Rosetta: Composable Native Multimodal Pretraining
Pith reviewed 2026-07-02 15:39 UTC · model grok-4.3
The pith
Rosetta adds new modalities to foundation models without erasing prior language or vision skills by anchoring gradients to optimizer momentum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
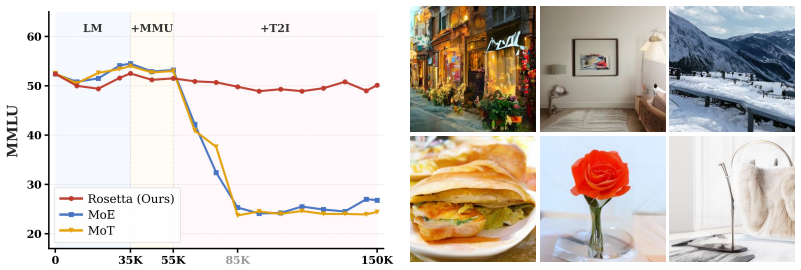
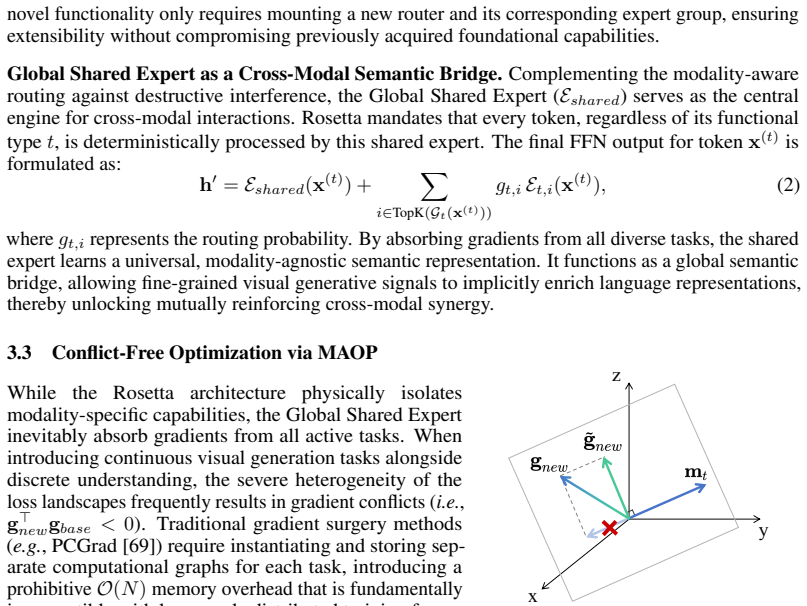
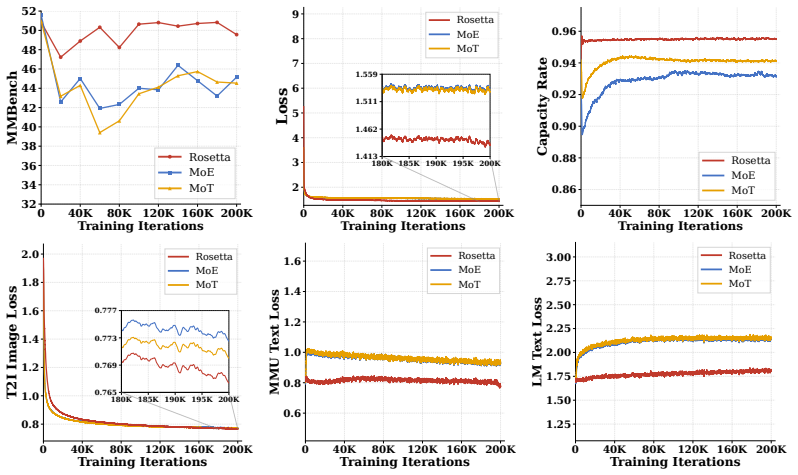
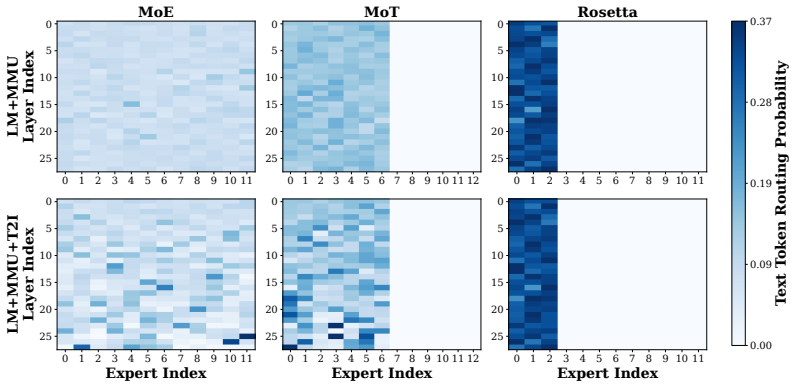
Rosetta adopts a modular paradigm where core foundational knowledge is preserved within global shared experts, while modality-specific capabilities are distributed across plug-and-play experts. To guarantee non-destructive composition, the authors introduce Momentum-Anchored Orthogonal Projection (MAOP). MAOP leverages the optimizer's momentum state as an implicit semantic anchor, selectively neutralizing conflicting gradient components from new modalities while preserving synergistic updates. Evaluations confirm that, unlike standard MoE and MoT, Rosetta robustly preserves established language and visual understanding, delivers superior image generation, and unlocks cross-modal synergy.
What carries the argument
Momentum-Anchored Orthogonal Projection (MAOP), which uses the optimizer momentum vector as a fixed semantic reference to project out only the conflicting parts of new-modality gradients.
If this is right
- Shared experts retain prior language and visual understanding while new experts handle added modalities.
- Image generation quality exceeds that of standard MoE and MoT baselines.
- Cross-modal interactions improve once conflicting gradients are removed.
- The same modular structure supports repeated modality additions without restarting pretraining.
Where Pith is reading between the lines
- The same projection technique could be applied when adding entirely new task families rather than new data modalities.
- Releasing the checkpoints makes it possible to test whether the preserved experts continue to improve when later modalities are introduced.
- If MAOP generalizes, the method offers a practical path toward foundation models that accumulate capabilities over successive training stages instead of requiring full retraining.
Load-bearing premise
The momentum state can be used to identify and remove only conflicting gradient directions from a new modality without also removing useful synergistic updates or altering overall training dynamics.
What would settle it
Train a language-only model, add an image-generation objective with and without MAOP, then measure whether language-task accuracy drops more in the non-MAOP run than in the MAOP run.
Figures



read the original abstract
Achieving true artificial general intelligence requires foundation models capable of integrating new modalities without forgetting prior knowledge. However, accommodating continuous generative objectives alongside discrete understanding tasks causes severe gradient conflicts. Existing architectures, including standard Mixture-of-Experts (MoE), are highly susceptible to representation overwriting. Even structurally partitioned paradigms like Mixture-of-Transformers (MoT) remain vulnerable to catastrophic forgetting, severely impeding multimodal scalability. In this work, we introduce Rosetta, a composable native multimodal pretraining framework designed for seamless and non-destructive modality expansion. Rosetta adopts a modular paradigm where core foundational knowledge is preserved within global shared experts, while modality-specific capabilities are distributed across plug-and-play experts. To guarantee non-destructive composition, we propose Momentum-Anchored Orthogonal Projection (MAOP). MAOP leverages the optimizer's momentum state as an implicit semantic anchor, selectively neutralizing conflicting gradient components from new modalities while preserving synergistic updates. Extensive evaluations demonstrate that, while standard MoE and MoT architectures suffer catastrophic forgetting of previously acquired knowledge, Rosetta robustly preserves established language and visual understanding. Furthermore, it delivers superior image generation and unlocks cross-modal synergy, paving the way for truly composable and unified multimodal foundation models. To facilitate further multimodal research, we release our code and checkpoints to the community. Project page at https://rosetta-lmm.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Rosetta, a composable native multimodal pretraining framework that uses a modular architecture consisting of global shared experts for core knowledge and plug-and-play modality-specific experts. It proposes Momentum-Anchored Orthogonal Projection (MAOP), which uses the optimizer's momentum state as an anchor to selectively neutralize conflicting gradient components from new modalities. The central claims are that, unlike standard MoE and MoT, Rosetta avoids catastrophic forgetting of prior language and visual understanding, delivers superior image generation, and unlocks cross-modal synergy, as shown by extensive evaluations; code and checkpoints are released.
Significance. If the MAOP mechanism and the empirical superiority claims are substantiated with quantitative results, the work would address a key scalability barrier in multimodal foundation models by enabling non-destructive modality expansion, which is relevant for building unified models that integrate understanding and generation tasks across modalities.
major comments (2)
- [Abstract] Abstract: the assertion of 'extensive evaluations' showing that Rosetta 'robustly preserves established language and visual understanding' and outperforms MoE/MoT is unsupported by any quantitative results, baselines, error bars, dataset details, or ablation studies in the provided text, preventing assessment of the central claims about forgetting and performance.
- [Abstract] Abstract (MAOP description): the claim that MAOP 'leverages the optimizer's momentum state as an implicit semantic anchor, selectively neutralizing conflicting gradient components from new modalities while preserving synergistic updates' lacks any equation, derivation, or analysis of how the (unspecified) orthogonal projection distinguishes conflict from synergy; momentum as an EMA does not by itself guarantee separation without additional assumptions on gradient geometry.
minor comments (1)
- [Abstract] Abstract: the project page URL is given but no details on the released code structure, checkpoint formats, or reproduction instructions are provided.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address the two major comments on the abstract point by point below, clarifying the relationship between the summary claims and the detailed results in the full manuscript. We will make targeted revisions to improve clarity and substantiation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'extensive evaluations' showing that Rosetta 'robustly preserves established language and visual understanding' and outperforms MoE/MoT is unsupported by any quantitative results, baselines, error bars, dataset details, or ablation studies in the provided text, preventing assessment of the central claims about forgetting and performance.
Authors: The abstract summarizes the primary findings at a high level, as is standard. The full manuscript contains the requested quantitative support in Sections 4 and 5, including direct comparisons against MoE and MoT baselines on language and vision benchmarks, error bars across multiple random seeds, dataset specifications, and ablation studies isolating the effect of MAOP on forgetting. To make these claims more immediately verifiable from the abstract, we will revise it to incorporate a small number of key quantitative highlights (e.g., retention percentages and generation metrics) while remaining within length constraints. revision: yes
-
Referee: [Abstract] Abstract (MAOP description): the claim that MAOP 'leverages the optimizer's momentum state as an implicit semantic anchor, selectively neutralizing conflicting gradient components from new modalities while preserving synergistic updates' lacks any equation, derivation, or analysis of how the (unspecified) orthogonal projection distinguishes conflict from synergy; momentum as an EMA does not by itself guarantee separation without additional assumptions on gradient geometry.
Authors: The complete mathematical definition of MAOP, including the orthogonal projection operator, the use of momentum as the anchor vector, the derivation showing how conflicting versus synergistic gradient components are identified, and the geometric assumptions required for the separation, appear in Section 3.2 together with supporting analysis. The abstract intentionally omits equations to maintain readability. We will revise the abstract to include a parenthetical reference to the MAOP formulation in Section 3.2 so readers can locate the derivation immediately. revision: partial
Circularity Check
No circularity: proposed MAOP mechanism lacks any derivation chain or equations that reduce to inputs
full rationale
The abstract and visible text describe Rosetta and MAOP as a design choice where momentum anchors orthogonal projection to neutralize conflicting gradients. No equations, fitted parameters, self-citations, or derivation steps are present that could create self-definitional loops, fitted-input predictions, or imported uniqueness. The central claim is an architectural proposal without a mathematical reduction to its own inputs, making this a standard non-circular case.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[3]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European conference on computer vision (ECCV), pages 139–154, 2018
2018
-
[4]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
FLUX.2: Frontier visual intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier visual intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[7]
Gradnorm: Gradient normal- ization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gradient normal- ization for adaptive loss balancing in deep multitask networks. InInternational conference on machine learning, pages 794–803. PMLR, 2018
2018
-
[8]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1280–1297, 2024
2024
-
[10]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[12]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[13]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[14]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[17]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[18]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017. 10
2017
-
[19]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[20]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
2023
-
[21]
Language is not all you need: Aligning perception with language models.Advances in Neural Information Processing Systems, 36:72096–72109, 2023
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, et al. Language is not all you need: Aligning perception with language models.Advances in Neural Information Processing Systems, 36:72096–72109, 2023
2023
-
[22]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
2016
-
[24]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[25]
arXiv preprint arXiv:2212.05055 , year=
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. Sparse upcycling: Training mixture-of-experts from dense checkpoints.arXiv preprint arXiv:2212.05055, 2022
-
[26]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11523–11532, 2022
2022
-
[27]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[28]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[29]
Uni-moe: Scaling unified multimodal llms with mixture of experts.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, and Min Zhang. Uni-moe: Scaling unified multimodal llms with mixture of experts.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[30]
Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
2017
-
[31]
Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.Transactions on Machine Learning Research, 2025
Weixin Liang, LILI YU, Liang Luo, Srini Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen tau Yih, Luke Zettlemoyer, and Xi Victoria Lin. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URLhttps://openreview.net/forum?id=Nu6N69i8SB
2025
-
[32]
Moe-llava: Mixture of experts for large vision-language models.IEEE Transactions on Multimedia, 2026
Bin Lin, Zhenyu Tang, Yang Ye, Jinfa Huang, Junwu Zhang, Yatian Pang, Peng Jin, Munan Ning, Jiebo Luo, and Li Yuan. Moe-llava: Mixture of experts for large vision-language models.IEEE Transactions on Multimedia, 2026
2026
-
[33]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[34]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Conflict-averse gradient descent for multi-task learning.Advances in neural information processing systems, 34:18878–18890, 2021
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning.Advances in neural information processing systems, 34:18878–18890, 2021
2021
-
[36]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 11
2023
-
[37]
Symbiotic-MoE: Unlocking the Synergy between Generation and Understanding
Xiangyue Liu, Zijian Zhang, Miles Yang, Zhao Zhong, Liefeng Bo, and Ping Tan. Symbiotic-moe: Unlocking the synergy between generation and understanding.arXiv preprint arXiv:2604.07753, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024
2024
-
[40]
Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
2017
-
[41]
Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, and Aniruddha Kembhavi. Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26439–26455, 2024
2024
-
[42]
Mm1: methods, analysis and insights from multimodal llm pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Anton Belyi, et al. Mm1: methods, analysis and insights from multimodal llm pre-training. InEuropean Conference on Computer Vision, pages 304–323. Springer, 2024
2024
-
[43]
Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
2022
-
[44]
Multi-task learning as a bargaining game,
Aviv Navon, Aviv Shamsian, Idan Achituve, Haggai Maron, Kenji Kawaguchi, Gal Chechik, and Ethan Fetaya. Multi-task learning as a bargaining game.arXiv preprint arXiv:2202.01017, 2022
-
[45]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[47]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[48]
Generating diverse high-fidelity images with vq-vae-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems, 32, 2019
2019
-
[49]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[50]
{Zero-offload}: Democratizing {billion-scale} model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. {Zero-offload}: Democratizing {billion-scale} model training. In2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 551–564, 2021
2021
-
[51]
Scaling vision with sparse mixture of experts.Advances in Neural Information Processing Systems, 34:8583–8595, 2021
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Su- sano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts.Advances in Neural Information Processing Systems, 34:8583–8595, 2021
2021
-
[52]
Experience replay for continual learning.Advances in neural information processing systems, 32, 2019
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Experience replay for continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[53]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[54]
Scaling vision- language models with sparse mixture of experts
Sheng Shen, Zhewei Yao, Chunyuan Li, Trevor Darrell, Kurt Keutzer, and Yuxiong He. Scaling vision- language models with sparse mixture of experts. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 11329–11344, 2023
2023
-
[55]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019. 12
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[56]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[57]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
arXiv preprint arXiv:2603.03276 , year=
Shengbang Tong, David Fan, John Nguyen, Ellis Brown, Gaoyue Zhou, Shengyi Qian, Boyang Zheng, Théophane Vallaeys, Junlin Han, Rob Fergus, et al. Beyond language modeling: An exploration of multimodal pretraining.arXiv preprint arXiv:2603.03276, 2026
-
[60]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[61]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[62]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
2022
-
[63]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12966–12977, 2025
2025
-
[64]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Grok-1.5 Vision Preview: Connecting the digital and physical worlds with our first multimodal model.https://x.ai/news/grok-1.5v, 2024
X.AI Corp. Grok-1.5 Vision Preview: Connecting the digital and physical worlds with our first multimodal model.https://x.ai/news/grok-1.5v, 2024
2024
-
[66]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[69]
Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
2020
-
[70]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[71]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024. 13 Supplementary Materials for Rosetta: Composable Native Multimodal Pretraining This supplem...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.