MEPA: Multi-Scale Representation Alignment for Visual Autoregressive Modeling with Mixture of Experts
Pith reviewed 2026-07-02 15:12 UTC · model grok-4.3
The pith
Scale-aware token-routed MoE plus residual self-supervised aggregation decouples multi-scale representations in VAR models and curbs early error propagation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
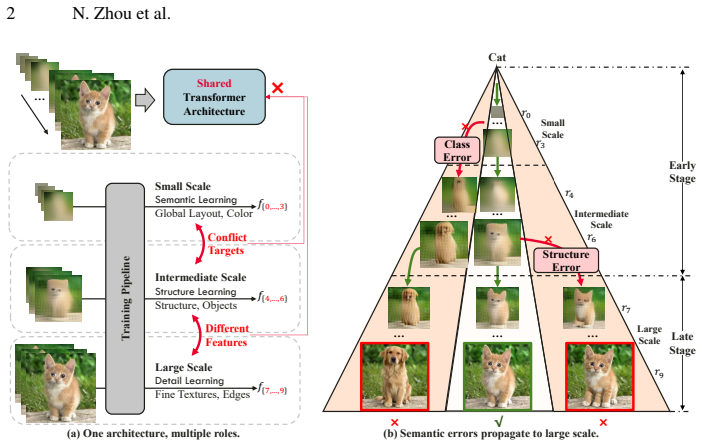
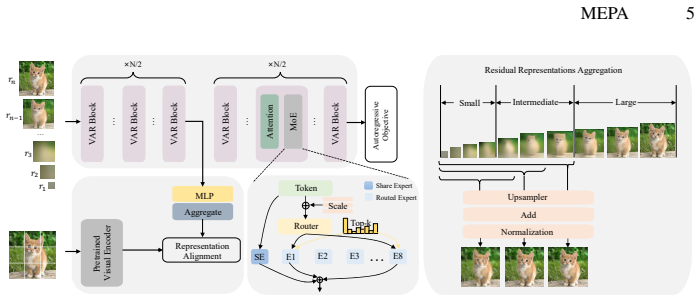
Replacing the shared architecture across scales in VAR with a scale-aware token-routed MoE architecture, together with a residual self-supervised feature aggregation scheme, decouples representation learning per scale and reduces error propagation from inaccurate early semantics, producing higher-quality images with substantially improved training efficiency.
What carries the argument
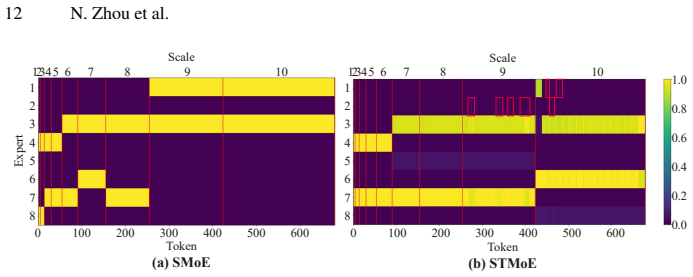
Scale-aware token-routed Mixture of Experts (MoE) combined with residual self-supervised feature aggregation.
If this is right
- Decouples representation learning across scales to avoid optimization conflicts from shared weights.
- Reduces propagation of inaccurate semantics from lower scales through the causal autoregressive chain.
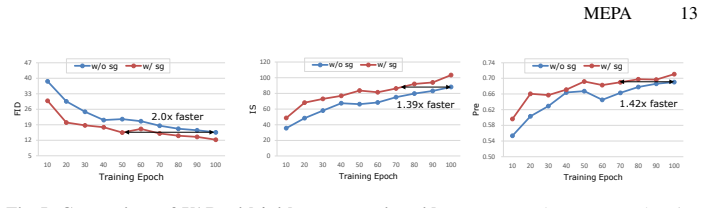
- Delivers superior FID on ImageNet 256x256 while using half the default training epochs and a smaller parameter budget.
- Increases training cost only marginally relative to the dense baseline.
- Widens the performance advantage over the baseline as training epochs increase.
Where Pith is reading between the lines
- The residual aggregation pattern could transfer to other autoregressive generators that face scale-dependent error accumulation.
- Token-routed experts may lower total compute needed for high-resolution image synthesis in practice.
- Similar routing-plus-residual alignment could be tested on video or 3D autoregressive models that also process coarse-to-fine sequences.
Load-bearing premise
A scale-aware token-routed MoE plus residual self-supervised feature aggregation will decouple representation learning across scales and prevent error propagation without introducing new optimization instabilities or distribution shifts.
What would settle it
Train an otherwise identical VAR model but replace scale-aware token routing with uniform expert sharing across scales and check whether the reported FID gains, epoch reduction, and parameter savings disappear on the ImageNet 256x256 benchmark.
Figures

read the original abstract
Visual AutoRegressive modeling (VAR) has pioneered a coarse-to-fine multi-scale autoregressive generative paradigm, demonstrating strong capabilities in image generation. However, VAR still suffers from inherent deficiencies in multi-scale representation learning. Specifically, lower scales primarily capture global semantics, while higher scales focus on fine-grained details. Employing a shared architecture across scales induces optimization conflicts. Moreover, due to the causal autoregressive process, inaccurate semantics at early scales can propagate and significantly degrade the final output. To address these issues, we introduce a scale-aware token-routed Mixture of Experts (MoE) architecture, allowing scale-adaptive expert selection, thereby facilitating decoupled representation learning across scales. In addition, we enhance semantic modeling at early scales by incorporating external self-supervised features. Unlike naive alignment, we analyse and design a residual feature aggregation scheme tailored to the VAR paradigm. Extensive experiments show that our method significantly improves both training efficiency and generation quality. On the ImageNet 256*256 benchmark, our model achieves a superior FID compared to the dense baseline while requiring only half of the default training epochs and a smaller parameter budget, with a merely marginal increase in training cost. Moreover, the performance gap further widens with larger training epochs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MEPA, a scale-aware token-routed Mixture of Experts (MoE) architecture combined with a residual self-supervised feature aggregation scheme for Visual Autoregressive (VAR) modeling. It addresses optimization conflicts from shared architectures across scales and error propagation from early-scale inaccuracies, claiming improved training efficiency and generation quality on ImageNet 256×256, with superior FID versus the dense VAR baseline at half the default epochs, reduced active parameters, and only marginal extra training cost.
Significance. If the reported results hold, the work shows that explicit scale-adaptive expert routing plus residual alignment can decouple multi-scale representations in autoregressive generators without introducing instabilities, yielding measurable gains in both sample quality and training efficiency. The manuscript supplies ablations, training curves, and implementation details that support the central empirical claim, which is a strength for reproducibility.
minor comments (2)
- [Abstract] The abstract states 'superior FID' and 'significantly improves' without any numerical values, error bars, or direct comparison metrics; adding the headline FID numbers and epoch counts here would improve immediate readability.
- [§3] Notation for the residual aggregation (e.g., how the self-supervised features are injected into the VAR token sequence) is introduced in the method section but not cross-referenced in the experimental setup; a brief equation or diagram pointer would clarify the exact residual path.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were raised in the report, so we have no specific points to address point-by-point. We will incorporate any minor editorial suggestions during revision.
Circularity Check
No significant circularity identified
full rationale
The paper introduces an architectural modification (scale-aware token-routed MoE plus residual self-supervised feature aggregation) to the VAR paradigm and validates it through ImageNet experiments. All central claims are framed as empirical outcomes (FID, training epochs, parameter count) rather than mathematical derivations or predictions. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content that would reduce the result to its own inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2007.01127 (2020)
Alaparthi, S., Mishra, M.: Bidirectional encoder representations from transformers (bert): A sentiment analysis odyssey. arXiv preprint arXiv:2007.01127 (2020)
-
[3]
In: Forty-second International Conference on Machine Learning (2025)
Bachmann, R., Allardice, J., Mizrahi, D., Fini, E., Kar, O.F., Amirloo, E., El-Nouby, A., Zamir, A., Dehghan, A.: Flextok: Resampling images into 1d token sequences of flexible length. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[4]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Brock,A.,Donahue,J.,Simonyan,K.:Largescalegantrainingforhighfidelitynaturalimage synthesis. arXiv preprint arXiv:1809.11096 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked generative image transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11315–11325 (2022)
2022
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen,H.,Wang,Z.,Li,X.,Sun,X.,Chen,F.,Liu,J.,Wang,J.,Raj,B.,Liu,Z.,Barsoum,E.: Softvq-vae: Efficient 1-dimensional continuous tokenizer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28358–28370 (2025) 16 N. Zhou et al
2025
-
[7]
In: International conference on machine learning
Chen,T.,Kornblith,S.,Norouzi,M.,Hinton,G.:Asimpleframeworkforcontrastivelearning of visual representations. In: International conference on machine learning. pp. 1597–1607. PmLR (2020)
2020
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Chen, Z., Ma, X., Fang, G., Wang, X.: Collaborative decoding makes visual auto-regressive modeling efficient. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 23334–23344 (2025)
2025
-
[9]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L.:Imagenet:Alarge-scalehierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[10]
Dhariwal,P.,Nichol,A.:Diffusionmodelsbeatgansonimagesynthesis.Advancesinneural information processing systems34, 8780–8794 (2021)
2021
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser,P.,Rombach,R.,Ommer,B.:Tamingtransformersforhigh-resolutionimagesynthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021)
2021
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Esteves, C., Suhail, M., Makadia, A.: Spectral image tokenizer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17181–17190 (2025)
2025
-
[13]
Journal of Machine Learning Research23(120), 1–39 (2022)
Fedus, W., Zoph, B., Shazeer, N.: Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research23(120), 1–39 (2022)
2022
-
[14]
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al.: Bootstrap your own latent-a new approachtoself-supervisedlearning.Advancesinneuralinformationprocessingsystems33, 21271–21284 (2020)
2020
-
[15]
arXiv preprint arXiv:2503.23367 (2025)
Guo, H., Li, Y., Zhang, T., Wang, J., Dai, T., Xia, S.T., Benini, L.: Fastvar: Linear visual autoregressive modeling via cached token pruning. arXiv preprint arXiv:2503.23367 (2025)
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Han, J., Liu, J., Jiang, Y., Yan, B., Zhang, Y., Yuan, Z., Peng, B., Liu, X.: Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15733–15744 (2025)
2025
-
[17]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable visionlearners.In:ProceedingsoftheIEEE/CVFconferenceoncomputervisionandpattern recognition. pp. 16000–16009 (2022)
2022
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9729–9738 (2020)
2020
-
[19]
Scaling Laws for Autoregressive Generative Modeling
Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., Brown, T.B., Dhariwal, P., Gray, S., et al.: Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[21]
Journal of Machine Learning Research23(47), 1–33 (2022)
Ho, J., Saharia, C., Chan, W., Fleet, D.J., Norouzi, M., Salimans, T.: Cascaded diffusion models for high fidelity image generation. Journal of Machine Learning Research23(47), 1–33 (2022)
2022
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, T., Zhang, J., Yi, R., Weng, J., Wang, Y., Zeng, X., Xue, Z., Ma, L.: Improving au- toregressive visual generation with cluster-oriented token prediction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9351–9360 (2025)
2025
-
[23]
arXiv preprint arXiv:2506.10962 (2025)
Huang,Y.,Chen,W.,Zheng,W.,Duan,Y.,Zhou,J.,Lu,J.:Spectralar:Spectralautoregressive visual generation. arXiv preprint arXiv:2506.10962 (2025)
-
[24]
arXiv preprint arXiv:2503.07076 (2025) MEPA 17
Huang, Z., Qiu, X., Ma, Y., Zhou, Y., Chen, J., Zhang, H., Zhang, C., Li, X.: Nfig: Autore- gressive image generation with next-frequency prediction. arXiv preprint arXiv:2503.07076 (2025) MEPA 17
-
[25]
Neural computation3(1), 79–87 (1991)
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural computation3(1), 79–87 (1991)
1991
-
[26]
arXiv preprint arXiv:2507.07997 (2025)
Jia, M., Yin, W., Hu, X., Guo, J., Guo, X., Zhang, Q., Long, X.X., Tan, P.: Mgvq: Could vq-vae beat vae? a generalizable tokenizer with multi-group quantization. arXiv preprint arXiv:2507.07997 (2025)
-
[27]
arXiv preprint arXiv:2502.20313 (2025)
Jiao, S., Zhang, G., Qian, Y., Huang, J., Zhao, Y., Shi, H., Ma, L., Wei, Y., Jie, Z.: Flex- var: Flexible visual autoregressive modeling without residual prediction. arXiv preprint arXiv:2502.20313 (2025)
-
[28]
arXiv preprint arXiv:2410.07348 (2024)
Jin, P., Zhu, B., Yuan, L., Yan, S.: Moe++: Accelerating mixture-of-experts methods with zero-computation experts. arXiv preprint arXiv:2410.07348 (2024)
-
[29]
Kang, M., Zhu, J.Y., Zhang, R., Park, J., Shechtman, E., Paris, S., Park, T.: Scaling up gans fortext-to-imagesynthesis.In:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition. pp. 10124–10134 (2023)
2023
-
[30]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Kingma,D.P.,Welling,M.:Auto-encodingvariationalbayes.arXivpreprintarXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lee, D., Kim, C., Kim, S., Cho, M., Han, W.S.: Autoregressive image generation using residual quantization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11523–11532 (2022)
2022
-
[33]
Lepikhin,D.,Lee,H.,Xu,Y.,Chen,D.,Firat,O.,Huang,Y.,Krikun,M.,Shazeer,N.,Chen, Z.:Gshard:Scalinggiantmodelswithconditionalcomputationandautomaticsharding.arXiv preprint arXiv:2006.16668 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[34]
CoRR (2023)
Li, T., Katabi, D., He, K.: Self-conditioned image generation via generating representations. CoRR (2023)
2023
-
[35]
Advances in Neural Information Processing Systems37, 56424–56445 (2024)
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation without vector quantization. Advances in Neural Information Processing Systems37, 56424–56445 (2024)
2024
-
[36]
arXiv preprint arXiv:2410.01756 , year=
Li,X.,Qiu,K.,Chen,H.,Kuen,J.,Gu,J.,Raj,B.,Lin,Z.:Imagefolder:Autoregressiveimage generation with folded tokens. arXiv preprint arXiv:2410.01756 (2024)
-
[37]
arXiv preprint arXiv:2410.10511 (2024)
Liu, W., Zhuo, L., Xin, Y., Xia, S., Gao, P., Yue, X.: Customize your visual autoregressive recipe with set autoregressive modeling. arXiv preprint arXiv:2410.10511 (2024)
-
[38]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
arXiv preprint arXiv:2412.15321 (2024)
Pang, Y., Jin, P., Yang, S., Lin, B., Zhu, B., Tang, Z., Chen, L., Tay, F.E., Lim, S.N., Yang, H., et al.: Next patch prediction for autoregressive visual generation. arXiv preprint arXiv:2412.15321 (2024)
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Pang, Z., Zhang, T., Luan, F., Man, Y., Tan, H., Zhang, K., Freeman, W.T., Wang, Y.X.: Randar: Decoder-only autoregressive visual generation in random orders. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 45–55 (2025)
2025
-
[41]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[42]
arXiv preprint arXiv:2502.20388 (2025)
Ren,S.,Yu,Q.,He,J.,Shen,X.,Yuille,A.,Chen,L.C.:Beyondnext-token:Next-xprediction for autoregressive visual generation. arXiv preprint arXiv:2502.20388 (2025)
-
[43]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image syn- thesiswithlatentdiffusionmodels.In:ProceedingsoftheIEEE/CVFconferenceoncomputer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[44]
Sauer,A.,Schwarz,K.,Geiger,A.:Stylegan-xl:Scalingstylegantolargediversedatasets.In: ACM SIGGRAPH 2022 conference proceedings. pp. 1–10 (2022) 18 N. Zhou et al
2022
-
[45]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun,P.,Jiang,Y.,Chen,S.,Zhang,S.,Peng,B.,Luo,P.,Yuan,Z.:Autoregressivemodelbeats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C.: Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Team,G.,Anil,R.,Borgeaud,S.,Alayrac,J.B.,Yu,J.,Soricut,R.,Schalkwyk,J.,Dai,A.M., Hauth,A.,Millican,K.,etal.:Gemini:afamilyofhighlycapablemultimodalmodels.arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Advances in neural information processing systems37, 84839–84865 (2024)
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scal- able image generation via next-scale prediction. Advances in neural information processing systems37, 84839–84865 (2024)
2024
-
[50]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
In: International conference on machine learning
Van Den Oord, A., Kalchbrenner, N., Kavukcuoglu, K.: Pixel recurrent neural networks. In: International conference on machine learning. pp. 1747–1756. PMLR (2016)
2016
-
[52]
Advances in neural information processing systems30(2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017)
2017
-
[53]
Emu3: Next-Token Prediction is All You Need
Wang,X.,Zhang,X.,Luo,Z.,Sun,Q.,Cui,Y.,Wang,J.,Zhang,F.,Wang,Y.,Li,Z.,Yu,Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Wang, Y., Ren, S., Lin, Z., Han, Y., Guo, H., Yang, Z., Zou, D., Feng, J., Liu, X.: Paral- lelizedautoregressivevisualgeneration.In:ProceedingsoftheComputerVisionandPattern Recognition Conference. pp. 12955–12965 (2025)
2025
-
[55]
arXiv preprint arXiv:2409.16211 , year=
Weber,M.,Yu,L.,Yu,Q.,Deng,X.,Shen,X.,Cremers,D.,Chen,L.C.:Maskbit:Embedding- free image generation via bit tokens. arXiv preprint arXiv:2409.16211 (2024)
-
[56]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie,J.,Mao,W.,Bai,Z.,Zhang,D.J.,Wang,W.,Lin,K.Q.,Gu,Y.,Chen,Z.,Yang,Z.,Shou, M.Z.: Show-o: One single transformer to unify multimodal understanding and generation. arXiv preprint arXiv:2408.12528 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xie, Z., Zhang, Z., Cao, Y., Lin, Y., Bao, J., Yao, Z., Dai, Q., Hu, H.: Simmim: A simple framework for masked image modeling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9653–9663 (2022)
2022
-
[58]
generation: Taming optimization dilemma in latent diffusion models
Yao, J., Yang, B., Wang, X.: Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15703–15712 (2025)
2025
-
[59]
arXiv preprint arXiv:2503.05305 (2025)
Yu, H., Luo, H., Yuan, H., Rong, Y., Zhao, F.: Frequency autoregressive image generation with continuous tokens. arXiv preprint arXiv:2503.05305 (2025)
-
[60]
In:ProceedingsoftheIEEE/CVFInternationalConferenceonComputerVision.pp.18431– 18441 (2025)
Yu,Q.,He,J.,Deng,X.,Shen,X.,Chen,L.C.:Randomizedautoregressivevisualgeneration. In:ProceedingsoftheIEEE/CVFInternationalConferenceonComputerVision.pp.18431– 18441 (2025)
2025
-
[61]
Advances in Neural Information Processing Systems37, 128940–128966 (2024)
Yu,Q.,Weber,M.,Deng,X.,Shen,X.,Cremers,D.,Chen,L.C.:Animageisworth32tokens for reconstruction and generation. Advances in Neural Information Processing Systems37, 128940–128966 (2024)
2024
-
[62]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation align- ment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
arXiv preprint arXiv:2505.12742 (2025) MEPA 19
Zhang, J., Long, W., Han, M., You, W., Gu, S.: Mvar: Visual autoregressive modeling with scale and spatial markovian conditioning. arXiv preprint arXiv:2505.12742 (2025) MEPA 19
-
[64]
Advances in Neural Information Processing Systems35, 7103–7114 (2022)
Zhou,Y.,Lei,T.,Liu,H.,Du,N.,Huang,Y.,Zhao,V.,Dai,A.M.,Le,Q.V.,Laudon,J.,etal.: Mixture-of-experts with expert choice routing. Advances in Neural Information Processing Systems35, 7103–7114 (2022)
2022
-
[65]
Zhuang,X.,Xie,Y.,Deng,Y.,Liang,L.,Ru,J.,Yin,Y.,Zou,Y.:Vargpt:Unifiedunderstanding and generation in a visual autoregressive multimodal large language model. arXiv preprint arXiv:2501.12327 (2025)
-
[66]
arXiv preprint arXiv:2110.04260 (2021)
Zuo,S.,Liu,X.,Jiao,J.,Kim,Y.J.,Hassan,H.,Zhang,R.,Zhao,T.,Gao,J.:Tamingsparsely activated transformer with stochastic experts. arXiv preprint arXiv:2110.04260 (2021)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.