GMO-E²DIT: Grounded Multi-Operation Editing for E-Commerce Images
Pith reviewed 2026-07-02 13:54 UTC · model grok-4.3
The pith
A VLM agent builds region-grounded edit plans and a reflection loop executes them iteratively to handle multi-step e-commerce image edits from vague instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
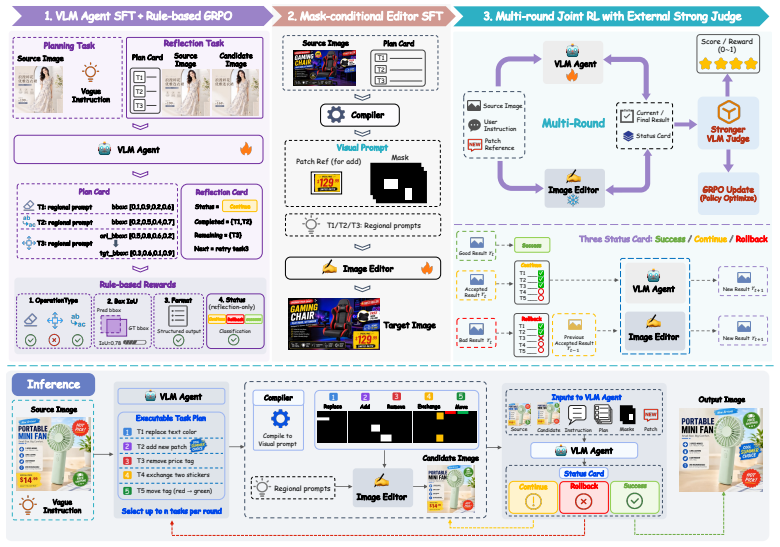
GMO-E²DIT couples a Vision-Language Model agent with a mask-conditioned image editor. The agent constructs a region-grounded edit agenda from underspecified instructions, decoupling cognitive reasoning from generative rendering. Sub-programs are executed via operation-aware masks and references inside a reflection-driven loop that inspects intermediate results, preserves safe partial progress, retries unfinished operations, and recovers from errors.
What carries the argument
The VLM agent constructing a region-grounded edit agenda, combined with a reflection-driven loop that inspects and corrects intermediate edit results.
If this is right
- Instruction accuracy and edit fidelity exceed those of existing one-shot baselines on multi-operation tasks.
- Safe partial progress is retained even when some operations initially fail.
- Cognitive planning and pixel synthesis can be handled by separate modules without loss of overall performance.
- A unified data pipeline can supply aligned supervision for planning, execution, and reflection stages.
Where Pith is reading between the lines
- The same separation of planning from rendering could extend to other tasks that require sequential localized changes, such as video or 3D model editing.
- Performance gains would likely scale with improvements in the underlying vision-language model's ability to produce accurate agendas.
- Commercial use would still benefit from optional human review for edits where mistakes carry high cost.
- The introduced benchmark offers a concrete way to compare future multi-operation editors on instruction following and content preservation.
Load-bearing premise
The vision-language model can reliably turn vague instructions into correct region-specific operation sequences and the reflection loop can detect and fix errors without introducing new ones.
What would settle it
A collection of underspecified e-commerce edit instructions where the VLM produces wrong region assignments or the reflection step leaves visible errors or undoes prior correct changes.
Figures





read the original abstract
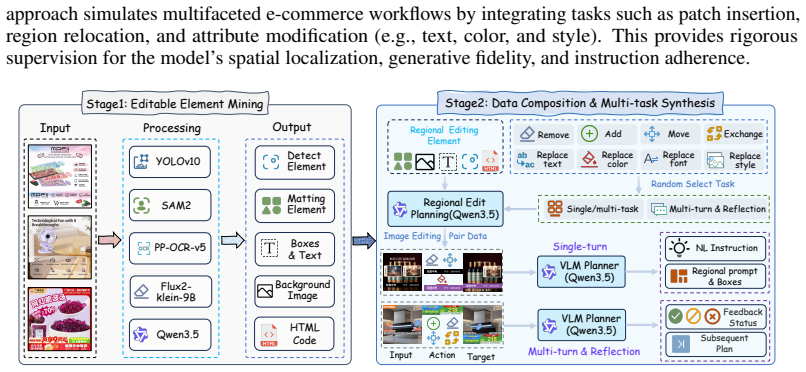
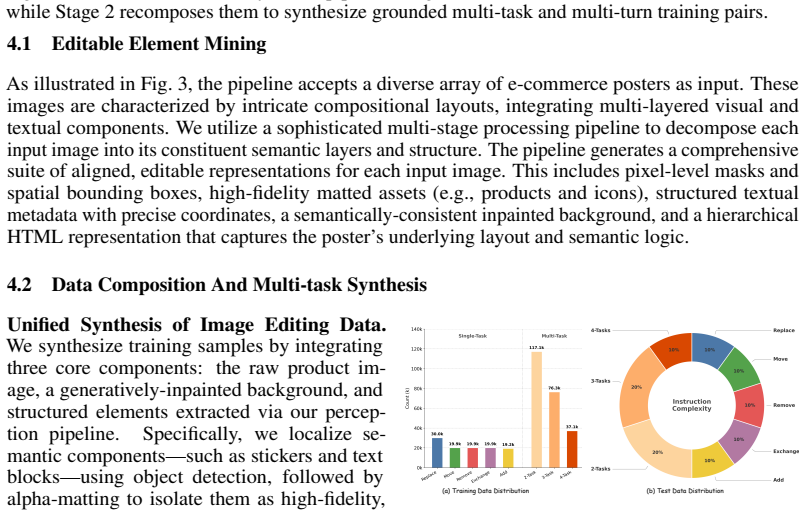
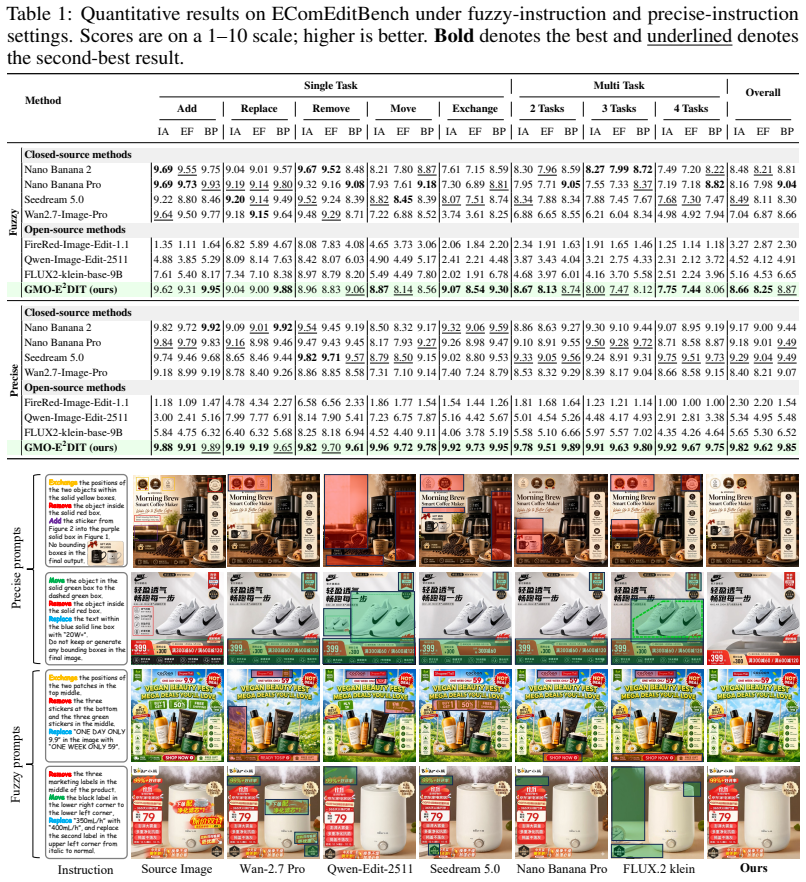
Real-world e-commerce image editing often requires multiple, localized, and auditable operations rather than global restyling. This compositional nature poses a dual challenge: models must precisely apply all requested edits to the correct regions while preserving unmodified content, even under ambiguous instructions. Existing one-shot editors conflate intent resolution, spatial grounding, and synthesis into a single step, frequently resulting in partial execution failures, which is unacceptable for commercial scenarios. To address this, we introduce GMO-E$^2$DIT, an agentic editing framework that couples a Vision-Language Model (VLM) with a mask-conditioned image editor to tackle structured multi-turn task completion. Given an underspecified instruction, the VLM agent constructs a region-grounded edit agenda, effectively decoupling cognitive reasoning from generative rendering. The framework then executes sub-programs via operation-aware masks and references, utilizing a reflection-driven loop to inspect intermediate results and determine the subsequent state. This iterative mechanism reliably preserves safe partial progress, retries unfinished operations, and recovers from errors. Furthermore, we develop a unified data pipeline providing aligned supervision for planning, execution, and reflection, alongside EComEditBench, a comprehensive benchmark for instruction-driven evaluation. Extensive experiments demonstrate that GMO-E$^2$DIT achieves competitive performance compared to strong closed-source models, yielding superior instruction accuracy and edit fidelity over existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GMO-E²DIT, an agentic framework for multi-operation e-commerce image editing. A VLM constructs a region-grounded edit agenda from underspecified instructions, decoupling reasoning from rendering; sub-programs are executed via operation-aware masks and references, with a reflection-driven loop that inspects intermediates, preserves partial progress, retries, and recovers from errors. The authors also contribute a unified data pipeline for planning/execution/reflection supervision and EComEditBench for instruction-driven evaluation. The central claim is that GMO-E²DIT achieves competitive performance with strong closed-source models while delivering superior instruction accuracy and edit fidelity over existing baselines.
Significance. If the performance claims hold, the work would be significant for commercial image-editing pipelines by enabling auditable, compositional edits under ambiguous instructions. Explicit strengths include the introduction of EComEditBench as a new benchmark and the unified data pipeline that supplies aligned supervision for the three stages; these could serve as reusable resources for the community even if the specific agentic loop requires further validation.
major comments (2)
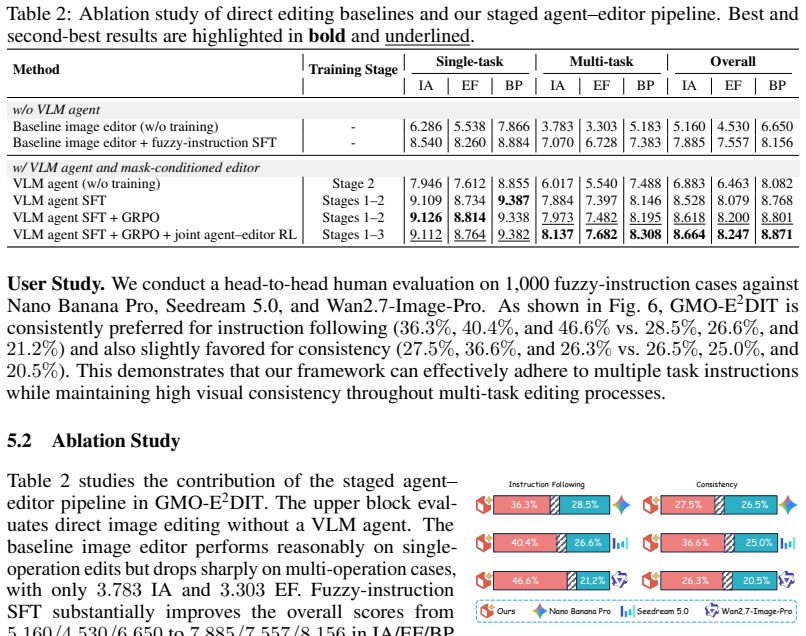
- [Abstract] Abstract: the claim that GMO-E²DIT 'achieves competitive performance... yielding superior instruction accuracy and edit fidelity' is presented without any quantitative metrics, tables, baseline names, or error analysis, rendering the central empirical claim unverifiable from the manuscript.
- [Experiments] Experiments (or equivalent section): no description is given of EComEditBench construction, its difficulty distribution, the comparison protocol for closed-source models, or failure-mode analysis of the reflection loop, all of which are load-bearing for assessing whether the reported edge is real or an artifact of benchmark design.
minor comments (2)
- [Method] The term 'operation-aware masks' is used without an explicit definition or reference to its construction on first appearance.
- [Figures] Figure captions could more explicitly link visual examples to the corresponding agenda steps and reflection outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve transparency and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GMO-E²DIT 'achieves competitive performance... yielding superior instruction accuracy and edit fidelity' is presented without any quantitative metrics, tables, baseline names, or error analysis, rendering the central empirical claim unverifiable from the manuscript.
Authors: We agree that the abstract presents the performance claim at a high level without specific numbers or references. The manuscript body includes quantitative tables and baseline comparisons in the Experiments section. To address the concern, we will revise the abstract to incorporate key quantitative highlights (e.g., specific accuracy and fidelity metrics) along with pointers to the relevant tables and sections. revision: yes
-
Referee: [Experiments] Experiments (or equivalent section): no description is given of EComEditBench construction, its difficulty distribution, the comparison protocol for closed-source models, or failure-mode analysis of the reflection loop, all of which are load-bearing for assessing whether the reported edge is real or an artifact of benchmark design.
Authors: We acknowledge these details are insufficiently elaborated in the current manuscript. While EComEditBench and the data pipeline are introduced, the construction process, difficulty distribution, closed-source comparison protocol, and reflection-loop failure-mode analysis are not fully described. We will expand the Experiments section to provide these specifics, enabling readers to evaluate the benchmark and results more rigorously. revision: yes
Circularity Check
No equations, derivations, or self-referential reductions present in framework description.
full rationale
The paper introduces GMO-E²DIT as a new agentic framework that decouples VLM-based agenda construction from mask-conditioned editing and adds a reflection loop. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations are described. The construction is presented as an original system design with an accompanying data pipeline and benchmark; performance claims are empirical rather than derived from prior inputs by construction. This matches the default case of a self-contained descriptive paper with no circularity in any claimed derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023
2023
-
[2]
Guid- ing instruction-based image editing via multimodal large language models
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guid- ing instruction-based image editing via multimodal large language models. InInternational Conference on Learning Representations, 2024
2024
-
[3]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[4]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs. Flux.1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Insightedit: Towards better instruction following for image editing
Yingjing Xu, Jie Kong, Jiazhi Wang, Xiao Pan, Bo Lin, and Qiang Liu. Insightedit: Towards better instruction following for image editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2694–2703, 2025
2025
-
[7]
Yiran Zhao, Yaoqi Ye, Xiang Liu, Michael Qizhe Shieh, and Trung Bui. Imageedit-r1: Boosting multi-agent image editing via reinforcement learning.arXiv preprint arXiv:2603.08059, 2026
-
[8]
Talk2image: A multi-agent system for multi-turn image generation and editing
Shichao Ma, Yunhe Guo, Jiahao Su, Qihe Huang, Zhengyang Zhou, and Yang Wang. Talk2image: A multi-agent system for multi-turn image generation and editing. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32437–32445, 2026
2026
-
[9]
Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Feize Wu, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, et al. Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback.arXiv preprint arXiv:2510.16888, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Enabling instructional image editing with in-context generation in large scale diffusion transformer
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. Enabling instructional image editing with in-context generation in large scale diffusion transformer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[11]
Meta-CoT: Enhancing Granularity and Generalization in Image Editing
Shiyi Zhang, Yiji Cheng, Tiankai Hang, Zijin Yin, Runze He, Yu Xu, Wenxun Dai, Yunlong Lin, Chunyu Wang, Qinglin Lu, et al. Meta-cot: Enhancing granularity and generalization in image editing.arXiv preprint arXiv:2604.24625, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Lichen Ma, Tiezhu Yue, Pei Fu, Yujie Zhong, Kai Zhou, Xiaoming Wei, and Jie Hu. Chargen: High accurate character-level visual text generation model with multimodal encoder.arXiv preprint arXiv:2412.17225, 2024
-
[13]
Objectmover: Generative object movement with video prior
Xin Yu, Tianyu Wang, Soo Ye Kim, Paul Guerrero, Xi Chen, Qing Liu, Zhe Lin, and Xiaojuan Qi. Objectmover: Generative object movement with video prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17682–17691, 2025
2025
-
[14]
Towards enhanced image inpainting: Mitigating unwanted object insertion and preserving color con- sistency
Yikai Wang, Chenjie Cao, Junqiu Yu, Ke Fan, Xiangyang Xue, and Yanwei Fu. Towards enhanced image inpainting: Mitigating unwanted object insertion and preserving color con- sistency. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23237–23248, 2025
2025
-
[15]
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InEuropean Conference on Computer Vision, pages 150–168. Springer, 2024. 11
2024
-
[16]
Turbofill: adapting few-step text- to-image model for fast image inpainting
Liangbin Xie, Daniil Pakhomov, Zhonghao Wang, Zongze Wu, Ziyan Chen, Yuqian Zhou, Haitian Zheng, Zhifei Zhang, Zhe Lin, Jiantao Zhou, et al. Turbofill: adapting few-step text- to-image model for fast image inpainting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7613–7622, 2025
2025
-
[17]
Zipeng Guo, Lichen Ma, Xiaolong Fu, Gaojing Zhou, Lan Yang, Yuchen Zhou, Linkai Liu, Yu He, Ximan Liu, Shiping Dong, et al. Repainter: Empowering e-commerce object removal via spatial-matting reinforcement learning.arXiv preprint arXiv:2510.07721, 2025
-
[18]
UM-Text: A Unified Multimodal Model for Image Understanding and Visual Text Editing
Lichen Ma, Xiaolong Fu, Gaojing Zhou, Zipeng Guo, Ting Zhu, Yichun Liu, Yu Shi, Jason Li, and Junshi Huang. Um-text: A unified multimodal model for image understanding.arXiv preprint arXiv:2601.08321, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Tianyuan Qu, Lei Ke, Xiaohang Zhan, Longxiang Tang, Yuqi Liu, Bohao Peng, Bei Yu, Dong Yu, and Jiaya Jia. Replan: Reasoning-guided region planning for complex instruction-based image editing.arXiv preprint arXiv:2512.16864, 2025
-
[20]
Rongyao Fang, Chengqi Duan, Kun Wang, Linjiang Huang, Hao Li, Shilin Yan, Hao Tian, Xingyu Zeng, Rui Zhao, Jifeng Dai, Xihui Liu, and Hongsheng Li. Got: Unleashing reasoning capability of multimodal large language model for visual generation and editing.arXiv preprint arXiv:2503.10639, 2025
-
[21]
Xuehai Bai, Xiaoling Gu, Akide Liu, Hangjie Yuan, YiFan Zhang, and Jack Ma. Mcie: Multimodal llm-driven complex instruction image editing with spatial guidance.arXiv preprint arXiv:2602.07993, 2026
-
[22]
Hongyu Li, Manyuan Zhang, Dian Zheng, Ziyu Guo, Yimeng Jia, Kaituo Feng, Hao Yu, Yexin Liu, Yan Feng, Peng Pei, Xunliang Cai, Linjiang Huang, Hongsheng Li, and Si Liu. Editthinker: Unlocking iterative reasoning for any image editor.arXiv preprint arXiv:2512.05965, 2025
-
[23]
Hengjia Li, Liming Jiang, Qing Yan, Yizhi Song, Hao Kang, Zichuan Liu, Xin Lu, Boxi Wu, and Deng Cai. Thinkrl-edit: Thinking in reinforcement learning for reasoning-centric image editing.arXiv preprint arXiv:2601.03467, 2026
-
[24]
Sixiang Chen, Jianyu Lai, Jialin Gao, Hengyu Shi, Zhongying Liu, Tian Ye, Junfeng Luo, Xiaoming Wei, and Lei Zhu. Posteromni: Generalized artistic poster creation via task distillation and unified reward feedback.arXiv preprint arXiv:2602.12127, 2026
-
[25]
Zhekai Chen, Yuqing Wang, Manyuan Zhang, and Xihui Liu. Macro: Advancing multi-reference image generation with structured long-context data.arXiv preprint arXiv:2603.25319, 2026
-
[26]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Diffedit: Diffusion- based semantic image editing with mask guidance
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion- based semantic image editing with mask guidance. InInternational Conference on Learning Representations, 2023
2023
-
[28]
Magicbrush: A manually annotated dataset for instruction-guided image editing
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing. InAdvances in Neural Information Processing Systems, 2023
2023
-
[29]
In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer. In Advances in Neural Information Processing Systems, 2025
2025
-
[30]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, Guopeng Li, Yuang Peng, Quan Sun, Jingwei Wu, Yan Cai, Zheng Ge, Ranchen Ming, Lei Xia, Xianfang Zeng, Yibo Zhu, Binxing Jiao, Xiangyu Zhang, Gang Yu, and Daxin Jiang. Step1x-edit: A practical framework for general image editing.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omnigen2: Towards instruction-aligned multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
FLUX.2: Next generation image generation
Black Forest Labs. FLUX.2: Next generation image generation. https://bfl.ai/models/ flux-2, 2025. Accessed: 2026-04-24
2025
-
[34]
Weedit: A dataset, benchmark and glyph-guided framework for text-centric image editing
Hui Zhang, Juntao Liu, Zongkai Liu, Liqiang Niu, Fandong Meng, Zuxuan Wu, and Yu-Gang Jiang. Weedit: A dataset, benchmark and glyph-guided framework for text-centric image editing. arXiv preprint arXiv:2603.11593, 2026
-
[35]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision, 2024
2024
-
[36]
Berg, Wan-Yen Lo, et al
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023
2023
-
[37]
Smartedit: Exploring complex instruction-based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, and Ying Shan. Smartedit: Exploring complex instruction-based image editing with multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[38]
Fireedit: Fine-grained instruction-based image editing via region-aware vision language model
Jun Zhou, Jiahao Li, Zunnan Xu, Hanhui Li, Yiji Cheng, Fa-Ting Hong, Qin Lin, Qinglin Lu, and Xiaodan Liang. Fireedit: Fine-grained instruction-based image editing via region-aware vision language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[39]
Chun-Hsiao Yeh, Yilin Wang, Nanxuan Zhao, Richard Zhang, Yuheng Li, Yi Ma, and Kr- ishna Kumar Singh. Beyond simple edits: X-planner for complex instruction-based image editing.arXiv preprint arXiv:2507.05259, 2025
-
[40]
Xing, et al
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, 2023
2023
-
[41]
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editre- ward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[42]
Xiangyu Zhao, Peiyuan Zhang, Junming Lin, Tianhao Liang, Yuchen Duan, Shengyuan Ding, Changyao Tian, Yuhang Zang, Junchi Yan, and Xue Yang. Trust your critic: Robust reward modeling and reinforcement learning for faithful image editing and generation.arXiv preprint arXiv:2603.12247, 2026
-
[43]
Yolov10: Real-time end-to-end object detection.Advances in neural information processing systems, 37:107984–108011, 2024
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yolov10: Real-time end-to-end object detection.Advances in neural information processing systems, 37:107984–108011, 2024
2024
-
[44]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Cheng Cui, Yubo Zhang, Ting Sun, Xueqing Wang, Hongen Liu, Manhui Lin, Yue Zhang, Tingquan Gao, Changda Zhou, Jiaxuan Liu, et al. Pp-ocrv5: A specialized 5m-parameter model rivaling billion-parameter vision-language models on ocr tasks.arXiv preprint arXiv:2603.24373, 2026
-
[46]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 14 Appendix In this work, we propose GMO-E 2DIT, an agentic framework for grounded multi-operation e- commerce image editing. Due to space constraints in the m...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
edit_fidelity: How well does the edited result satisfy the requested edit inside the target regions? For insertion tasks, also judge whether the inserted content matches the patch image
-
[49]
In the precise protocol, examine each bounding box and reference region indices in the reasoning
background_preservation: Outside the requested edit regions, is the edited image unchanged compared with the source image? Instructions.Read the benchmark instruction carefully. In the precise protocol, examine each bounding box and reference region indices in the reasoning. In the fuzzy protocol, identify the intended edit from the natural-language reque...
-
[50]
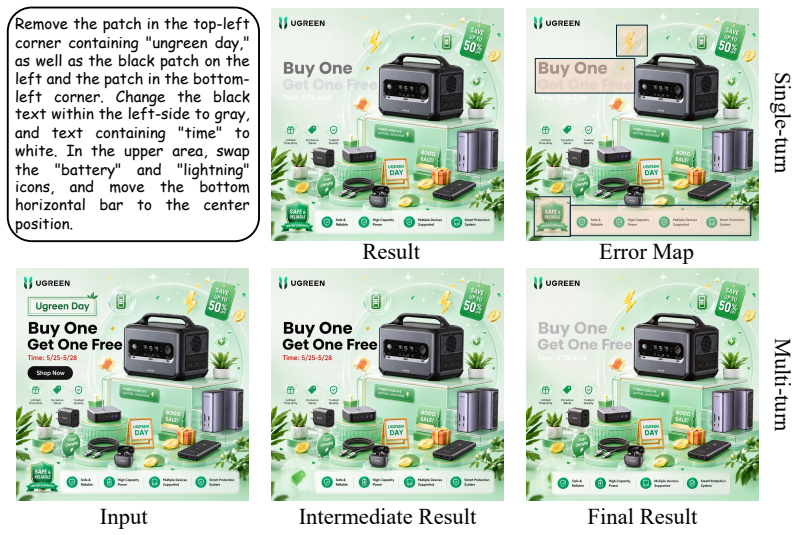
ungreenday,
Unless otherwise specified, all experiments are conducted on the same constructed training dataset and evaluated on the held-out EComEditBench split. All experiments are conducted on 16 NVIDIA B200 GPUs. E More Experiment Results E.1 Multi-turn Editing To evaluate our multi-turn joint RL and reflection-driven mechanism, we conduct experiments on a test se...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.