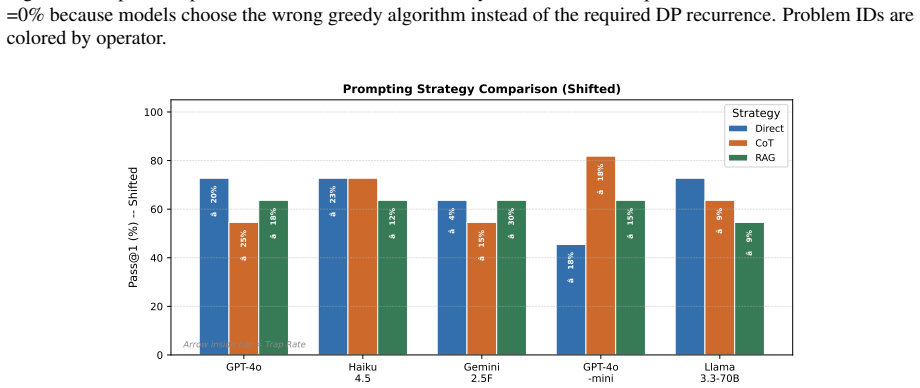
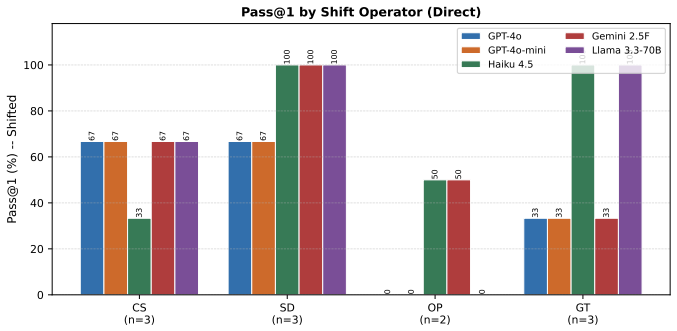
ALGOBENCH builds novel algorithmic problems from known competitive-programming problems via constraint-shifting transformations that make the original reference algorithm fail, and pairs them with complexity-aware metrics to demonstrate that models often produce functionally correct but asymptotically unsuitable solutions.
What carries the argument
Constraint-shifting transformations that produce problems requiring a different algorithm from the source while remaining valid and solvable.
If this is right
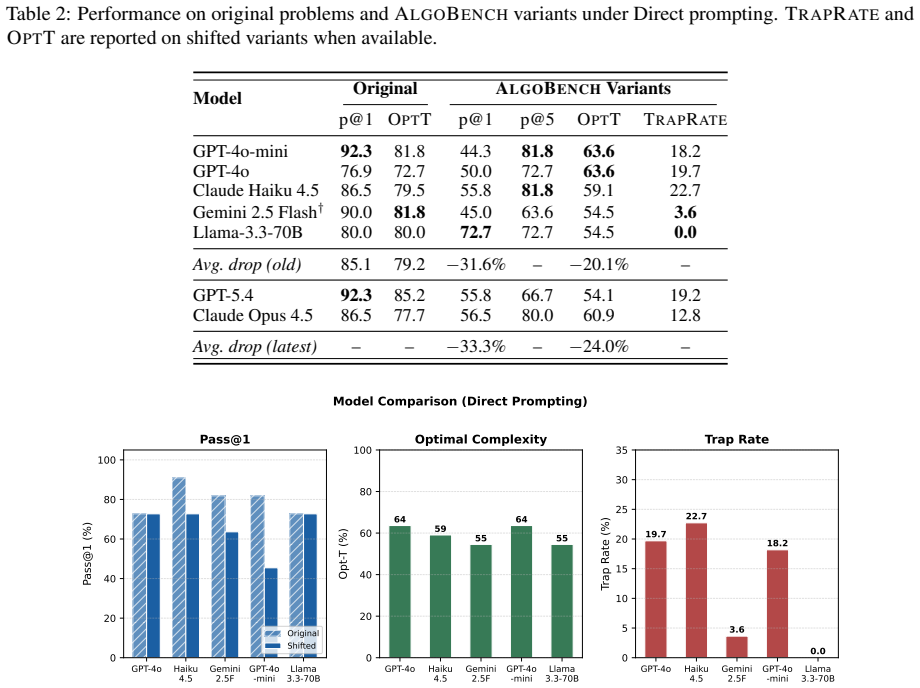
- Performance drops sharply on ALGOBENCH variants across multiple LLMs and prompting strategies.
- Retrieval can increase reuse of the old algorithm.
- Many correct-looking solutions fail to meet the required complexity.
- Error analysis shows that failures are mainly algorithmic rather than implementation-level.
Where Pith is reading between the lines
- Existing benchmarks may overestimate algorithmic ability due to public exposure of problems and solutions.
- The transformations offer a way to generate fresh test cases that stay ahead of training data contamination.
- Models could be evaluated or trained specifically on detecting when an algorithm becomes inefficient under new constraints.
- This points to a broader need for benchmarks that separate functional correctness from efficiency reasoning in code generation.
- keywords:[
- algorithmic adaptation
- code generation
- LLMs
Load-bearing premise
The constraint-shifting transformations produce problems that genuinely require different algorithms from the source while remaining valid and solvable, and the complexity-aware metrics correctly distinguish asymptotic suitability independent of implementation artifacts.
What would settle it
An experiment finding no sharp performance drop or complexity failures on ALGOBENCH variants, or where the original algorithm still solves the transformed problems optimally, would challenge the central claim.
Figures
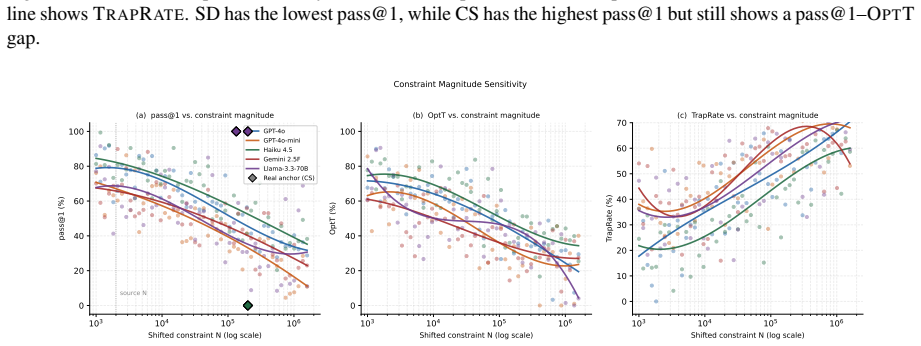
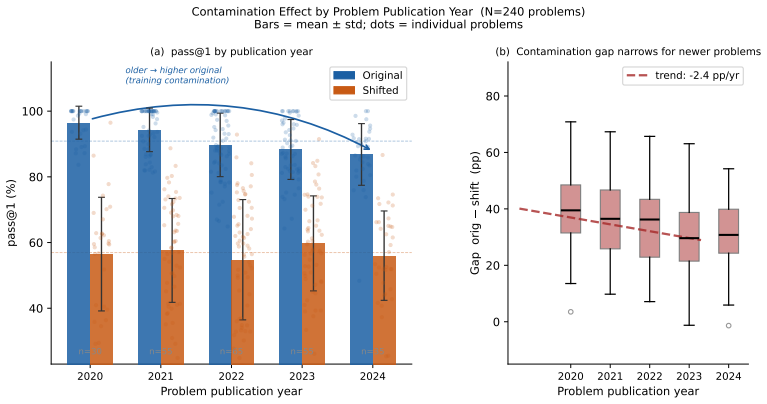
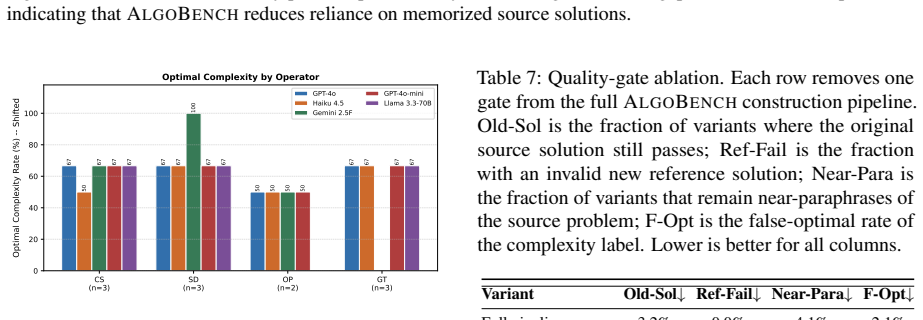
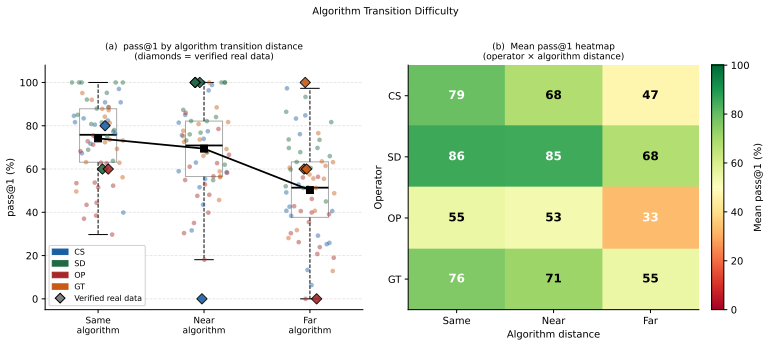

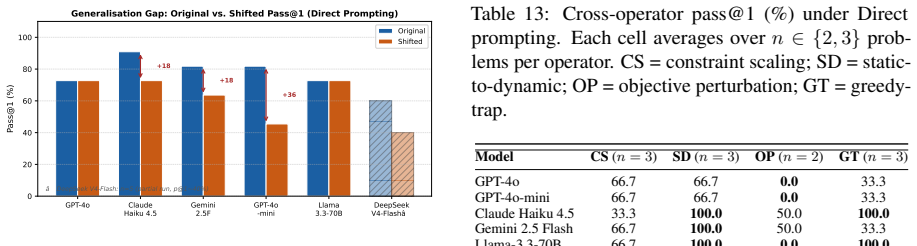
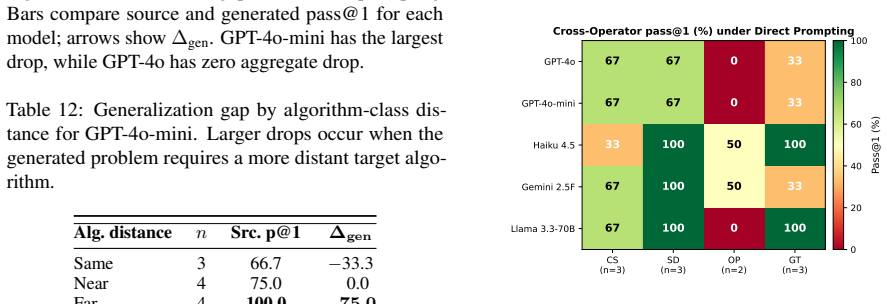
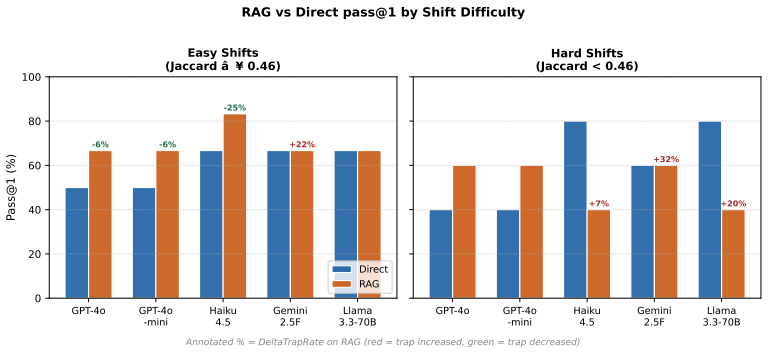
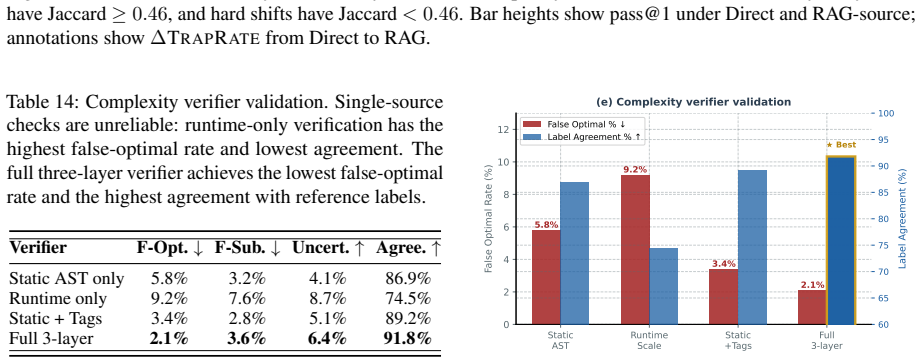
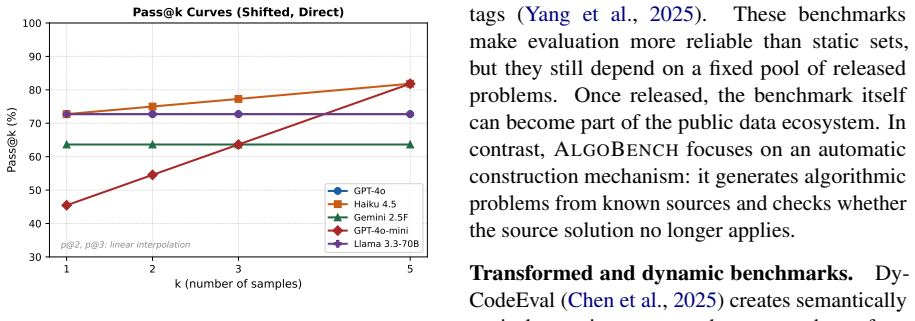
read the original abstract
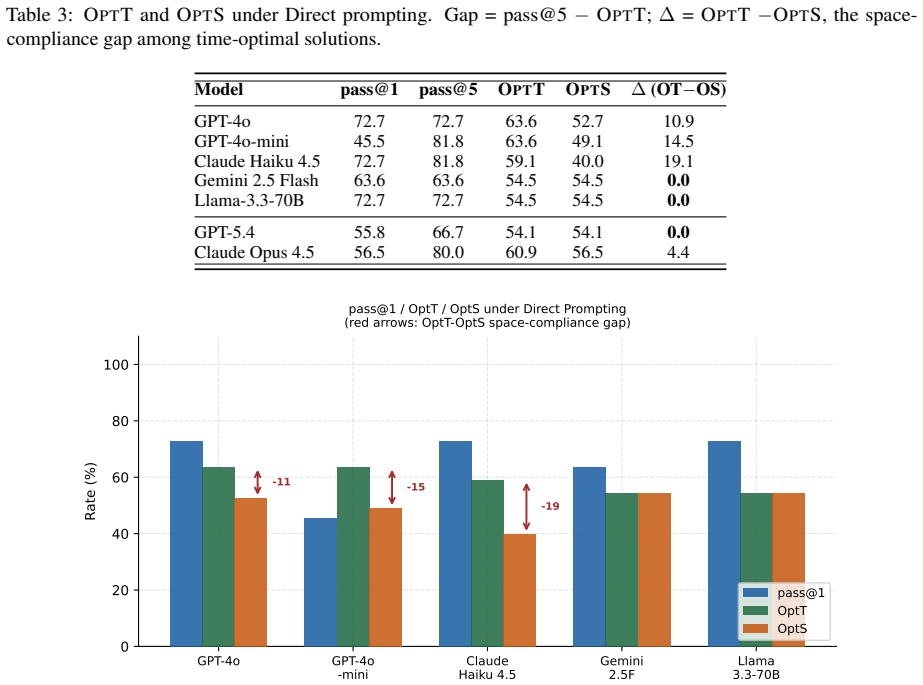
High pass rates on established programming benchmarks such as HumanEval and LiveCodeBench do not always show whether a model can reason about algorithms. Many fixed benchmarks eventually become part of the public training ecosystem through released problem statements, editorials, and generated solutions, allowing later models to improve partly by exposure rather than by stronger algorithmic ability. We introduce ALGOBENCH, a framework that automatically builds novel algorithmic problems from known competitive-programming problems through structured constraint-shifting transformations. Each accepted ALGOBENCH variant is traceable to a source problem, but must make the original reference algorithm fail. Beyond pass@$k$, we introduce complexity-aware metrics -- including OPTT, OPTS, TRAPRATE, GAPT, and CONSENS -- to test whether a solution is not only functionally correct but also asymptotically suitable for the generated problem. Experiments across multiple LLMs and prompting strategies show that performance drops sharply on ALGOBENCH variants, retrieval can increase reuse of the old algorithm, and many correct-looking solutions fail to meet the required complexity. Error analysis shows that failures are mainly algorithmic rather than implementation-level, suggesting that ALGOBENCH evaluates adaptation beyond functional correctness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ALGOBENCH, a framework that automatically generates novel algorithmic problems from competitive-programming sources via structured constraint-shifting transformations. Each accepted variant is required to cause the original reference algorithm to fail, and the work adds complexity-aware metrics (OPTT, OPTS, TRAPRATE, GAPT, CONSENS) that go beyond functional correctness to assess asymptotic suitability. Experiments across LLMs and prompting strategies report sharp performance drops on the variants, increased reuse of the source algorithm under retrieval, and that many functionally correct solutions fail the complexity metrics, with error analysis attributing failures primarily to algorithmic rather than implementation issues.
Significance. If the transformations reliably force a change in asymptotic class and the new metrics correctly isolate asymptotic suitability from implementation artifacts, ALGOBENCH would address a genuine limitation of existing benchmarks that have become contaminated by training data. The approach of traceable, automatically generated variants with explicit failure conditions for the source algorithm is a concrete step toward evaluating adaptation rather than recall.
major comments (3)
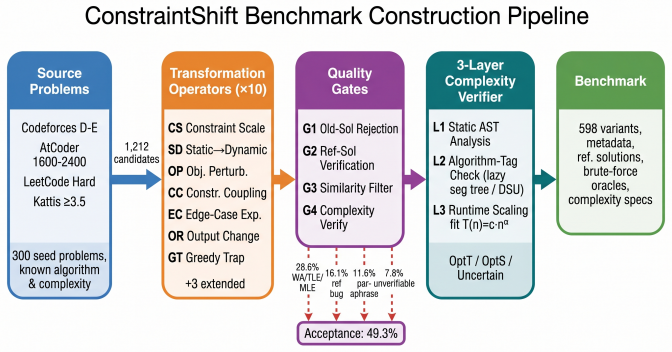
- [Abstract / Variant Generation] Abstract and § on variant generation: the central claim that 'each accepted ALGOBENCH variant ... must make the original reference algorithm fail' and that 'failures are mainly algorithmic rather than implementation-level' rests on the unshown procedures for (a) verifying that the source algorithm indeed fails on the transformed instance and (b) confirming that the transformation necessitates a different asymptotic class. No acceptance criteria, number of generated vs. accepted variants, or validation examples are supplied.
- [Abstract / Metrics] Abstract and § on metrics: the metrics OPTT, OPTS, TRAPRATE, GAPT, and CONSENS are introduced to test asymptotic suitability, yet the manuscript supplies neither their formal definitions, computation procedures, nor any validation that they distinguish asymptotic class independently of constant factors or test-case artifacts. Without these, the reported performance drops and error analysis cannot be evaluated.
- [Experiments] Experiments: the abstract states that 'performance drops sharply' and that 'retrieval can increase reuse,' but reports neither the number of problems/variants tested, the statistical significance of the drops, nor the prompting and retrieval setups in sufficient detail to reproduce or assess the strength of the algorithmic-vs-implementation distinction.
minor comments (1)
- [Abstract] The abstract mentions 'many correct-looking solutions fail to meet the required complexity' but does not define what constitutes a 'correct-looking' solution or how functional correctness was verified on the new constraints.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional detail and formalization will strengthen the manuscript. We address each major comment below and will incorporate the requested clarifications, definitions, and experimental details in the revised version.
read point-by-point responses
-
Referee: [Abstract / Variant Generation] Abstract and § on variant generation: the central claim that 'each accepted ALGOBENCH variant ... must make the original reference algorithm fail' and that 'failures are mainly algorithmic rather than implementation-level' rests on the unshown procedures for (a) verifying that the source algorithm indeed fails on the transformed instance and (b) confirming that the transformation necessitates a different asymptotic class. No acceptance criteria, number of generated vs. accepted variants, or validation examples are supplied.
Authors: We agree that the verification procedures, acceptance criteria, and quantitative details on variant generation were insufficiently documented. The revised manuscript will include a new subsection under Variant Generation that (i) specifies the exact failure-verification procedure (including test-case generation and execution checks against the reference implementation), (ii) describes the asymptotic-class validation step, (iii) reports the total number of generated and accepted variants together with acceptance rates, and (iv) provides concrete validation examples with before/after constraint shifts and the corresponding reference-algorithm failure evidence. These additions will make the central claim fully reproducible. revision: yes
-
Referee: [Abstract / Metrics] Abstract and § on metrics: the metrics OPTT, OPTS, TRAPRATE, GAPT, and CONSENS are introduced to test asymptotic suitability, yet the manuscript supplies neither their formal definitions, computation procedures, nor any validation that they distinguish asymptotic class independently of constant factors or test-case artifacts. Without these, the reported performance drops and error analysis cannot be evaluated.
Authors: We acknowledge that the formal definitions and validation of the complexity-aware metrics were omitted. In the revision we will add a dedicated Metrics section containing (a) precise mathematical definitions and pseudocode for OPTT, OPTS, TRAPRATE, GAPT, and CONSENS, (b) the exact procedure used to compute each metric from execution traces, and (c) a validation subsection demonstrating that the metrics separate asymptotic classes on controlled synthetic instances while remaining insensitive to constant-factor and test-case-size artifacts. This will allow readers to assess the reported performance drops and error analysis. revision: yes
-
Referee: [Experiments] Experiments: the abstract states that 'performance drops sharply' and that 'retrieval can increase reuse,' but reports neither the number of problems/variants tested, the statistical significance of the drops, nor the prompting and retrieval setups in sufficient detail to reproduce or assess the strength of the algorithmic-vs-implementation distinction.
Authors: We agree that the experimental section lacked the necessary quantitative and reproducibility details. The revised manuscript will expand the Experiments section to report (i) the exact number of source problems and accepted variants evaluated, (ii) statistical significance tests (including p-values and confidence intervals) for all reported performance drops, and (iii) complete prompting templates, retrieval configurations, and hyper-parameters for every LLM and strategy tested. These additions will enable full reproduction and strengthen the distinction between algorithmic and implementation failures. revision: yes
Circularity Check
No circularity; benchmark and metrics defined independently of performance claims
full rationale
The paper constructs ALGOBENCH via constraint-shifting transformations that are required to make the source algorithm fail, then defines new metrics (OPTT, OPTS, TRAPRATE, GAPT, CONSENS) to evaluate asymptotic suitability separately from functional correctness. No equations, fitted parameters, or self-citations appear in the provided text. The reported performance drops, retrieval effects, and error analysis are empirical results obtained by applying these independently specified transformations and metrics to LLMs; they do not reduce by construction to the input definitions or prior author work. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constraint-shifting transformations exist that make the original reference algorithm fail while keeping the problem well-defined and solvable by some other algorithm.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025a. Introducing Claude Haiku 4.5. https://www.anthropic.com/news/ claude-haiku-4-5. Accessed: 2026-05-20. Anthropic. 2025b. Introducing Claude Opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5. Accessed: 2026-05-26. AtCoder Inc
2026
-
[2]
https://atcoder.jp/
Atcoder. https://atcoder.jp/. Accessed: 2026-05-14. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton
2026
-
[3]
Program Synthesis with Large Language Models
Program synthesis with large language models.arXiv preprint arXiv:2108.07732. Jialun Cao, Yuk-Kit Chan, Zixuan Ling, Wenxuan Wang, Shuqing Li, Mingwei Liu, Ruixi Qiao, Yuting Han, Chaozheng Wang, Boxi Yu, Pinjia He, Shuai Wang, Zibin Zheng, Michael R. Lyu, and Shing-Chi Cheung
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Rigor, reliability, and reproducibility matter: A decade-scale survey of 572 code bench- marks.Preprint, arXiv:2501.10711. Version 4 re- vised in
-
[5]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Simin Chen, Pranav Pusarla, and Baishakhi Ray
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Dynamic benchmarking of reasoning capabilities in code large language models under data contamina- tion.Preprint, arXiv:2503.04149. Codeforces
-
[7]
https://codeforces
Codeforces. https://codeforces. com/. Accessed: 2026-05-14. Gheorghe Comanici and 1 others
2026
-
[8]
Time travel in LLMs: Tracing data contamination in large language models.arXiv preprint arXiv:2308.08493. Dan Hendrycks, Steven Basart, Saurav Kadavath, Man- tas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Ja- cob Steinhardt
-
[9]
Measuring Coding Challenge Competence With APPS
Measuring coding chal- lenge competence with APPS.arXiv preprint arXiv:2105.09938. Paul Jaccard
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Live- CodeBench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974. Kattis
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
https://open.kattis.com/
Kattis. https://open.kattis.com/. Accessed: 2026-05-14. LeetCode
2026
-
[12]
https://leetcode.com/
Leetcode. https://leetcode.com/. Accessed: 2026-05-14. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, Sebastian Riedel, and Douwe Kiela
2026
-
[13]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Ling- ming Zhang
Humanity’s last code exam: Can advanced LLMs conquer human’s hardest code competition? arXiv preprint arXiv:2506.12713. Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Ling- ming Zhang
-
[14]
Is your code generated by Chat- GPT really correct? rigorous evaluation of large lan- guage models for code generation.arXiv preprint arXiv:2305.01210. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Self-refine: Iterative re- finement with self-feedback.arXiv preprint arXiv:2303.17651. Meta AI
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
https://developer.meta.com/ai/docs/ model-cards-and-prompt-formats/llama3_3/
Llama 3.3 Model Card. https://developer.meta.com/ai/docs/ model-cards-and-prompt-formats/llama3_3/ . Accessed: 2026-05-20. OpenAI
2026
-
[17]
https:// openai.com/index/gpt-4o-system-card/
GPT-4o System Card. https:// openai.com/index/gpt-4o-system-card/ . Ac- cessed: 2026-05-20. OpenAI
2026
-
[18]
https:// openai.com/index/introducing-gpt-5-4/
Introducing GPT-5.4. https:// openai.com/index/introducing-gpt-5-4/ . Ac- cessed: 2026-05-26. Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer
2026
-
[19]
Detecting Pretraining Data from Large Language Models
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789. Noah Shinn, Federico Cassano, Edward Berman, Ash- win Gopinath, Karthik Narasimhan, and Shunyu Yao
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Livebench: A challenging, contamination-limited llm benchmark. Preprint, arXiv:2406.19314. Lei Yang, Renren Jin, Ling Shi, Jianxiang Peng, Yue Chen, and Deyi Xiong
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Probench: Benchmark- ing large language models in competitive program- ming.arXiv preprint arXiv:2502.20868. Shang Zhou, Zihan Zheng, Kaiyuan Liu, Zeyu Shen, Zerui Cheng, Zexing Chen, Hansen He, Jianzhu Yao, Huanzhi Mao, Qiuyang Mang, Tianfu Fu, Beichen Li, Dongruixuan Li, Wenhao Chai, Zhuang Liu, Alek- sandra Korolova, Peter Henderson, Natasha Jaques, Pr...
-
[23]
Autocode: Llms as problem setters for competitive program- ming.Preprint, arXiv:2510.12803. A Detailed Transformation Operators This section gives the full definitions of the ten transformation operators used by ALGOBENCH. Each operator takes a source problem with a known reference algorithm and produces a generated prob- lem whose solution requires a cha...
-
[24]
This gate ensures that every accepted problem has a certified algorithmic target
A candidate is rejected if the verifier marks the reference solution as UNCERTAINor reports a mis- match with the target time or space complexity. This gate ensures that every accepted problem has a certified algorithmic target. C Example Benchmark Problems Example 1: Range Query Shift (CS + SD) Source.Given a static array of n≤10 5 inte- gers, answer Q≤1...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.