Testing Frontier Large Language Models' Physics Literacy in Parallel Physical Worlds
Pith reviewed 2026-07-02 19:16 UTC · model grok-4.3
The pith
Frontier LLMs pass at most 6 out of 15 trials when forced to reason inside three unfamiliar physics frameworks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
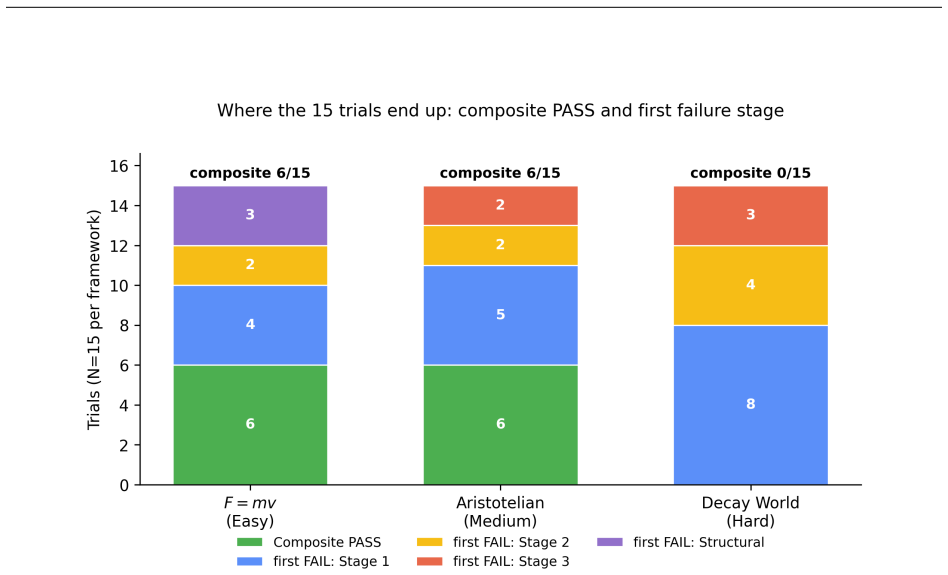
The four-stage diagnostic applied to the F=mv world, Aristotelian mechanics, and Decay World shows that Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro achieve composite pass rates of only 6/15, 6/15, and 0/15 respectively when content and structural correctness are both required (content axis only for Decay World). Models exhibit a qualitative-versus-quantitative asymmetry in Decay World, correctly predicting direction of change yet slipping to standard-physics ratios. LLM-judge reliability does not transfer across frameworks, and Stage 4 self-review wrongly reports no error in at least two-thirds of trials that contain one.
What carries the argument
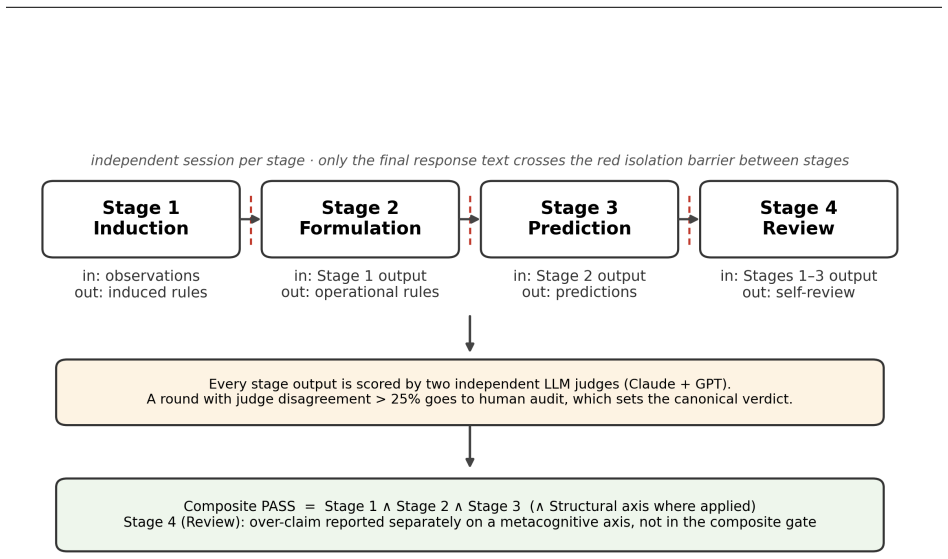
Four-stage diagnostic protocol that evaluates induction, formulation, prediction, and review inside locked parallel physics worlds using pre-registrations, fresh sessions, and dual-LLM judging.
If this is right
- Accuracy-only physics benchmarks cannot distinguish genuine reasoning from pattern recall.
- Models display a systematic qualitative-versus-quantitative asymmetry when operating inside new frameworks.
- LLM-based judges for evaluation do not generalize across different physics worlds.
- Model self-review fails to detect earlier errors in the majority of trials that contain them.
Where Pith is reading between the lines
- The diagnostic could be reused to test inductive reasoning in domains other than physics without changing the protocol structure.
- Persistent reversion to standard-physics ratios suggests that current training data distributions dominate even when explicit instructions require a new framework.
- If the asymmetry holds, training objectives that reward only directional correctness would leave quantitative prediction errors unaddressed.
Load-bearing premise
The constructed parallel worlds and four-stage protocol with locked pre-registrations and dual-LLM judging successfully isolate genuine inductive reasoning from pattern recall or contamination.
What would settle it
A fourth novel physics world, constructed identically to the three tested worlds, on which the same models and protocol produce pass rates above 12/15.
Figures
read the original abstract
Current large-language-model (LLM) physics benchmarks are usually scored by answer accuracy, which cannot distinguish genuine reasoning from recall of familiar problem patterns and reveals little about where a model's reasoning breaks down. We introduce an auditable four-stage diagnostic that evaluates whether an LLM can reason inside an unfamiliar physics framework through induction, formulation, prediction, and review. The diagnostic combines locked pre-registrations, fresh sessions between stages, dual-LLM judging, and a human-audit pathway, and we apply it to three parallel physics worlds: a single-equation counterfactual world ($F=mv$), a historical framework (Aristotelian mechanics), and a four-domain counterfactual world (Decay World). Across Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro, the three worlds yield composite PASS rates are 6/15, 6/15, and 0/15 respectively (content $\land$ structural for $F=mv$ and Aristotelian, content axis only for Decay World where the structural axis is out of scope). The most pointed empirical pattern is a qualitative-versus-quantitative asymmetry: in Decay World, models almost never predict the wrong direction of change, but frequently compute the wrong ratio by slipping back to standard-physics relations. The protocol also surfaces two methodology findings: LLM-judge reliability does not transfer across frameworks, and Stage 4 self-review is weak in every framework, with the model's own review wrongly reporting no earlier error in at least two-thirds of the trials that actually contained one. We release the full prompts, responses, verdicts, and audit records.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an auditable four-stage diagnostic protocol (locked pre-registrations, fresh sessions, dual-LLM judging, human-audit pathway) to test whether frontier LLMs can perform inductive reasoning inside three unfamiliar parallel physics worlds: a single-equation counterfactual (F=mv), Aristotelian mechanics, and a four-domain Decay World. It reports composite PASS rates (content ∧ structural for the first two worlds; content only for Decay World) of 6/15, 6/15, and 0/15 across Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro, documents a qualitative-versus-quantitative asymmetry in Decay World, and releases all prompts, responses, verdicts, and audit records. Two methodology findings are also reported: LLM-judge reliability does not transfer across frameworks, and Stage 4 self-review is weak.
Significance. If the protocol successfully isolates genuine inductive reasoning from pattern recall or contamination, the work supplies a reproducible, auditable evaluation framework that goes beyond accuracy-based physics benchmarks and surfaces concrete failure modes (e.g., reversion to standard-physics ratios). The open release of full materials is a clear strength that supports verifiability and future replication.
major comments (3)
- [Abstract and §2] Abstract and §2 (The Diagnostic Protocol): the headline composite PASS rates (6/15, 6/15, 0/15) are presented as evidence that the models cannot reliably induce inside the counterfactual frameworks. This interpretation is load-bearing on the claim that locked pre-registrations, fresh sessions, and dual-LLM judging successfully prevent recall of standard physics or cross-stage leakage; yet the text supplies no explicit mechanism (e.g., prompt constraints or exclusion rules) that would block re-interpretation of F=mv as a limiting case of F=ma or keep Decay World quantities orthogonal to training data.
- [§4] §4 (Methodology Findings) and the judging procedure: the paper reports that LLM-judge reliability does not transfer across frameworks, yet the same dual-LLM judges are used to produce the composite scores for all three worlds. This directly affects the validity of the 0/15 rate in Decay World (where only the content axis is scored) and the cross-world comparison of the 6/15 rates.
- [§3] §3 (The Three Parallel Worlds) and the Decay World definition: the qualitative-versus-quantitative asymmetry is a central empirical pattern, but the four-domain structure and the precise definition of “content axis only” scoring are not accompanied by an explicit validation that the structural axis is truly out of scope rather than simply unmeasurable; this choice influences the 0/15 result and requires a concrete example of a trial that would have failed on structure had it been scored.
minor comments (3)
- [Abstract] Abstract: the sentence fragment “the three worlds yield composite PASS rates are 6/15” is grammatically incorrect.
- [Results] Table or results section: the 15 trials per model/world are not broken down by stage or by error type, making it difficult to trace exactly where the induction failures occur.
- [§3] Notation: the symbols used for the four domains of Decay World are introduced without a compact reference table, forcing the reader to hunt through the text on each mention.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (The Diagnostic Protocol): the headline composite PASS rates (6/15, 6/15, 0/15) are presented as evidence that the models cannot reliably induce inside the counterfactual frameworks. This interpretation is load-bearing on the claim that locked pre-registrations, fresh sessions, and dual-LLM judging successfully prevent recall of standard physics or cross-stage leakage; yet the text supplies no explicit mechanism (e.g., prompt constraints or exclusion rules) that would block re-interpretation of F=mv as a limiting case of F=ma or keep Decay World quantities orthogonal to training data.
Authors: We agree that the manuscript would benefit from greater explicitness on the isolation mechanisms. The locked pre-registrations and fresh sessions are the primary safeguards against cross-stage leakage, while the stage-1 prompts contain explicit instructions requiring the model to treat the supplied framework as self-contained and to make no reference to standard physics. We will expand §2 with the precise prompt wording and exclusion rules used to enforce this separation, thereby providing the requested concrete documentation. revision: yes
-
Referee: [§4] §4 (Methodology Findings) and the judging procedure: the paper reports that LLM-judge reliability does not transfer across frameworks, yet the same dual-LLM judges are used to produce the composite scores for all three worlds. This directly affects the validity of the 0/15 rate in Decay World (where only the content axis is scored) and the cross-world comparison of the 6/15 rates.
Authors: This observation is correct and highlights a genuine limitation. Because reliability does not transfer, the cross-framework comparisons must be interpreted cautiously. For Decay World the content-only scoring reduces the impact, yet we will revise §4 to state explicitly that the non-transferability qualifies both the 0/15 result and any direct comparison with the 6/15 rates from the other worlds, and we will add a short discussion of the implications for future protocol design. revision: partial
-
Referee: [§3] §3 (The Three Parallel Worlds) and the Decay World definition: the qualitative-versus-quantitative asymmetry is a central empirical pattern, but the four-domain structure and the precise definition of “content axis only” scoring are not accompanied by an explicit validation that the structural axis is truly out of scope rather than simply unmeasurable; this choice influences the 0/15 result and requires a concrete example of a trial that would have failed on structure had it been scored.
Authors: We accept the need for additional clarification. The structural axis is out of scope because Decay World comprises four independent domains whose inter-domain consistency cannot be captured by a single structural criterion applicable across all trials. We will add to §3 both an explicit justification of this design choice and a concrete example of a trial response that would have failed a structural check had one been applied, thereby making the rationale for content-only scoring transparent. revision: yes
Circularity Check
No circularity: empirical evaluation protocol with no derivation chain
full rationale
The paper presents an empirical four-stage diagnostic protocol applied to LLMs across constructed physics worlds, reporting composite PASS rates (6/15, 6/15, 0/15) from direct testing. No equations, fitted parameters, or first-principles derivations are claimed; the work does not reduce any reported outcome to a self-referential definition, fitted input renamed as prediction, or self-citation chain. The protocol description (locked pre-registrations, dual-LLM judging) is presented as a methodological choice without mathematical reduction to its own inputs. This is a standard empirical evaluation paper whose central claims rest on observed test outcomes rather than any load-bearing derivation that collapses by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four-stage process (induction, formulation, prediction, review) with locked pre-registrations and dual-LLM judging isolates genuine inductive reasoning from pattern recall.
invented entities (1)
-
Three parallel physics worlds (single-equation F=mv counterfactual, Aristotelian mechanics, four-domain Decay World)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Remarks on the disproof of the unit distance conjecture
Noga Alon, Thomas F. Bloom, W. T. Gowers, Daniel Litt, Will Sawin, Arul Shankar, Jacob Tsimerman, Victor Wang, and Melanie Matchett Wood. Remarks on the disproof of the unit distance conjecture. arXiv preprint arXiv:2605.20695, 2026. Human-verified companion to the OpenAI -generated counterexample
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Peter W. Battaglia, Jessica B. Hamrick, and Joshua B. Tenenbaum. Simulation as an engine of physical scene understanding. Proceedings of the National Academy of Sciences (PNAS), 110 0 (45): 0 18327--18332, 2013. doi:10.1073/pnas.1306572110
-
[3]
Bear, Elias Wang, Damian Mrowca, Felix J
Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, Hsiau-Yu Fish Tung, R. T. Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, Li Fei-Fei, Nancy Kanwisher, Joshua B. Tenenbaum, Daniel L. K. Yamins, and Judith E. Fan. Physion: Evaluating physical prediction from vision in humans and machines. In NeurIPS Datasets and Benchmarks, 2021
2021
-
[4]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models. Nature, 624: 0 570--578, 2023. doi:10.1038/s41586-023-06792-0
-
[5]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. OpenAI technical report, https://openai.com/research/video-generation-models-as-world-simulators, 2024
2024
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[7]
Quantifying Memorization Across Neural Language Models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tram \`e r, and Chiyuan Zhang. Quantifying memorization across neural language models. In ICLR, 2023. arXiv:2202.07646
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
The Science of Mechanics in the Middle Ages
Marshall Clagett. The Science of Mechanics in the Middle Ages. University of Wisconsin Press, Madison, 1959
1959
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Die Grundlage der allgemeinen Relativit\"atstheorie
Albert Einstein. Die Grundlage der allgemeinen Relativit\"atstheorie . Annalen der Physik, 49: 0 769--822, 1916. General Relativity field equations; predicts light bending in a gravitational field, confirmed by the 1919 eclipse
1916
-
[11]
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Jon M. Laurent, Muhammed T. Razzak, Andrew D. White, Michaela M. Hinks, and Samuel G. Rodriques. Robin: A multi-agent system for automating scientific discovery. arXiv preprint arXiv:2505.13400, 2025
-
[12]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, et al. Towards an AI co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Aaron Grattafiori et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
World models
David Ha and J\" u rgen Schmidhuber. World models. In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[15]
Remarks on an `` Einstein Test '' for AGI
Demis Hassabis. Remarks on an `` Einstein Test '' for AGI . India AI Impact Summit, February 17, 2026, 2026. Public address
2026
-
[16]
Carl G. Hempel. Philosophy of Natural Science. Prentice-Hall, Englewood Cliffs, NJ, 1966
1966
-
[17]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In NeurIPS Datasets and Benchmarks, 2021
2021
-
[18]
Towards Reasoning in Large Language Models: A Survey
Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. arXiv preprint arXiv:2212.10403, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Astronomia Nova
Johannes Kepler. Astronomia Nova. 1609. Three laws of planetary motion; geometric formulation. T^2 a^3 appears in Harmonices Mundi (1619)
-
[20]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[21]
Thomas S. Kuhn. The Structure of Scientific Revolutions. University of Chicago Press, Chicago, 1962. 2nd edition with Postscript, 1970
1962
-
[22]
A path towards autonomous machine intelligence (position paper, version 0.9)
Yann LeCun. A path towards autonomous machine intelligence (position paper, version 0.9). Technical report, OpenReview, June 2022. URL https://openreview.net/forum?id=BZ5a1r-kVsf
2022
-
[23]
G. E. R. Lloyd. Aristotle: The Growth and Structure of his Thought. Cambridge University Press, Cambridge, 1968
1968
-
[24]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
A dynamical theory of the electromagnetic field
James Clerk Maxwell. A dynamical theory of the electromagnetic field. Philosophical Transactions of the Royal Society of London, 155: 0 459--512, 1865
-
[26]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. GSM-Symbolic : Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Philosophi Naturalis Principia Mathematica
Isaac Newton. Philosophi Naturalis Principia Mathematica . 1687. Universal gravitation as inverse-square attraction; modern algebraic form assembled by later writers
-
[28]
Nosek, George Alter, George C
Brian A. Nosek, George Alter, George C. Banks, Denny Borsboom, Sara D. Bowman, Steven J. Breckler, Stuart Buck, Christopher D. Chambers, Gilbert Chin, Garret Christensen, et al. Promoting an open research culture. Science, 348 0 (6242): 0 1422--1425, 2015
2015
-
[29]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA , Niket Agarwal, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025. Released around CES 2025. Open-license world foundation models for robotics and autonomous-driving applications
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program)
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivi \`e re, Alina Beygelzimer, Florence d'Alch \'e Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program). Journal of Machine Learning Research, 22 0 (164): 0 1--20, 2021
2019
-
[31]
Karl R. Popper. The Logic of Scientific Discovery. Hutchinson, London, 1959. Original German edition: Logik der Forschung, Springer, Vienna, 1934 (imprint 1935)
1959
-
[32]
Phybench: Holistic evaluation of physical perception and reasoning in large language models, 2025
Shi Qiu et al. PHYBench : Holistic evaluation of physical perception and reasoning in large language models. arXiv preprint arXiv:2504.16074, 2025
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level G oogle-proof Q&A benchmark. In Conference on Language Modeling (COLM), 2024
2024
-
[34]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models. Nature, 625: 0 468--475, 2024. doi:10.1038/s41586-023-06924-6
-
[35]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker Garc \'i a-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Findings of EMNLP, 2023. arXiv:2310.18018
-
[36]
Are emergent abilities of large language models a mirage? In Advances in Neural Information Processing Systems (NeurIPS), 2023
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[37]
Sculley, Jasper Snoek, Alex Wiltschko, and Ali Rahimi
D. Sculley, Jasper Snoek, Alex Wiltschko, and Ali Rahimi. Winner's curse? On pace, progress, and empirical rigor. In ICLR Workshop Track, 2018
2018
-
[38]
Dolma : An open corpus of three trillion tokens for language model pretraining research
Luca Soldaini, Rodney Kinney, Akshita Bhagia, et al. Dolma : An open corpus of three trillion tokens for language model pretraining research. arXiv preprint arXiv:2402.00159, 2024
-
[39]
Trieu H. Trinh, Yuhuai Wu, Quoc V. Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations. Nature, 625: 0 476--482, 2024. doi:10.1038/s41586-023-06747-5
-
[40]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models. Transactions on Machine Learning Research (TMLR), 2022 a
2022
-
[41]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2022 b
2022
-
[42]
The Philosophy of the Inductive Sciences, Founded Upon Their History
William Whewell. The Philosophy of the Inductive Sciences, Founded Upon Their History. John W. Parker, London, 1840. 2 volumes
-
[43]
DiscoverPhysics: Benchmarking LLMs for Out-of-the-Box Scientific Thinking
Matt L. Wiemann, Lindsay M. Smith, Peter Melchior, Siddharth Mishra-Sharma, Andrew Gordon Wilson, Pavel Izmailov, and Carolina Cuesta-L \'a zaro. DiscoverPhysics : Benchmarking LLMs for out-of-the-box scientific thinking. arXiv preprint arXiv:2605.26087, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
arXiv preprint arXiv:2307.02477 , year=
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Aky \"u rek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. In NAACL, 2024. arXiv:2307.02477
-
[45]
A careful examination of large language model performance on grade school arithmetic
Hugh Zhang, Jeff Da, Dean Lee, et al. A careful examination of large language model performance on grade school arithmetic. arXiv preprint arXiv:2405.00332, 2024
-
[46]
Jianqiu Zhang. Sora and V-JEPA have not learned the complete real world model -- a philosophical analysis of video AIs through the theory of productive imagination. arXiv preprint arXiv:2407.10311, 2024
-
[47]
Yiming Zhang et al. ABench-Physics : Benchmarking physical reasoning in LLMs via high-difficulty and dynamic physics problems. arXiv preprint arXiv:2507.04766, 2025
-
[48]
Tianshi Zheng, Kelvin Kiu-Wai Tam, Newt Hue-Nam K. Nguyen, Baixuan Xu, Zhaowei Wang, Jiayang Cheng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Tianqing Fang, Yangqiu Song, Ginny Y. Wong, and Simon See. NewtonBench : Benchmarking generalizable scientific law discovery in LLM agents. In ICLR, 2026. arXiv:2510.07172
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.