Identifying and Resolving Pitfalls of Knowledge-Based VQA Benchmarks: Auditing, Repairing, and Augmenting
Pith reviewed 2026-07-02 19:11 UTC · model grok-4.3
The pith
Existing KB-VQA benchmarks systematically violate assumptions on answer derivability, question clarity, and visual disambiguation, rendering accuracy a misleading metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
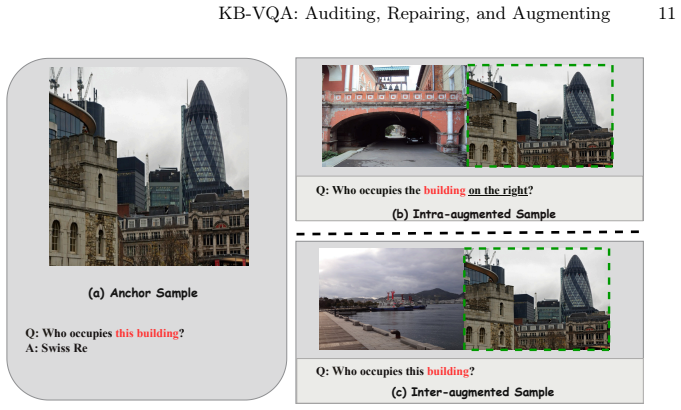
Existing KB-VQA benchmarks contain substantial instances with missing or contradicted answers and underspecified questions, and rely on visually trivial single-entity scenes. These flaws render accuracy a misleading metric and lead to distorted model rankings even with controlled architectures. A principled audit-and-repair protocol restores answer derivability and question clarity, while a controlled multi-entity augmentation protocol introduces visual ambiguity to challenge initial retrieval and grounded reasoning. Re-evaluation under corrected and augmented settings yields markedly different performance trends.
What carries the argument
An audit-and-repair protocol that identifies and corrects violations of answer derivability and question clarity, together with a multi-entity augmentation protocol that adds visual ambiguity to test grounded reasoning.
If this is right
- Accuracy scores on existing KB-VQA benchmarks do not reliably indicate knowledge-grounded reasoning capabilities.
- Model rankings become distorted when benchmarks contain non-derivable answers or underspecified questions.
- Single-entity visual scenes allow models to bypass the need for visual-to-knowledge mapping.
- Re-evaluation after repair and augmentation produces different performance trends across models.
- Evaluation protocols should prioritize verifiable reasoning over simple answer matching.
Where Pith is reading between the lines
- The same audit approach could be used to check hidden assumption violations in other vision-language or knowledge-retrieval benchmarks.
- Augmenting scenes with multiple entities may serve as a template for testing disambiguation in additional multi-modal tasks.
- Distorted rankings could lead to incorrect conclusions about which models are ready for applications that require external knowledge lookup.
- Future benchmarks may need explicit checks that each answer is supported by the knowledge base and that each question supplies enough constraints.
Load-bearing premise
The audit protocol correctly detects and fixes violations of answer derivability and question clarity without introducing new errors, and the multi-entity augmentation specifically tests initial retrieval and grounding rather than unrelated factors.
What would settle it
Applying the audit-and-repair and multi-entity augmentation protocols to existing KB-VQA datasets and then re-running the same models to determine whether accuracy scores and relative rankings change substantially.
Figures














read the original abstract
Knowledge-Based Visual Question Answering (KB-VQA) aims to evaluate whether Visual Language Models (VLMs) can retrieve, ground, and reason over external structured knowledge beyond visual evidence. In practice, answer accuracy is widely adopted as the primary evaluation metric, implicitly treating correctness as a proxy for knowledge-grounded reasoning. However, for existing KB-VQA benchmarks, this proxy relies on critical assumptions that are often overlooked and rendered unreliable by benchmark issues: annotated answer must be derivable from the associated knowledge base, question must be well-posed with sufficient constraints, and visual setting must meaningfully require grounded disambiguation. In this work, we show that these assumptions are systematically violated in existing KB-VQA benchmarks. Our audit reveals substantial instances with missing or contradicted answers and underspecified questions that render accuracy a misleading metric. Furthermore, we find that existing datasets rely on visually trivial, single-entity scenes that bypass the need for sophisticated visual-to-knowledge mapping. We demonstrate that even with controlled architectures, these flaws lead to distorted model rankings and overestimations of reasoning capabilities. To address this, we introduce (1) a principled audit-and-repair protocol that restores answer derivability and question clarity, and (2) a controlled multi-entity augmentation protocol that introduces visual ambiguity to challenge initial retrieval and grounded reasoning. Re-evaluation under corrected and augmented settings yields markedly different performance trends. Our findings call for rethinking evaluation protocols and designing more interaction-aware KB-VQA benchmarks that prioritize verifiable reasoning over simple matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing KB-VQA benchmarks systematically violate three assumptions required for answer accuracy to measure knowledge-grounded reasoning: annotated answers must be derivable from the KB, questions must be well-posed with sufficient constraints, and visual settings must require grounded disambiguation. An audit identifies substantial instances of missing/contradicted answers and underspecified questions, plus reliance on visually trivial single-entity scenes. The authors introduce an audit-and-repair protocol to restore derivability and clarity, plus a controlled multi-entity augmentation to introduce visual ambiguity, and show that re-evaluation produces markedly different performance trends and model rankings.
Significance. If the audit protocol proves reliable and the violations are shown to be systematic and load-bearing, the work would be significant for the KB-VQA community by demonstrating that accuracy-based rankings can be distorted and by providing concrete protocols for repairing and augmenting benchmarks to better test retrieval and grounded reasoning.
major comments (2)
- [Audit protocol] Audit protocol description: the operationalization of 'answer derivability from the KB' and 'question well-posedness' lacks explicit decision rules (e.g., entailment check, KB query template, or inter-annotator protocol), which is load-bearing for the claim of systematic violations and for attributing re-evaluation differences to the identified flaws rather than to the repair choices themselves.
- [Results] Results section: no quantitative counts (e.g., number or percentage of instances with missing/contradicted answers or underspecified questions) or concrete examples are supplied, which is required to substantiate the assertion of 'substantial instances' and the claim that these flaws lead to distorted rankings.
minor comments (1)
- [Abstract] The abstract and introduction would be strengthened by including at least one concrete example of a violation (missing answer, contradicted answer, or underspecified question) to illustrate the audit findings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional clarity and evidence will strengthen the manuscript. We agree that both the audit protocol and results sections require more explicit operationalization and quantitative support. We will revise the paper to address these points in detail.
read point-by-point responses
-
Referee: [Audit protocol] Audit protocol description: the operationalization of 'answer derivability from the KB' and 'question well-posedness' lacks explicit decision rules (e.g., entailment check, KB query template, or inter-annotator protocol), which is load-bearing for the claim of systematic violations and for attributing re-evaluation differences to the identified flaws rather than to the repair choices themselves.
Authors: We agree that the manuscript currently lacks explicit decision rules for operationalizing answer derivability and question well-posedness. In the revision, we will add a dedicated subsection detailing the decision rules, including KB query templates for entailment verification, specific criteria for identifying missing or contradicted answers, and an inter-annotator protocol with agreement metrics. This will allow readers to reproduce the audit and confirm that performance differences stem from the identified violations rather than arbitrary repair decisions. revision: yes
-
Referee: [Results] Results section: no quantitative counts (e.g., number or percentage of instances with missing/contradicted answers or underspecified questions) or concrete examples are supplied, which is required to substantiate the assertion of 'substantial instances' and the claim that these flaws lead to distorted rankings.
Authors: We acknowledge that the current results section does not include quantitative counts or concrete examples, which weakens the substantiation of 'substantial instances.' The revised manuscript will add a table reporting exact counts and percentages of affected instances across benchmarks (e.g., percentage with missing answers, contradicted answers, and underspecified questions), along with 3-4 representative examples per violation type. We will also include an analysis showing how these flaws correlate with changes in model rankings under the repaired setting. revision: yes
Circularity Check
No significant circularity; audit protocol is an independent methodological contribution.
full rationale
The paper's central claims rest on applying a newly introduced audit-and-repair protocol to existing external KB-VQA benchmarks, identifying violations of answer derivability and question well-posedness, then demonstrating altered model rankings under the repaired and augmented settings. This chain does not reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations; the protocol is presented as an external procedure whose outputs (flagged instances) are not presupposed by its own criteria. The derivation remains self-contained against the benchmarks being audited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 16 Q. Ma et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Proceedings of the IEEE international confer- ence on computer vision
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: Vqa: Visual question answering. In: Proceedings of the IEEE international confer- ence on computer vision. pp. 2425–2433 (2015)
2015
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: human language technologies
Changpinyo, S., Kukliansy, D., Szpektor, I., Chen, X., Ding, N., Soricut, R.: All you may need for vqa are image captions. In: Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: human language technologies. pp. 1947–1963 (2022)
2022
-
[5]
Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., Liu, Z.: Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self- knowledge distillation. arXiv preprint arXiv:2402.03216 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [6]
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cocchi, F., Moratelli, N., Cornia, M., Baraldi, L., Cucchiara, R.: Augmenting mul- timodal llms with self-reflective tokens for knowledge-based visual question an- swering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9199–9209 (June 2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Compagnoni, A., Morini, M., Sarto, S., Cocchi, F., Caffagni, D., Cornia, M., Baraldi, L., Cucchiara, R.: Reag: Reasoning-augmented generation for knowledge- based visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11901–11911 (2026)
2026
-
[9]
arXiv preprint arXiv:2504.17547 (2025)
Deng, J., Wu, Z., Huo, H., Xu, G.: A comprehensive survey of knowledge-based vision question answering systems: The lifecycle of knowledge in visual reasoning task. arXiv preprint arXiv:2504.17547 (2025)
-
[10]
IEEE Transactions on Big Data (2025)
Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P.E., Lomeli, M., Hosseini, L., Jégou, H.: The faiss library. IEEE Transactions on Big Data (2025)
2025
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6904–6913 (2017)
2017
-
[12]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hong, Y., Gu, J., Lou, Y., Fan, L., Yang, Q., Wang, Y., Ding, K., Wu, Y., Xiang, S., Ye, J.: Cc-vqa: Conflict-and correlation-aware method for mitigating knowl- edge conflict in knowledge-based visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5232– 5241 (2026)
2026
-
[14]
arXiv preprint arXiv:2510.14605 (2025)
Hong, Y., Gu, J., Yang, Q., Fan, L., Wu, Y., Wang, Y., Ding, K., Xiang, S., Ye, J.: Knowledge-based visual question answer with multimodal processing, retrieval and filtering. arXiv preprint arXiv:2510.14605 (2025)
-
[15]
ACM Computing Surveys57(10), 1–35 (2025)
Kim, B.S., Kim, J., Lee, D., Jang, B.: Visual question answering: A survey of methods, datasets, evaluation, and challenges. ACM Computing Surveys57(10), 1–35 (2025)
2025
-
[16]
ACM Computing Surveys57(8), 1–36 (2025) KB-VQA: Auditing, Repairing, and Augmenting 17
Kuang, J., Shen, Y., Xie, J., Luo, H., Xu, Z., Li, R., Li, Y., Cheng, X., Lin, X., Han, Y.: Natural language understanding and inference with mllm in visual question answering: A survey. ACM Computing Surveys57(8), 1–36 (2025) KB-VQA: Auditing, Repairing, and Augmenting 17
2025
-
[17]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[18]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al.: Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[20]
Ma, Q., Wu, Q., Zhou, Z., Ma, Y.: Ground then rank: Revisiting knowledge-based vqa with training-free entity identification (2026),https://arxiv.org/abs/2606. 23881
2026
-
[21]
In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition
Marino,K.,Rastegari,M.,Farhadi,A.,Mottaghi,R.:Ok-vqa:Avisualquestionan- swering benchmark requiring external knowledge. In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. pp. 3195–3204 (2019)
2019
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Mensink, T., Uijlings, J., Castrejon, L., Goel, A., Cadar, F., Zhou, H., Sha, F., Araujo, A., Ferrari, V.: Encyclopedic vqa: Visual questions about detailed prop- erties of fine-grained categories. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3113–3124 (2023)
2023
-
[23]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[24]
In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=EVwMw2lVlw
Su, X., Luo, M., Pan, K.W., Chou, T.P., Lal, V., Howard, P.: SK-VQA: Synthetic knowledge generation at scale for training context-augmented multimodal LLMs. In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=EVwMw2lVlw
2025
-
[25]
arXiv preprint arXiv:2402.04252 (2024)
Sun, Q., Wang, J., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, X.: Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252 (2024)
-
[26]
arXiv preprint arXiv:2506.02544 (2025)
Tian, Y., Liu, F., Zhang, J., Hu, Y., Nie, L., et al.: Core-mmrag: Cross-source knowledge reconciliation for multimodal rag. arXiv preprint arXiv:2506.02544 (2025)
-
[27]
Com- munications of the ACM57(10), 78–85 (2014)
Vrandečić, D., Krötzsch, M.: Wikidata: a free collaborative knowledgebase. Com- munications of the ACM57(10), 78–85 (2014)
2014
-
[28]
Wang, P., Wu, Q., Shen, C., Dick, A., Van Den Hengel, A.: Fvqa: Fact-based visual questionanswering.IEEEtransactionsonpatternanalysisandmachineintelligence 40(10), 2413–2427 (2017)
2017
-
[29]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
arXiv preprint arXiv:2505.17670 (2025)
Wu, W., Song, Z., Zhou, K., Shao, Y., Hu, Z., Huang, B.: Towards general contin- uous memory for vision-language models. arXiv preprint arXiv:2505.17670 (2025)
-
[31]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Yan, Y., Xie, W.: Echosight: Advancing visual-language models with wiki knowl- edge. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 1538–1551 (2024)
2024
-
[32]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
IEEE transactions on pattern analysis and machine intelligence46(8), 5625–5644 (2024) 18 Q
Zhang, J., Huang, J., Jin, S., Lu, S.: Vision-language models for vision tasks: A survey. IEEE transactions on pattern analysis and machine intelligence46(8), 5625–5644 (2024) 18 Q. Ma et al
2024
-
[34]
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019) KB-VQA: Auditing, Repairing, and Augmenting 1 A Qualitative Examples of Fixing Outcome In this section we present more qualitative samples ofour fixing outcome. Besides the qualitative example that is removed...
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[35]
Data Mismatch: Answer supported by Wikidata but missing from provided Knowledge Base
Goal: Desired answer '112 - 158'.2. Data Mismatch: Answer supported by Wikidata but missing from provided Knowledge Base. Instead, '131' days is expected.3. Outcome: Change the desired annotated answer to '131' days Summary of Fixing Logic Mismatch Source: Wikipedia hascontradict evidence for the answer. Card 2: KB-VQA Input &Ground Truth Item: Q41960 (Re...
-
[36]
Which season during the year isthe mating period?
Goal: Desired answer 'Spring' exist in evidence.2. Question Underspecified: Answer supported by evidence but moreplausible answers available e.g., explicit months. 3. Outcome: Change question to "Which season during the year isthe mating period?" Summary of Fixing Logic Card 3: KB-VQA Input &Ground Truth Input Question Desired Answer When is the mating pe...
-
[37]
EchoSight: No Mention ×3
CoMEM: 70,000 ×2. EchoSight: No Mention ×3. IBA: 81,000 ×4. ReflectiVA: 66,000 ×5. Wiki-PRF: ...tens of thousands of people. No Exact Number. × Summary of Output Card 4: KB-VQA Input &Ground Truth Input Question Desired Answer How many people can this stadium host? System Input 65,358 Image (Q): (A): (VeteransStadium) EchoSight Top-1 Re-ranked SectionIBA ...
-
[38]
Before fixing, EchoSight select incorrect section from wrong entity
The question is improved with our proposed fixing protocol.2. Before fixing, EchoSight select incorrect section from wrong entity. 3. After fixing, EchoSight can re-rank the correct section to top-1.4. Hence, outcome answer turn from wrong '1951' into correct '1962'. Summary of Fixing and Re-ranking outcome of EchoSight Card 5: KB-VQA Input &Ground Truth ...
1951
-
[39]
The QA pair is improved and fixed with our proposed fixing protocol
-
[40]
Before fixing, EchoSight selects incorrect section
-
[41]
After fixing, EchoSight can correctly pritorize the correct section
-
[42]
In what country did people consider this castle to be theequalofanyothercastle?
Hence, outcome answer turn from wrong '2.39' into correct '1301' and is correctly evaluated with the revised ground truth answer. Summary of Fixing and Re-ranking outcome of EchoSight Card 6: KB-VQA Input & Ground Truth Input Question Before Fixing: Desired Answer Before Fixing: How many kilogram does this vehicle weigh? System Input 1302 Image McLaren 12...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.